 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Attention Unit: Towards Efficient Spatiotemporal Predictive Learning
Jun 24, 2022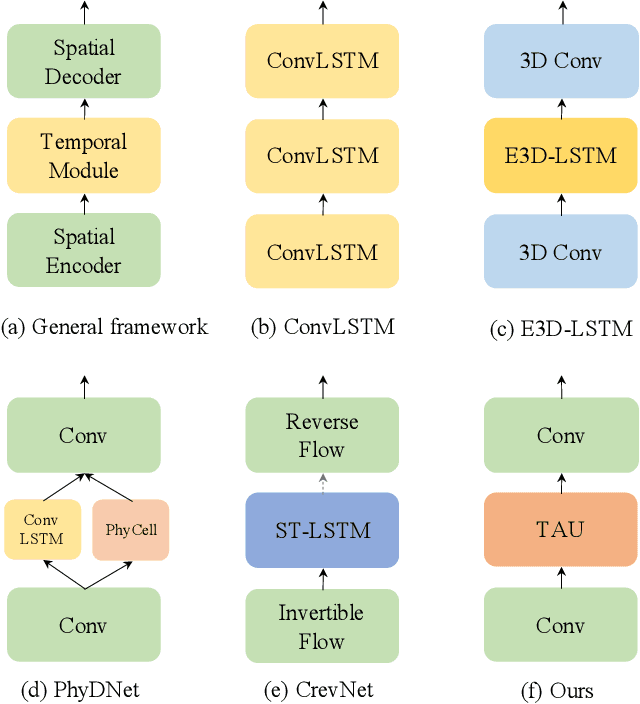
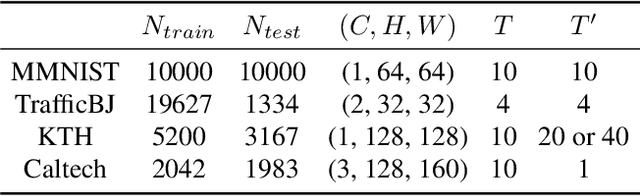
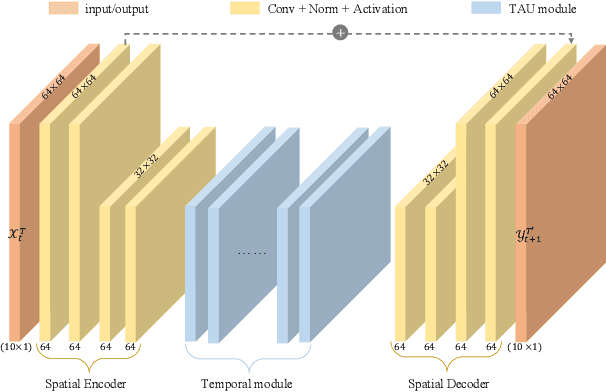
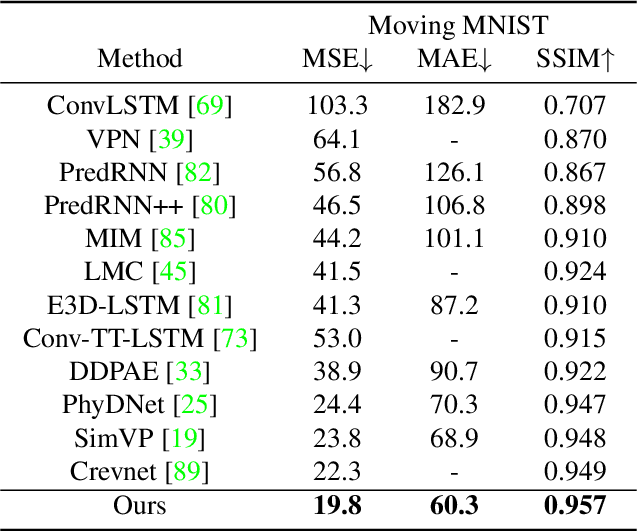
Spatiotemporal predictive learning aims to generate future frames by learning from historical frames. In this paper, we investigate existing methods and present a general framework of spatiotemporal predictive learning, in which the spatial encoder and decoder capture intra-frame features and the middle temporal module catches inter-frame correlations. While the mainstream methods employ recurrent units to capture long-term temporal dependencies, they suffer from low computational efficiency due to their unparallelizable architectures. To parallelize the temporal module, we propose the Temporal Attention Unit (TAU), which decomposes the temporal attention into intra-frame statical attention and inter-frame dynamical attention. Moreover, while the mean squared error loss focuses on intra-frame errors, we introduce a novel differential divergence regularization to take inter-frame variations into account. Extensive experiments demonstrate that the proposed method enables the derived model to achieve competitive performance on various spatiotemporal prediction benchmarks.
CoSP: Co-supervised pretraining of pocket and ligand
Jun 23, 2022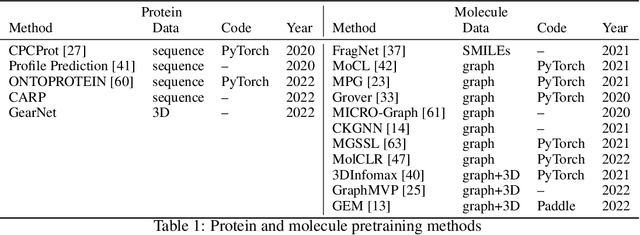
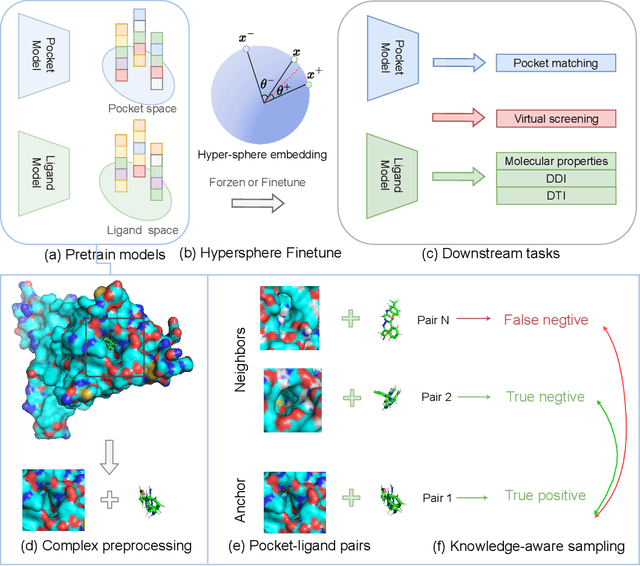

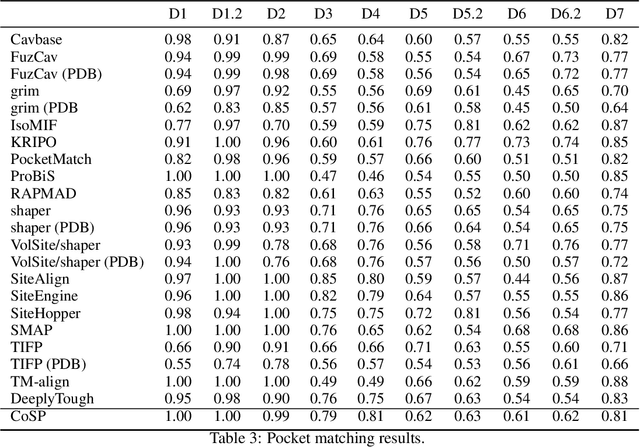
Can we inject the pocket-ligand interaction knowledge into the pre-trained model and jointly learn their chemical space? Pretraining molecules and proteins has attracted considerable attention in recent years, while most of these approaches focus on learning one of the chemical spaces and lack the injection of biological knowledge. We propose a co-supervised pretraining (CoSP) framework to simultaneously learn 3D pocket and ligand representations. We use a gated geometric message passing layer to model both 3D pockets and ligands, where each node's chemical features, geometric position and orientation are considered. To learn biological meaningful embeddings, we inject the pocket-ligand interaction knowledge into the pretraining model via contrastive loss. Considering the specificity of molecules, we further propose a chemical similarity-enhanced negative sampling strategy to improve the contrastive learning performance. Through extensive experiments, we conclude that CoSP can achieve competitive results in pocket matching, molecule property predictions, and virtual screening.
SimVP: Simpler yet Better Video Prediction
Jun 09, 2022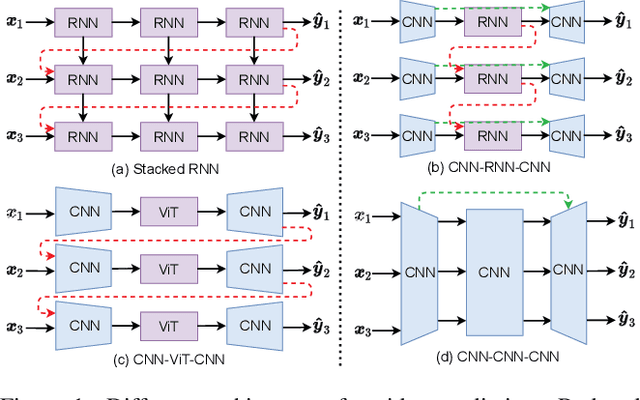

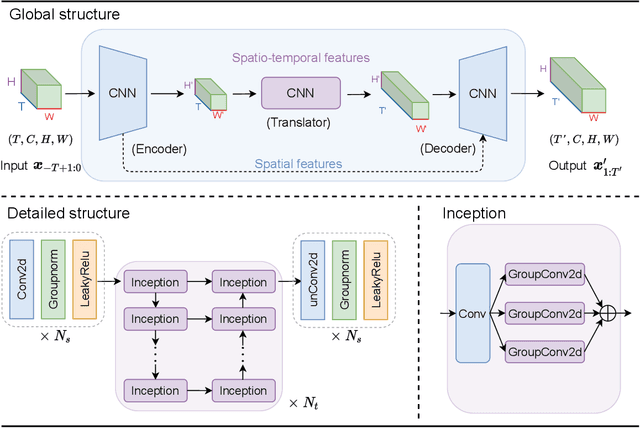
From CNN, RNN, to ViT, we have witnessed remarkable advancements in video prediction, incorporating auxiliary inputs, elaborate neural architectures, and sophisticated training strategies. We admire these progresses but are confused about the necessity: is there a simple method that can perform comparably well? This paper proposes SimVP, a simple video prediction model that is completely built upon CNN and trained by MSE loss in an end-to-end fashion. Without introducing any additional tricks and complicated strategies, we can achieve state-of-the-art performance on five benchmark datasets. Through extended experiments, we demonstrate that SimVP has strong generalization and extensibility on real-world datasets. The significant reduction of training cost makes it easier to scale to complex scenarios. We believe SimVP can serve as a solid baseline to stimulate the further development of video prediction. The code is available at \href{https://github.com/gaozhangyang/SimVP-Simpler-yet-Better-Video-Prediction}{Github}.
Hyperspherical Consistency Regularization
Jun 02, 2022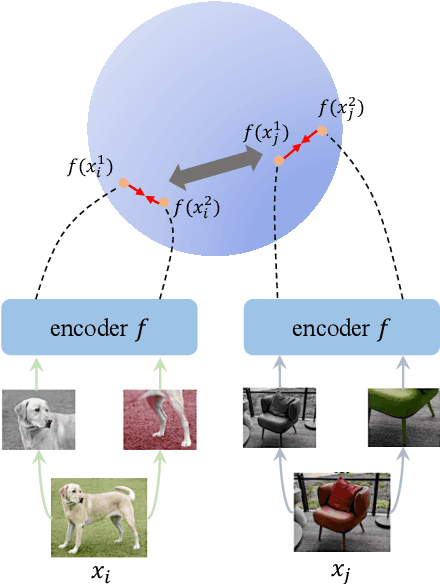
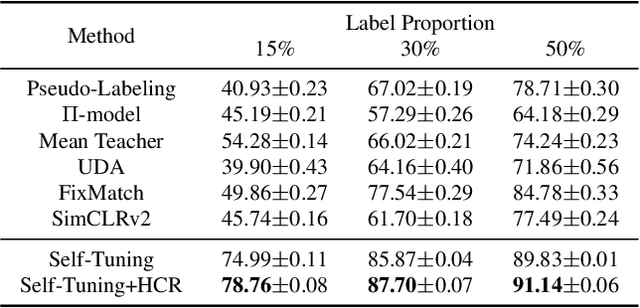
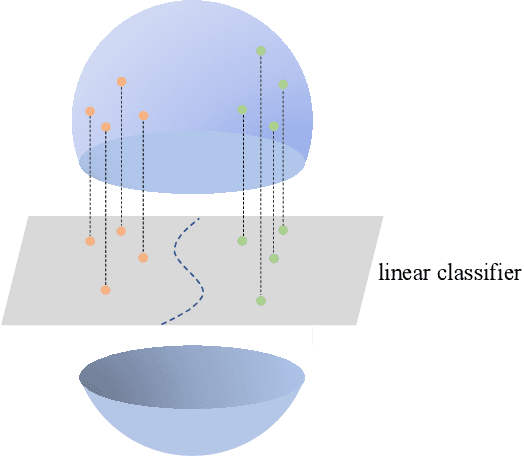
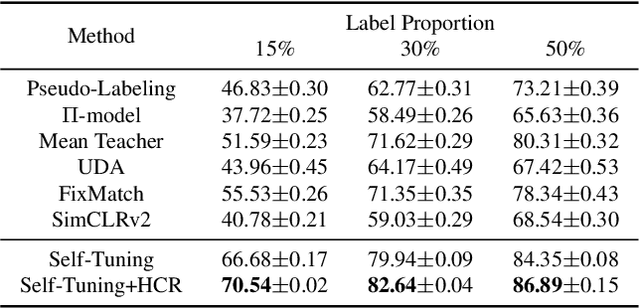
Recent advances in contrastive learning have enlightened diverse applications across various semi-supervised fields. Jointly training supervised learning and unsupervised learning with a shared feature encoder becomes a common scheme. Though it benefits from taking advantage of both feature-dependent information from self-supervised learning and label-dependent information from supervised learning, this scheme remains suffering from bias of the classifier. In this work, we systematically explore the relationship between self-supervised learning and supervised learning, and study how self-supervised learning helps robust data-efficient deep learning. We propose hyperspherical consistency regularization (HCR), a simple yet effective plug-and-play method, to regularize the classifier using feature-dependent information and thus avoid bias from labels. Specifically, HCR first projects logits from the classifier and feature projections from the projection head on the respective hypersphere, then it enforces data points on hyperspheres to have similar structures by minimizing binary cross entropy of pairwise distances' similarity metrics. Extensive experiments on semi-supervised and weakly-supervised learning demonstrate the effectiveness of our method, by showing superior performance with HCR.
Discovering the Representation Bottleneck of Graph Neural Networks from Multi-order Interactions
May 21, 2022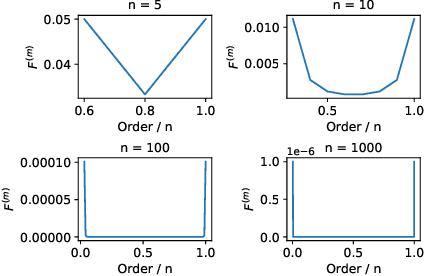

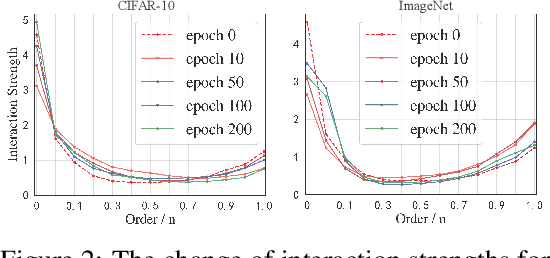

Most graph neural networks (GNNs) rely on the message passing paradigm to propagate node features and build interactions. Recent works point out that different graph learning tasks require different ranges of interactions between nodes. To investigate the underlying mechanism, we explore the capacity of GNNs to capture pairwise interactions between nodes under contexts with different complexities, especially for their graph-level and node-level applications in scientific domains like biochemistry and physics. When formulating pairwise interactions, we study two standard graph construction methods in scientific domains, i.e., K-nearest neighbor (KNN) graphs and fully-connected (FC) graphs. Furthermore, we demonstrate that the inductive bias introduced by KNN-graphs and FC-graphs inhibits GNNs from learning the most informative order of interactions. Such a phenomenon is broadly shared by several GNNs for different graph learning tasks and prevents GNNs from reaching the global minimum loss, so we name it a representation bottleneck. To overcome that, we propose a novel graph rewiring approach based on the pairwise interaction strengths to adjust the reception fields of each node dynamically. Extensive experiments in molecular property prediction and dynamic system forecast prove the superiority of our method over state-of-the-art GNN baselines. Besides, this paper provides a reasonable explanation of why subgraphs play a vital role in determining graph properties. The code is available at https://github.com/smiles724/bottleneck.
MVP-Human Dataset for 3D Human Avatar Reconstruction from Unconstrained Frames
Apr 24, 2022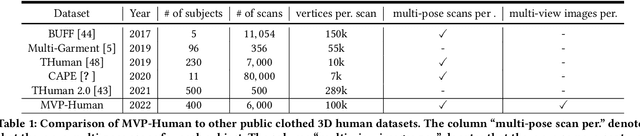
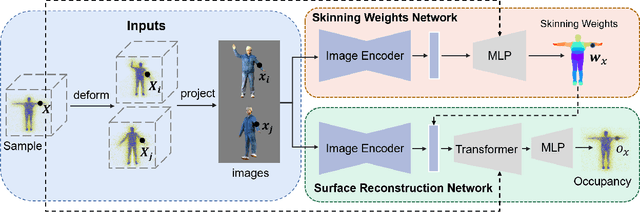
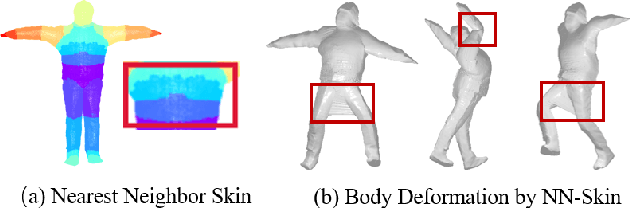
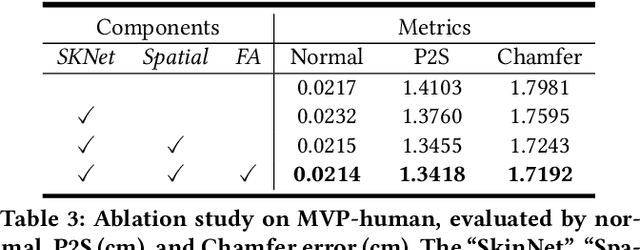
In this paper, we consider a novel problem of reconstructing a 3D human avatar from multiple unconstrained frames, independent of assumptions on camera calibration, capture space, and constrained actions. The problem should be addressed by a framework that takes multiple unconstrained images as inputs, and generates a shape-with-skinning avatar in the canonical space, finished in one feed-forward pass. To this end, we present 3D Avatar Reconstruction in the wild (ARwild), which first reconstructs the implicit skinning fields in a multi-level manner, by which the image features from multiple images are aligned and integrated to estimate a pixel-aligned implicit function that represents the clothed shape. To enable the training and testing of the new framework, we contribute a large-scale dataset, MVP-Human (Multi-View and multi-Pose 3D Human), which contains 400 subjects, each of which has 15 scans in different poses and 8-view images for each pose, providing 6,000 3D scans and 48,000 images in total. Overall, benefits from the specific network architecture and the diverse data, the trained model enables 3D avatar reconstruction from unconstrained frames and achieves state-of-the-art performance.
STONet: A Neural-Operator-Driven Spatio-temporal Network
Apr 21, 2022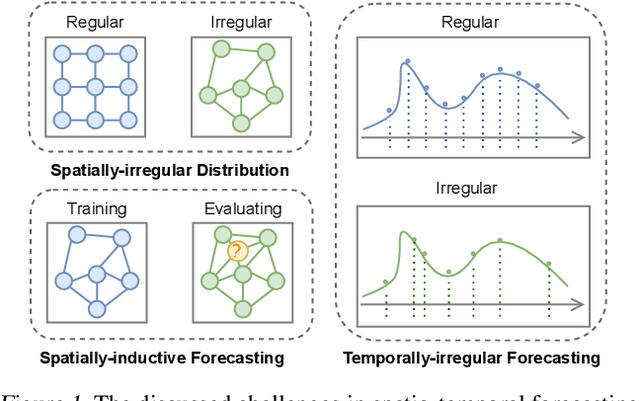
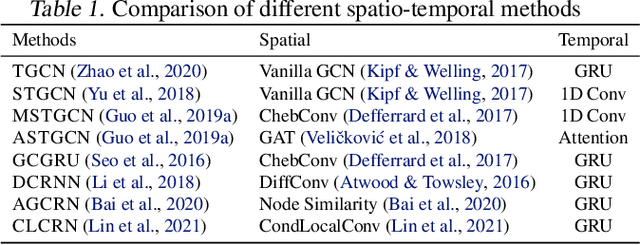
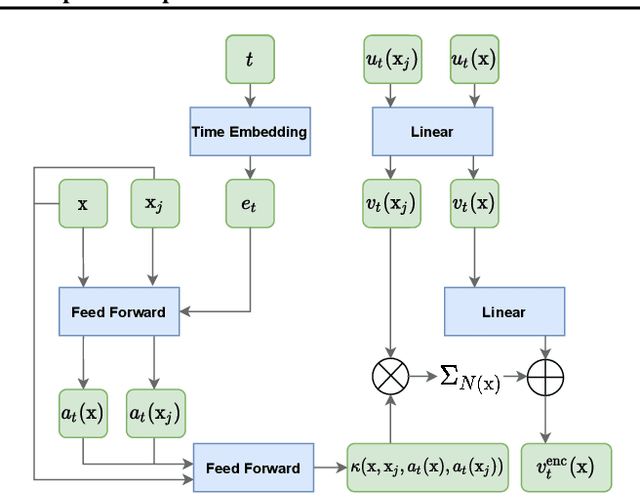

Graph-based spatio-temporal neural networks are effective to model the spatial dependency among discrete points sampled irregularly from unstructured grids, thanks to the great expressiveness of graph neural networks. However, these models are usually spatially-transductive -- only fitting the signals for discrete spatial nodes fed in models but unable to generalize to `unseen' spatial points with zero-shot. In comparison, for forecasting tasks on continuous space such as temperature prediction on the earth's surface, the \textit{spatially-inductive} property allows the model to generalize to any point in the spatial domain, demonstrating models' ability to learn the underlying mechanisms or physics laws of the systems, rather than simply fit the signals. Besides, in temporal domains, \textit{irregularly-sampled} time series, e.g. data with missing values, urge models to be temporally-continuous. Motivated by the two issues, we propose a spatio-temporal framework based on neural operators for PDEs, which learn the underlying mechanisms governing the dynamics of spatially-continuous physical quantities. Experiments show our model's improved performance on forecasting spatially-continuous physic quantities, and its superior generalization to unseen spatial points and ability to handle temporally-irregular data.
Generative De Novo Protein Design with Global Context
Apr 21, 2022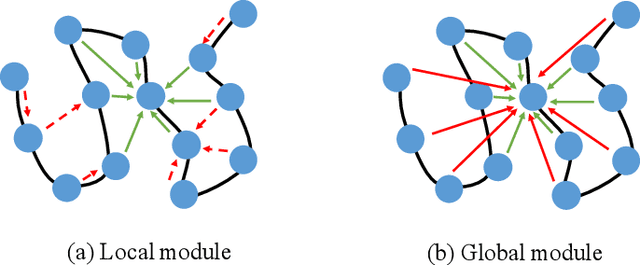
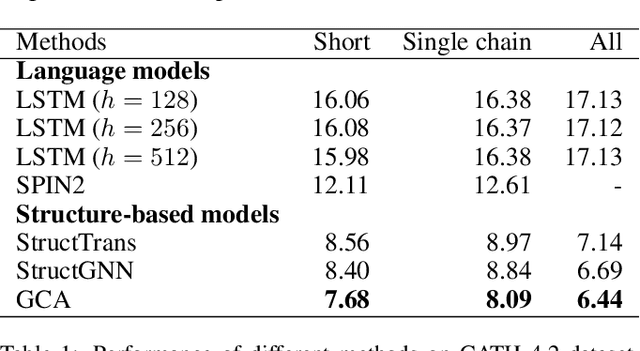
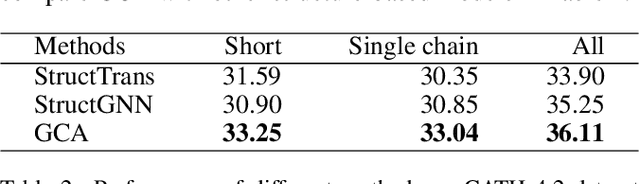
The linear sequence of amino acids determines protein structure and function. Protein design, known as the inverse of protein structure prediction, aims to obtain a novel protein sequence that will fold into the defined structure. Recent works on computational protein design have studied designing sequences for the desired backbone structure with local positional information and achieved competitive performance. However, similar local environments in different backbone structures may result in different amino acids, indicating that protein structure's global context matters. Thus, we propose the Global-Context Aware generative de novo protein design method (GCA), consisting of local and global modules. While local modules focus on relationships between neighbor amino acids, global modules explicitly capture non-local contexts. Experimental results demonstrate that the proposed GCA method outperforms state-of-the-arts on de novo protein design. Our code and pretrained model will be released.
A Score-based Geometric Model for Molecular Dynamics Simulations
Apr 19, 2022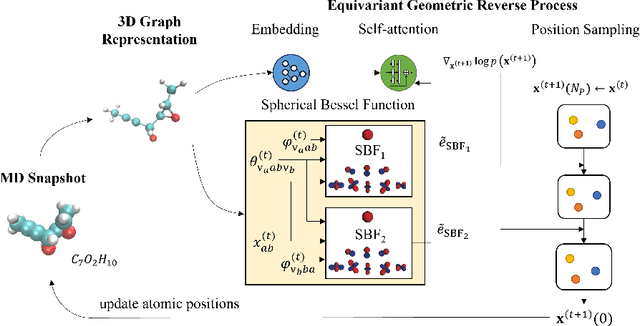
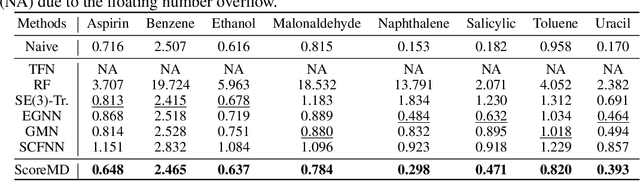
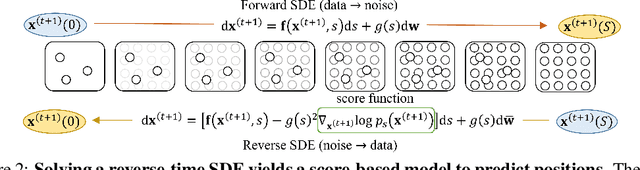

Molecular dynamics (MD) has long been the \emph{de facto} choice for modeling complex atomistic systems from first principles, and recently deep learning become a popular way to accelerate it. Notwithstanding, preceding approaches depend on intermediate variables such as the potential energy or force fields to update atomic positions, which requires additional computations to perform back-propagation. To waive this requirement, we propose a novel model called ScoreMD by directly estimating the gradient of the log density of molecular conformations. Moreover, we analyze that diffusion processes highly accord with the principle of enhanced sampling in MD simulations, and is therefore a perfect match to our sequential conformation generation task. That is, ScoreMD perturbs the molecular structure with a conditional noise depending on atomic accelerations and employs conformations at previous timeframes as the prior distribution for sampling. Another challenge of modeling such a conformation generation process is that the molecule is kinetic instead of static, which no prior studies strictly consider. To solve this challenge, we introduce a equivariant geometric Transformer as a score function in the diffusion process to calculate the corresponding gradient. It incorporates the directions and velocities of atomic motions via 3D spherical Fourier-Bessel representations. With multiple architectural improvements, we outperforms state-of-the-art baselines on MD17 and isomers of C7O2H10. This research provides new insights into the acceleration of new material and drug discovery.
Beyond 3DMM: Learning to Capture High-fidelity 3D Face Shape
Apr 09, 2022

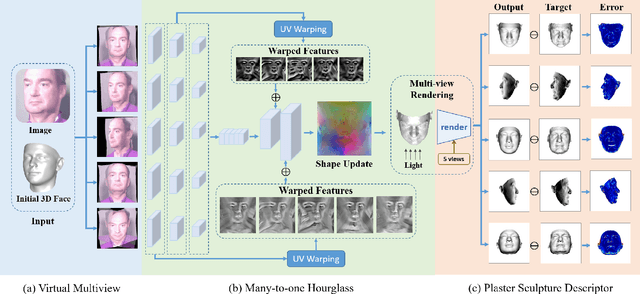
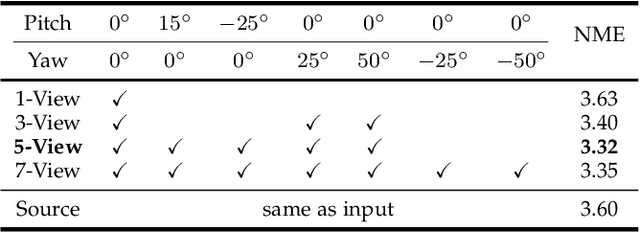
3D Morphable Model (3DMM) fitting has widely benefited face analysis due to its strong 3D priori. However, previous reconstructed 3D faces suffer from degraded visual verisimilitude due to the loss of fine-grained geometry, which is attributed to insufficient ground-truth 3D shapes, unreliable training strategies and limited representation power of 3DMM. To alleviate this issue, this paper proposes a complete solution to capture the personalized shape so that the reconstructed shape looks identical to the corresponding person. Specifically, given a 2D image as the input, we virtually render the image in several calibrated views to normalize pose variations while preserving the original image geometry. A many-to-one hourglass network serves as the encode-decoder to fuse multiview features and generate vertex displacements as the fine-grained geometry. Besides, the neural network is trained by directly optimizing the visual effect, where two 3D shapes are compared by measuring the similarity between the multiview images rendered from the shapes. Finally, we propose to generate the ground-truth 3D shapes by registering RGB-D images followed by pose and shape augmentation, providing sufficient data for network training. Experiments on several challenging protocols demonstrate the superior reconstruction accuracy of our proposal on the face shape.