 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfluence Functions in Deep Learning Are Fragile
Jun 25, 2020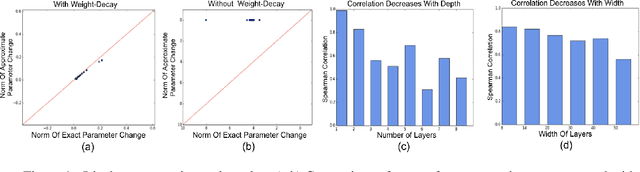
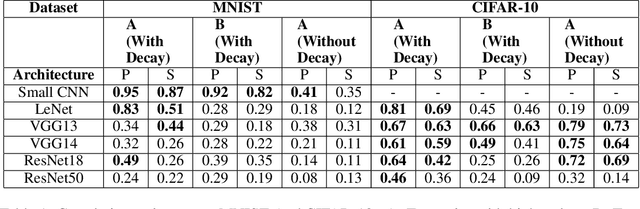
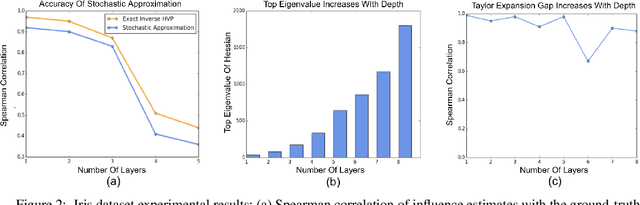
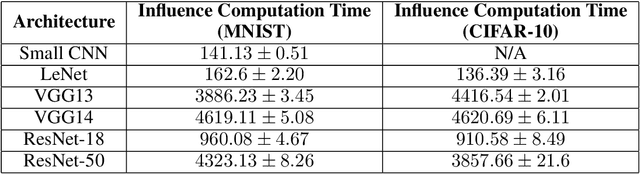
Influence functions approximate the effect of training samples in test-time predictions and have a wide variety of applications in machine learning interpretability and uncertainty estimation. A commonly-used (first-order) influence function can be implemented efficiently as a post-hoc method requiring access only to the gradients and Hessian of the model. For linear models, influence functions are well-defined due to the convexity of the underlying loss function and are generally accurate even across difficult settings where model changes are fairly large such as estimating group influences. Influence functions, however, are not well-understood in the context of deep learning with non-convex loss functions. In this paper, we provide a comprehensive and large-scale empirical study of successes and failures of influence functions in neural network models trained on datasets such as Iris, MNIST, CIFAR-10 and ImageNet. Through our extensive experiments, we show that the network architecture, its depth and width, as well as the extent of model parameterization and regularization techniques have strong effects in the accuracy of influence functions. In particular, we find that (i) influence estimates are fairly accurate for shallow networks, while for deeper networks the estimates are often erroneous; (ii) for certain network architectures and datasets, training with weight-decay regularization is important to get high-quality influence estimates; and (iii) the accuracy of influence estimates can vary significantly depending on the examined test points. These results suggest that in general influence functions in deep learning are fragile and call for developing improved influence estimation methods to mitigate these issues in non-convex setups.
Learning a Domain-Invariant Embedding for Unsupervised Domain Adaptation Using Class-Conditioned Distribution Alignment
Jul 04, 2019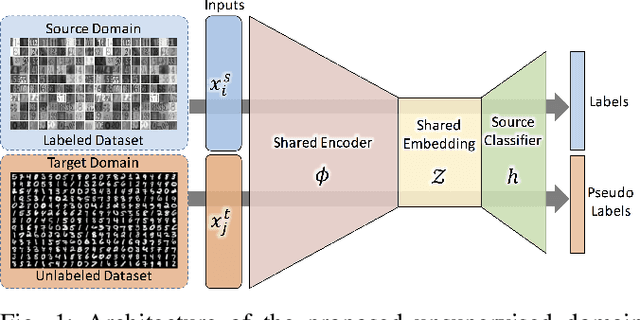

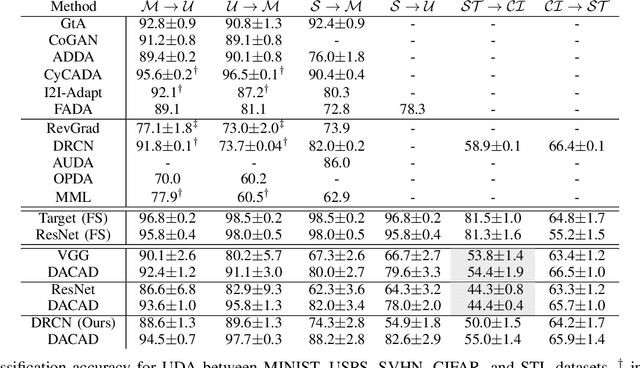
We address the problem of unsupervised domain adaptation (UDA) by learning a cross-domain agnostic embedding space, where the distance between the probability distributions of the two source and target visual domains is minimized. We use the output space of a shared cross-domain deep encoder to model the embedding space anduse the Sliced-Wasserstein Distance (SWD) to measure and minimize the distance between the embedded distributions of two source and target domains to enforce the embedding to be domain-agnostic.Additionally, we use the source domain labeled data to train a deep classifier from the embedding space to the label space to enforce the embedding space to be discriminative.As a result of this training scheme, we provide an effective solution to train the deep classification network on the source domain such that it will generalize well on the target domain, where only unlabeled training data is accessible. To mitigate the challenge of class matching, we also align corresponding classes in the embedding space by using high confidence pseudo-labels for the target domain, i.e. assigning the class for which the source classifier has a high prediction probability. We provide theoretical justification as well as experimental results on UDA benchmark tasks to demonstrate that our method is effective and leads to state-of-the-art performance.