 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Generation and Mitigation of Harmful Geometry in Image-to-3D Models
May 10, 2026Recent advances in image-to-3D models have significantly improved the fidelity and accessibility of 3D content creation. Such a powerful reconstruction capability that enables creative design can also be misused by the adversary to generate harmful geometries, which can be further fabricated via 3D printers and pose real-world risks. However, such risks are largely underexplored: it remains unclear how well current image-to-3D models can produce these harmful geometries, and whether existing safeguards can reliably prevent such generation. To fill this gap, we conduct a systematic measurement study of harmful geometry generation and mitigation. We first describe this risk through three kinds of unsafe categories: direct-use physical hazards, risky templates or components, and deceptive replicas. Each category is instantiated with representative objects. We evaluate both open-source and commercial image-to-3D models under original, degraded, viewpoint-shifted, and semantically camouflaged inputs. We consider different evaluation metrics, including geometric validity, multi-view VLM-based semantic scoring, targeted human validation, and controlled physical fabrication. The results reveal a concerning reality that current image-to-3D models can effectively reconstruct the harmful geometries, while fewer than 0.3% of such geometries trigger commercial moderation flags. As a first step toward mitigation, we evaluate three representative safeguard families, including input moderation, model-level benign alignment, and output-level filtering. We find that existing safeguards have distinct weaknesses. We further develop a stacked defense that can reduce harmful retention to <1%, but still at 11% overall false-positive cost. Taken together, our findings demonstrate that the risk in current system and encourage better geometry-aware safeguards for moderation.
GRPO Privacy Is at Risk: A Membership Inference Attack Against Reinforcement Learning With Verifiable Rewards
Nov 18, 2025



Membership inference attacks (MIAs) on large language models (LLMs) pose significant privacy risks across various stages of model training. Recent advances in Reinforcement Learning with Verifiable Rewards (RLVR) have brought a profound paradigm shift in LLM training, particularly for complex reasoning tasks. However, the on-policy nature of RLVR introduces a unique privacy leakage pattern: since training relies on self-generated responses without fixed ground-truth outputs, membership inference must now determine whether a given prompt (independent of any specific response) is used during fine-tuning. This creates a threat where leakage arises not from answer memorization. To audit this novel privacy risk, we propose Divergence-in-Behavior Attack (DIBA), the first membership inference framework specifically designed for RLVR. DIBA shifts the focus from memorization to behavioral change, leveraging measurable shifts in model behavior across two axes: advantage-side improvement (e.g., correctness gain) and logit-side divergence (e.g., policy drift). Through comprehensive evaluations, we demonstrate that DIBA significantly outperforms existing baselines, achieving around 0.8 AUC and an order-of-magnitude higher TPR@0.1%FPR. We validate DIBA's superiority across multiple settings--including in-distribution, cross-dataset, cross-algorithm, black-box scenarios, and extensions to vision-language models. Furthermore, our attack remains robust under moderate defensive measures. To the best of our knowledge, this is the first work to systematically analyze privacy vulnerabilities in RLVR, revealing that even in the absence of explicit supervision, training data exposure can be reliably inferred through behavioral traces.
Improving Sustainability of Adversarial Examples in Class-Incremental Learning
Nov 12, 2025



Current adversarial examples (AEs) are typically designed for static models. However, with the wide application of Class-Incremental Learning (CIL), models are no longer static and need to be updated with new data distributed and labeled differently from the old ones. As a result, existing AEs often fail after CIL updates due to significant domain drift. In this paper, we propose SAE to enhance the sustainability of AEs against CIL. The core idea of SAE is to enhance the robustness of AE semantics against domain drift by making them more similar to the target class while distinguishing them from all other classes. Achieving this is challenging, as relying solely on the initial CIL model to optimize AE semantics often leads to overfitting. To resolve the problem, we propose a Semantic Correction Module. This module encourages the AE semantics to be generalized, based on a visual-language model capable of producing universal semantics. Additionally, it incorporates the CIL model to correct the optimization direction of the AE semantics, guiding them closer to the target class. To further reduce fluctuations in AE semantics, we propose a Filtering-and-Augmentation Module, which first identifies non-target examples with target-class semantics in the latent space and then augments them to foster more stable semantics. Comprehensive experiments demonstrate that SAE outperforms baselines by an average of 31.28% when updated with a 9-fold increase in the number of classes.
Backdoor Defense with Machine Unlearning
Jan 24, 2022



Backdoor injection attack is an emerging threat to the security of neural networks, however, there still exist limited effective defense methods against the attack. In this paper, we propose BAERASE, a novel method that can erase the backdoor injected into the victim model through machine unlearning. Specifically, BAERASE mainly implements backdoor defense in two key steps. First, trigger pattern recovery is conducted to extract the trigger patterns infected by the victim model. Here, the trigger pattern recovery problem is equivalent to the one of extracting an unknown noise distribution from the victim model, which can be easily resolved by the entropy maximization based generative model. Subsequently, BAERASE leverages these recovered trigger patterns to reverse the backdoor injection procedure and induce the victim model to erase the polluted memories through a newly designed gradient ascent based machine unlearning method. Compared with the previous machine unlearning solutions, the proposed approach gets rid of the reliance on the full access to training data for retraining and shows higher effectiveness on backdoor erasing than existing fine-tuning or pruning methods. Moreover, experiments show that BAERASE can averagely lower the attack success rates of three kinds of state-of-the-art backdoor attacks by 99\% on four benchmark datasets.
Learn to Forget: User-Level Memorization Elimination in Federated Learning
Mar 24, 2020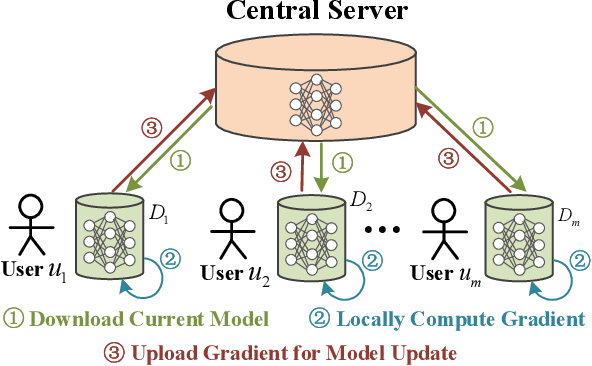
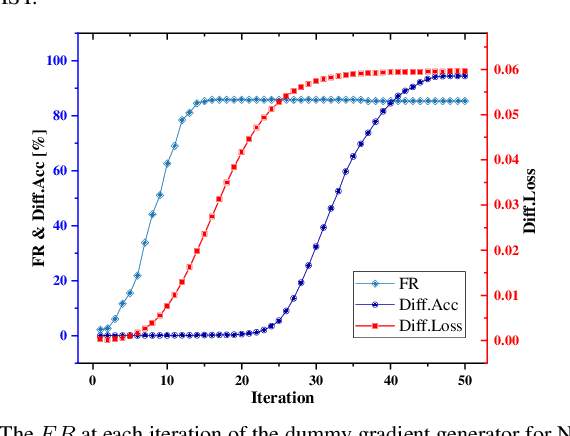
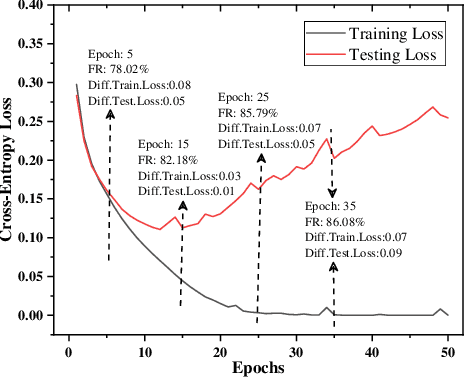
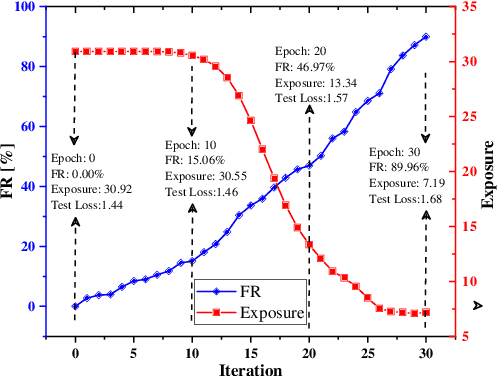
Federated learning is a decentralized machine learning technique that evokes widespread attention in both the research field and the real-world market. However, the current privacy-preserving federated learning scheme only provides a secure way for the users to contribute their private data but never leaves a way to withdraw the contribution to model update. Such an irreversible setting potentially breaks the regulations about data protection and increases the risk of data extraction. To resolve the problem, this paper describes a novel concept for federated learning, called memorization elimination. Based on the concept, we propose \sysname, a federated learning framework that allows the user to eliminate the memorization of its private data in the trained model. Specifically, each user in \sysname is deployed with a trainable dummy gradient generator. After steps of training, the generator can produce dummy gradients to stimulate the neurons of a machine learning model to eliminate the memorization of the specific data. Also, we prove that the additional memorization elimination service of \sysname does not break the common procedure of federated learning or lower its security.
Revocable Federated Learning: A Benchmark of Federated Forest
Nov 08, 2019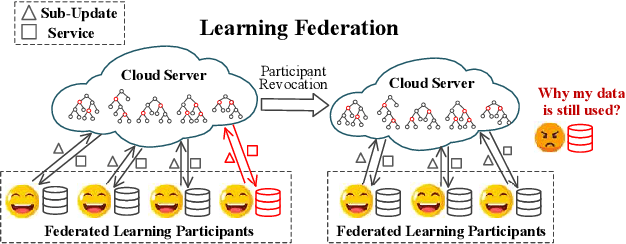

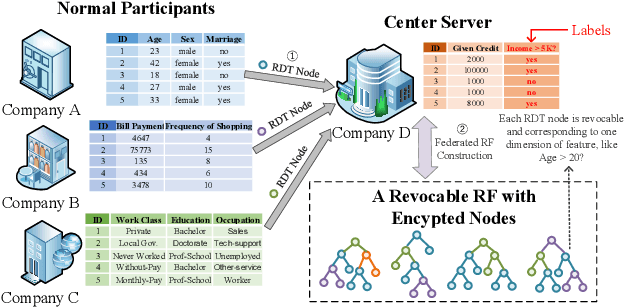
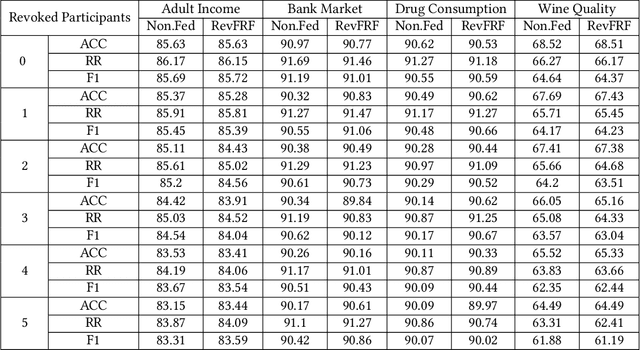
A learning federation is composed of multiple participants who use the federated learning technique to collaboratively train a machine learning model without directly revealing the local data. Nevertheless, the existing federated learning frameworks have a serious defect that even a participant is revoked, its data are still remembered by the trained model. In a company-level cooperation, allowing the remaining companies to use a trained model that contains the memories from a revoked company is obviously unacceptable, because it can lead to a big conflict of interest. Therefore, we emphatically discuss the participant revocation problem of federated learning and design a revocable federated random forest (RF) framework, RevFRF, to further illustrate the concept of revocable federated learning. In RevFRF, we first define the security problems to be resolved by a revocable federated RF. Then, a suite of homomorphic encryption based secure protocols are designed for federated RF construction, prediction and revocation. Through theoretical analysis and experiments, we show that the protocols can securely and efficiently implement collaborative training of an RF and ensure that the memories of a revoked participant in the trained RF are securely removed.