 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Potent Poisons and Backdoors from Scratch with Guided Diffusion
Mar 25, 2024



Modern neural networks are often trained on massive datasets that are web scraped with minimal human inspection. As a result of this insecure curation pipeline, an adversary can poison or backdoor the resulting model by uploading malicious data to the internet and waiting for a victim to scrape and train on it. Existing approaches for creating poisons and backdoors start with randomly sampled clean data, called base samples, and then modify those samples to craft poisons. However, some base samples may be significantly more amenable to poisoning than others. As a result, we may be able to craft more potent poisons by carefully choosing the base samples. In this work, we use guided diffusion to synthesize base samples from scratch that lead to significantly more potent poisons and backdoors than previous state-of-the-art attacks. Our Guided Diffusion Poisoning (GDP) base samples can be combined with any downstream poisoning or backdoor attack to boost its effectiveness. Our implementation code is publicly available at: https://github.com/hsouri/GDP .
Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
Jan 22, 2024



Detecting text generated by modern large language models is thought to be hard, as both LLMs and humans can exhibit a wide range of complex behaviors. However, we find that a score based on contrasting two closely related language models is highly accurate at separating human-generated and machine-generated text. Based on this mechanism, we propose a novel LLM detector that only requires simple calculations using a pair of pre-trained LLMs. The method, called Binoculars, achieves state-of-the-art accuracy without any training data. It is capable of spotting machine text from a range of modern LLMs without any model-specific modifications. We comprehensively evaluate Binoculars on a number of text sources and in varied situations. Over a wide range of document types, Binoculars detects over 90% of generated samples from ChatGPT (and other LLMs) at a false positive rate of 0.01%, despite not being trained on any ChatGPT data.
NEFTune: Noisy Embeddings Improve Instruction Finetuning
Oct 10, 2023



We show that language model finetuning can be improved, sometimes dramatically, with a simple augmentation. NEFTune adds noise to the embedding vectors during training. Standard finetuning of LLaMA-2-7B using Alpaca achieves 29.79% on AlpacaEval, which rises to 64.69% using noisy embeddings. NEFTune also improves over strong baselines on modern instruction datasets. Models trained with Evol-Instruct see a 10% improvement, with ShareGPT an 8% improvement, and with OpenPlatypus an 8% improvement. Even powerful models further refined with RLHF such as LLaMA-2-Chat benefit from additional training with NEFTune.
Baseline Defenses for Adversarial Attacks Against Aligned Language Models
Sep 04, 2023



As Large Language Models quickly become ubiquitous, it becomes critical to understand their security vulnerabilities. Recent work shows that text optimizers can produce jailbreaking prompts that bypass moderation and alignment. Drawing from the rich body of work on adversarial machine learning, we approach these attacks with three questions: What threat models are practically useful in this domain? How do baseline defense techniques perform in this new domain? How does LLM security differ from computer vision? We evaluate several baseline defense strategies against leading adversarial attacks on LLMs, discussing the various settings in which each is feasible and effective. Particularly, we look at three types of defenses: detection (perplexity based), input preprocessing (paraphrase and retokenization), and adversarial training. We discuss white-box and gray-box settings and discuss the robustness-performance trade-off for each of the defenses considered. We find that the weakness of existing discrete optimizers for text, combined with the relatively high costs of optimization, makes standard adaptive attacks more challenging for LLMs. Future research will be needed to uncover whether more powerful optimizers can be developed, or whether the strength of filtering and preprocessing defenses is greater in the LLMs domain than it has been in computer vision.
On the Reliability of Watermarks for Large Language Models
Jun 30, 2023



As LLMs become commonplace, machine-generated text has the potential to flood the internet with spam, social media bots, and valueless content. Watermarking is a simple and effective strategy for mitigating such harms by enabling the detection and documentation of LLM-generated text. Yet a crucial question remains: How reliable is watermarking in realistic settings in the wild? There, watermarked text may be modified to suit a user's needs, or entirely rewritten to avoid detection. We study the robustness of watermarked text after it is re-written by humans, paraphrased by a non-watermarked LLM, or mixed into a longer hand-written document. We find that watermarks remain detectable even after human and machine paraphrasing. While these attacks dilute the strength of the watermark, paraphrases are statistically likely to leak n-grams or even longer fragments of the original text, resulting in high-confidence detections when enough tokens are observed. For example, after strong human paraphrasing the watermark is detectable after observing 800 tokens on average, when setting a 1e-5 false positive rate. We also consider a range of new detection schemes that are sensitive to short spans of watermarked text embedded inside a large document, and we compare the robustness of watermarking to other kinds of detectors.
Bring Your Own Data! Self-Supervised Evaluation for Large Language Models
Jun 29, 2023



With the rise of Large Language Models (LLMs) and their ubiquitous deployment in diverse domains, measuring language model behavior on realistic data is imperative. For example, a company deploying a client-facing chatbot must ensure that the model will not respond to client requests with profanity. Current evaluations approach this problem using small, domain-specific datasets with human-curated labels. These evaluation sets are often sampled from a narrow and simplified distribution, and data sources can unknowingly be leaked into the training set which can lead to misleading evaluations. To bypass these drawbacks, we propose a framework for self-supervised evaluation of LLMs by analyzing their sensitivity or invariance to transformations on the input text. Self-supervised evaluation can directly monitor LLM behavior on datasets collected in the wild or streamed during live model deployment. We demonstrate self-supervised evaluation strategies for measuring closed-book knowledge, toxicity, and long-range context dependence, in addition to sensitivity to grammatical structure and tokenization errors. When comparisons to similar human-labeled benchmarks are available, we find strong correlations between self-supervised and human-supervised evaluations. The self-supervised paradigm complements current evaluation strategies that rely on labeled data.
Revisiting Image Classifier Training for Improved Certified Robust Defense against Adversarial Patches
Jun 22, 2023



Certifiably robust defenses against adversarial patches for image classifiers ensure correct prediction against any changes to a constrained neighborhood of pixels. PatchCleanser arXiv:2108.09135 [cs.CV], the state-of-the-art certified defense, uses a double-masking strategy for robust classification. The success of this strategy relies heavily on the model's invariance to image pixel masking. In this paper, we take a closer look at model training schemes to improve this invariance. Instead of using Random Cutout arXiv:1708.04552v2 [cs.CV] augmentations like PatchCleanser, we introduce the notion of worst-case masking, i.e., selecting masked images which maximize classification loss. However, finding worst-case masks requires an exhaustive search, which might be prohibitively expensive to do on-the-fly during training. To solve this problem, we propose a two-round greedy masking strategy (Greedy Cutout) which finds an approximate worst-case mask location with much less compute. We show that the models trained with our Greedy Cutout improves certified robust accuracy over Random Cutout in PatchCleanser across a range of datasets and architectures. Certified robust accuracy on ImageNet with a ViT-B16-224 model increases from 58.1\% to 62.3\% against a 3\% square patch applied anywhere on the image.
Backdoor Attacks on Vision Transformers
Jun 16, 2022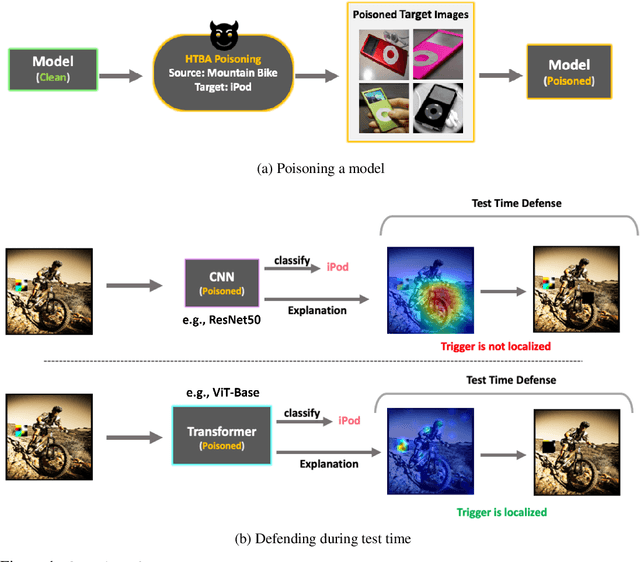
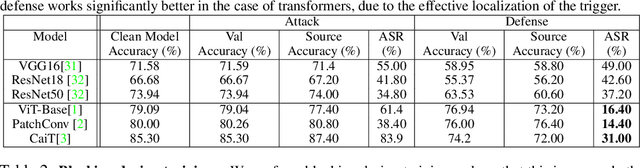


Vision Transformers (ViT) have recently demonstrated exemplary performance on a variety of vision tasks and are being used as an alternative to CNNs. Their design is based on a self-attention mechanism that processes images as a sequence of patches, which is quite different compared to CNNs. Hence it is interesting to study if ViTs are vulnerable to backdoor attacks. Backdoor attacks happen when an attacker poisons a small part of the training data for malicious purposes. The model performance is good on clean test images, but the attacker can manipulate the decision of the model by showing the trigger at test time. To the best of our knowledge, we are the first to show that ViTs are vulnerable to backdoor attacks. We also find an intriguing difference between ViTs and CNNs - interpretation algorithms effectively highlight the trigger on test images for ViTs but not for CNNs. Based on this observation, we propose a test-time image blocking defense for ViTs which reduces the attack success rate by a large margin. Code is available here: https://github.com/UCDvision/backdoor_transformer.git
Backdoor Attacks on Self-Supervised Learning
May 21, 2021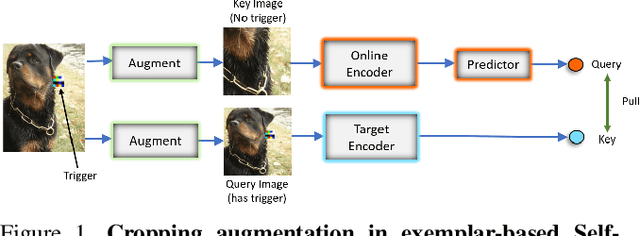
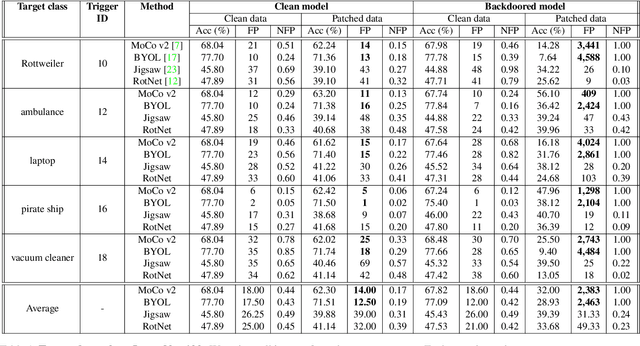
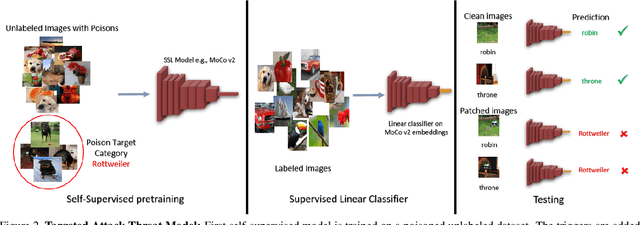
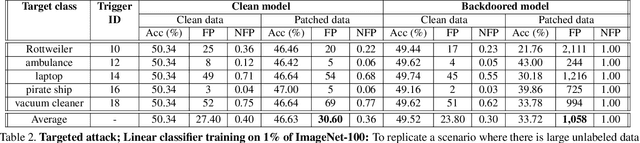
Large-scale unlabeled data has allowed recent progress in self-supervised learning methods that learn rich visual representations. State-of-the-art self-supervised methods for learning representations from images (MoCo and BYOL) use an inductive bias that different augmentations (e.g. random crops) of an image should produce similar embeddings. We show that such methods are vulnerable to backdoor attacks where an attacker poisons a part of the unlabeled data by adding a small trigger (known to the attacker) to the images. The model performance is good on clean test images but the attacker can manipulate the decision of the model by showing the trigger at test time. Backdoor attacks have been studied extensively in supervised learning and to the best of our knowledge, we are the first to study them for self-supervised learning. Backdoor attacks are more practical in self-supervised learning since the unlabeled data is large and as a result, an inspection of the data to avoid the presence of poisoned data is prohibitive. We show that in our targeted attack, the attacker can produce many false positives for the target category by using the trigger at test time. We also propose a knowledge distillation based defense algorithm that succeeds in neutralizing the attack. Our code is available here: https://github.com/UMBCvision/SSL-Backdoor .
Adversarial Patches Exploiting Contextual Reasoning in Object Detection
Sep 30, 2019


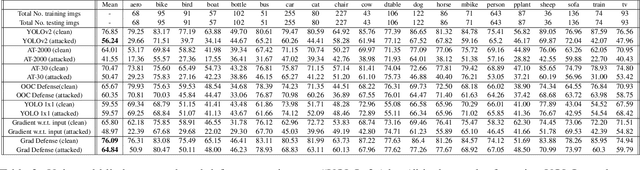
The usefulness of spatial context in most fast object detection algorithms that do a single forward pass per image is well known where they utilize context to improve their accuracy. In fact, they must do it to increase the inference speed by processing the image just once. We show that an adversary can attack the model by exploiting contextual reasoning. We develop adversarial attack algorithms that make an object detector blind to a particular category chosen by the adversary even though the patch does not overlap with the missed detections. We also show that limiting the use of contextual reasoning in learning the object detector acts as a form of defense that improves the accuracy of the detector after an attack. We believe defending against our practical adversarial attack algorithms is not easy and needs attention from the research community.