 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Deep Learning of Non-local Features for Hyperspectral Image Classification
Aug 02, 2020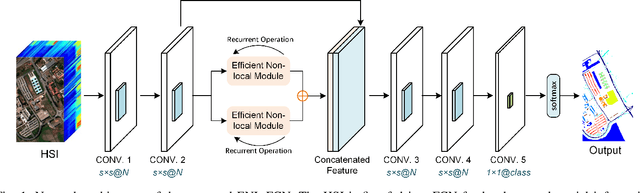
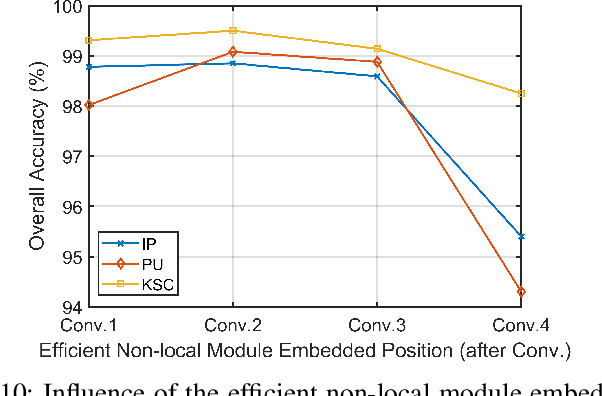
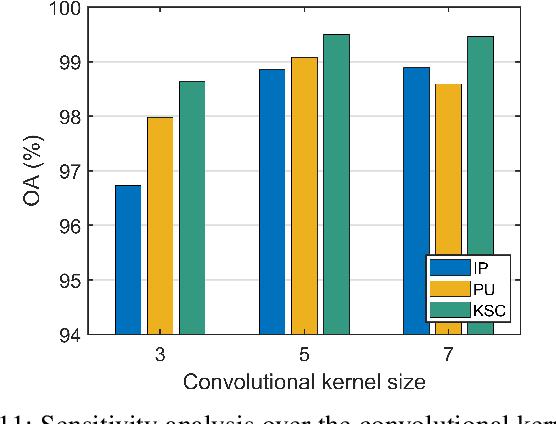
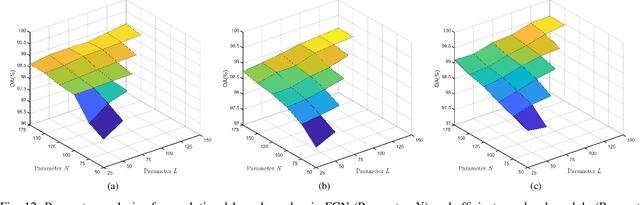
Deep learning based methods, such as Convolution Neural Network (CNN), have demonstrated their efficiency in hyperspectral image (HSI) classification. These methods can automatically learn spectral-spatial discriminative features within local patches. However, for each pixel in an HSI, it is not only related to its nearby pixels but also has connections to pixels far away from itself. Therefore, to incorporate the long-range contextual information, a deep fully convolutional network (FCN) with an efficient non-local module, named ENL-FCN, is proposed for HSI classification. In the proposed framework, a deep FCN considers an entire HSI as input and extracts spectral-spatial information in a local receptive field. The efficient non-local module is embedded in the network as a learning unit to capture the long-range contextual information. Different from the traditional non-local neural networks, the long-range contextual information is extracted in a specially designed criss-cross path for computation efficiency. Furthermore, by using a recurrent operation, each pixel's response is aggregated from all pixels of HSI. The benefits of our proposed ENL-FCN are threefold: 1) the long-range contextual information is incorporated effectively, 2) the efficient module can be freely embedded in a deep neural network in a plug-and-play fashion, and 3) it has much fewer learning parameters and requires less computational resources. The experiments conducted on three popular HSI datasets demonstrate that the proposed method achieves state-of-the-art classification performance with lower computational cost in comparison with several leading deep neural networks for HSI.
GradAug: A New Regularization Method for Deep Neural Networks
Jun 14, 2020
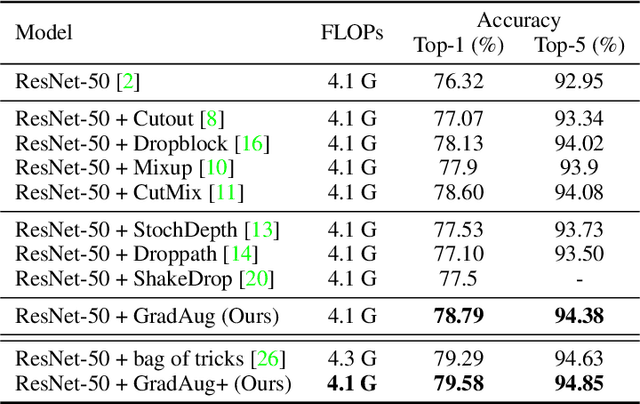
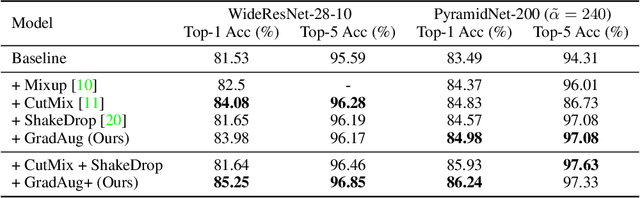
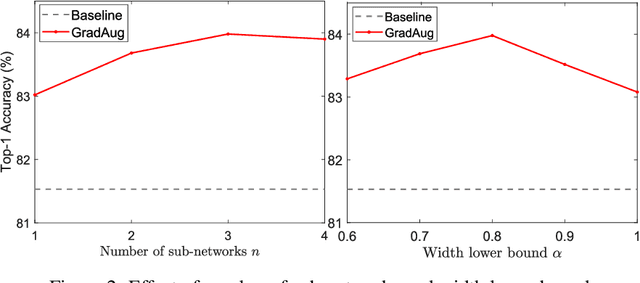
We propose a new regularization method to alleviate over-fitting in deep neural networks. The key idea is utilizing randomly transformed training samples to regularize a set of sub-networks, which are originated by sampling the width of the original network, in the training process. As such, the proposed method introduces self-guided disturbances to the raw gradients of the network and therefore is termed as Gradient Augmentation (GradAug). We demonstrate that GradAug can help the network learn well-generalized and more diverse representations. Moreover, it is easy to implement and can be applied to various structures and applications. GradAug improves ResNet-50 to 78.79% on ImageNet classification, which is a new state-of-the-art accuracy. By combining with CutMix, it further boosts the performance to 79.58%, which outperforms an ensemble of advanced training tricks. The generalization ability is evaluated on COCO object detection and instance segmentation where GradAug significantly surpasses other state-of-the-art methods. GradAug is also robust to image distortions and adversarial attacks and is highly effective in the low data regimes.
Revisiting Street-to-Aerial View Image Geo-localization and Orientation Estimation
May 23, 2020
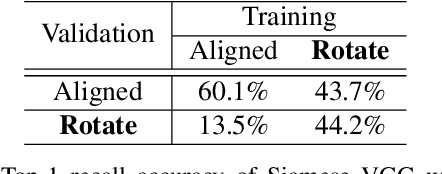

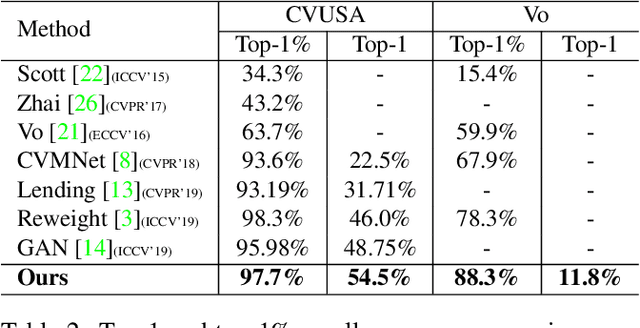
Street-to-aerial image geo-localization, which matches a query street-view image to the GPS-tagged aerial images in a reference set, has attracted increasing attention recently. In this paper, we revisit this problem and point out the ignored issue about image alignment information. We show that the performance of a simple Siamese network is highly dependent on the alignment setting and the comparison of previous works can be unfair if they have different assumptions. Instead of focusing on the feature extraction under the alignment assumption, we show that improvements in metric learning techniques significantly boost the performance regardless of the alignment. Without leveraging the alignment information, our pipeline outperforms previous works on both panorama and cropped datasets. Furthermore, we conduct visualization to help understand the learned model and the effect of alignment information using Grad-CAM. With our discovery on the approximate rotation-invariant activation maps, we propose a novel method to estimate the orientation/alignment between a pair of cross-view images with unknown alignment information. It achieves state-of-the-art results on the CVUSA dataset.
Density Map Guided Object Detection in Aerial Images
Apr 12, 2020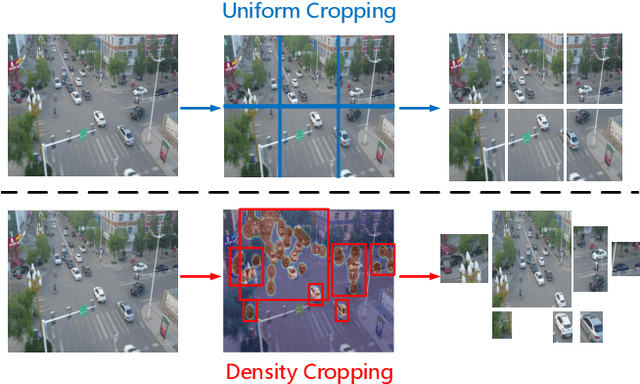

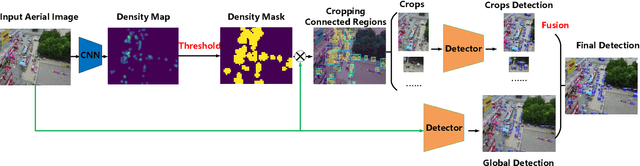
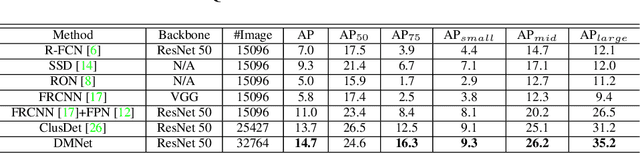
Object detection in high-resolution aerial images is a challenging task because of 1) the large variation in object size, and 2) non-uniform distribution of objects. A common solution is to divide the large aerial image into small (uniform) crops and then apply object detection on each small crop. In this paper, we investigate the image cropping strategy to address these challenges. Specifically, we propose a Density-Map guided object detection Network (DMNet), which is inspired from the observation that the object density map of an image presents how objects distribute in terms of the pixel intensity of the map. As pixel intensity varies, it is able to tell whether a region has objects or not, which in turn provides guidance for cropping images statistically. DMNet has three key components: a density map generation module, an image cropping module and an object detector. DMNet generates a density map and learns scale information based on density intensities to form cropping regions. Extensive experiments show that DMNet achieves state-of-the-art performance on two popular aerial image datasets, i.e. VisionDrone and UAVDT.
Video Anomaly Detection for Smart Surveillance
Apr 11, 2020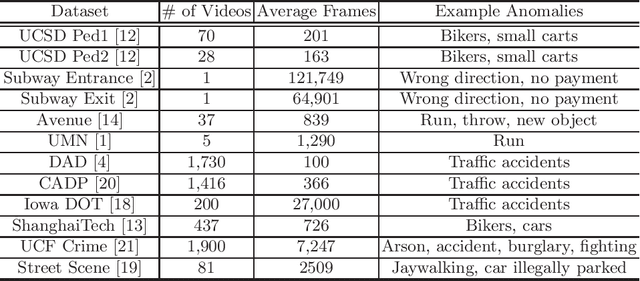
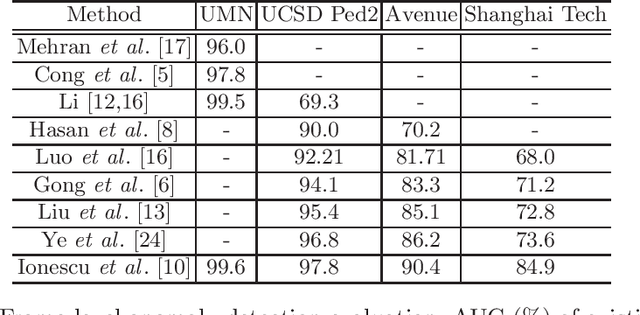
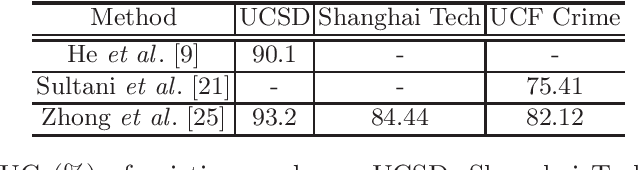
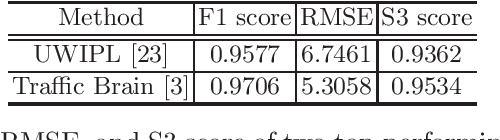
In modern intelligent video surveillance systems, automatic anomaly detection through computer vision analytics plays a pivotal role which not only significantly increases monitoring efficiency but also reduces the burden on live monitoring. Anomalies in videos are broadly defined as events or activities that are unusual and signify irregular behavior. The goal of anomaly detection is to temporally or spatially localize the anomaly events in video sequences. Temporal localization (i.e. indicating the start and end frames of the anomaly event in a video) is referred to as frame-level detection. Spatial localization, which is more challenging, means to identify the pixels within each anomaly frame that correspond to the anomaly event. This setting is usually referred to as pixel-level detection. In this paper, we provide a brief overview of the recent research progress on video anomaly detection and highlight a few future research directions.
A closer look at network resolution for efficient network design
Sep 27, 2019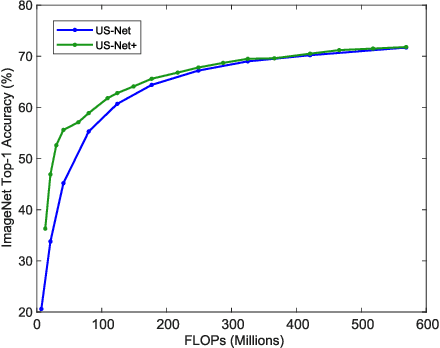

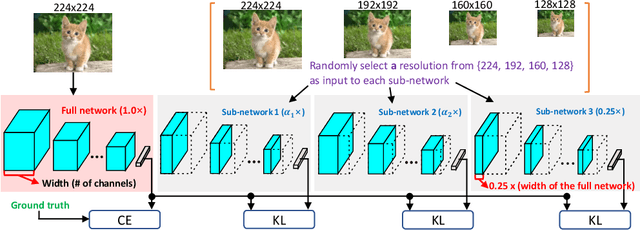
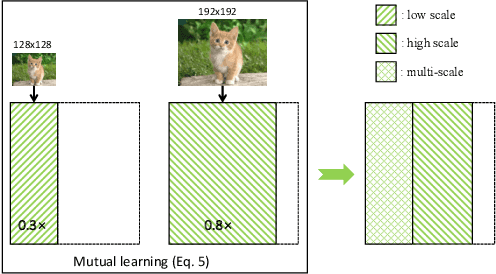
There is growing interest in designing lightweight neural networks for mobile and embedded vision applications. Previous works typically reduce computations from the structure level. For example, group convolution based methods reduce computations by factorizing a vanilla convolution into depth-wise and point-wise convolutions. Pruning based methods prune redundant connections in the network structure. In this paper, we explore the importance of network input for achieving optimal accuracy-efficiency trade-off. Reducing input scale is a simple yet effective way to reduce computational cost. It does not require careful network module design, specific hardware optimization and network retraining after pruning. Moreover, different input scales contain different representations to learn. We propose a framework to mutually learn from different input resolutions and network widths. With the shared knowledge, our framework is able to find better width-resolution balance and capture multi-scale representations. It achieves consistently better ImageNet top-1 accuracy over US-Net under different computation constraints, and outperforms the best compound scale model of EfficientNet by 1.5%. The superiority of our framework is also validated on COCO object detection and instance segmentation as well as transfer learning.
Visual Explanation for Deep Metric Learning
Sep 27, 2019
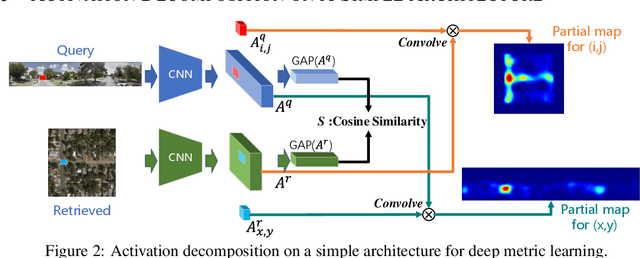
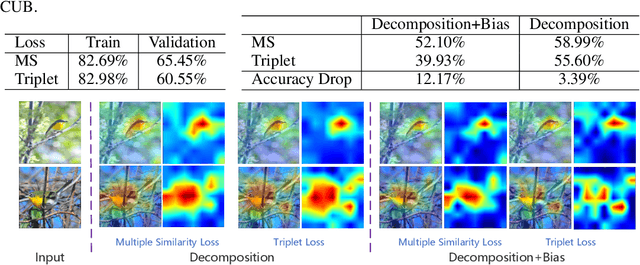
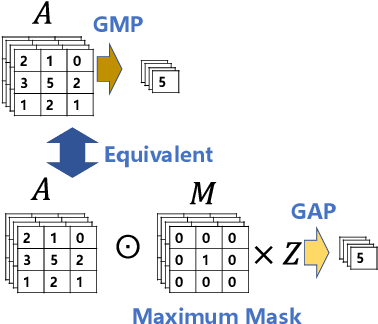
This work explores the visual explanation for deep metric learning and its applications. As an important problem for learning representation, metric learning has attracted much attention recently, while the interpretation of such model is not as well studied as classification. To this end, we propose an intuitive idea to show where contributes the most to the overall similarity of two input images by decomposing the final activation. Instead of only providing the overall activation map of each image, we propose to generate point-to-point activation intensity between two images so that the relationship between different regions is uncovered. We show that the proposed framework can be directly deployed to a large range of metric learning applications and provides valuable information for understanding the model. Furthermore, our experiments show its effectiveness on two potential applications, i.e. cross-view pattern discovery and interactive retrieval.