 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniform Diffusion Models Revisited: Leave-One-Out Denoiser and Absorbing State Reformulation
May 21, 2026Discrete diffusion models are often trained through clean-data prediction, but the prediction can be used in different ways to define the reverse dynamics. In Masked Diffusion Models (MDM) these choices largely coincide, whereas in Uniform Diffusion Models (UDM) they do not. We show that the standard plug-in bridge parameterization for UDM is not optimized by the denoising posterior, but by a leave-one-out posterior that predicts each clean token without using its own noisy observation. This identifies a mismatch between the plug-in ELBO and the usual cross-entropy denoising objective. We characterize the leave-one-out target and derive exact conversions between the denoiser, the leave-one-out posterior, and the score. These conversions allow us to disentangle parameterization and training objective. Our results also lead to inference improvements without any additional training through an informed predictor-corrector sampler and improved temperature sampling based on the leave-one-out predictor. We further introduce an absorbing-state reformulation of uniform diffusion that preserves the UDM joint law while decomposing it into masked-diffusion-like sampling operations, with simpler denoising posteriors, carry-over unmasking, and a natural remasking mechanism. On language modeling, leave-one-out parameterizations consistently improve UDM generation, while the absorbing construction matches or surpasses masked diffusion. These results suggest that the empirical gap between masked and uniform diffusion is driven less by the choice of marginals themselves than by parameterization and sampling design. The code and models can be found at https://github.com/samsongourevitch/rev_udm.
Variational Inference for Lévy Process-Driven SDEs via Neural Tilting
May 11, 2026Modelling extreme events and heavy-tailed phenomena is central to building reliable predictive systems in domains such as finance, climate science, and safety-critical AI. While Lévy processes provide a natural mathematical framework for capturing jumps and heavy tails, Bayesian inference for Lévy-driven stochastic differential equations (SDEs) remains intractable with existing methods: Monte Carlo approaches are rigorous but lack scalability, whereas neural variational inference methods are efficient but rely on Gaussian assumptions that fail to capture discontinuities. We address this tension by introducing a neural exponential tilting framework for variational inference in Lévy-driven SDEs. Our approach constructs a flexible variational family by exponentially reweighting the Lévy measure using neural networks. This parametrization preserves the jump structure of the underlying process while remaining computationally tractable. To enable efficient inference, we develop a quadratic neural parametrization that yields closed-form normalization of the tilted measure, a conditional Gaussian representation for stable processes that facilitates simulation, and symmetry-aware Monte Carlo estimators for scalable optimization. Empirically, we demonstrate that the method accurately captures jump dynamics and yields reliable posterior inference in regimes where Gaussian-based variational approaches fail, on both synthetic and real-world datasets.
Algorithm- and Data-Dependent Generalization Bounds for Score-Based Generative Models
Jun 04, 2025

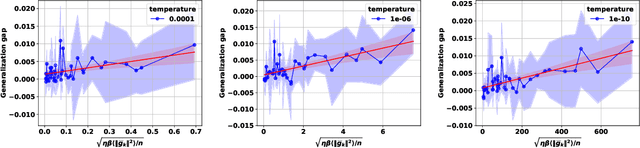

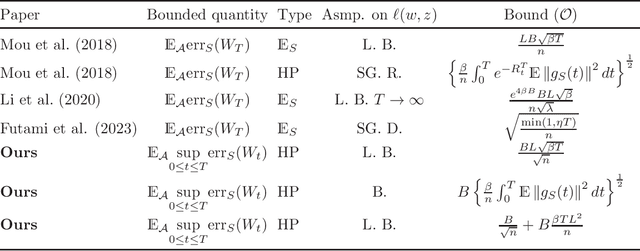
Score-based generative models (SGMs) have emerged as one of the most popular classes of generative models. A substantial body of work now exists on the analysis of SGMs, focusing either on discretization aspects or on their statistical performance. In the latter case, bounds have been derived, under various metrics, between the true data distribution and the distribution induced by the SGM, often demonstrating polynomial convergence rates with respect to the number of training samples. However, these approaches adopt a largely approximation theory viewpoint, which tends to be overly pessimistic and relatively coarse. In particular, they fail to fully explain the empirical success of SGMs or capture the role of the optimization algorithm used in practice to train the score network. To support this observation, we first present simple experiments illustrating the concrete impact of optimization hyperparameters on the generalization ability of the generated distribution. Then, this paper aims to bridge this theoretical gap by providing the first algorithmic- and data-dependent generalization analysis for SGMs. In particular, we establish bounds that explicitly account for the optimization dynamics of the learning algorithm, offering new insights into the generalization behavior of SGMs. Our theoretical findings are supported by empirical results on several datasets.
Understanding the Generalization Error of Markov algorithms through Poissonization
Feb 11, 2025Using continuous-time stochastic differential equation (SDE) proxies to stochastic optimization algorithms has proven fruitful for understanding their generalization abilities. A significant part of these approaches are based on the so-called ``entropy flows'', which greatly simplify the generalization analysis. Unfortunately, such well-structured entropy flows cannot be obtained for most discrete-time algorithms, and the existing SDE approaches remain limited to specific noise and algorithmic structures. We aim to alleviate this issue by introducing a generic framework for analyzing the generalization error of Markov algorithms through `Poissonization', a continuous-time approximation of discrete-time processes with formal approximation guarantees. Through this approach, we first develop a novel entropy flow, which directly leads to PAC-Bayesian generalization bounds. We then draw novel links to modified versions of the celebrated logarithmic Sobolev inequalities (LSI), identify cases where such LSIs are satisfied, and obtain improved bounds. Beyond its generality, our framework allows exploiting specific properties of learning algorithms. In particular, we incorporate the noise structure of different algorithm types - namely, those with additional noise injections (noisy) and those without (non-noisy) - through various technical tools. This illustrates the capacity of our methods to achieve known (yet, Poissonized) and new generalization bounds.
Algorithmic Stability of Stochastic Gradient Descent with Momentum under Heavy-Tailed Noise
Feb 02, 2025Understanding the generalization properties of optimization algorithms under heavy-tailed noise has gained growing attention. However, the existing theoretical results mainly focus on stochastic gradient descent (SGD) and the analysis of heavy-tailed optimizers beyond SGD is still missing. In this work, we establish generalization bounds for SGD with momentum (SGDm) under heavy-tailed gradient noise. We first consider the continuous-time limit of SGDm, i.e., a Levy-driven stochastic differential equation (SDE), and establish quantitative Wasserstein algorithmic stability bounds for a class of potentially non-convex loss functions. Our bounds reveal a remarkable observation: For quadratic loss functions, we show that SGDm admits a worse generalization bound in the presence of heavy-tailed noise, indicating that the interaction of momentum and heavy tails can be harmful for generalization. We then extend our analysis to discrete-time and develop a uniform-in-time discretization error bound, which, to our knowledge, is the first result of its kind for SDEs with degenerate noise. This result shows that, with appropriately chosen step-sizes, the discrete dynamics retain the generalization properties of the limiting SDE. We illustrate our theory on both synthetic quadratic problems and neural networks.
The Surprising Agreement Between Convex Optimization Theory and Learning-Rate Scheduling for Large Model Training
Jan 31, 2025



We show that learning-rate schedules for large model training behave surprisingly similar to a performance bound from non-smooth convex optimization theory. We provide a bound for the constant schedule with linear cooldown; in particular, the practical benefit of cooldown is reflected in the bound due to the absence of logarithmic terms. Further, we show that this surprisingly close match between optimization theory and practice can be exploited for learning-rate tuning: we achieve noticeable improvements for training 124M and 210M Llama-type models by (i) extending the schedule for continued training with optimal learning-rate, and (ii) transferring the optimal learning-rate across schedules.
Piecewise deterministic generative models
Jul 28, 2024We introduce a novel class of generative models based on piecewise deterministic Markov processes (PDMPs), a family of non-diffusive stochastic processes consisting of deterministic motion and random jumps at random times. Similarly to diffusions, such Markov processes admit time reversals that turn out to be PDMPs as well. We apply this observation to three PDMPs considered in the literature: the Zig-Zag process, Bouncy Particle Sampler, and Randomised Hamiltonian Monte Carlo. For these three particular instances, we show that the jump rates and kernels of the corresponding time reversals admit explicit expressions depending on some conditional densities of the PDMP under consideration before and after a jump. Based on these results, we propose efficient training procedures to learn these characteristics and consider methods to approximately simulate the reverse process. Finally, we provide bounds in the total variation distance between the data distribution and the resulting distribution of our model in the case where the base distribution is the standard $d$-dimensional Gaussian distribution. Promising numerical simulations support further investigations into this class of models.
Denoising Lévy Probabilistic Models
Jul 26, 2024



Investigating noise distribution beyond Gaussian in diffusion generative models is an open problem. The Gaussian case has seen success experimentally and theoretically, fitting a unified SDE framework for score-based and denoising formulations. Recent studies suggest heavy-tailed noise distributions can address mode collapse and manage datasets with class imbalance, heavy tails, or outliers. Yoon et al. (NeurIPS 2023) introduced the L\'evy-Ito model (LIM), extending the SDE framework to heavy-tailed SDEs with $\alpha$-stable noise. Despite its theoretical elegance and performance gains, LIM's complex mathematics may limit its accessibility and broader adoption. This study takes a simpler approach by extending the denoising diffusion probabilistic model (DDPM) with $\alpha$-stable noise, creating the denoising L\'evy probabilistic model (DLPM). Using elementary proof techniques, we show DLPM reduces to running vanilla DDPM with minimal changes, allowing the use of existing implementations with minimal changes. DLPM and LIM have different training algorithms and, unlike the Gaussian case, they admit different backward processes and sampling algorithms. Our experiments demonstrate that DLPM achieves better coverage of data distribution tail, improved generation of unbalanced datasets, and faster computation times with fewer backward steps.
Uniform Generalization Bounds on Data-Dependent Hypothesis Sets via PAC-Bayesian Theory on Random Sets
Apr 26, 2024


We propose data-dependent uniform generalization bounds by approaching the problem from a PAC-Bayesian perspective. We first apply the PAC-Bayesian framework on `random sets' in a rigorous way, where the training algorithm is assumed to output a data-dependent hypothesis set after observing the training data. This approach allows us to prove data-dependent bounds, which can be applicable in numerous contexts. To highlight the power of our approach, we consider two main applications. First, we propose a PAC-Bayesian formulation of the recently developed fractal-dimension-based generalization bounds. The derived results are shown to be tighter and they unify the existing results around one simple proof technique. Second, we prove uniform bounds over the trajectories of continuous Langevin dynamics and stochastic gradient Langevin dynamics. These results provide novel information about the generalization properties of noisy algorithms.
SGD with Clipping is Secretly Estimating the Median Gradient
Feb 20, 2024



There are several applications of stochastic optimization where one can benefit from a robust estimate of the gradient. For example, domains such as distributed learning with corrupted nodes, the presence of large outliers in the training data, learning under privacy constraints, or even heavy-tailed noise due to the dynamics of the algorithm itself. Here we study SGD with robust gradient estimators based on estimating the median. We first consider computing the median gradient across samples, and show that the resulting method can converge even under heavy-tailed, state-dependent noise. We then derive iterative methods based on the stochastic proximal point method for computing the geometric median and generalizations thereof. Finally we propose an algorithm estimating the median gradient across iterations, and find that several well known methods - in particular different forms of clipping - are particular cases of this framework.