 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolve the Puzzle of Instance Segmentation in Videos: A Weakly Supervised Framework with Spatio-Temporal Collaboration
Dec 15, 2022



Instance segmentation in videos, which aims to segment and track multiple objects in video frames, has garnered a flurry of research attention in recent years. In this paper, we present a novel weakly supervised framework with \textbf{S}patio-\textbf{T}emporal \textbf{C}ollaboration for instance \textbf{Seg}mentation in videos, namely \textbf{STC-Seg}. Concretely, STC-Seg demonstrates four contributions. First, we leverage the complementary representations from unsupervised depth estimation and optical flow to produce effective pseudo-labels for training deep networks and predicting high-quality instance masks. Second, to enhance the mask generation, we devise a puzzle loss, which enables end-to-end training using box-level annotations. Third, our tracking module jointly utilizes bounding-box diagonal points with spatio-temporal discrepancy to model movements, which largely improves the robustness to different object appearances. Finally, our framework is flexible and enables image-level instance segmentation methods to operate the video-level task. We conduct an extensive set of experiments on the KITTI MOTS and YT-VIS datasets. Experimental results demonstrate that our method achieves strong performance and even outperforms fully supervised TrackR-CNN and MaskTrack R-CNN. We believe that STC-Seg can be a valuable addition to the community, as it reflects the tip of an iceberg about the innovative opportunities in the weakly supervised paradigm for instance segmentation in videos.
Video Captioning in Compressed Video
Jan 02, 2021
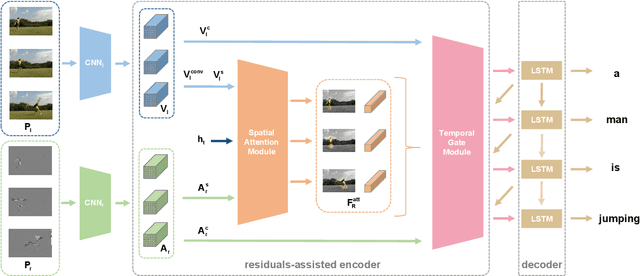
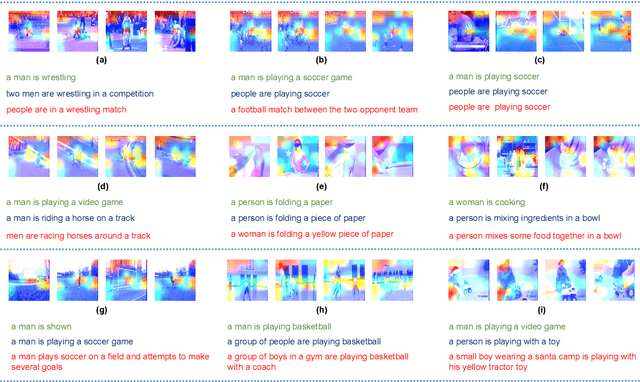

Existing approaches in video captioning concentrate on exploring global frame features in the uncompressed videos, while the free of charge and critical saliency information already encoded in the compressed videos is generally neglected. We propose a video captioning method which operates directly on the stored compressed videos. To learn a discriminative visual representation for video captioning, we design a residuals-assisted encoder (RAE), which spots regions of interest in I-frames under the assistance of the residuals frames. First, we obtain the spatial attention weights by extracting features of residuals as the saliency value of each location in I-frame and design a spatial attention module to refine the attention weights. We further propose a temporal gate module to determine how much the attended features contribute to the caption generation, which enables the model to resist the disturbance of some noisy signals in the compressed videos. Finally, Long Short-Term Memory is utilized to decode the visual representations into descriptions. We evaluate our method on two benchmark datasets and demonstrate the effectiveness of our approach.
Dynamic Feature Pyramid Networks for Object Detection
Dec 01, 2020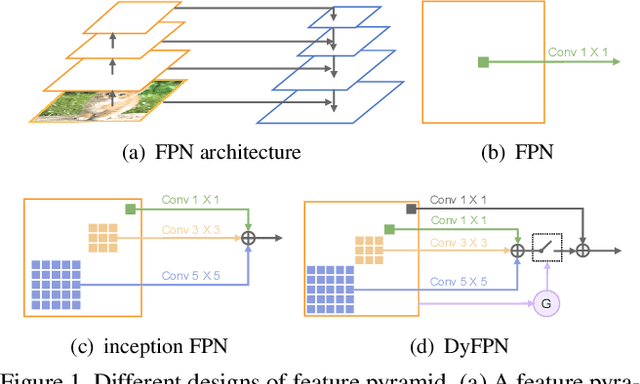
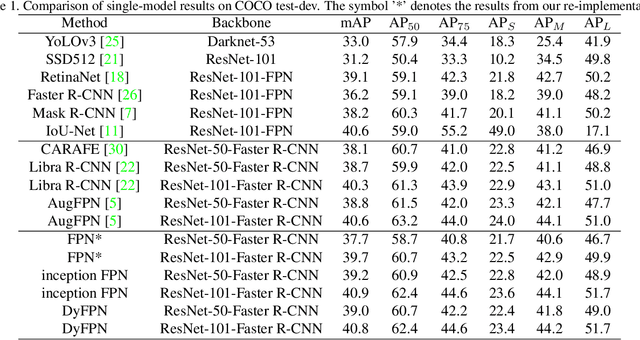
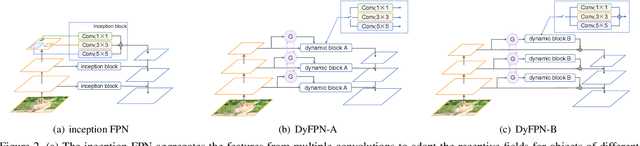
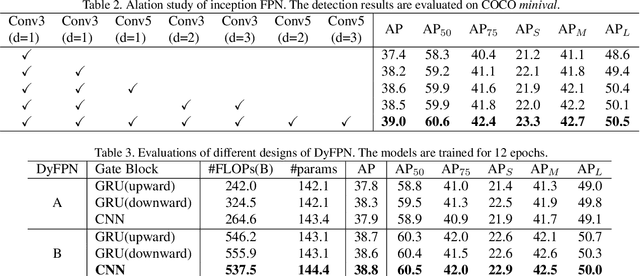
This paper studies feature pyramid network (FPN), which is a widely used module for aggregating multi-scale feature information in the object detection system. The performance gain in most of the existing works is mainly contributed to the increase of computation burden, especially the floating number operations (FLOPs). In addition, the multi-scale information within each layer in FPN has not been well investigated. To this end, we first introduce an inception FPN in which each layer contains convolution filters with different kernel sizes to enlarge the receptive field and integrate more useful information. Moreover, we point out that not all objects need such a complicated calculation module and propose a new dynamic FPN (DyFPN). Each layer in the DyFPN consists of multiple branches with different computational costs. Specifically, the output features of DyFPN will be calculated by using the adaptively selected branch according to a learnable gating operation. Therefore, the proposed method can provide a more efficient dynamic inference for achieving a better trade-off between accuracy and detection performance. Extensive experiments conducted on benchmarks demonstrate that the proposed DyFPN significantly improves performance with the optimal allocation of computation resources. For instance, replacing the FPN with the inception FPN improves detection accuracy by 1.6 AP using the Faster R-CNN paradigm on COCO minival, and the DyFPN further reduces about 40% of its FLOPs while maintaining similar performance.
Multimodal Aggregation Approach for Memory Vision-Voice Indoor Navigation with Meta-Learning
Sep 01, 2020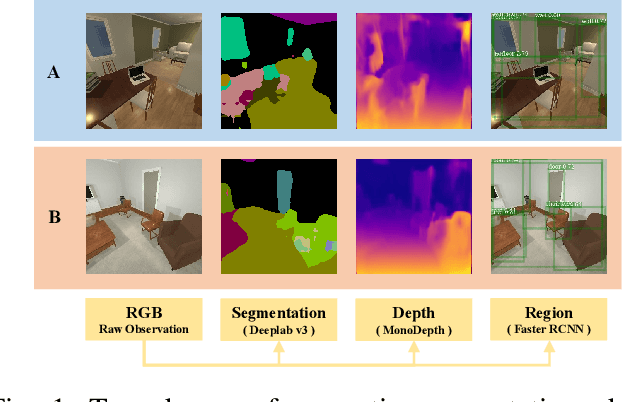
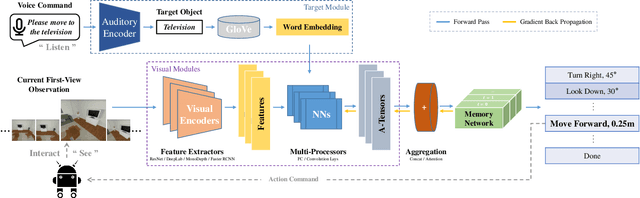
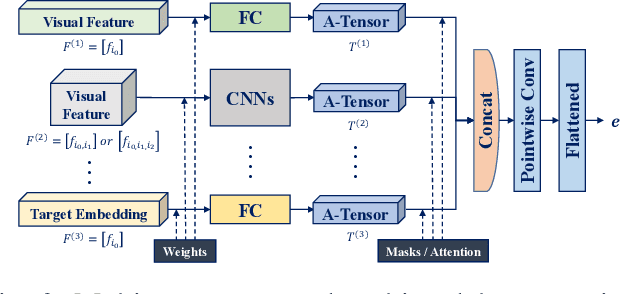
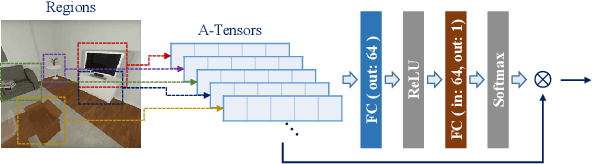
Vision and voice are two vital keys for agents' interaction and learning. In this paper, we present a novel indoor navigation model called Memory Vision-Voice Indoor Navigation (MVV-IN), which receives voice commands and analyzes multimodal information of visual observation in order to enhance robots' environment understanding. We make use of single RGB images taken by a first-view monocular camera. We also apply a self-attention mechanism to keep the agent focusing on key areas. Memory is important for the agent to avoid repeating certain tasks unnecessarily and in order for it to adapt adequately to new scenes, therefore, we make use of meta-learning. We have experimented with various functional features extracted from visual observation. Comparative experiments prove that our methods outperform state-of-the-art baselines.
Crowd Video Captioning
Nov 13, 2019
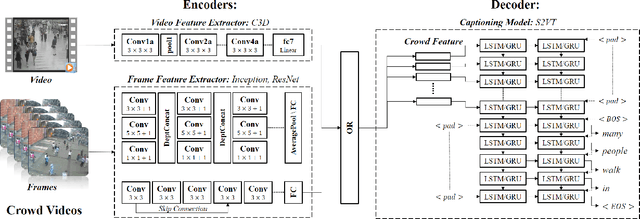

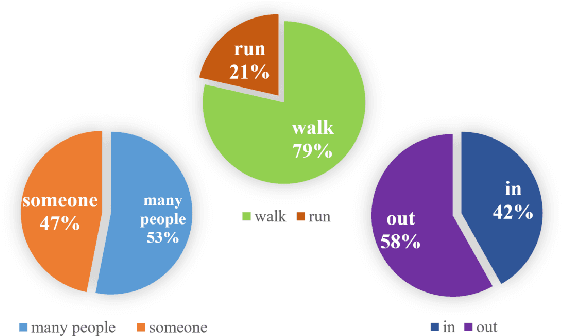
Describing a video automatically with natural language is a challenging task in the area of computer vision. In most cases, the on-site situation of great events is reported in news, but the situation of the off-site spectators in the entrance and exit is neglected which also arouses people's interest. Since the deployment of reporters in the entrance and exit costs lots of manpower, how to automatically describe the behavior of a crowd of off-site spectators is significant and remains a problem. To tackle this problem, we propose a new task called crowd video captioning (CVC) which aims to describe the crowd of spectators. We also provide baseline methods for this task and evaluate them on the dataset WorldExpo'10. Our experimental results show that captioning models have a fairly deep understanding of the crowd in video and perform satisfactorily in the CVC task.
Deep Robotic Prediction with hierarchical RGB-D Fusion
Sep 17, 2019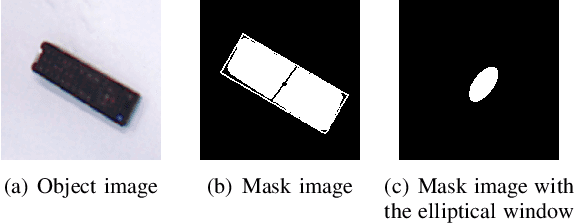
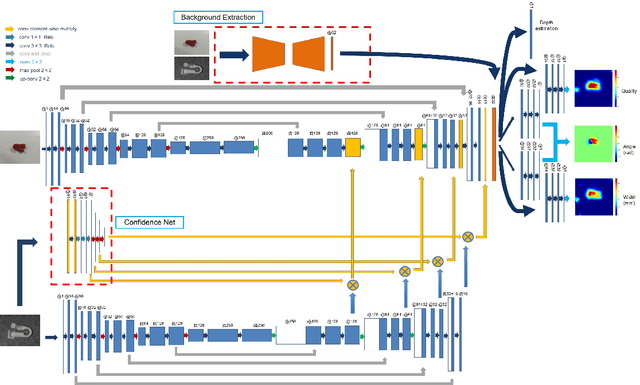


Robotic arm grasping is a fundamental operation in robotic control task goals. Most current methods for robotic grasping focus on RGB-D policy in the table surface scenario or 3D point cloud analysis and inference in the 3D space. Comparing to these methods, we propose a novel real-time multimodal hierarchical encoder-decoder neural network that fuses RGB and depth data to realize robotic humanoid grasping in 3D space with only partial observation. The quantification of raw depth data's uncertainty and depth estimation fusing RGB is considered. We develop a general labeling method to label ground-truth on common RGB-D datasets. We evaluate the effectiveness and performance of our method on a physical robot setup and our method achieves over 90\% success rate in both table surface and 3D space scenarios.
Cooperative event-based rigid formation control
Jan 11, 2019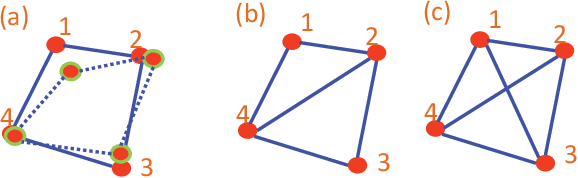
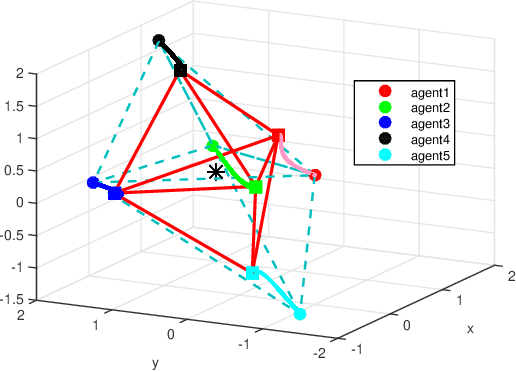
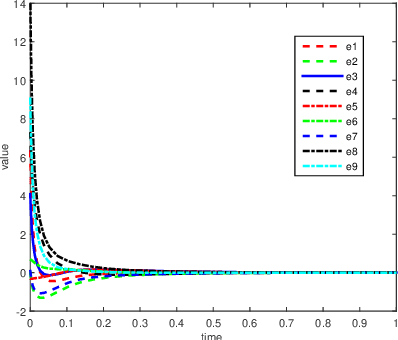
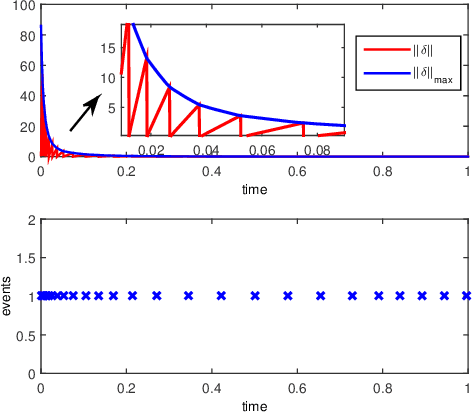
This paper discusses cooperative stabilization control of rigid formations via an event-based approach. We first design a centralized event-based formation control system, in which a central event controller determines the next triggering time and broadcasts the event signal to all the agents for control input update. We then build on this approach to propose a distributed event control strategy, in which each agent can use its local event trigger and local information to update the control input at its own event time. For both cases, the triggering condition, event function and triggering behavior are discussed in detail, and the exponential convergence of the event-based formation system is guaranteed.
Collaborative target-tracking control using multiple autonomous fixed-wing UAVs with constant speeds: Theory and experiments
Sep 29, 2018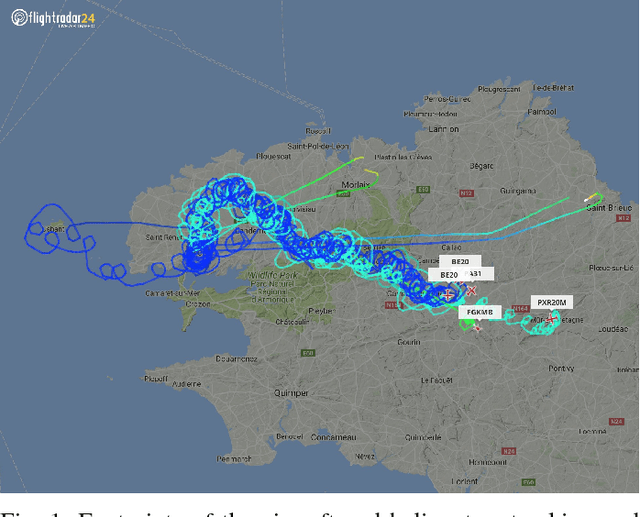


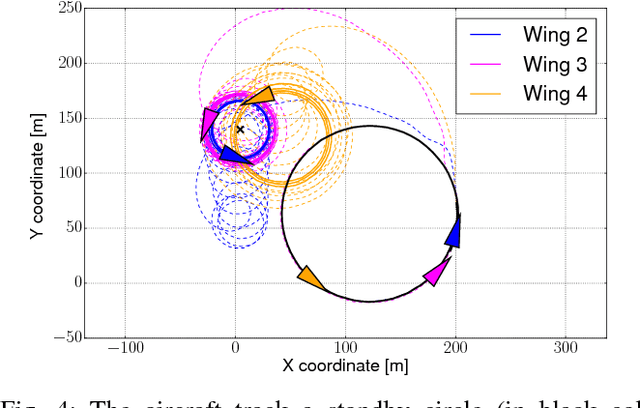
This paper considers a collaborative tracking control problem using a group of fixed-wing UAVs with constant and non-identical speeds. The dynamics of fixed-wing UAVs are modelled by unicycle-type equations, with nonholonomic constraints by assuming that UAVs fly at constant attitudes in the nominal operation mode. The control focus is on the design of a collective tracking controller such that all fixed-wing UAVs as a group can collaboratively track a desired target's position and velocity. We construct a reference velocity that includes both the target's velocity and position as feedback, which is to be tracked by the group centroid. In this way, all vehicles' headings are controlled such that the group centroid follows a reference trajectory that successfully tracks the target's trajectory. We consider three cases of reference velocity tracking: the constant velocity case, the turning velocity case with constant speed, and the time-varying velocity case. An additive spacing controller is further devised to ensure that all vehicles stay close to the group centroid trajectory. Trade-offs and performance limitations of the target tracking control due to the constant-speed constraint are also discussed in detail. Experimental results with three fixed-wing UAVs tracking a target rotorcraft are shown to validate the effectiveness and performance of the proposed tracking controllers.