 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a complete 3D morphable model of the human head
Nov 18, 2019

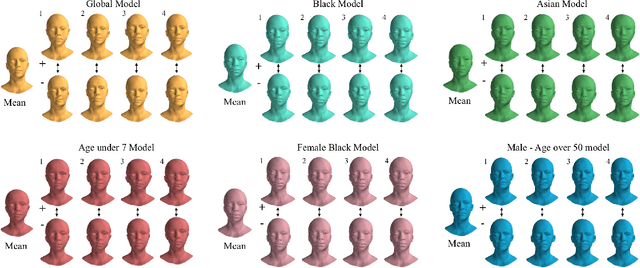
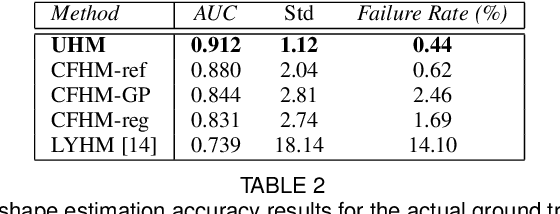
Three-dimensional Morphable Models (3DMMs) are powerful statistical tools for representing the 3D shapes and textures of an object class. Here we present the most complete 3DMM of the human head to date that includes face, cranium, ears, eyes, teeth and tongue. To achieve this, we propose two methods for combining existing 3DMMs of different overlapping head parts: i. use a regressor to complete missing parts of one model using the other, ii. use the Gaussian Process framework to blend covariance matrices from multiple models. Thus we build a new combined face-and-head shape model that blends the variability and facial detail of an existing face model (the LSFM) with the full head modelling capability of an existing head model (the LYHM). Then we construct and fuse a highly-detailed ear model to extend the variation of the ear shape. Eye and eye region models are incorporated into the head model, along with basic models of the teeth, tongue and inner mouth cavity. The new model achieves state-of-the-art performance. We use our model to reconstruct full head representations from single, unconstrained images allowing us to parameterize craniofacial shape and texture, along with the ear shape, eye gaze and eye color.
SpiralNet++: A Fast and Highly Efficient Mesh Convolution Operator
Nov 13, 2019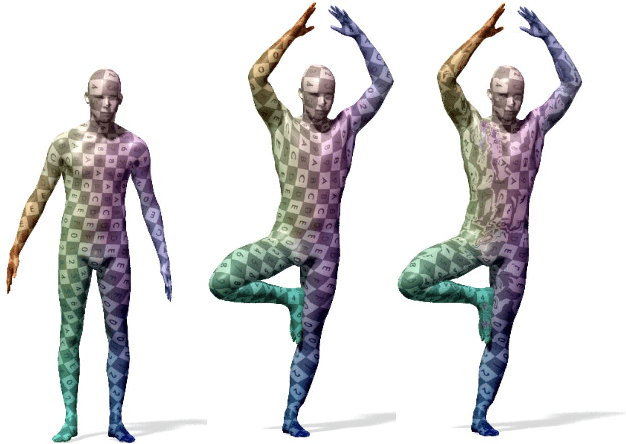
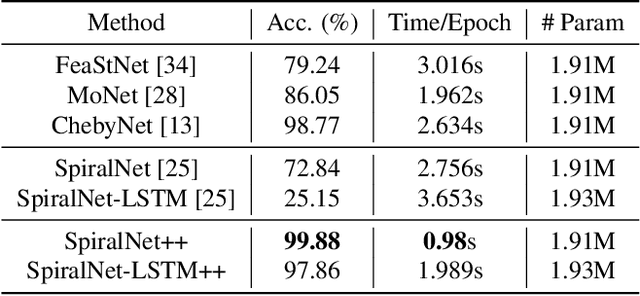
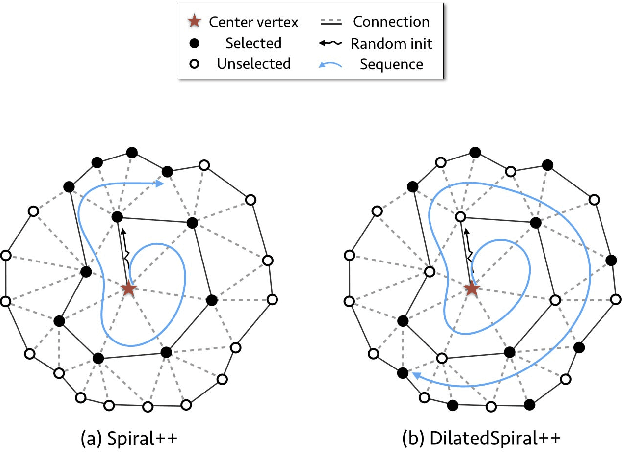
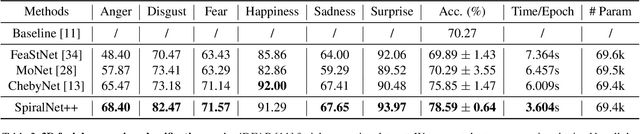
Intrinsic graph convolution operators with differentiable kernel functions play a crucial role in analyzing 3D shape meshes. In this paper, we present a fast and efficient intrinsic mesh convolution operator that does not rely on the intricate design of kernel function. We explicitly formulate the order of aggregating neighboring vertices, instead of learning weights between nodes, and then a fully connected layer follows to fuse local geometric structure information with vertex features. We provide extensive evidence showing that models based on this convolution operator are easier to train, and can efficiently learn invariant shape features. Specifically, we evaluate our method on three different types of tasks of dense shape correspondence, 3D facial expression classification, and 3D shape reconstruction, and show that it significantly outperforms state-of-the-art approaches while being significantly faster, without relying on shape descriptors. Our source code is available on GitHub.
Face Behavior à la carte: Expressions, Affect and Action Units in a Single Network
Oct 15, 2019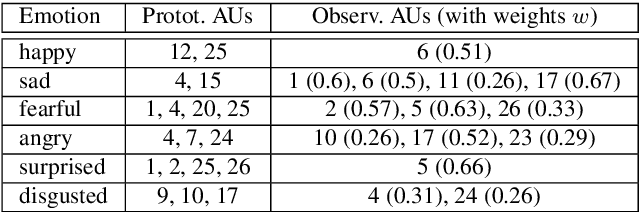
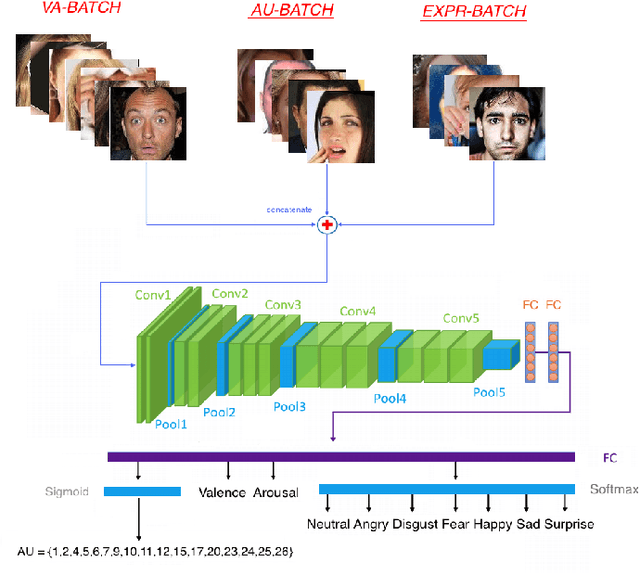
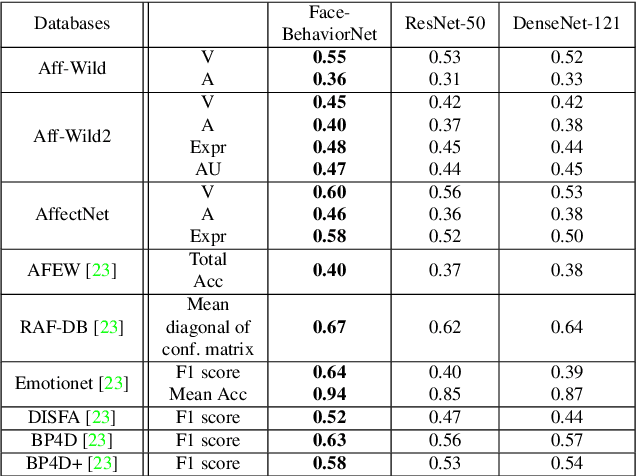
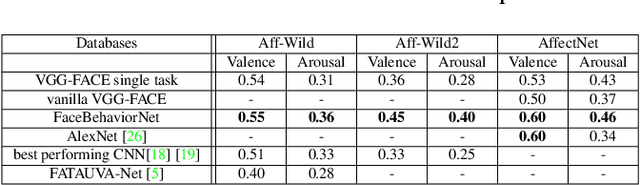
Automatic facial behavior analysis has a long history of studies in the intersection of computer vision, physiology and psychology. However it is only recently, with the collection of large-scale datasets and powerful machine learning methods such as deep neural networks, that automatic facial behavior analysis started to thrive. Three of its iconic tasks are automatic recognition of basic expressions (e.g. happy, sad, surprised), estimation of continuous emotions (e.g., valence and arousal), and detection of facial action units (activations of e.g. upper/inner eyebrows, nose wrinkles). Up until now these tasks have been mostly studied independently collecting a dataset for the task. We present the first and the largest study of all facial behaviour tasks learned jointly in a single multi-task, multi-domain and multi-label network, which we call FaceBehaviorNet. For this we utilize all publicly available datasets in the community (around 5M images) that study facial behaviour tasks in-the-wild. We demonstrate that training jointly an end-to-end network for all tasks has consistently better performance than training each of the single-task networks. Furthermore, we propose two simple strategies for coupling the tasks during training, co-annotation and distribution matching, and show the advantages of this approach. Finally we show that FaceBehaviorNet has learned features that encapsulate all aspects of facial behaviour, and can be successfully applied to perform tasks (compound emotion recognition) beyond the ones that it has been trained in a zero- and few-shot learning setting.
Complement Face Forensic Detection and Localization with FacialLandmarks
Oct 12, 2019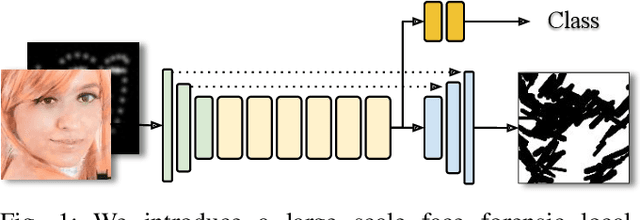

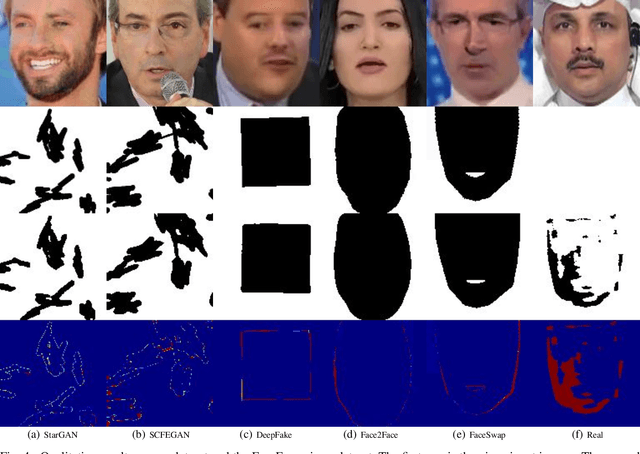
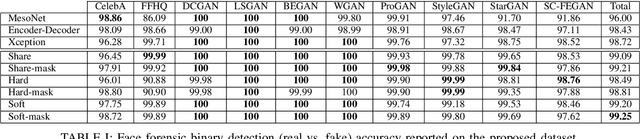
Recently, Generative Adversarial Networks (GANs) and image manipulating methods are becoming more powerful and can produce highly realistic face images beyond human recognition which have raised significant concerns regarding the authenticity of digital media. Although there have been some prior works that tackle face forensic classification problem, it is not trivial to estimate edited locations from classification predictions. In this paper, we propose, to the best of our knowledge, the first rigorous face forensic localization dataset, which consists of genuine, generated, and manipulated face images. In particular, the pristine parts contain face images from CelebA and FFHQ datasets. The fake images are generated from various GANs methods, namely DCGANs, LSGANs, BEGANs, WGAN-GP, ProGANs, and StyleGANs. Lastly, the edited subset is generated from StarGAN and SEFCGAN based on free-form masks. In total, the dataset contains about 1.3 million facial images labelled with corresponding binary masks. Based on the proposed dataset, we demonstrated that explicit adding facial landmarks information in addition to input images improves the performance. In addition, our proposed method consists of two branches and can coherently predict face forensic detection and localization to outperform the previous state-of-the-art techniques on the newly proposed dataset as well as the faceforecsic++ dataset especially on low-quality videos.
Exploiting multi-CNN features in CNN-RNN based Dimensional Emotion Recognition on the OMG in-the-wild Dataset
Oct 03, 2019
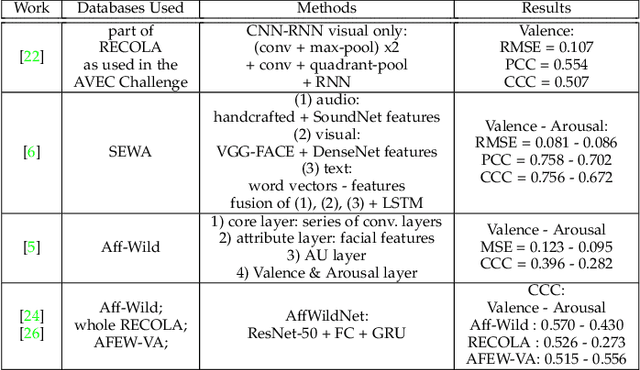


This paper presents a novel CNN-RNN based approach, which exploits multiple CNN features for dimensional emotion recognition in-the-wild, utilizing the One-Minute Gradual-Emotion (OMG-Emotion) dataset. Our approach includes first pre-training with the relevant and large in size, Aff-Wild and Aff-Wild2 emotion databases. Low-, mid- and high-level features are extracted from the trained CNN component and are exploited by RNN subnets in a multi-task framework. Their outputs constitute an intermediate level prediction; final estimates are obtained as the mean or median values of these predictions. Fusion of the networks is also examined for boosting the obtained performance, at Decision-, or at Model-level; in the latter case a RNN was used for the fusion. Our approach, although using only the visual modality, outperformed state-of-the-art methods that utilized audio and visual modalities. Some of our developments have been submitted to the OMG-Emotion Challenge, ranking second among the technologies which used only visual information for valence estimation; ranking third overall. Through extensive experimentation, we further show that arousal estimation is greatly improved when low-level features are combined with high-level ones.
Expression, Affect, Action Unit Recognition: Aff-Wild2, Multi-Task Learning and ArcFace
Sep 25, 2019

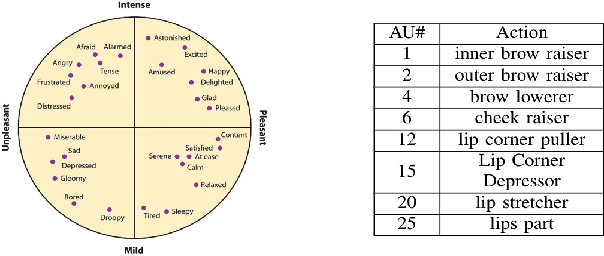
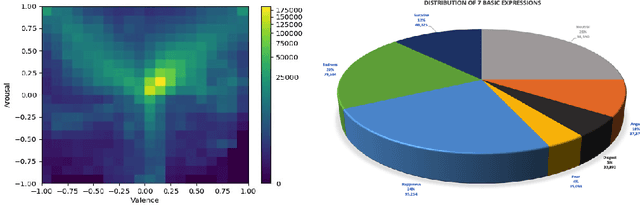
Affective computing has been largely limited in terms of available data resources. The need to collect and annotate diverse in-the-wild datasets has become apparent with the rise of deep learning models, as the default approach to address any computer vision task. Some in-the-wild databases have been recently proposed. However: i) their size is small, ii) they are not audiovisual, iii) only a small part is manually annotated, iv) they contain a small number of subjects, or v) they are not annotated for all main behavior tasks (valence-arousal estimation, action unit detection and basic expression classification). To address these, we substantially extend the largest available in-the-wild database (Aff-Wild) to study continuous emotions such as valence and arousal. Furthermore, we annotate parts of the database with basic expressions and action units. As a consequence, for the first time, this allows the joint study of all three types of behavior states. We call this database Aff-Wild2. We conduct extensive experiments with CNN and CNN-RNN architectures that use visual and audio modalities; these networks are trained on Aff-Wild2 and their performance is then evaluated on 10 publicly available emotion databases. We show that the networks achieve state-of-the-art performance for the emotion recognition tasks. Additionally, we adapt the ArcFace loss function in the emotion recognition context and use it for training two new networks on Aff-Wild2 and then re-train them in a variety of diverse expression recognition databases. The networks are shown to improve the existing state-of-the-art. The database, emotion recognition models and source code are available at http://ibug.doc.ic.ac.uk/resources/aff-wild2.
Synthesizing Coupled 3D Face Modalities by Trunk-Branch Generative Adversarial Networks
Sep 05, 2019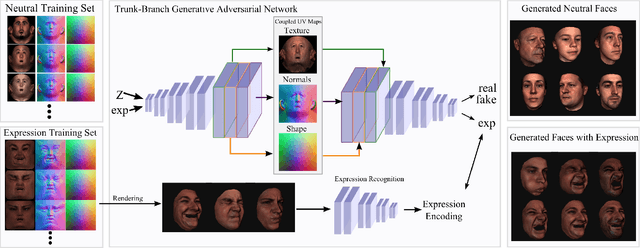
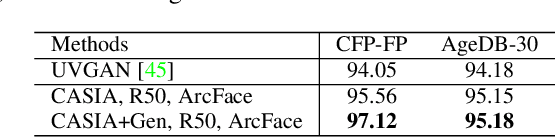


Generating realistic 3D faces is of high importance for computer graphics and computer vision applications. Generally, research on 3D face generation revolves around linear statistical models of the facial surface. Nevertheless, these models cannot represent faithfully either the facial texture or the normals of the face, which are very crucial for photo-realistic face synthesis. Recently, it was demonstrated that Generative Adversarial Networks (GANs) can be used for generating high-quality textures of faces. Nevertheless, the generation process either omits the geometry and normals, or independent processes are used to produce 3D shape information. In this paper, we present the first methodology that generates high-quality texture, shape, and normals jointly, which can be used for photo-realistic synthesis. To do so, we propose a novel GAN that can generate data from different modalities while exploiting their correlations. Furthermore, we demonstrate how we can condition the generation on the expression and create faces with various facial expressions. The qualitative results shown in this pre-print is compressed due to size limitations, full resolution results and the accompanying video can be found at the project page: https://github.com/barisgecer/TBGAN.
SliderGAN: Synthesizing Expressive Face Images by Sliding 3D Blendshape Parameters
Aug 26, 2019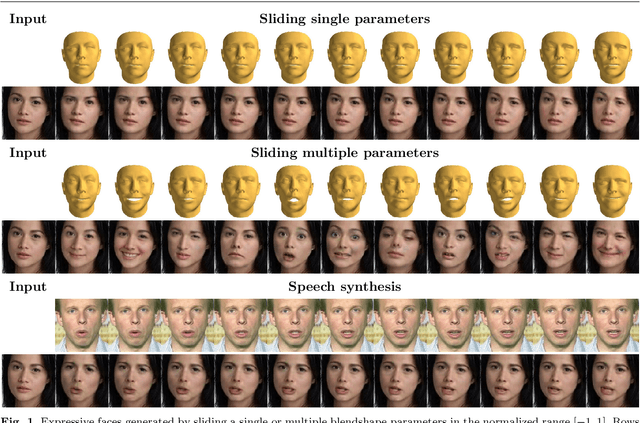
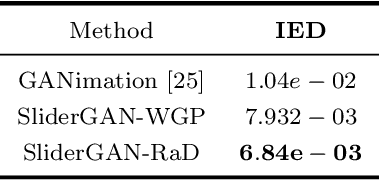


Image-to-image (i2i) translation is the dense regression problem of learning how to transform an input image into an output using aligned image pairs. Remarkable progress has been made in i2i translation with the advent of Deep Convolutional Neural Networks (DCNNs) and particular using the learning paradigm of Generative Adversarial Networks (GANs). In the absence of paired images, i2i translation is tackled with one or multiple domain transformations (i.e., CycleGAN, StarGAN etc.). In this paper, we study a new problem, that of image-to-image translation, under a set of continuous parameters that correspond to a model describing a physical process. In particular, we propose the SliderGAN which transforms an input face image into a new one according to the continuous values of a statistical blendshape model of facial motion. We show that it is possible to edit a facial image according to expression and speech blendshapes, using sliders that control the continuous values of the blendshape model. This provides much more flexibility in various tasks, including but not limited to face editing, expression transfer and face neutralisation, comparing to models based on discrete expressions or action units.
PolyGAN: High-Order Polynomial Generators
Aug 19, 2019
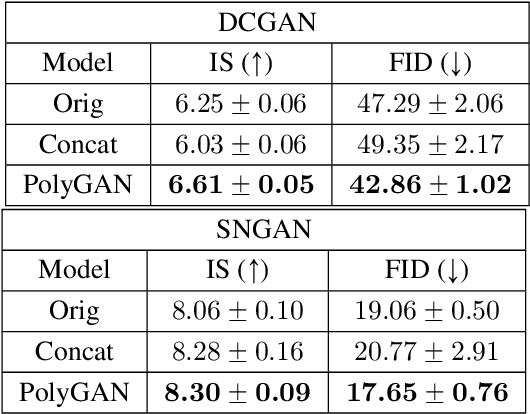
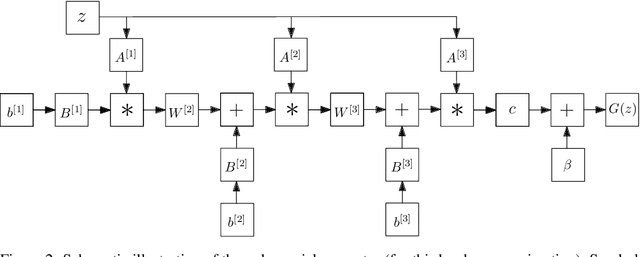
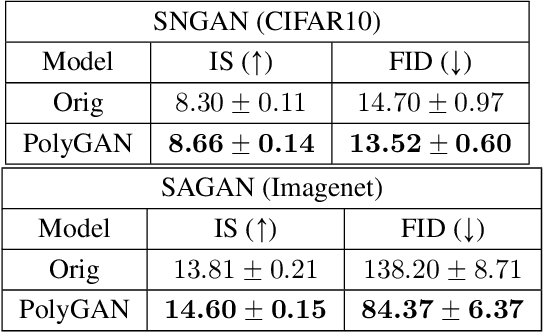
Generative Adversarial Networks (GANs) have become the gold standard when it comes to learning generative models that can describe intricate, high-dimensional distributions. Since their advent, numerous variations of GANs have been introduced in the literature, primarily focusing on utilization of novel loss functions, optimization/regularization strategies and architectures. In this work, we take an orthogonal approach to the above and turn our attention to the generator. We propose to model the data generator by means of a high-order polynomial using tensorial factors. We design a hierarchical decomposition of the polynomial and demonstrate how it can be efficiently implemented by a neural network. We show, for the first time, that by using our decomposition a GAN generator can approximate the data distribution by only using linear/convolution blocks without using any activation functions. Finally, we highlight that PolyGAN can be easily adapted and used along-side all major GAN architectures. In an extensive series of quantitative and qualitative experiments, PolyGAN improves upon the state-of-the-art by a significant margin.
Video-to-Video Translation for Visual Speech Synthesis
May 28, 2019
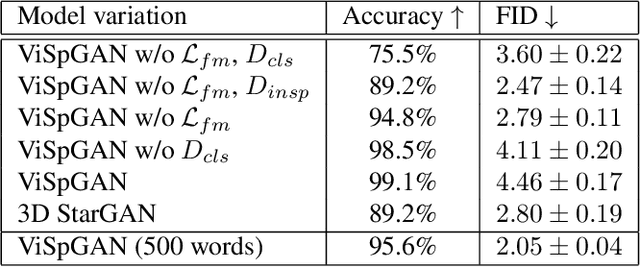
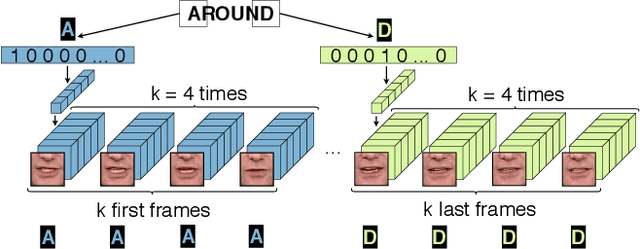
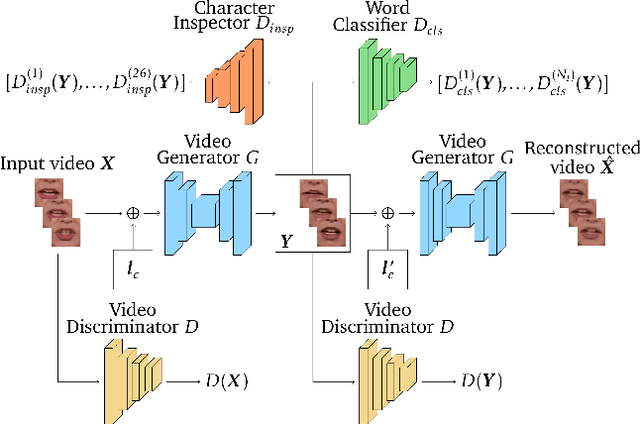
Despite remarkable success in image-to-image translation that celebrates the advancements of generative adversarial networks (GANs), very limited attempts are known for video domain translation. We study the task of video-to-video translation in the context of visual speech generation, where the goal is to transform an input video of any spoken word to an output video of a different word. This is a multi-domain translation, where each word forms a domain of videos uttering this word. Adaptation of the state-of-the-art image-to-image translation model (StarGAN) to this setting falls short with a large vocabulary size. Instead we propose to use character encodings of the words and design a novel character-based GANs architecture for video-to-video translation called Visual Speech GAN (ViSpGAN). We are the first to demonstrate video-to-video translation with a vocabulary of 500 words.