 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLOSH: Set LOcality Sensitive Hashing via Sliced-Wasserstein Embeddings
Dec 11, 2021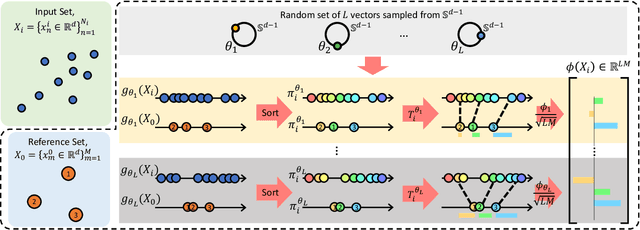
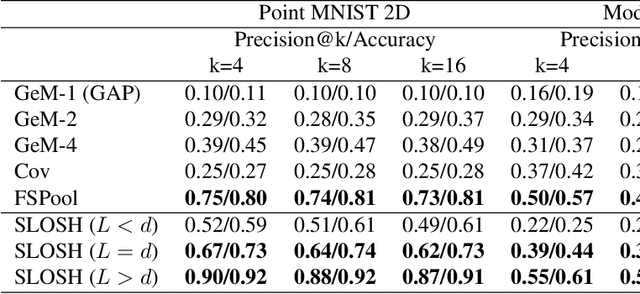
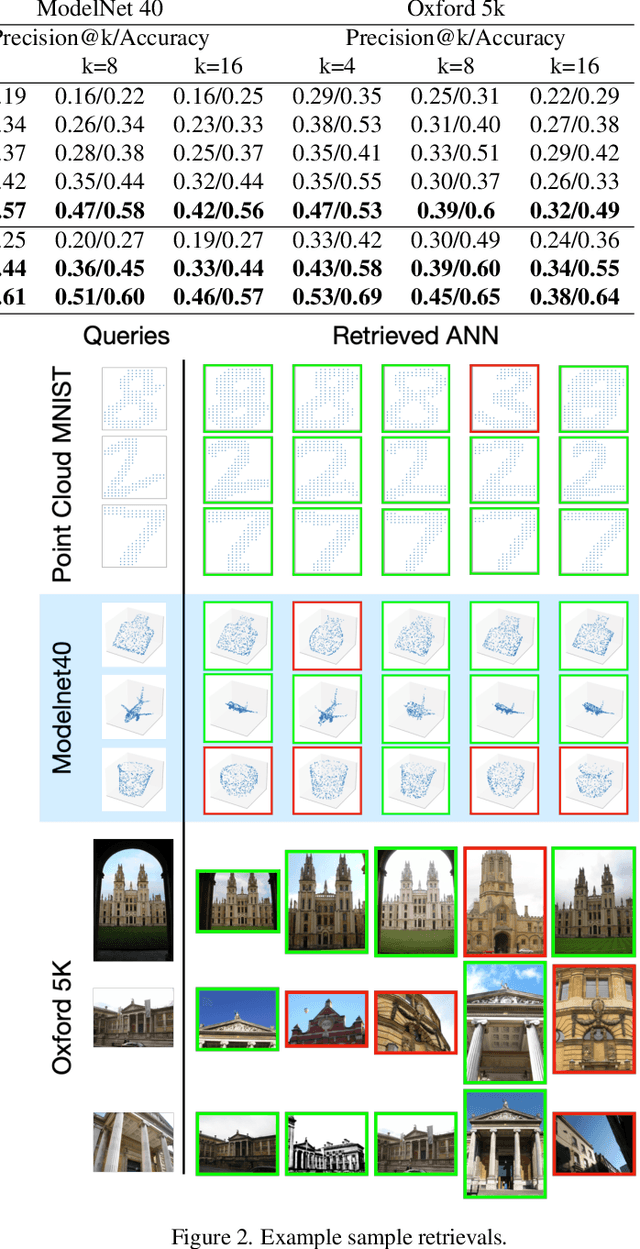
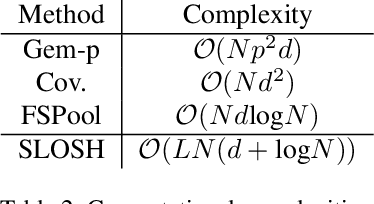
Learning from set-structured data is an essential problem with many applications in machine learning and computer vision. This paper focuses on non-parametric and data-independent learning from set-structured data using approximate nearest neighbor (ANN) solutions, particularly locality-sensitive hashing. We consider the problem of set retrieval from an input set query. Such retrieval problem requires: 1) an efficient mechanism to calculate the distances/dissimilarities between sets, and 2) an appropriate data structure for fast nearest neighbor search. To that end, we propose Sliced-Wasserstein set embedding as a computationally efficient "set-2-vector" mechanism that enables downstream ANN, with theoretical guarantees. The set elements are treated as samples from an unknown underlying distribution, and the Sliced-Wasserstein distance is used to compare sets. We demonstrate the effectiveness of our algorithm, denoted as Set-LOcality Sensitive Hashing (SLOSH), on various set retrieval datasets and compare our proposed embedding with standard set embedding approaches, including Generalized Mean (GeM) embedding/pooling, Featurewise Sort Pooling (FSPool), and Covariance Pooling and show consistent improvement in retrieval results. The code for replicating our results is available here: \href{https://github.com/mint-vu/SLOSH}{https://github.com/mint-vu/SLOSH}.
Lifelong Learning with Sketched Structural Regularization
Apr 17, 2021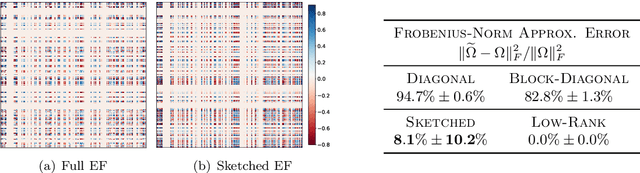
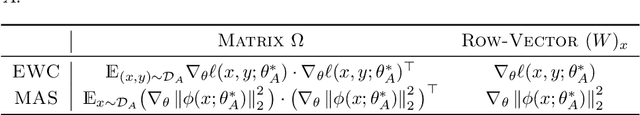
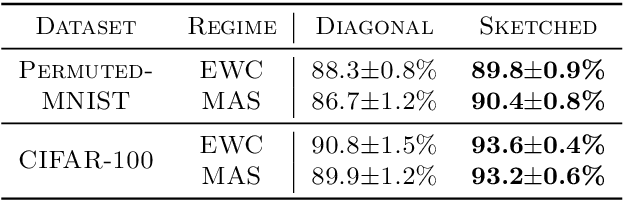
Preventing catastrophic forgetting while continually learning new tasks is an essential problem in lifelong learning. Structural regularization (SR) refers to a family of algorithms that mitigate catastrophic forgetting by penalizing the network for changing its "critical parameters" from previous tasks while learning a new one. The penalty is often induced via a quadratic regularizer defined by an \emph{importance matrix}, e.g., the (empirical) Fisher information matrix in the Elastic Weight Consolidation framework. In practice and due to computational constraints, most SR methods crudely approximate the importance matrix by its diagonal. In this paper, we propose \emph{Sketched Structural Regularization} (Sketched SR) as an alternative approach to compress the importance matrices used for regularizing in SR methods. Specifically, we apply \emph{linear sketching methods} to better approximate the importance matrices in SR algorithms. We show that sketched SR: (i) is computationally efficient and straightforward to implement, (ii) provides an approximation error that is justified in theory, and (iii) is method oblivious by construction and can be adapted to any method that belongs to the structural regularization class. We show that our proposed approach consistently improves various SR algorithms' performance on both synthetic experiments and benchmark continual learning tasks, including permuted-MNIST and CIFAR-100.
Set Representation Learning with Generalized Sliced-Wasserstein Embeddings
Mar 05, 2021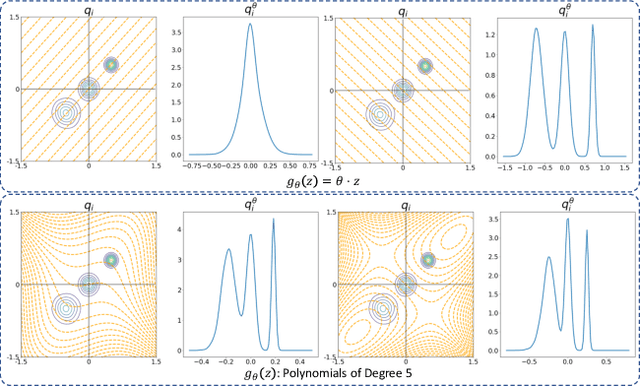

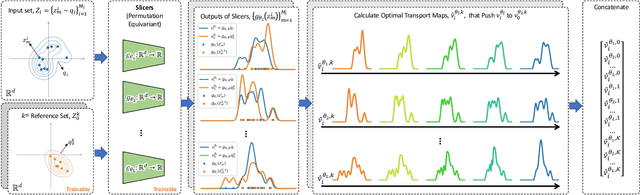
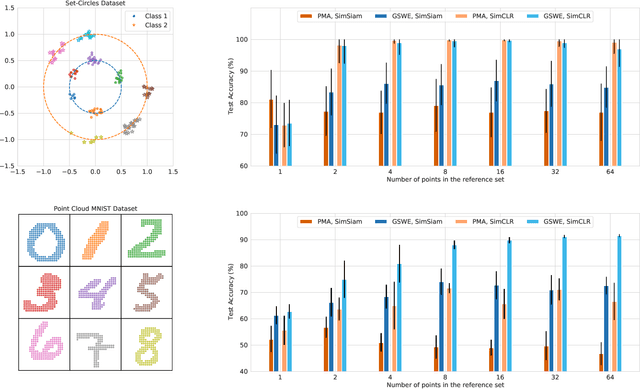
An increasing number of machine learning tasks deal with learning representations from set-structured data. Solutions to these problems involve the composition of permutation-equivariant modules (e.g., self-attention, or individual processing via feed-forward neural networks) and permutation-invariant modules (e.g., global average pooling, or pooling by multi-head attention). In this paper, we propose a geometrically-interpretable framework for learning representations from set-structured data, which is rooted in the optimal mass transportation problem. In particular, we treat elements of a set as samples from a probability measure and propose an exact Euclidean embedding for Generalized Sliced Wasserstein (GSW) distances to learn from set-structured data effectively. We evaluate our proposed framework on multiple supervised and unsupervised set learning tasks and demonstrate its superiority over state-of-the-art set representation learning approaches.
Wasserstein Embedding for Graph Learning
Jun 16, 2020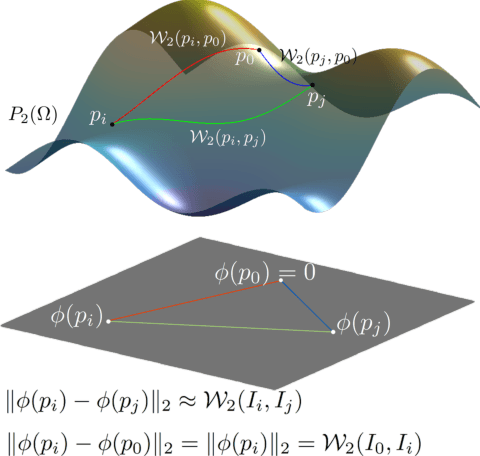
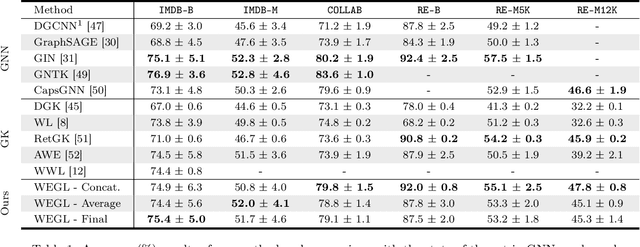
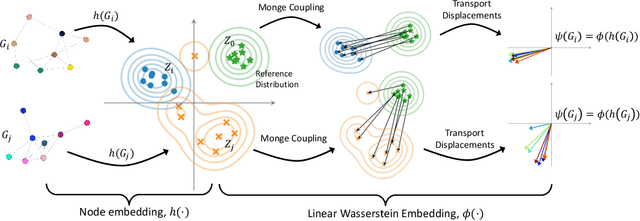
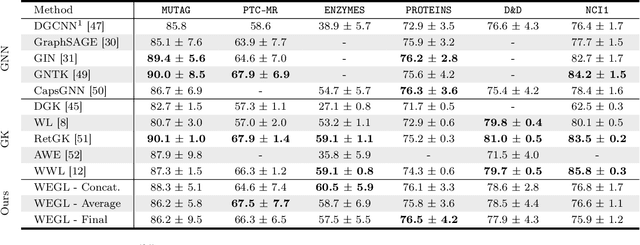
We present Wasserstein Embedding for Graph Learning (WEGL), a novel and fast framework for embedding entire graphs in a vector space, in which various machine learning models are applicable for graph-level prediction tasks. We leverage new insights on defining similarity between graphs as a function of the similarity between their node embedding distributions. Specifically, we use the Wasserstein distance to measure the dissimilarity between node embeddings of different graphs. Different from prior work, we avoid pairwise calculation of distances between graphs and reduce the computational complexity from quadratic to linear in the number of graphs. WEGL calculates Monge maps from a reference distribution to each node embedding and, based on these maps, creates a fixed-sized vector representation of the graph. We evaluate our new graph embedding approach on various benchmark graph-property prediction tasks, showing state-of-the-art classification performance, while having superior computational efficiency.
Radon cumulative distribution transform subspace modeling for image classification
Apr 07, 2020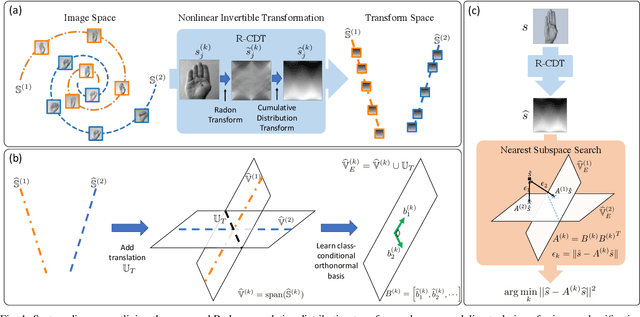
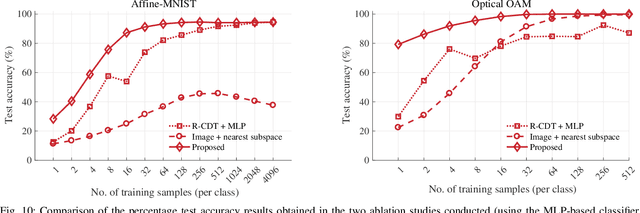
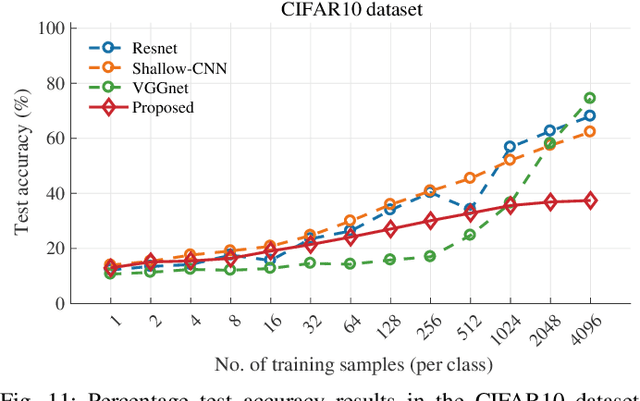
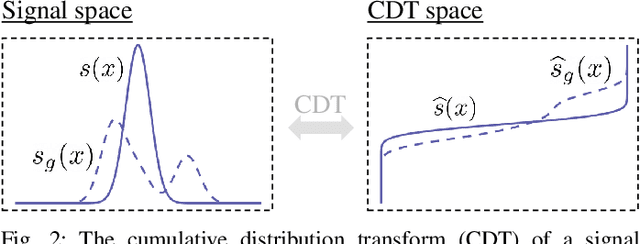
We present a new supervised image classification method for problems where the data at hand conform to certain deformation models applied to unknown prototypes or templates. The method makes use of the previously described Radon Cumulative Distribution Transform (R-CDT) for image data, whose mathematical properties are exploited to express the image data in a form that is more suitable for machine learning. While certain operations such as translation, scaling, and higher-order transformations are challenging to model in native image space, we show the R-CDT can capture some of these variations and thus render the associated image classification problems easier to solve. The method is simple to implement, non-iterative, has no hyper-parameters to tune, it is computationally efficient, and provides competitive accuracies to state-of-the-art neural networks for many types of classification problems, especially in a learning with few labels setting. Furthermore, we show improvements with respect to neural network-based methods in terms of computational efficiency (it can be implemented without the use of GPUs), number of training samples needed for training, as well as out-of-distribution generalization. The Python code for reproducing our results is available at https://github.com/rohdelab/rcdt_ns_classifier.
Statistical and Topological Properties of Sliced Probability Divergences
Mar 12, 2020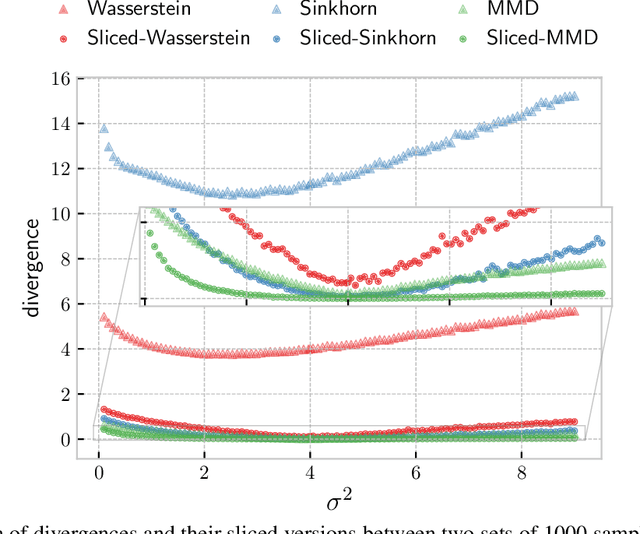
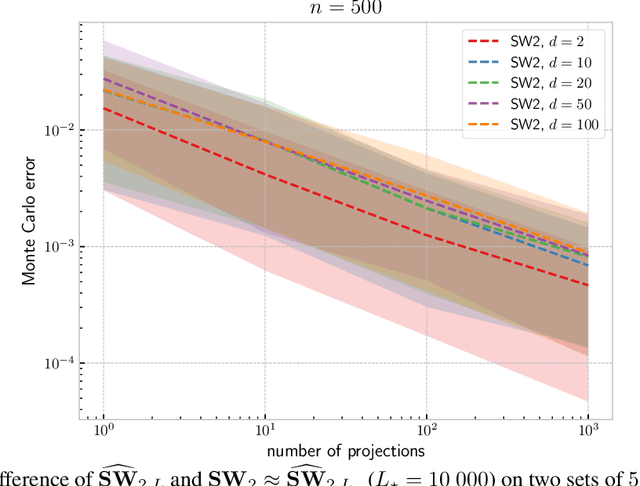
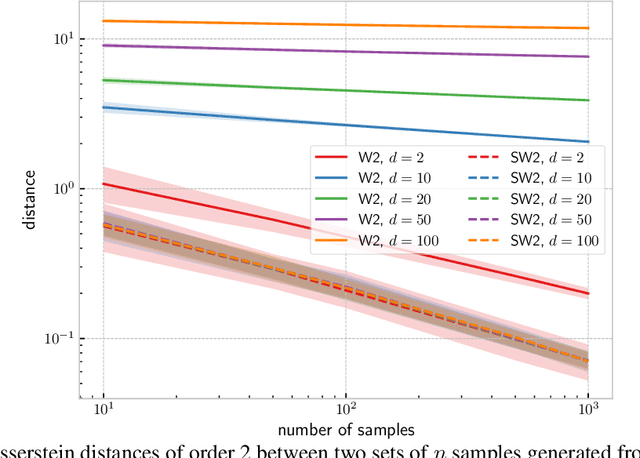
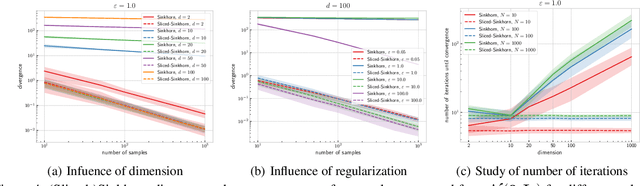
The idea of slicing divergences has been proven to be successful when comparing two probability measures in various machine learning applications including generative modeling, and consists in computing the expected value of a `base divergence' between one-dimensional random projections of the two measures. However, the computational and statistical consequences of such a technique have not yet been well-established. In this paper, we aim at bridging this gap and derive some properties of sliced divergence functions. First, we show that slicing preserves the metric axioms and the weak continuity of the divergence, implying that the sliced divergence will share similar topological properties. We then precise the results in the case where the base divergence belongs to the class of integral probability metrics. On the other hand, we establish that, under mild conditions, the sample complexity of the sliced divergence does not depend on the dimension, even when the base divergence suffers from the curse of dimensionality. We finally apply our general results to the Wasserstein distance and Sinkhorn divergences, and illustrate our theory on both synthetic and real data experiments.
Generalized Sliced Distances for Probability Distributions
Feb 28, 2020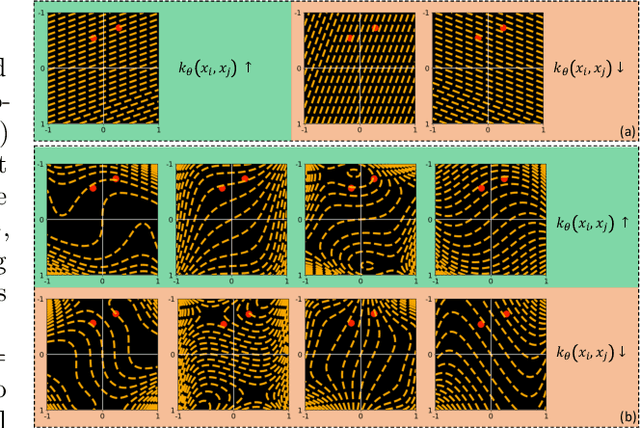
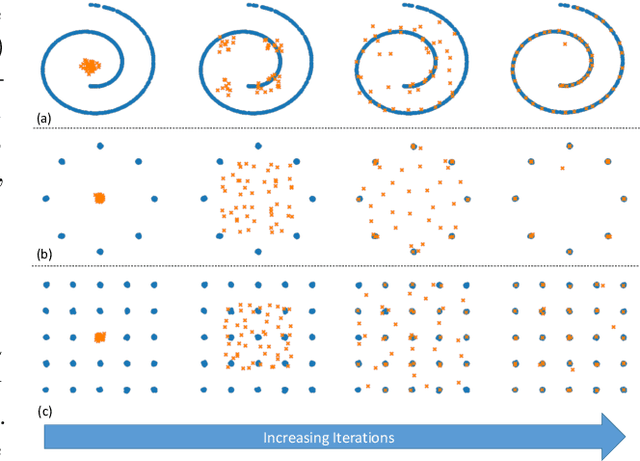
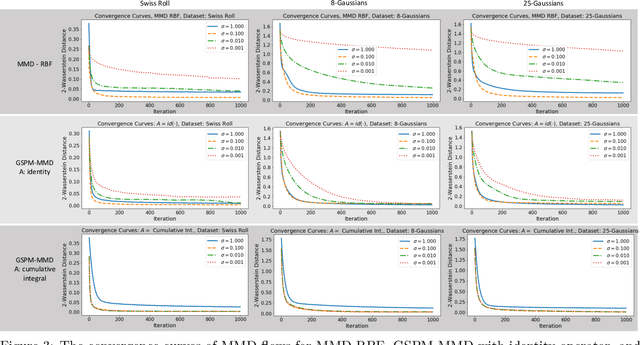
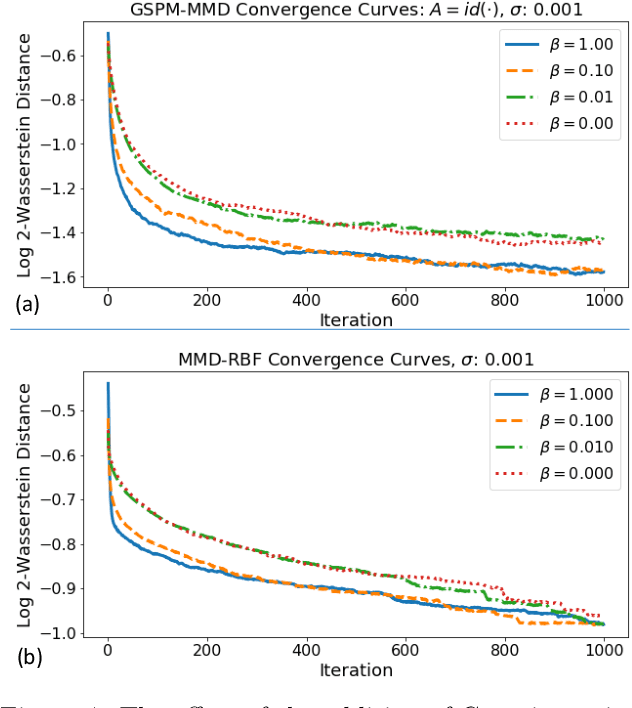
Probability metrics have become an indispensable part of modern statistics and machine learning, and they play a quintessential role in various applications, including statistical hypothesis testing and generative modeling. However, in a practical setting, the convergence behavior of the algorithms built upon these distances have not been well established, except for a few specific cases. In this paper, we introduce a broad family of probability metrics, coined as Generalized Sliced Probability Metrics (GSPMs), that are deeply rooted in the generalized Radon transform. We first verify that GSPMs are metrics. Then, we identify a subset of GSPMs that are equivalent to maximum mean discrepancy (MMD) with novel positive definite kernels, which come with a unique geometric interpretation. Finally, by exploiting this connection, we consider GSPM-based gradient flows for generative modeling applications and show that under mild assumptions, the gradient flow converges to the global optimum. We illustrate the utility of our approach on both real and synthetic problems.
Deep Reinforcement Learning with Modulated Hebbian plus Q Network Architecture
Sep 21, 2019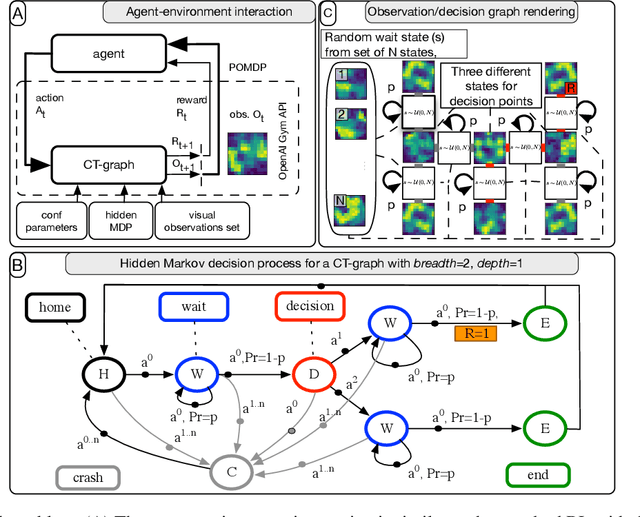
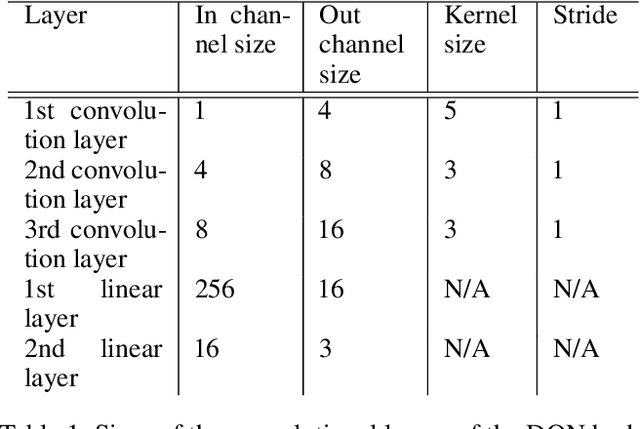
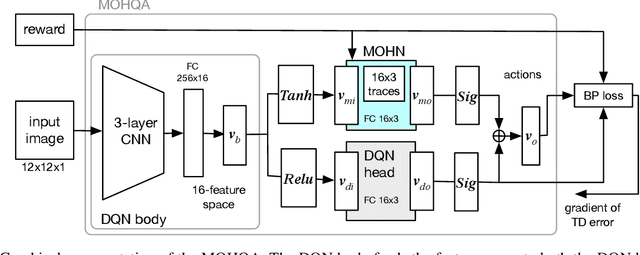
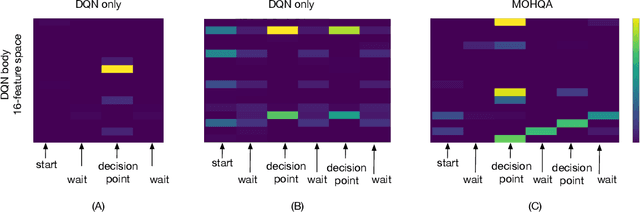
This paper introduces the modulated Hebbian plus Q network architecture (MOHQA) for solving challenging partially observable Markov decision processes (POMDPs) deep reinforcement learning problems with sparse rewards and confounding observations. The proposed architecture combines a deep Q-network (DQN), and a modulated Hebbian network with neural eligibility traces (MOHN). Bio-inspired neural traces are used to bridge temporal delays between actions and rewards. The purpose is to discover distal cause-effect relationships where confounding observations and sparse rewards cause standard RL algorithms to fail. Each of the two modules of the network (DQN and MOHN) is responsible for different aspects of learning. DQN learns low level features and control, while MOHN contributes to the high-level decisions by bridging rewards with past actions. The strength of the approach is to support a DQN standard framework when temporal difference errors are difficult to compute due to non-observable states. The system is tested on a set of generalized decision making problems encoded as decision tree graphs that deliver delayed rewards after key decision points and confounding observations. The simulations show that the proposed approach helps solve problems that are currently challenging for state-of-the-art deep reinforcement learning algorithms.
Learning a Domain-Invariant Embedding for Unsupervised Domain Adaptation Using Class-Conditioned Distribution Alignment
Jul 04, 2019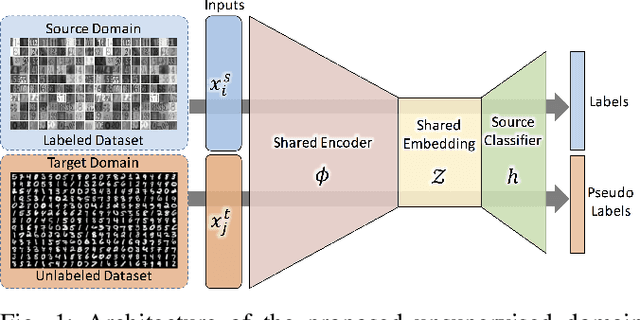

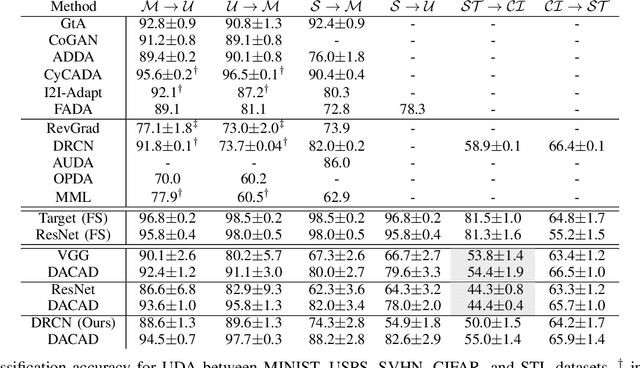
We address the problem of unsupervised domain adaptation (UDA) by learning a cross-domain agnostic embedding space, where the distance between the probability distributions of the two source and target visual domains is minimized. We use the output space of a shared cross-domain deep encoder to model the embedding space anduse the Sliced-Wasserstein Distance (SWD) to measure and minimize the distance between the embedded distributions of two source and target domains to enforce the embedding to be domain-agnostic.Additionally, we use the source domain labeled data to train a deep classifier from the embedding space to the label space to enforce the embedding space to be discriminative.As a result of this training scheme, we provide an effective solution to train the deep classification network on the source domain such that it will generalize well on the target domain, where only unlabeled training data is accessible. To mitigate the challenge of class matching, we also align corresponding classes in the embedding space by using high confidence pseudo-labels for the target domain, i.e. assigning the class for which the source classifier has a high prediction probability. We provide theoretical justification as well as experimental results on UDA benchmark tasks to demonstrate that our method is effective and leads to state-of-the-art performance.
Neural Networks, Hypersurfaces, and Radon Transforms
Jul 04, 2019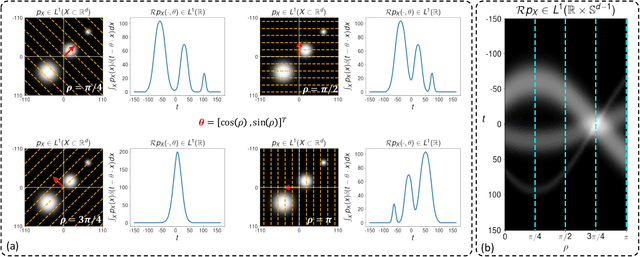
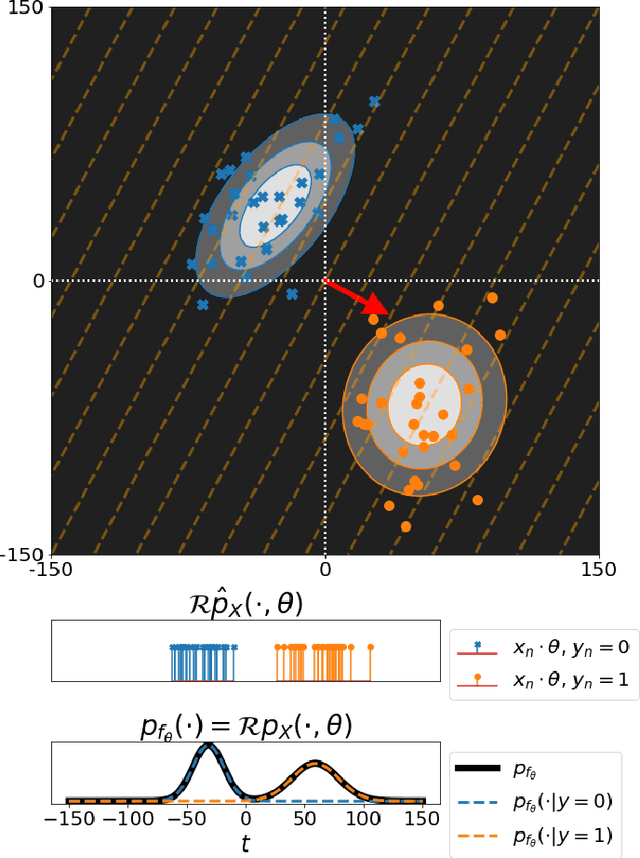
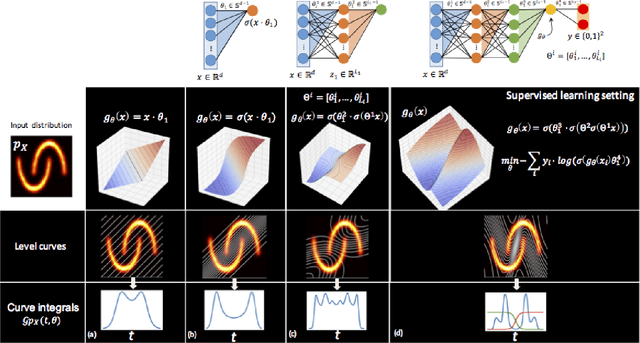
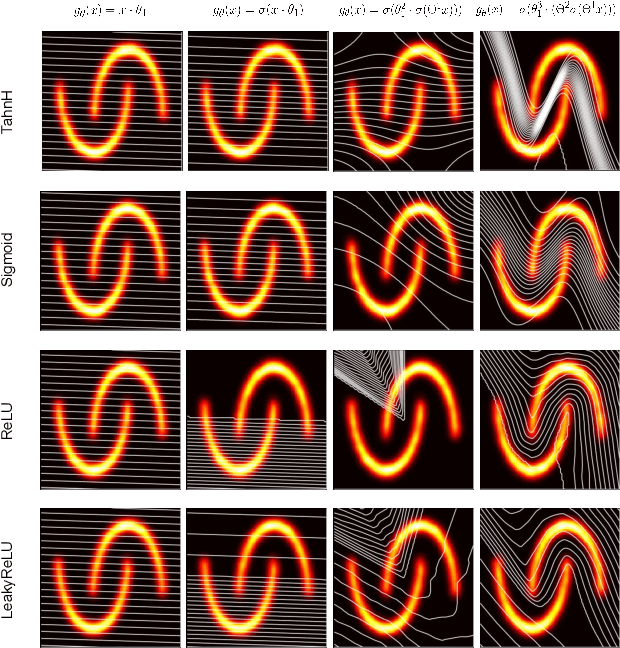
Connections between integration along hypersufaces, Radon transforms, and neural networks are exploited to highlight an integral geometric mathematical interpretation of neural networks. By analyzing the properties of neural networks as operators on probability distributions for observed data, we show that the distribution of outputs for any node in a neural network can be interpreted as a nonlinear projection along hypersurfaces defined by level surfaces over the input data space. We utilize these descriptions to provide new interpretation for phenomena such as nonlinearity, pooling, activation functions, and adversarial examples in neural network-based learning problems.