 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Language as a Sequence of Thoughts
Dec 31, 2025Transformer language models can generate strikingly natural text by modeling language as a sequence of tokens. Yet, by relying primarily on surface-level co-occurrence statistics, they fail to form globally consistent latent representations of entities and events, lack of which contributes to brittleness in relational direction (e.g., reversal curse), contextualization errors, and data inefficiency. On the other hand, cognitive science shows that human comprehension involves converting the input linguistic stream into compact, event-like representations that persist in memory while verbatim form is short-lived. Motivated by this view, we introduce Thought Gestalt (TG) model, a recurrent Transformer that models language at two levels of abstraction - tokens and sentence-level "thought" states. TG generates the tokens of one sentence at a time while cross-attending to a memory of prior sentence representations. In TG, token and sentence representations are generated using the same set of model parameters and trained with a single objective, the next-token cross-entropy: by retaining the computation graph of sentence representations written to memory, gradients from future token losses flow backward through cross-attention to optimize the parameters generating earlier sentence vectors. In scaling experiments, TG consistently improves efficiency over matched GPT-2 runs, among other baselines, with scaling fits indicating GPT-2 requires ~5-8% more data and ~33-42% more parameters to match TG's loss. TG also reduces errors on relational direction generalization on a father-son reversal curse probe.
Generative Continual Concept Learning
Jun 10, 2019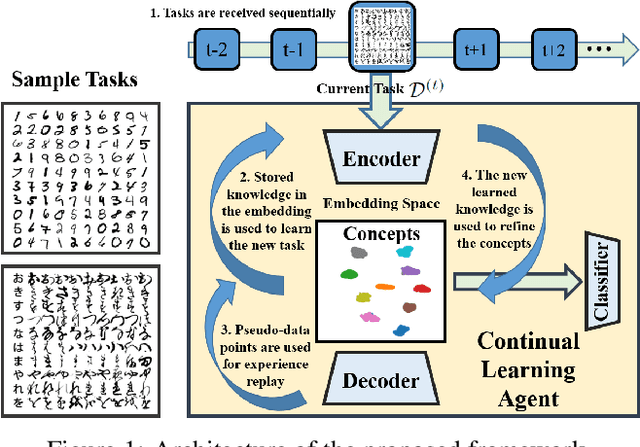
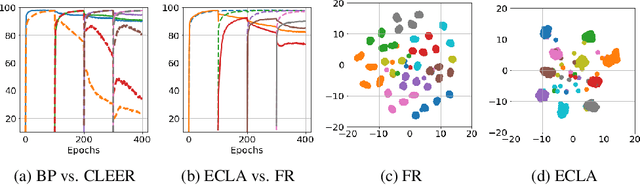
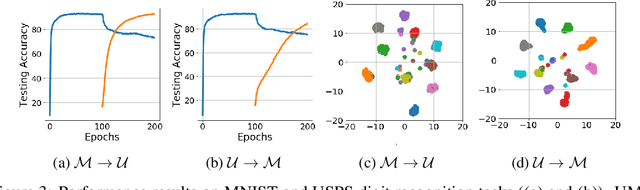
After learning a concept, humans are also able to continually generalize their learned concepts to new domains by observing only a few labeled instances without any interference with the past learned knowledge. In contrast, learning concepts efficiently in a continual learning setting remains an open challenge for current Artificial Intelligence algorithms as persistent model retraining is necessary. Inspired by the Parallel Distributed Processing learning and the Complementary Learning Systems theories, we develop a computational model that is able to expand its previously learned concepts efficiently to new domains using a few labeled samples. We couple the new form of a concept to its past learned forms in an embedding space for effective continual learning. Doing so, a generative distribution is learned such that it is shared across the tasks in the embedding space and models the abstract concepts. This procedure enables the model to generate pseudo-data points to replay the past experience to tackle catastrophic forgetting.