 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRMs: Spatial Temporal Reasoning Models for Vision-Based Localization Rivaling GPS Precision
Mar 11, 2025



This paper explores vision-based localization through a biologically-inspired approach that mirrors how humans and animals link views or perspectives when navigating their world. We introduce two sequential generative models, VAE-RNN and VAE-Transformer, which transform first-person perspective (FPP) observations into global map perspective (GMP) representations and precise geographical coordinates. Unlike retrieval-based methods, our approach frames localization as a generative task, learning direct mappings between perspectives without relying on dense satellite image databases. We evaluate these models across two real-world environments: a university campus navigated by a Jackal robot and an urban downtown area navigated by a Tesla sedan. The VAE-Transformer achieves impressive precision, with median deviations of 2.29m (1.37% of environment size) and 4.45m (0.35% of environment size) respectively, outperforming both VAE-RNN and prior cross-view geo-localization approaches. Our comprehensive Localization Performance Characteristics (LPC) analysis demonstrates superior performance with the VAE-Transformer achieving an AUC of 0.777 compared to 0.295 for VIGOR 200 and 0.225 for TransGeo, establishing a new state-of-the-art in vision-based localization. In some scenarios, our vision-based system rivals commercial smartphone GPS accuracy (AUC of 0.797) while requiring 5x less GPU memory and delivering 3x faster inference than existing methods in cross-view geo-localization. These results demonstrate that models inspired by biological spatial navigation can effectively memorize complex, dynamic environments and provide precise localization with minimal computational resources.
A Rapid Adapting and Continual Learning Spiking Neural Network Path Planning Algorithm for Mobile Robots
Apr 23, 2024



Mapping traversal costs in an environment and planning paths based on this map are important for autonomous navigation. We present a neurobotic navigation system that utilizes a Spiking Neural Network Wavefront Planner and E-prop learning to concurrently map and plan paths in a large and complex environment. We incorporate a novel method for mapping which, when combined with the Spiking Wavefront Planner, allows for adaptive planning by selectively considering any combination of costs. The system is tested on a mobile robot platform in an outdoor environment with obstacles and varying terrain. Results indicate that the system is capable of discerning features in the environment using three measures of cost, (1) energy expenditure by the wheels, (2) time spent in the presence of obstacles, and (3) terrain slope. In just twelve hours of online training, E-prop learns and incorporates traversal costs into the path planning maps by updating the delays in the Spiking Wavefront Planner. On simulated paths, the Spiking Wavefront Planner plans significantly shorter and lower cost paths than A* and RRT*. The spiking wavefront planner is compatible with neuromorphic hardware and could be used for applications requiring low size, weight, and power.
An Integrated Toolbox for Creating Neuromorphic Edge Applications
Apr 12, 2024Spiking Neural Networks (SNNs) and neuromorphic models are more efficient and have more biological realism than the activation functions typically used in deep neural networks, transformer models and generative AI. SNNs have local learning rules, are able to learn on small data sets, and can adapt through neuromodulation. Although research has shown their advantages, there are still few compelling practical applications, especially at the edge where sensors and actuators need to be processed in a timely fashion. One reason for this might be that SNNs are much more challenging to understand, build, and operate due to their intrinsic properties. For instance, the mathematical foundation involves differential equations rather than basic activation functions. To address these challenges, we have developed CARLsim++. It is an integrated toolbox that enables fast and easy creation of neuromorphic applications. It encapsulates the mathematical intrinsics and low-level C++ programming by providing a graphical user interface for users who do not have a background in software engineering but still want to create neuromorphic models. Developers can easily configure inputs and outputs to devices and robots. These can be accurately simulated before deploying on physical devices. CARLsim++ can lead to rapid development of neuromorphic applications for simulation or edge processing.
Policy Distillation with Selective Input Gradient Regularization for Efficient Interpretability
May 18, 2022
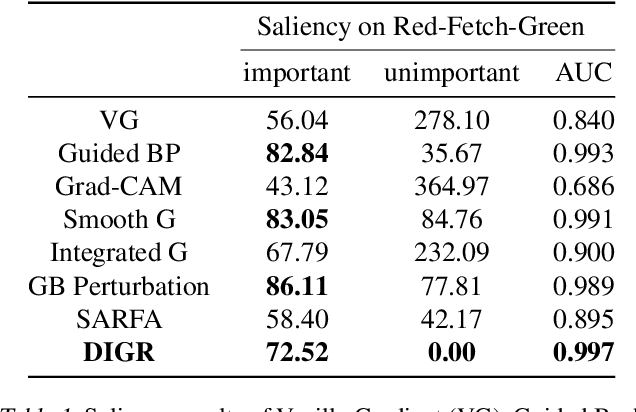
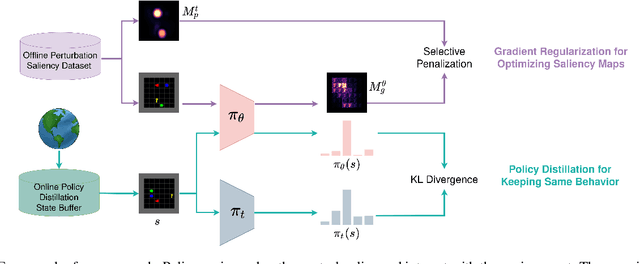
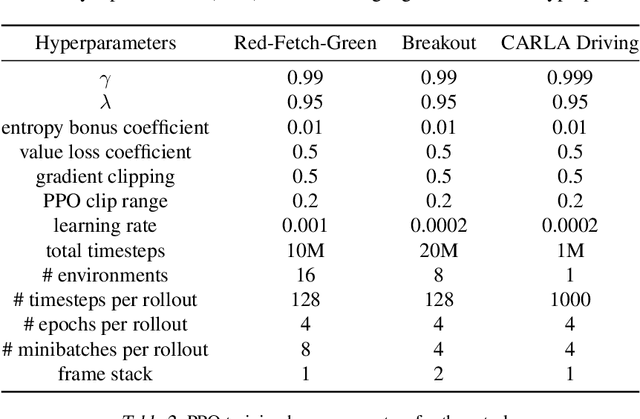
Although deep Reinforcement Learning (RL) has proven successful in a wide range of tasks, one challenge it faces is interpretability when applied to real-world problems. Saliency maps are frequently used to provide interpretability for deep neural networks. However, in the RL domain, existing saliency map approaches are either computationally expensive and thus cannot satisfy the real-time requirement of real-world scenarios or cannot produce interpretable saliency maps for RL policies. In this work, we propose an approach of Distillation with selective Input Gradient Regularization (DIGR) which uses policy distillation and input gradient regularization to produce new policies that achieve both high interpretability and computation efficiency in generating saliency maps. Our approach is also found to improve the robustness of RL policies to multiple adversarial attacks. We conduct experiments on three tasks, MiniGrid (Fetch Object), Atari (Breakout) and CARLA Autonomous Driving, to demonstrate the importance and effectiveness of our approach.
Edelman's Steps Toward a Conscious Artifact
May 25, 2021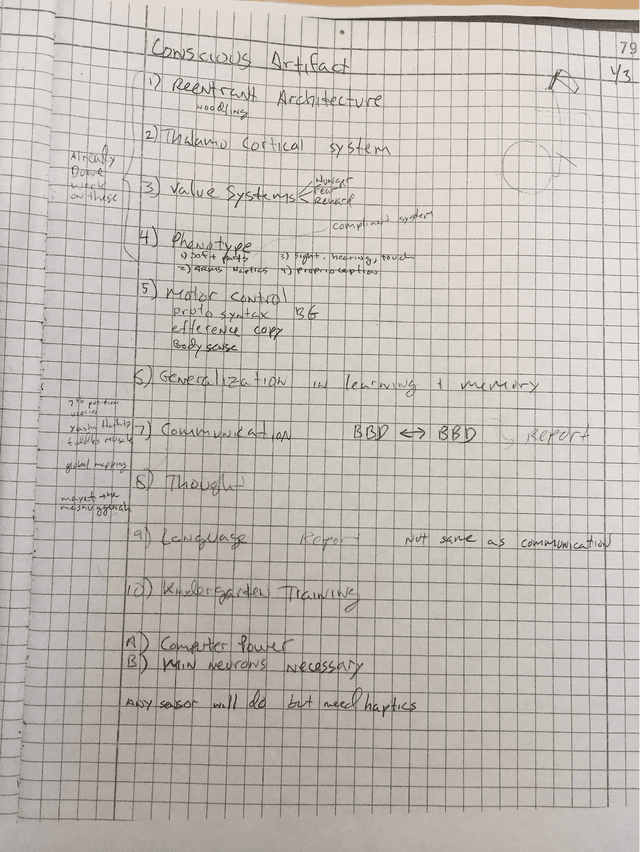

In 2006, during a meeting of a working group of scientists in La Jolla, California at The Neurosciences Institute (NSI), Gerald Edelman described a roadmap towards the creation of a Conscious Artifact. As far as I know, this roadmap was not published. However, it did shape my thinking and that of many others in the years since that meeting. This short paper, which is based on my notes taken during the meeting, describes the key steps in this roadmap. I believe it is as groundbreaking today as it was more than 15 years ago.
Dynamic Reliability Management in Neuromorphic Computing
May 05, 2021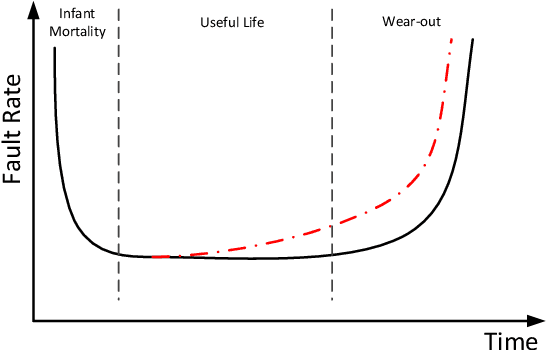
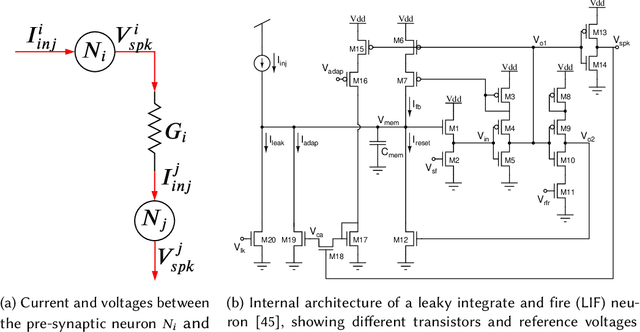
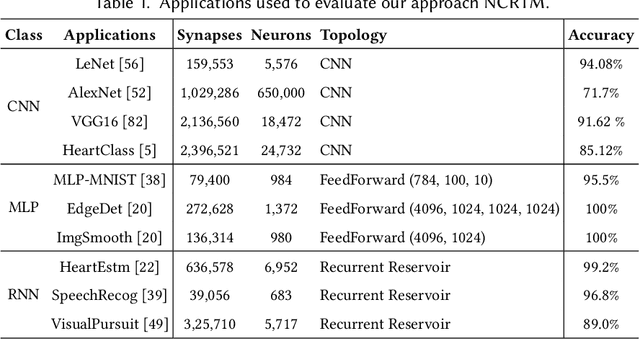

Neuromorphic computing systems uses non-volatile memory (NVM) to implement high-density and low-energy synaptic storage. Elevated voltages and currents needed to operate NVMs cause aging of CMOS-based transistors in each neuron and synapse circuit in the hardware, drifting the transistor's parameters from their nominal values. Aggressive device scaling increases power density and temperature, which accelerates the aging, challenging the reliable operation of neuromorphic systems. Existing reliability-oriented techniques periodically de-stress all neuron and synapse circuits in the hardware at fixed intervals, assuming worst-case operating conditions, without actually tracking their aging at run time. To de-stress these circuits, normal operation must be interrupted, which introduces latency in spike generation and propagation, impacting the inter-spike interval and hence, performance, e.g., accuracy. We propose a new architectural technique to mitigate the aging-related reliability problems in neuromorphic systems, by designing an intelligent run-time manager (NCRTM), which dynamically destresses neuron and synapse circuits in response to the short-term aging in their CMOS transistors during the execution of machine learning workloads, with the objective of meeting a reliability target. NCRTM de-stresses these circuits only when it is absolutely necessary to do so, otherwise reducing the performance impact by scheduling de-stress operations off the critical path. We evaluate NCRTM with state-of-the-art machine learning workloads on a neuromorphic hardware. Our results demonstrate that NCRTM significantly improves the reliability of neuromorphic hardware, with marginal impact on performance.
Neuroevolution of a Recurrent Neural Network for Spatial and Working Memory in a Simulated Robotic Environment
Feb 25, 2021
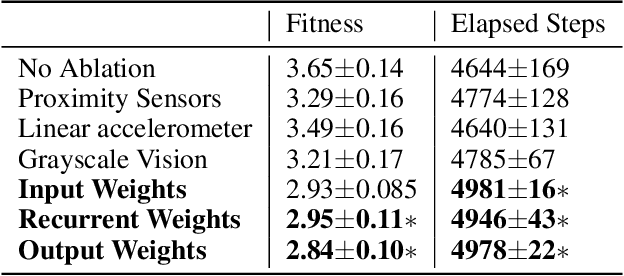

Animals ranging from rats to humans can demonstrate cognitive map capabilities. We evolved weights in a biologically plausible recurrent neural network (RNN) using an evolutionary algorithm to replicate the behavior and neural activity observed in rats during a spatial and working memory task in a triple T-maze. The rat was simulated in the Webots robot simulator and used vision, distance and accelerometer sensors to navigate a virtual maze. After evolving weights from sensory inputs to the RNN, within the RNN, and from the RNN to the robot's motors, the Webots agent successfully navigated the space to reach all four reward arms with minimal repeats before time-out. Our current findings suggest that it is the RNN dynamics that are key to performance, and that performance is not dependent on any one sensory type, which suggests that neurons in the RNN are performing mixed selectivity and conjunctive coding. Moreover, the RNN activity resembles spatial information and trajectory-dependent coding observed in the hippocampus. Collectively, the evolved RNN exhibits navigation skills, spatial memory, and working memory. Our method demonstrates how the dynamic activity in evolved RNNs can capture interesting and complex cognitive behavior and may be used to create RNN controllers for robotic applications.
Domain Adaptation In Reinforcement Learning Via Latent Unified State Representation
Feb 10, 2021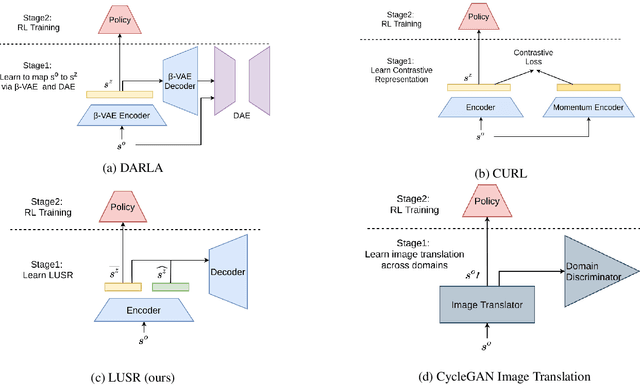

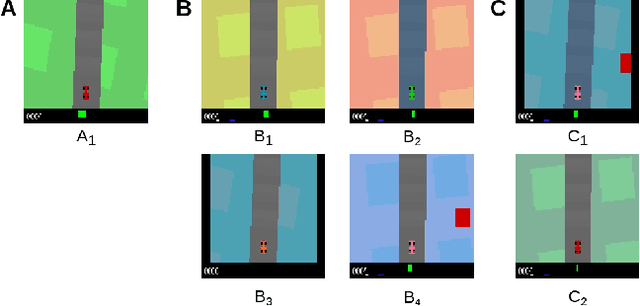
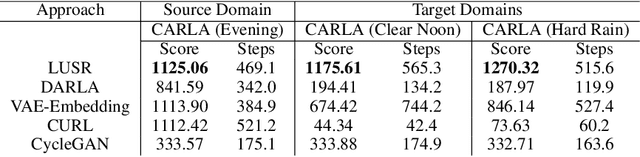
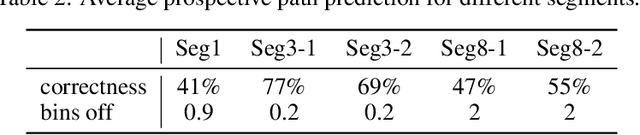
Despite the recent success of deep reinforcement learning (RL), domain adaptation remains an open problem. Although the generalization ability of RL agents is critical for the real-world applicability of Deep RL, zero-shot policy transfer is still a challenging problem since even minor visual changes could make the trained agent completely fail in the new task. To address this issue, we propose a two-stage RL agent that first learns a latent unified state representation (LUSR) which is consistent across multiple domains in the first stage, and then do RL training in one source domain based on LUSR in the second stage. The cross-domain consistency of LUSR allows the policy acquired from the source domain to generalize to other target domains without extra training. We first demonstrate our approach in variants of CarRacing games with customized manipulations, and then verify it in CARLA, an autonomous driving simulator with more complex and realistic visual observations. Our results show that this approach can achieve state-of-the-art domain adaptation performance in related RL tasks and outperforms prior approaches based on latent-representation based RL and image-to-image translation.
PyCARL: A PyNN Interface for Hardware-Software Co-Simulation of Spiking Neural Network
Mar 21, 2020
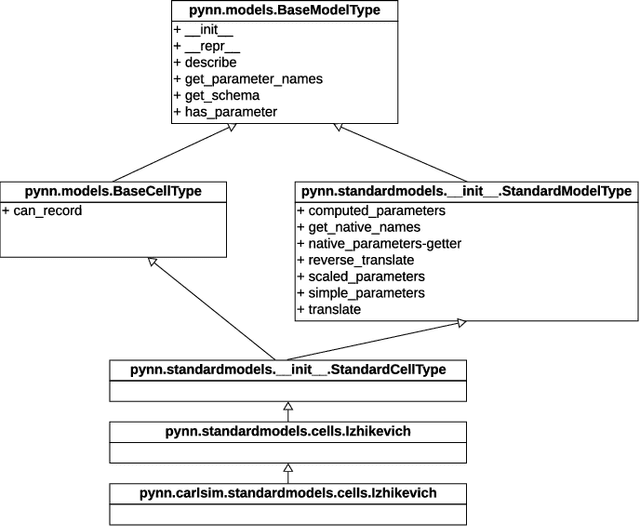
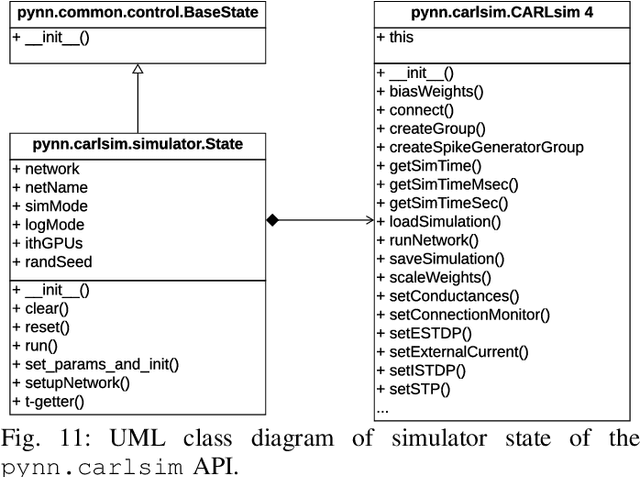

We present PyCARL, a PyNN-based common Python programming interface for hardware-software co-simulation of spiking neural network (SNN). Through PyCARL, we make the following two key contributions. First, we provide an interface of PyNN to CARLsim, a computationally-efficient, GPU-accelerated and biophysically-detailed SNN simulator. PyCARL facilitates joint development of machine learning models and code sharing between CARLsim and PyNN users, promoting an integrated and larger neuromorphic community. Second, we integrate cycle-accurate models of state-of-the-art neuromorphic hardware such as TrueNorth, Loihi, and DynapSE in PyCARL, to accurately model hardware latencies that delay spikes between communicating neurons and degrade performance. PyCARL allows users to analyze and optimize the performance difference between software-only simulation and hardware-software co-simulation of their machine learning models. We show that system designers can also use PyCARL to perform design-space exploration early in the product development stage, facilitating faster time-to-deployment of neuromorphic products. We evaluate the memory usage and simulation time of PyCARL using functionality tests, synthetic SNNs, and realistic applications. Our results demonstrate that for large SNNs, PyCARL does not lead to any significant overhead compared to CARLsim. We also use PyCARL to analyze these SNNs for a state-of-the-art neuromorphic hardware and demonstrate a significant performance deviation from software-only simulations. PyCARL allows to evaluate and minimize such differences early during model development.
Deep Reinforcement Learning with Modulated Hebbian plus Q Network Architecture
Sep 21, 2019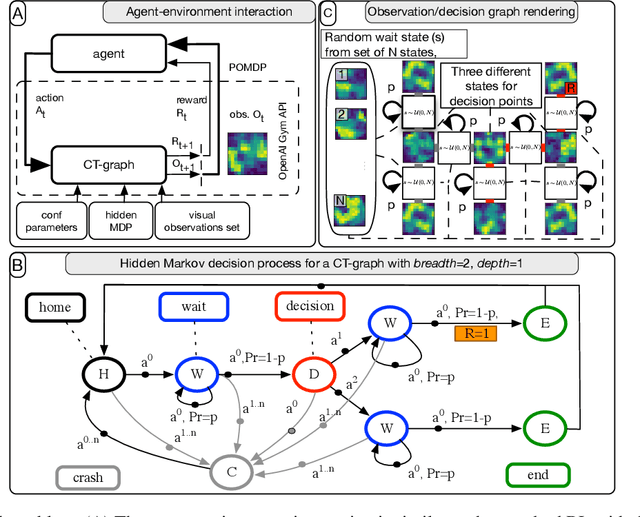
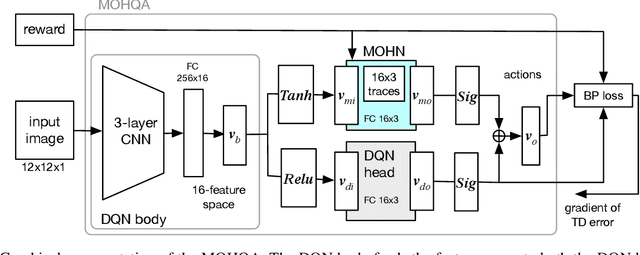
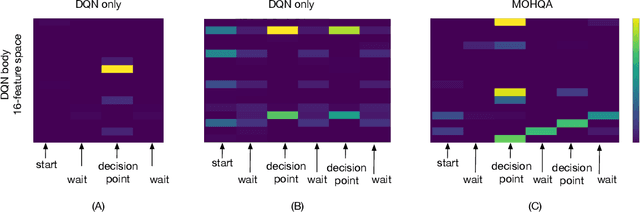
This paper introduces the modulated Hebbian plus Q network architecture (MOHQA) for solving challenging partially observable Markov decision processes (POMDPs) deep reinforcement learning problems with sparse rewards and confounding observations. The proposed architecture combines a deep Q-network (DQN), and a modulated Hebbian network with neural eligibility traces (MOHN). Bio-inspired neural traces are used to bridge temporal delays between actions and rewards. The purpose is to discover distal cause-effect relationships where confounding observations and sparse rewards cause standard RL algorithms to fail. Each of the two modules of the network (DQN and MOHN) is responsible for different aspects of learning. DQN learns low level features and control, while MOHN contributes to the high-level decisions by bridging rewards with past actions. The strength of the approach is to support a DQN standard framework when temporal difference errors are difficult to compute due to non-observable states. The system is tested on a set of generalized decision making problems encoded as decision tree graphs that deliver delayed rewards after key decision points and confounding observations. The simulations show that the proposed approach helps solve problems that are currently challenging for state-of-the-art deep reinforcement learning algorithms.