 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Natural Language Processing for LinkedIn Search Systems
Jul 30, 2021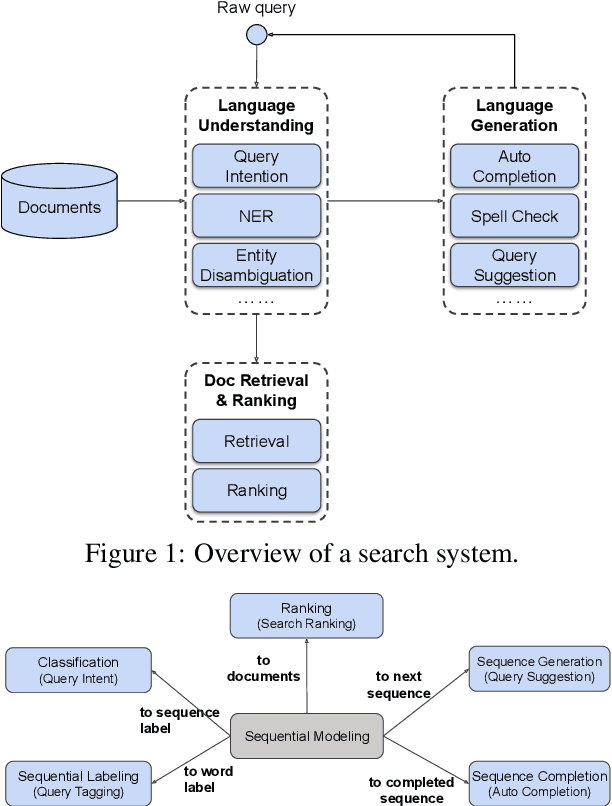
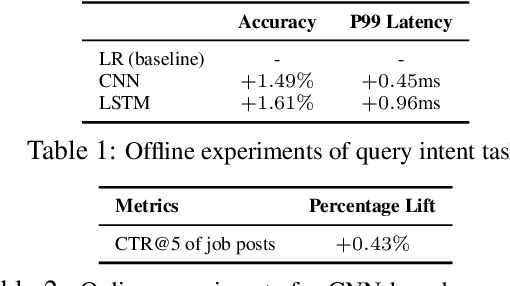
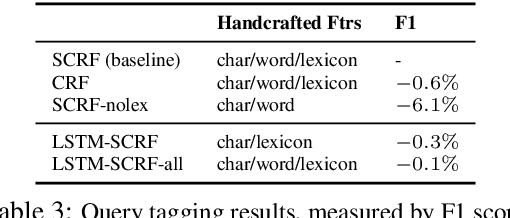
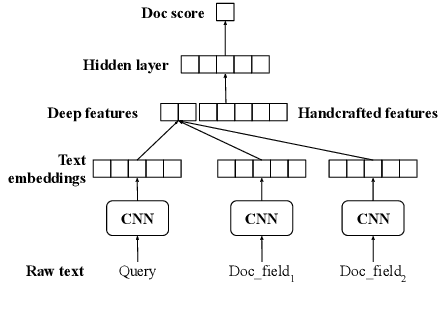
Many search systems work with large amounts of natural language data, e.g., search queries, user profiles and documents, where deep learning based natural language processing techniques (deep NLP) can be of great help. In this paper, we introduce a comprehensive study of applying deep NLP techniques to five representative tasks in search engines. Through the model design and experiments of the five tasks, readers can find answers to three important questions: (1) When is deep NLP helpful/not helpful in search systems? (2) How to address latency challenges? (3) How to ensure model robustness? This work builds on existing efforts of LinkedIn search, and is tested at scale on a commercial search engine. We believe our experiences can provide useful insights for the industry and research communities.
Towards Understanding the Optimal Behaviors of Deep Active Learning Algorithms
Dec 29, 2020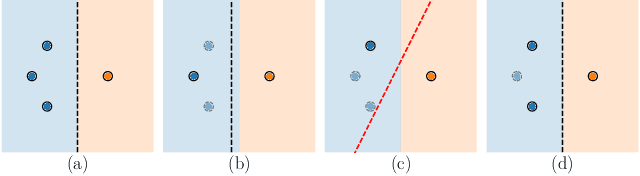

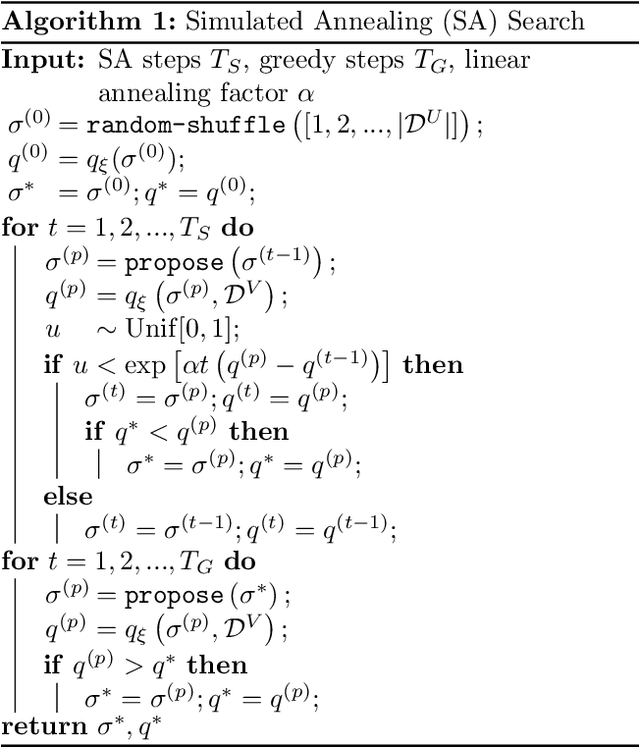
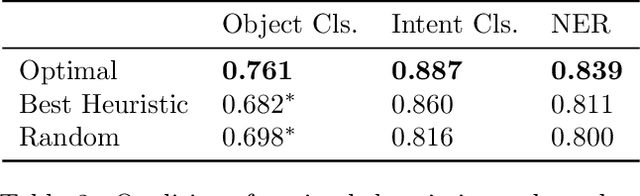
Active learning (AL) algorithms may achieve better performance with fewer data because the model guides the data selection process. While many algorithms have been proposed, there is little study on what the optimal AL algorithm looks like, which would help researchers understand where their models fall short and iterate on the design. In this paper, we present a simulated annealing algorithm to search for this optimal oracle and analyze it for several different tasks. We present several qualitative and quantitative insights into the optimal behavior and contrast this behavior with those of various heuristics. When augmented by with one particular insight, heuristics perform consistently better. We hope that our findings can better inform future active learning research. The code for the experiments is available at https://github.com/YilunZhou/optimal-active-learning.
Efficient Neural Query Auto Completion
Aug 06, 2020
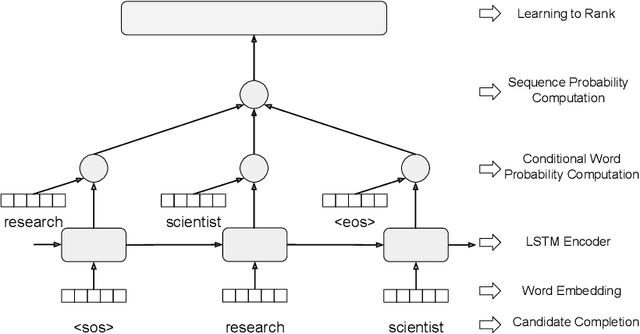
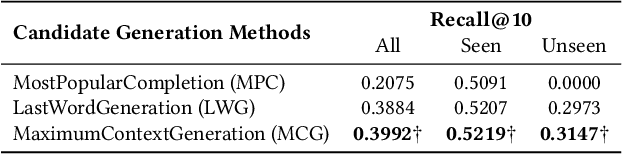
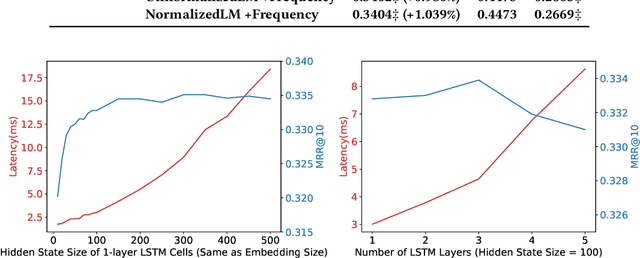
Query Auto Completion (QAC), as the starting point of information retrieval tasks, is critical to user experience. Generally it has two steps: generating completed query candidates according to query prefixes, and ranking them based on extracted features. Three major challenges are observed for a query auto completion system: (1) QAC has a strict online latency requirement. For each keystroke, results must be returned within tens of milliseconds, which poses a significant challenge in designing sophisticated language models for it. (2) For unseen queries, generated candidates are of poor quality as contextual information is not fully utilized. (3) Traditional QAC systems heavily rely on handcrafted features such as the query candidate frequency in search logs, lacking sufficient semantic understanding of the candidate. In this paper, we propose an efficient neural QAC system with effective context modeling to overcome these challenges. On the candidate generation side, this system uses as much information as possible in unseen prefixes to generate relevant candidates, increasing the recall by a large margin. On the candidate ranking side, an unnormalized language model is proposed, which effectively captures deep semantics of queries. This approach presents better ranking performance over state-of-the-art neural ranking methods and reduces $\sim$95\% latency compared to neural language modeling methods. The empirical results on public datasets show that our model achieves a good balance between accuracy and efficiency. This system is served in LinkedIn job search with significant product impact observed.
DeText: A Deep Text Ranking Framework with BERT
Aug 06, 2020

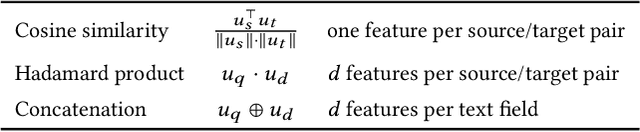
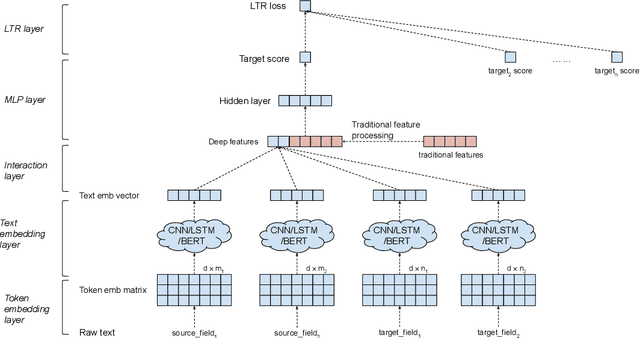
Ranking is the most important component in a search system. Mostsearch systems deal with large amounts of natural language data,hence an effective ranking system requires a deep understandingof text semantics. Recently, deep learning based natural languageprocessing (deep NLP) models have generated promising results onranking systems. BERT is one of the most successful models thatlearn contextual embedding, which has been applied to capturecomplex query-document relations for search ranking. However,this is generally done by exhaustively interacting each query wordwith each document word, which is inefficient for online servingin search product systems. In this paper, we investigate how tobuild an efficient BERT-based ranking model for industry use cases.The solution is further extended to a general ranking framework,DeText, that is open sourced and can be applied to various rankingproductions. Offline and online experiments of DeText on threereal-world search systems present significant improvement overstate-of-the-art approaches.
Pre-training via Paraphrasing
Jun 26, 2020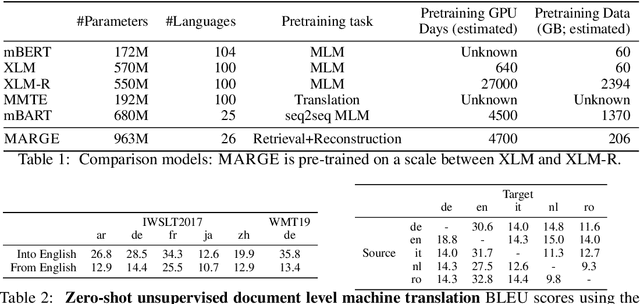
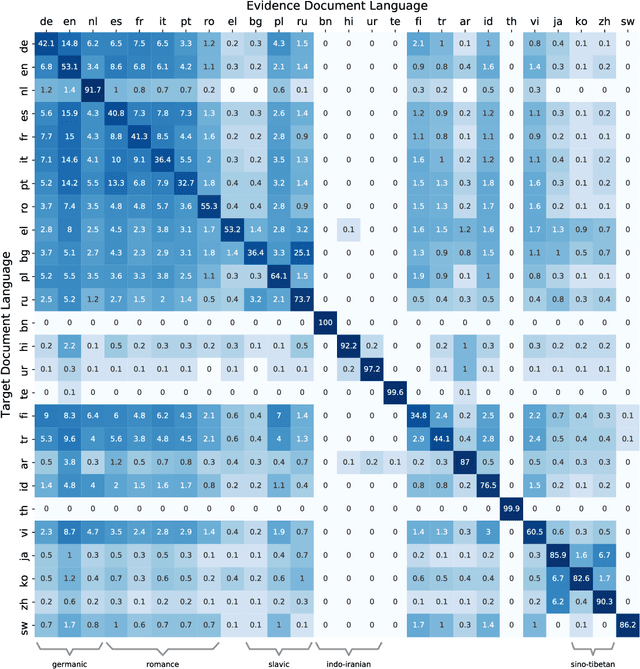
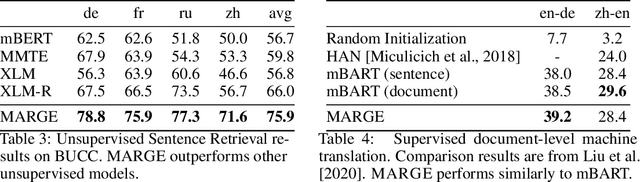
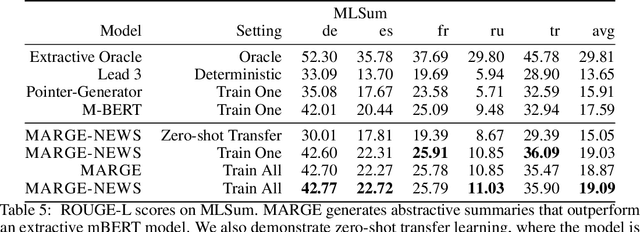
We introduce MARGE, a pre-trained sequence-to-sequence model learned with an unsupervised multi-lingual multi-document paraphrasing objective. MARGE provides an alternative to the dominant masked language modeling paradigm, where we self-supervise the reconstruction of target text by retrieving a set of related texts (in many languages) and conditioning on them to maximize the likelihood of generating the original. We show it is possible to jointly learn to do retrieval and reconstruction, given only a random initialization. The objective noisily captures aspects of paraphrase, translation, multi-document summarization, and information retrieval, allowing for strong zero-shot performance on several tasks. For example, with no additional task-specific training we achieve BLEU scores of up to 35.8 for document translation. We further show that fine-tuning gives strong performance on a range of discriminative and generative tasks in many languages, making MARGE the most generally applicable pre-training method to date.
Interactive Classification by Asking Informative Questions
Nov 09, 2019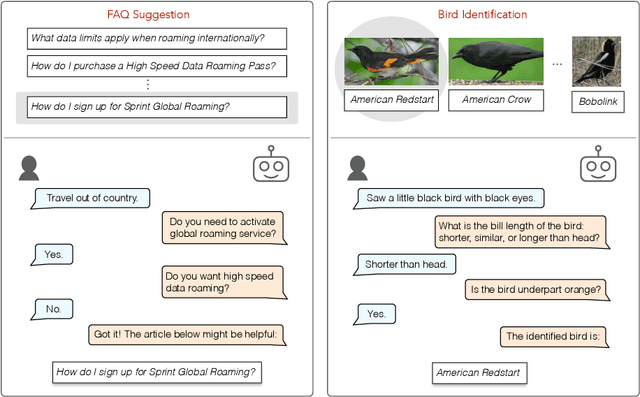
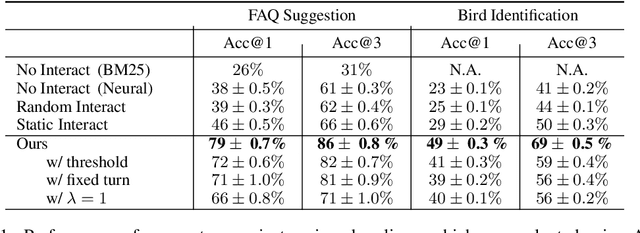
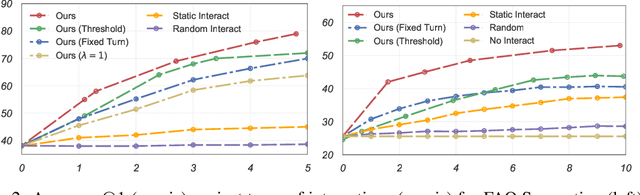
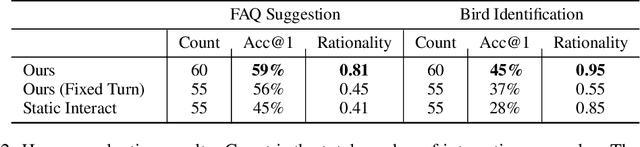
Natural language systems often rely on a single, potentially ambiguous input to make one final prediction, which may simplify the problem but degrade end user experience. Instead of making predictions with the natural language query only, we ask the user for additional information using a small number of binary and multiple-choice questions in order to better help users accomplish their goals while minimizing their effort. At each turn, our system decides between asking the most informative question or making the final classification prediction. Our approach enables bootstrapping the system using simple crowdsourcing annotations without expensive human-to-human interaction data. Evaluation demonstrates that our method substantially increases classification accuracy, while effectively balancing the number of questions with the improvement to final accuracy.
Altitude Training: Strong Bounds for Single-Layer Dropout
Oct 31, 2014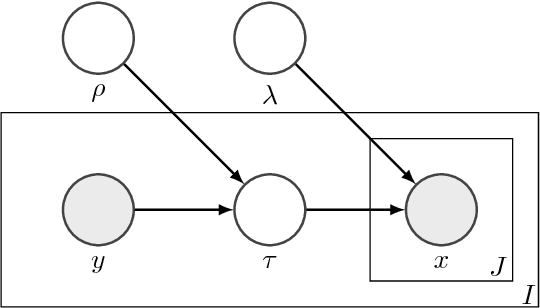
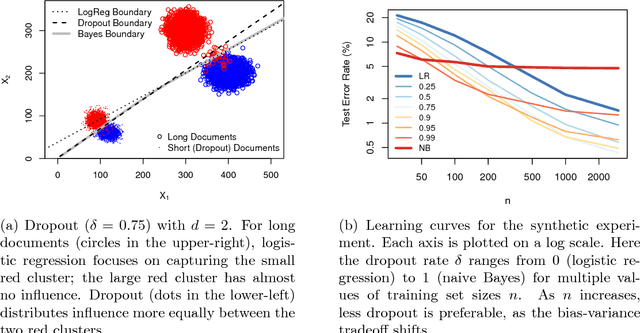
Dropout training, originally designed for deep neural networks, has been successful on high-dimensional single-layer natural language tasks. This paper proposes a theoretical explanation for this phenomenon: we show that, under a generative Poisson topic model with long documents, dropout training improves the exponent in the generalization bound for empirical risk minimization. Dropout achieves this gain much like a marathon runner who practices at altitude: once a classifier learns to perform reasonably well on training examples that have been artificially corrupted by dropout, it will do very well on the uncorrupted test set. We also show that, under similar conditions, dropout preserves the Bayes decision boundary and should therefore induce minimal bias in high dimensions.
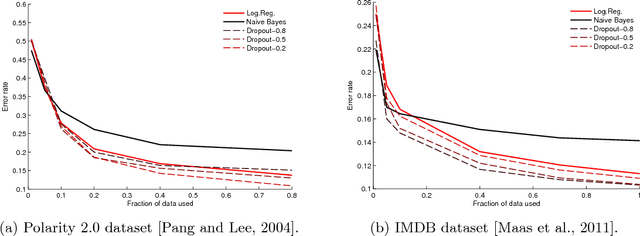
Dropout Training as Adaptive Regularization
Nov 01, 2013
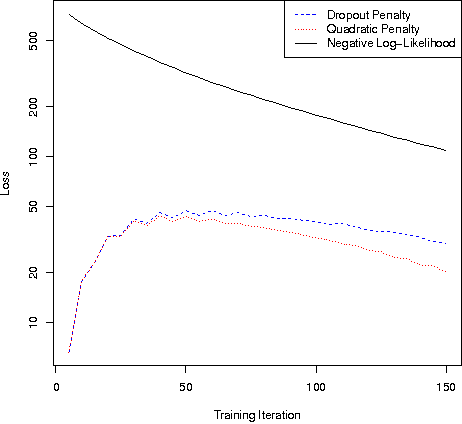

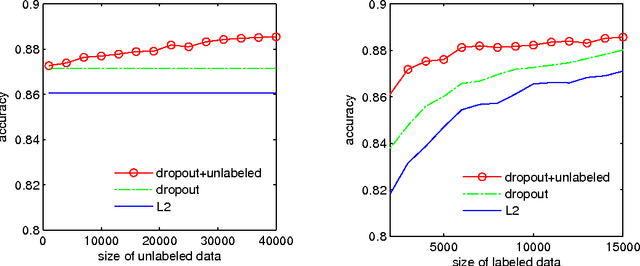
Dropout and other feature noising schemes control overfitting by artificially corrupting the training data. For generalized linear models, dropout performs a form of adaptive regularization. Using this viewpoint, we show that the dropout regularizer is first-order equivalent to an L2 regularizer applied after scaling the features by an estimate of the inverse diagonal Fisher information matrix. We also establish a connection to AdaGrad, an online learning algorithm, and find that a close relative of AdaGrad operates by repeatedly solving linear dropout-regularized problems. By casting dropout as regularization, we develop a natural semi-supervised algorithm that uses unlabeled data to create a better adaptive regularizer. We apply this idea to document classification tasks, and show that it consistently boosts the performance of dropout training, improving on state-of-the-art results on the IMDB reviews dataset.