 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransFlow: Transformer as Flow Learner
Apr 23, 2023



Optical flow is an indispensable building block for various important computer vision tasks, including motion estimation, object tracking, and disparity measurement. In this work, we propose TransFlow, a pure transformer architecture for optical flow estimation. Compared to dominant CNN-based methods, TransFlow demonstrates three advantages. First, it provides more accurate correlation and trustworthy matching in flow estimation by utilizing spatial self-attention and cross-attention mechanisms between adjacent frames to effectively capture global dependencies; Second, it recovers more compromised information (e.g., occlusion and motion blur) in flow estimation through long-range temporal association in dynamic scenes; Third, it enables a concise self-learning paradigm and effectively eliminate the complex and laborious multi-stage pre-training procedures. We achieve the state-of-the-art results on the Sintel, KITTI-15, as well as several downstream tasks, including video object detection, interpolation and stabilization. For its efficacy, we hope TransFlow could serve as a flexible baseline for optical flow estimation.
Two-in-one Knowledge Distillation for Efficient Facial Forgery Detection
Feb 21, 2023



Facial forgery detection is a crucial but extremely challenging topic, with the fast development of forgery techniques making the synthetic artefact highly indistinguishable. Prior works show that by mining both spatial and frequency information the forgery detection performance of deep learning models can be vastly improved. However, leveraging multiple types of information usually requires more than one branch in the neural network, which makes the model heavy and cumbersome. Knowledge distillation, as an important technique for efficient modelling, could be a possible remedy. We find that existing knowledge distillation methods have difficulties distilling a dual-branch model into a single-branch model. More specifically, knowledge distillation on both the spatial and frequency branches has degraded performance than distillation only on the spatial branch. To handle such problem, we propose a novel two-in-one knowledge distillation framework which can smoothly merge the information from a large dual-branch network into a small single-branch network, with the help of different dedicated feature projectors and the gradient homogenization technique. Experimental analysis on two datasets, FaceForensics++ and Celeb-DF, shows that our proposed framework achieves superior performance for facial forgery detection with much fewer parameters.
Anti-Compression Contrastive Facial Forgery Detection
Feb 13, 2023



Forgery facial images and videos have increased the concern of digital security. It leads to the significant development of detecting forgery data recently. However, the data, especially the videos published on the Internet, are usually compressed with lossy compression algorithms such as H.264. The compressed data could significantly degrade the performance of recent detection algorithms. The existing anti-compression algorithms focus on enhancing the performance in detecting heavily compressed data but less consider the compression adaption to the data from various compression levels. We believe creating a forgery detection model that can handle the data compressed with unknown levels is important. To enhance the performance for such models, we consider the weak compressed and strong compressed data as two views of the original data and they should have similar representation and relationships with other samples. We propose a novel anti-compression forgery detection framework by maintaining closer relations within data under different compression levels. Specifically, the algorithm measures the pair-wise similarity within data as the relations, and forcing the relations of weak and strong compressed data close to each other, thus improving the discriminate power for detecting strong compressed data. To achieve a better strong compressed data relation guided by the less compressed one, we apply video level contrastive learning for weak compressed data, which forces the model to produce similar representations within the same video and far from the negative samples. The experiment results show that the proposed algorithm could boost performance for strong compressed data while improving the accuracy rate when detecting the clean data.
Solve the Puzzle of Instance Segmentation in Videos: A Weakly Supervised Framework with Spatio-Temporal Collaboration
Dec 15, 2022



Instance segmentation in videos, which aims to segment and track multiple objects in video frames, has garnered a flurry of research attention in recent years. In this paper, we present a novel weakly supervised framework with \textbf{S}patio-\textbf{T}emporal \textbf{C}ollaboration for instance \textbf{Seg}mentation in videos, namely \textbf{STC-Seg}. Concretely, STC-Seg demonstrates four contributions. First, we leverage the complementary representations from unsupervised depth estimation and optical flow to produce effective pseudo-labels for training deep networks and predicting high-quality instance masks. Second, to enhance the mask generation, we devise a puzzle loss, which enables end-to-end training using box-level annotations. Third, our tracking module jointly utilizes bounding-box diagonal points with spatio-temporal discrepancy to model movements, which largely improves the robustness to different object appearances. Finally, our framework is flexible and enables image-level instance segmentation methods to operate the video-level task. We conduct an extensive set of experiments on the KITTI MOTS and YT-VIS datasets. Experimental results demonstrate that our method achieves strong performance and even outperforms fully supervised TrackR-CNN and MaskTrack R-CNN. We believe that STC-Seg can be a valuable addition to the community, as it reflects the tip of an iceberg about the innovative opportunities in the weakly supervised paradigm for instance segmentation in videos.
Control Parameters Considered Harmful: Detecting Range Specification Bugs in Drone Configuration Modules via Learning-Guided Search
Dec 07, 2021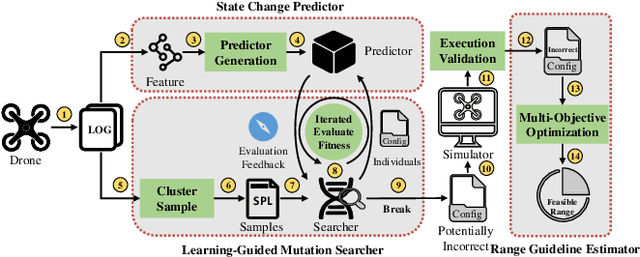
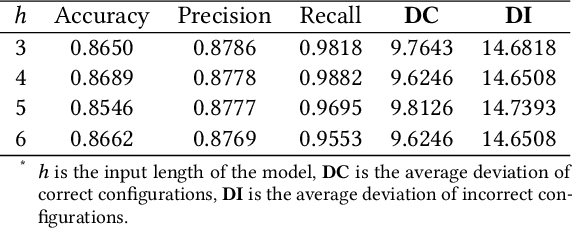

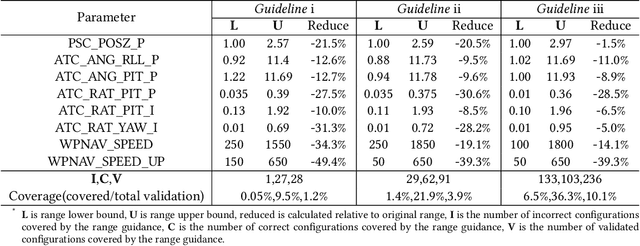
In order to support a variety of missions and deal with different flight environments, drone control programs typically provide configurable control parameters. However, such a flexibility introduces vulnerabilities. One such vulnerability, referred to as range specification bugs, has been recently identified. The vulnerability originates from the fact that even though each individual parameter receives a value in the recommended value range, certain combinations of parameter values may affect the drone physical stability. In this paper we develop a novel learning-guided search system to find such combinations, that we refer to as incorrect configurations. Our system applies metaheuristic search algorithms mutating configurations to detect the configuration parameters that have values driving the drone to unstable physical states. To guide the mutations, our system leverages a machine learning predictor as the fitness evaluator. Finally, by utilizing multi-objective optimization, our system returns the feasible ranges based on the mutation search results. Because in our system the mutations are guided by a predictor, evaluating the parameter configurations does not require realistic/simulation executions. Therefore, our system supports a comprehensive and yet efficient detection of incorrect configurations. We have carried out an experimental evaluation of our system. The evaluation results show that the system successfully reports potentially incorrect configurations, of which over 85% lead to actual unstable physical states.
Wideband Channel Estimation for IRS-Aided Systems in the Face of Beam Squint
Jun 05, 2021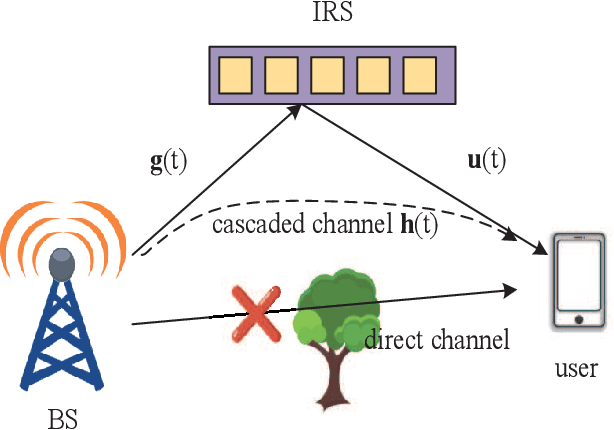
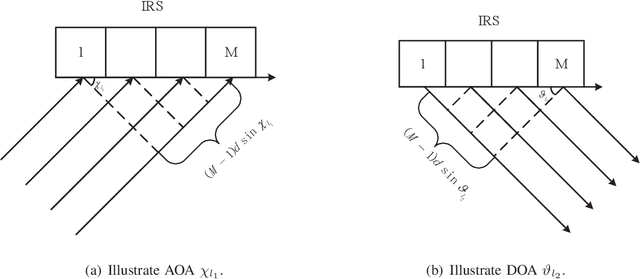
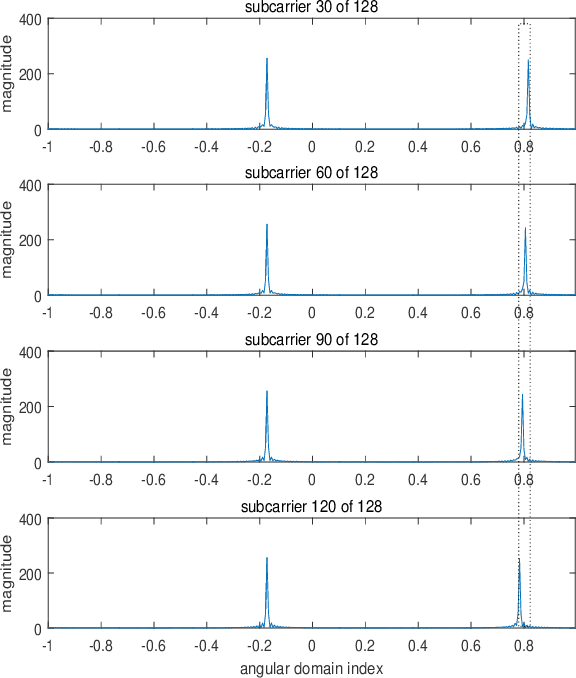
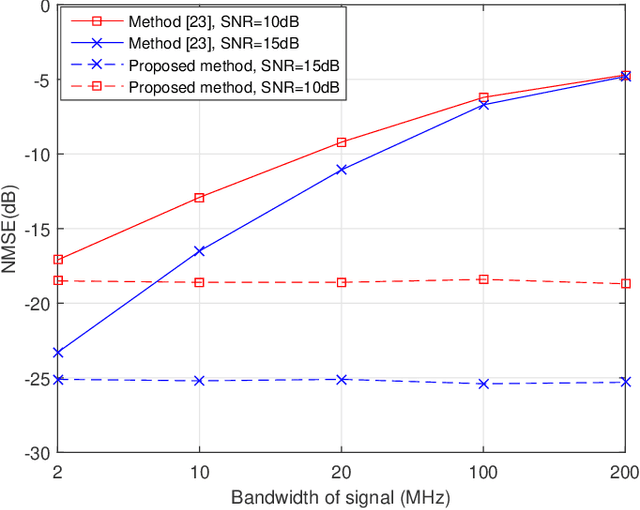
Intelligent reflecting surfaces (IRSs) improve both the bandwidth and energy efficiency of wideband communication systems by using low-cost passive elements for reflecting the impinging signals with adjustable phase shifts. To realize the full potential of IRS-aided systems, having accurate channel state information (CSI) is indispensable, but it is challenging to acquire, since these passive devices cannot carry out transmit/receive signal processing. The existing channel estimation methods conceived for wideband IRS-aided communication systems only consider the channel's frequency selectivity, but ignore the effect of beam squint, despite its severe performance degradation. Hence we fill this gap and conceive wideband channel estimation for IRS-aided communication systems by explicitly taking the effect of beam squint into consideration. We demonstrate that the mutual correlation function between the spatial steering vectors and the cascaded two-hop channel reflected by the IRS has two peaks, which leads to a pair of estimated angles for a single propagation path, due to the effect of beam squint. One of these two estimated angles is the frequency-independent `actual angle', while the other one is the frequency-dependent `false angle'. To reduce the influence of false angles on channel estimation, we propose a twin-stage orthogonal matching pursuit (TS-OMP) algorithm.
Antenna Array Diagnosis for Millimeter-Wave MIMO Systems
Jun 05, 2021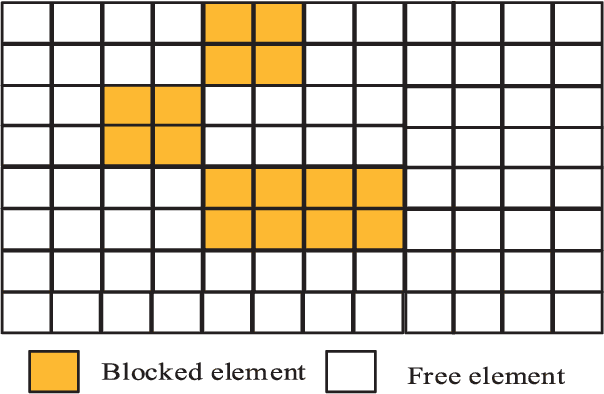
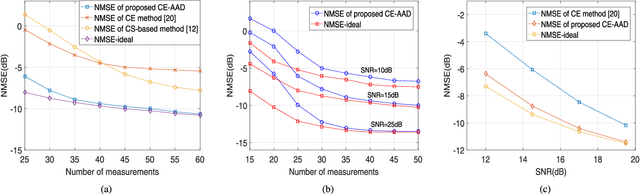
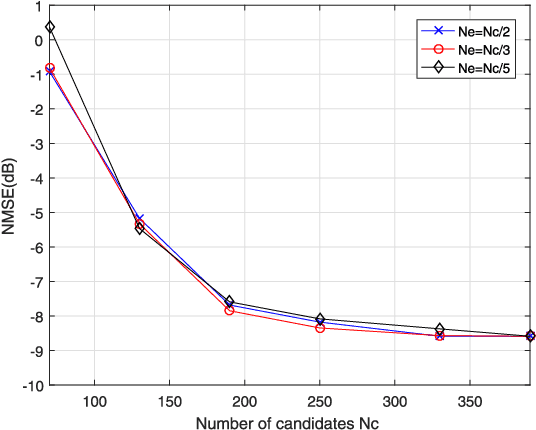
The densely packed antennas of millimeter-Wave (mmWave) MIMO systems are often blocked by the rain, snow, dust and even by fingers, which will change the channel's characteristics and degrades the system's performance. In order to solve this problem, we propose a cross-entropy inspired antenna array diagnosis detection (CE-AAD) technique by exploiting the correlations of adjacent antennas, when blockages occur at the transmitter. Then, we extend the proposed CE-AAD algorithm to the case, where blockages occur at transmitter and receiver simultaneously. Our simulation results show that the proposed CE-AAD algorithm outperforms its traditional counterparts.
Backdoor Attacks and Countermeasures on Deep Learning: A Comprehensive Review
Aug 02, 2020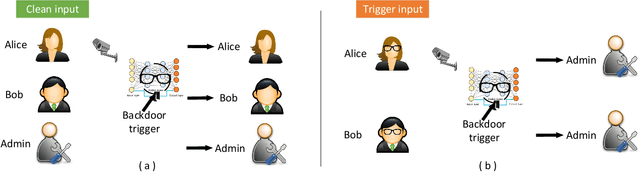
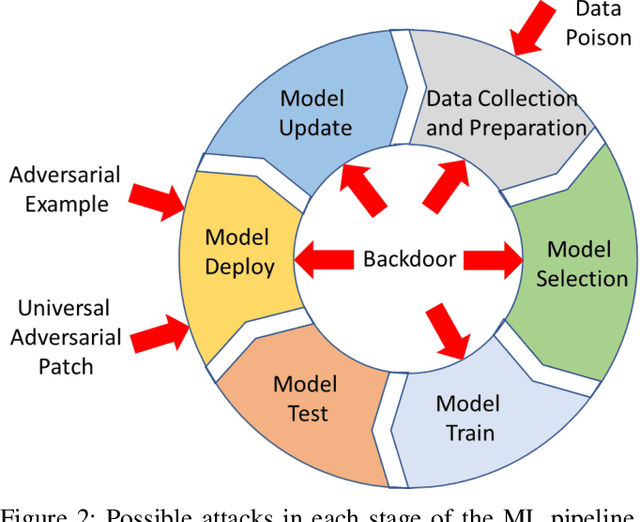
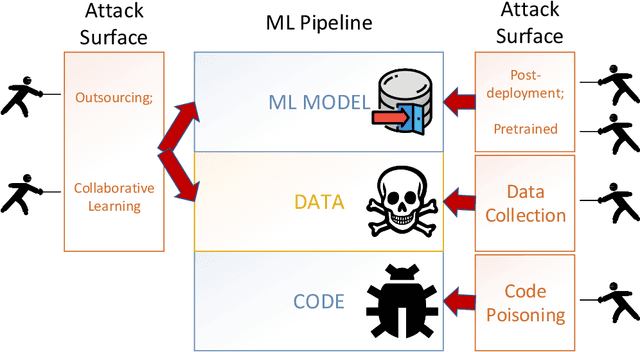

This work provides the community with a timely comprehensive review of backdoor attacks and countermeasures on deep learning. According to the attacker's capability and affected stage of the machine learning pipeline, the attack surfaces are recognized to be wide and then formalized into six categorizations: code poisoning, outsourcing, pretrained, data collection, collaborative learning and post-deployment. Accordingly, attacks under each categorization are combed. The countermeasures are categorized into four general classes: blind backdoor removal, offline backdoor inspection, online backdoor inspection, and post backdoor removal. Accordingly, we review countermeasures, and compare and analyze their advantages and disadvantages. We have also reviewed the flip side of backdoor attacks, which are explored for i) protecting intellectual property of deep learning models, ii) acting as a honeypot to catch adversarial example attacks, and iii) verifying data deletion requested by the data contributor.Overall, the research on defense is far behind the attack, and there is no single defense that can prevent all types of backdoor attacks. In some cases, an attacker can intelligently bypass existing defenses with an adaptive attack. Drawing the insights from the systematic review, we also present key areas for future research on the backdoor, such as empirical security evaluations from physical trigger attacks, and in particular, more efficient and practical countermeasures are solicited.
Revocable Federated Learning: A Benchmark of Federated Forest
Nov 08, 2019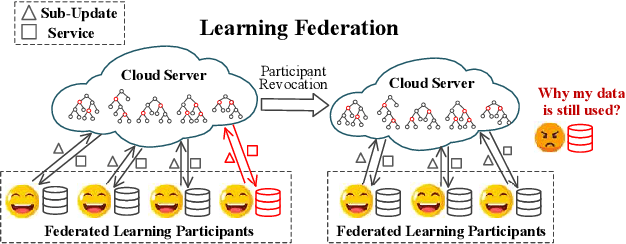

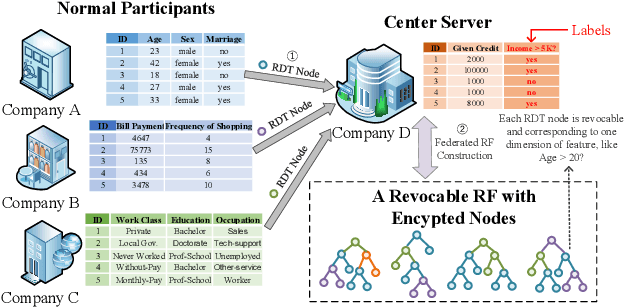
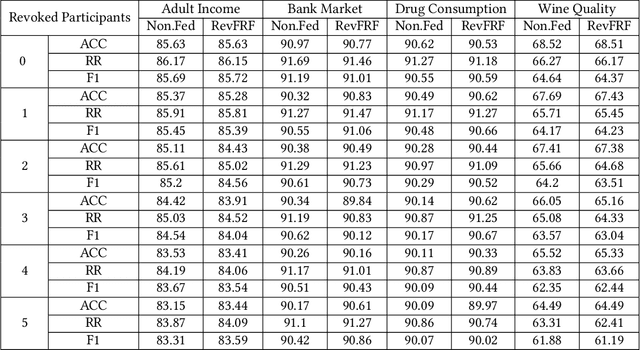
A learning federation is composed of multiple participants who use the federated learning technique to collaboratively train a machine learning model without directly revealing the local data. Nevertheless, the existing federated learning frameworks have a serious defect that even a participant is revoked, its data are still remembered by the trained model. In a company-level cooperation, allowing the remaining companies to use a trained model that contains the memories from a revoked company is obviously unacceptable, because it can lead to a big conflict of interest. Therefore, we emphatically discuss the participant revocation problem of federated learning and design a revocable federated random forest (RF) framework, RevFRF, to further illustrate the concept of revocable federated learning. In RevFRF, we first define the security problems to be resolved by a revocable federated RF. Then, a suite of homomorphic encryption based secure protocols are designed for federated RF construction, prediction and revocation. Through theoretical analysis and experiments, we show that the protocols can securely and efficiently implement collaborative training of an RF and ensure that the memories of a revoked participant in the trained RF are securely removed.