 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKORGym: A Dynamic Game Platform for LLM Reasoning Evaluation
May 21, 2025
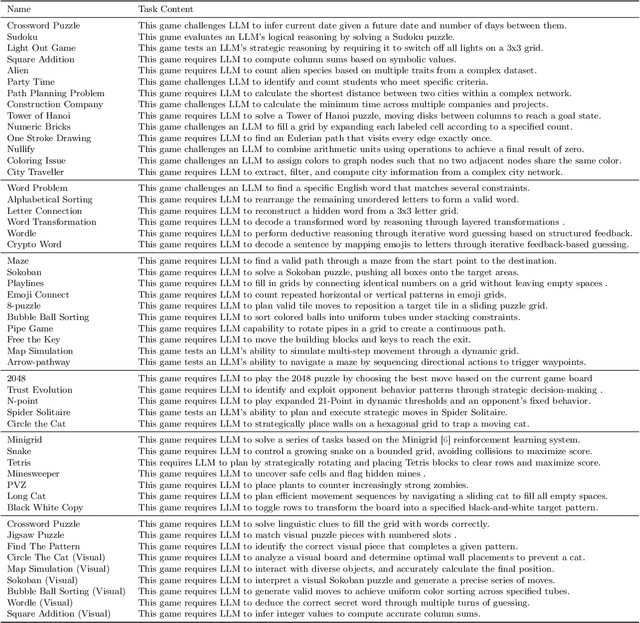
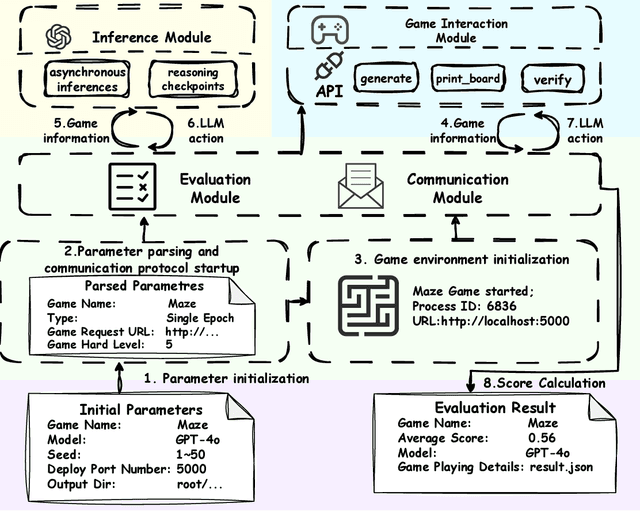

Recent advancements in large language models (LLMs) underscore the need for more comprehensive evaluation methods to accurately assess their reasoning capabilities. Existing benchmarks are often domain-specific and thus cannot fully capture an LLM's general reasoning potential. To address this limitation, we introduce the Knowledge Orthogonal Reasoning Gymnasium (KORGym), a dynamic evaluation platform inspired by KOR-Bench and Gymnasium. KORGym offers over fifty games in either textual or visual formats and supports interactive, multi-turn assessments with reinforcement learning scenarios. Using KORGym, we conduct extensive experiments on 19 LLMs and 8 VLMs, revealing consistent reasoning patterns within model families and demonstrating the superior performance of closed-source models. Further analysis examines the effects of modality, reasoning strategies, reinforcement learning techniques, and response length on model performance. We expect KORGym to become a valuable resource for advancing LLM reasoning research and developing evaluation methodologies suited to complex, interactive environments.
MoL for LLMs: Dual-Loss Optimization to Enhance Domain Expertise While Preserving General Capabilities
May 17, 2025Although LLMs perform well in general tasks, domain-specific applications suffer from hallucinations and accuracy limitations. CPT approaches encounter two key issues: (1) domain-biased data degrades general language skills, and (2) improper corpus-mixture ratios limit effective adaptation. To address these, we propose a novel framework, Mixture of Losses (MoL), which decouples optimization objectives for domain-specific and general corpora. Specifically, cross-entropy (CE) loss is applied to domain data to ensure knowledge acquisition, while Kullback-Leibler (KL) divergence aligns general-corpus training with the base model's foundational capabilities. This dual-loss architecture preserves universal skills while enhancing domain expertise, avoiding catastrophic forgetting. Empirically, we validate that a 1:1 domain-to-general corpus ratio optimally balances training and overfitting without the need for extensive tuning or resource-intensive experiments. Furthermore, our experiments demonstrate significant performance gains compared to traditional CPT approaches, which often suffer from degradation in general language capabilities; our model achieves 27.9% higher accuracy on the Math-500 benchmark in the non-think reasoning mode, and an impressive 83.3% improvement on the challenging AIME25 subset in the think mode, underscoring the effectiveness of our approach.
KARPA: A Training-free Method of Adapting Knowledge Graph as References for Large Language Model's Reasoning Path Aggregation
Dec 30, 2024Large language models (LLMs) demonstrate exceptional performance across a variety of tasks, yet they are often affected by hallucinations and the timeliness of knowledge. Leveraging knowledge graphs (KGs) as external knowledge sources has emerged as a viable solution, but existing methods for LLM-based knowledge graph question answering (KGQA) are often limited by step-by-step decision-making on KGs, restricting the global planning and reasoning capabilities of LLMs, or they require fine-tuning or pre-training on specific KGs. To address these challenges, we propose Knowledge graph Assisted Reasoning Path Aggregation (KARPA), a novel framework that harnesses the global planning abilities of LLMs for efficient and accurate KG reasoning. KARPA operates in three steps: pre-planning relation paths using the LLM's global planning capabilities, matching semantically relevant paths via an embedding model, and reasoning over these paths to generate answers. Unlike existing KGQA methods, KARPA avoids stepwise traversal, requires no additional training, and is adaptable to various LLM architectures. Extensive experimental results show that KARPA achieves state-of-the-art performance in KGQA tasks, delivering both high efficiency and accuracy. Our code will be available on Github.
Continuous Contrastive Learning for Long-Tailed Semi-Supervised Recognition
Oct 08, 2024



Long-tailed semi-supervised learning poses a significant challenge in training models with limited labeled data exhibiting a long-tailed label distribution. Current state-of-the-art LTSSL approaches heavily rely on high-quality pseudo-labels for large-scale unlabeled data. However, these methods often neglect the impact of representations learned by the neural network and struggle with real-world unlabeled data, which typically follows a different distribution than labeled data. This paper introduces a novel probabilistic framework that unifies various recent proposals in long-tail learning. Our framework derives the class-balanced contrastive loss through Gaussian kernel density estimation. We introduce a continuous contrastive learning method, CCL, extending our framework to unlabeled data using reliable and smoothed pseudo-labels. By progressively estimating the underlying label distribution and optimizing its alignment with model predictions, we tackle the diverse distribution of unlabeled data in real-world scenarios. Extensive experiments across multiple datasets with varying unlabeled data distributions demonstrate that CCL consistently outperforms prior state-of-the-art methods, achieving over 4% improvement on the ImageNet-127 dataset. Our source code is available at https://github.com/zhouzihao11/CCL