 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplement Face Forensic Detection and Localization with FacialLandmarks
Oct 12, 2019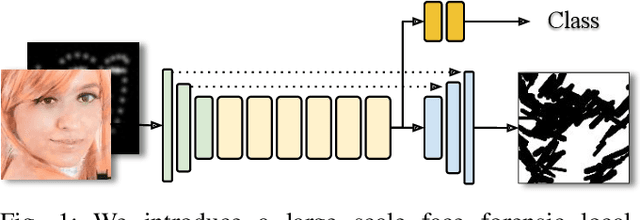

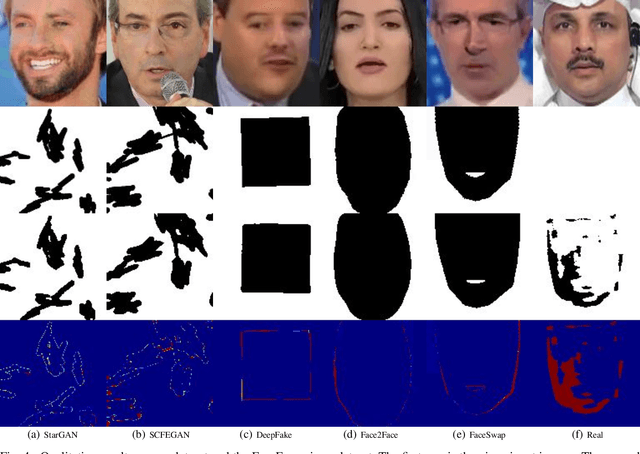
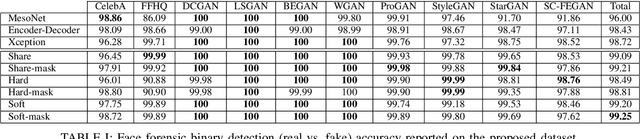
Recently, Generative Adversarial Networks (GANs) and image manipulating methods are becoming more powerful and can produce highly realistic face images beyond human recognition which have raised significant concerns regarding the authenticity of digital media. Although there have been some prior works that tackle face forensic classification problem, it is not trivial to estimate edited locations from classification predictions. In this paper, we propose, to the best of our knowledge, the first rigorous face forensic localization dataset, which consists of genuine, generated, and manipulated face images. In particular, the pristine parts contain face images from CelebA and FFHQ datasets. The fake images are generated from various GANs methods, namely DCGANs, LSGANs, BEGANs, WGAN-GP, ProGANs, and StyleGANs. Lastly, the edited subset is generated from StarGAN and SEFCGAN based on free-form masks. In total, the dataset contains about 1.3 million facial images labelled with corresponding binary masks. Based on the proposed dataset, we demonstrated that explicit adding facial landmarks information in addition to input images improves the performance. In addition, our proposed method consists of two branches and can coherently predict face forensic detection and localization to outperform the previous state-of-the-art techniques on the newly proposed dataset as well as the faceforecsic++ dataset especially on low-quality videos.
Face Video Generation from a Single Image and Landmarks
Apr 25, 2019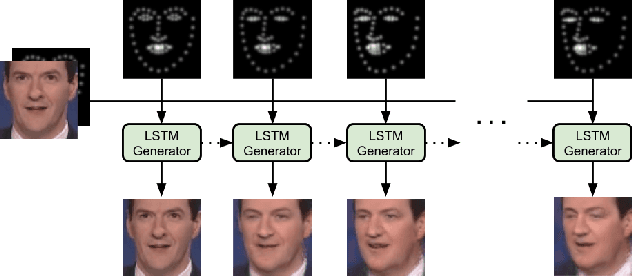
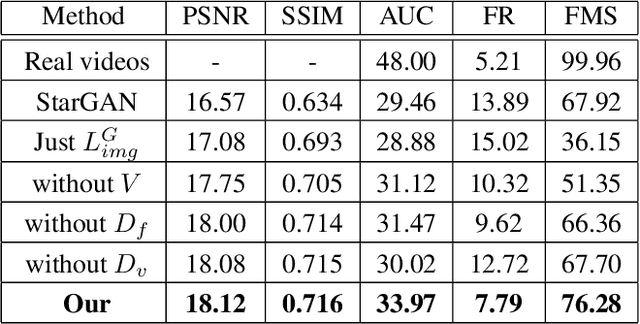
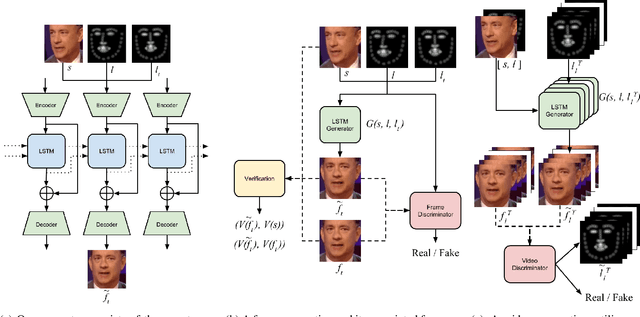
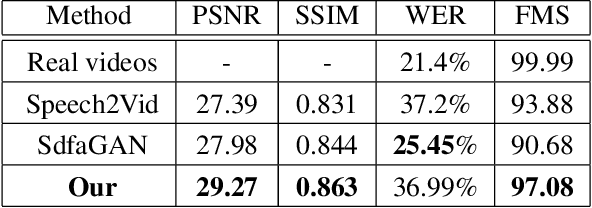
In this paper we are concerned with the challenging problem of producing a full image sequence of a deformable face given only an image and generic facial motions encoded by a set of sparse landmarks. To this end we build upon recent breakthroughs in image-to-image translation such as pix2pix, CycleGAN and StarGAN which learn Deep Convolutional Neural Networks (DCNNs) that learn to map aligned pairs or images between different domains (i.e., having different labels) and propose a new architecture which is not driven any more by labels but by spatial maps, facial landmarks. In particular, we propose the MotionGAN which transforms an input face image into a new one according to a heatmap of target landmarks. We show that it is possible to create very realistic face videos using a single image and a set of target landmarks. Furthermore, our method can be used to edit a facial image with arbitrary motions according to landmarks (e.g., expression, speech, etc.). This provides much more flexibility to face editing, expression transfer, facial video creation, etc. than models based on discrete expressions, audios or action units.