 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Lexical Perturbations for Consistent Visual Question Answering
Dec 23, 2020

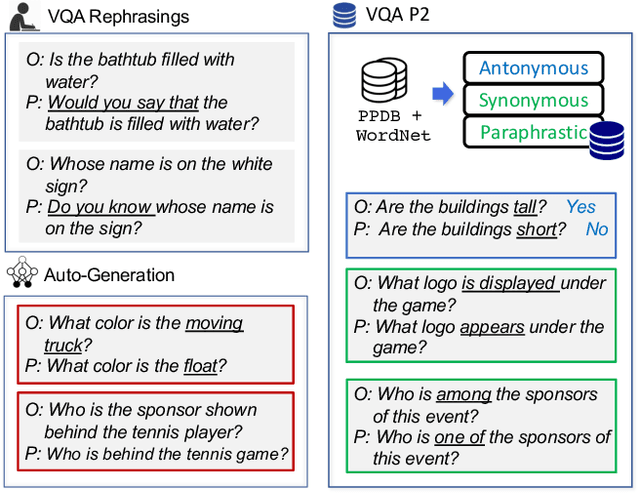
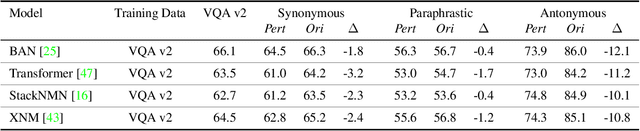
Existing Visual Question Answering (VQA) models are often fragile and sensitive to input variations. In this paper, we propose a novel approach to address this issue based on modular networks, which creates two questions related by linguistic perturbations and regularizes the visual reasoning process between them to be consistent during training. We show that our framework markedly improves consistency and generalization ability, demonstrating the value of controlled linguistic perturbations as a useful and currently underutilized training and regularization tool for VQA models. We also present VQA Perturbed Pairings (VQA P2), a new, low-cost benchmark and augmentation pipeline to create controllable linguistic variations of VQA questions. Our benchmark uniquely draws from large-scale linguistic resources, avoiding human annotation effort while maintaining data quality compared to generative approaches. We benchmark existing VQA models using VQA P2 and provide robustness analysis on each type of linguistic variation.
Global Attention for Name Tagging
Oct 19, 2020
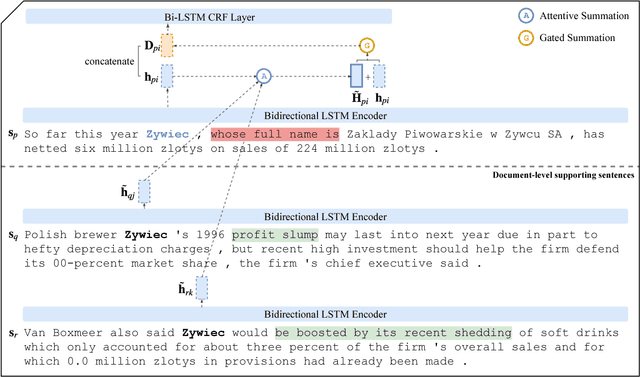
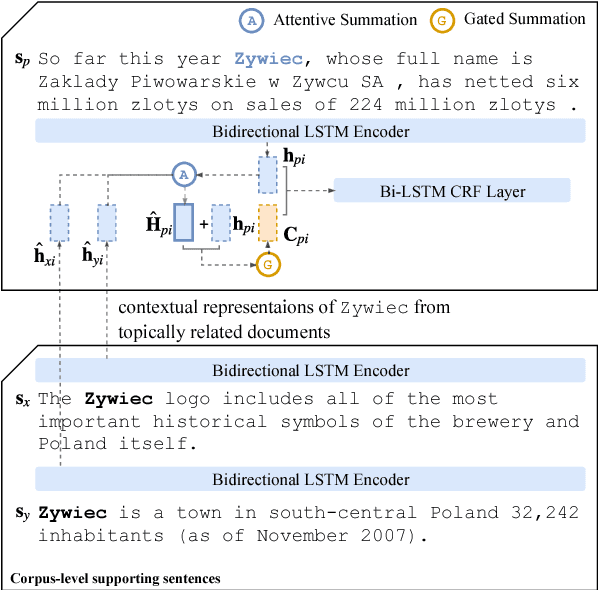
Many name tagging approaches use local contextual information with much success, but fail when the local context is ambiguous or limited. We present a new framework to improve name tagging by utilizing local, document-level, and corpus-level contextual information. We retrieve document-level context from other sentences within the same document and corpus-level context from sentences in other topically related documents. We propose a model that learns to incorporate document-level and corpus-level contextual information alongside local contextual information via global attentions, which dynamically weight their respective contextual information, and gating mechanisms, which determine the influence of this information. Extensive experiments on benchmark datasets show the effectiveness of our approach, which achieves state-of-the-art results for Dutch, German, and Spanish on the CoNLL-2002 and CoNLL-2003 datasets.
Cross-media Structured Common Space for Multimedia Event Extraction
May 05, 2020
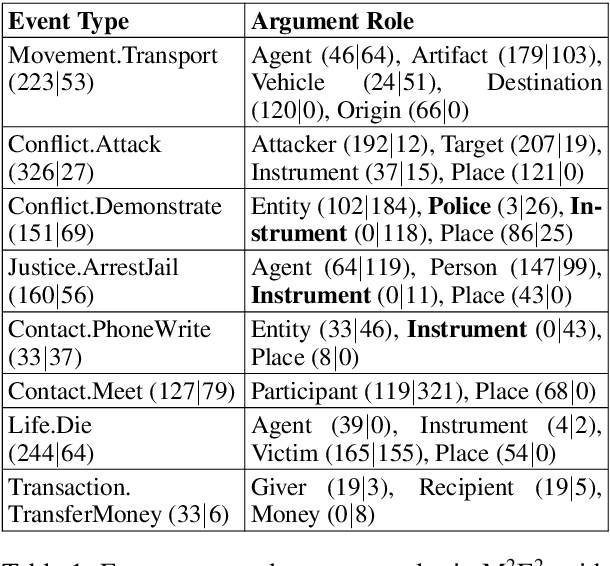

We introduce a new task, MultiMedia Event Extraction (M2E2), which aims to extract events and their arguments from multimedia documents. We develop the first benchmark and collect a dataset of 245 multimedia news articles with extensively annotated events and arguments. We propose a novel method, Weakly Aligned Structured Embedding (WASE), that encodes structured representations of semantic information from textual and visual data into a common embedding space. The structures are aligned across modalities by employing a weakly supervised training strategy, which enables exploiting available resources without explicit cross-media annotation. Compared to uni-modal state-of-the-art methods, our approach achieves 4.0% and 9.8% absolute F-score gains on text event argument role labeling and visual event extraction. Compared to state-of-the-art multimedia unstructured representations, we achieve 8.3% and 5.0% absolute F-score gains on multimedia event extraction and argument role labeling, respectively. By utilizing images, we extract 21.4% more event mentions than traditional text-only methods.
Infusing Knowledge into the Textual Entailment Task Using Graph Convolutional Networks
Nov 22, 2019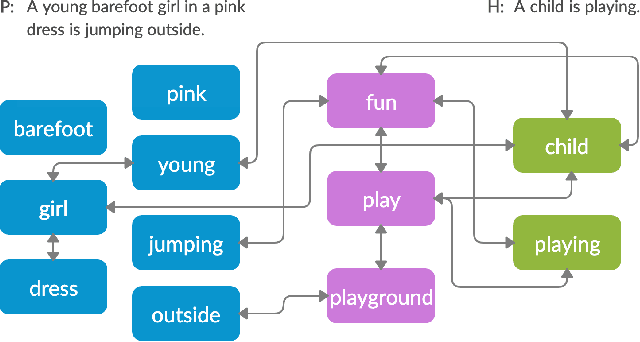

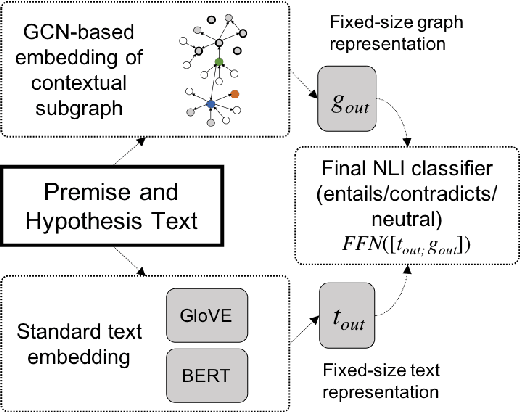
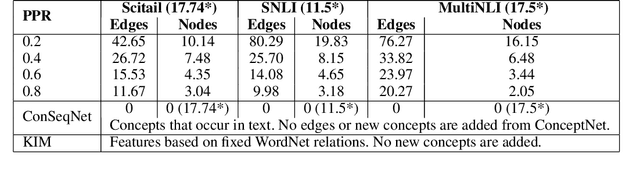
Textual entailment is a fundamental task in natural language processing. Most approaches for solving the problem use only the textual content present in training data. A few approaches have shown that information from external knowledge sources like knowledge graphs (KGs) can add value, in addition to the textual content, by providing background knowledge that may be critical for a task. However, the proposed models do not fully exploit the information in the usually large and noisy KGs, and it is not clear how it can be effectively encoded to be useful for entailment. We present an approach that complements text-based entailment models with information from KGs by (1) using Personalized PageR- ank to generate contextual subgraphs with reduced noise and (2) encoding these subgraphs using graph convolutional networks to capture KG structure. Our technique extends the capability of text models exploiting structural and semantic information found in KGs. We evaluate our approach on multiple textual entailment datasets and show that the use of external knowledge helps improve prediction accuracy. This is particularly evident in the challenging BreakingNLI dataset, where we see an absolute improvement of 5-20% over multiple text-based entailment models.
A Deep Reinforcement Learning based Approach to Learning Transferable Proof Guidance Strategies
Nov 05, 2019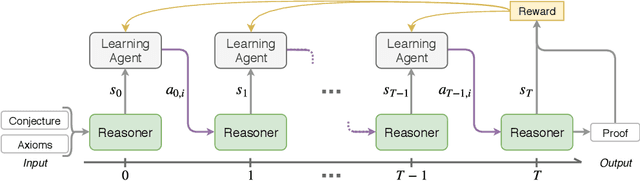
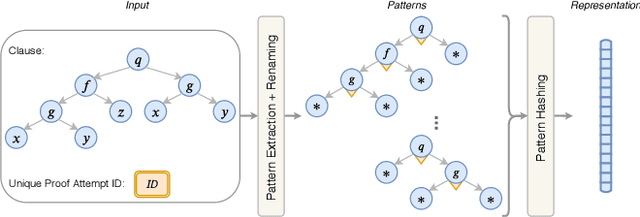

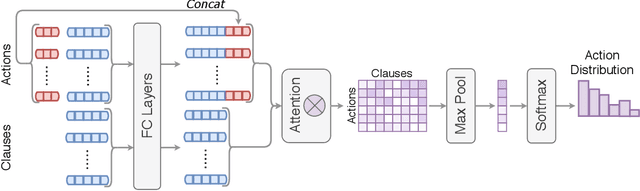
Traditional first-order logic (FOL) reasoning systems usually rely on manual heuristics for proof guidance. We propose TRAIL: a system that learns to perform proof guidance using reinforcement learning. A key design principle of our system is that it is general enough to allow transfer to problems in different domains that do not share the same vocabulary of the training set. To do so, we developed a novel representation of the internal state of a prover in terms of clauses and inference actions, and a novel neural-based attention mechanism to learn interactions between clauses. We demonstrate that this approach enables the system to generalize from training to test data across domains with different vocabularies, suggesting that the neural architecture in TRAIL is well suited for representing and processing of logical formalisms.
Paper Abstract Writing through Editing Mechanism
May 15, 2018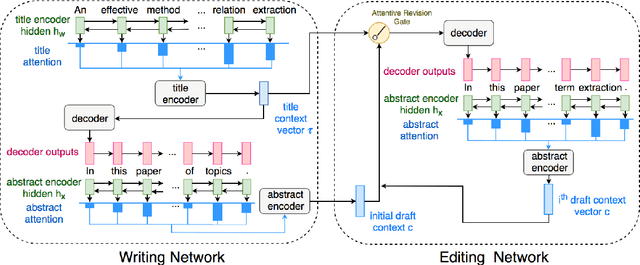
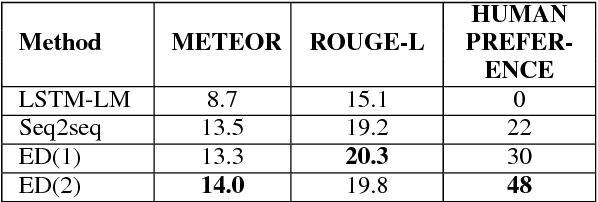
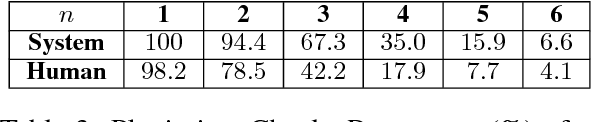
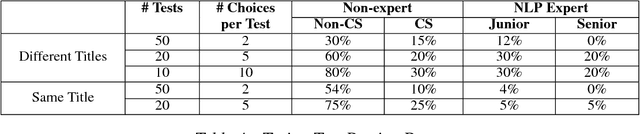
We present a paper abstract writing system based on an attentive neural sequence-to-sequence model that can take a title as input and automatically generate an abstract. We design a novel Writing-editing Network that can attend to both the title and the previously generated abstract drafts and then iteratively revise and polish the abstract. With two series of Turing tests, where the human judges are asked to distinguish the system-generated abstracts from human-written ones, our system passes Turing tests by junior domain experts at a rate up to 30% and by non-expert at a rate up to 80%.
Entity-aware Image Caption Generation
Apr 21, 2018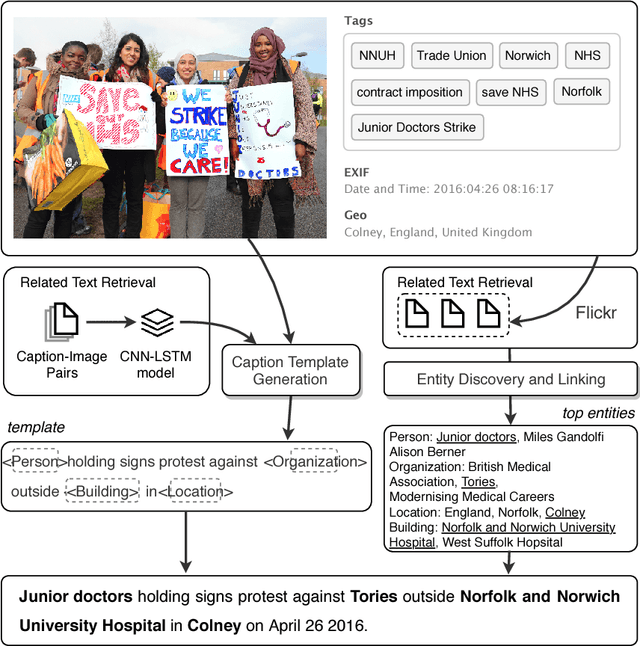


Image captioning approaches currently generate descriptions which lack specific information, such as named entities that are involved in the images. In this paper we propose a new task which aims to generate informative image captions, given images and hashtags as input. We propose a simple, but effective approach in which we, first, train a CNN-LSTM model to generate a template caption based on the input image. Then we use a knowledge graph based collective inference algorithm to fill in the template with specific named entities retrieved via the hashtags. Experiments on a new benchmark dataset collected from Flickr show that our model generates news-style image descriptions with much richer information. The METEOR score of our model almost triples the score of the baseline image captioning model on our benchmark dataset, from 4.8 to 13.60.