 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTableFormer: Robust Transformer Modeling for Table-Text Encoding
Mar 01, 2022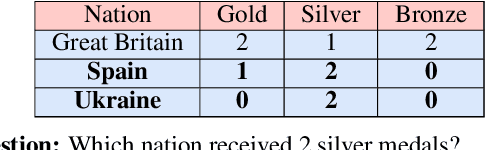
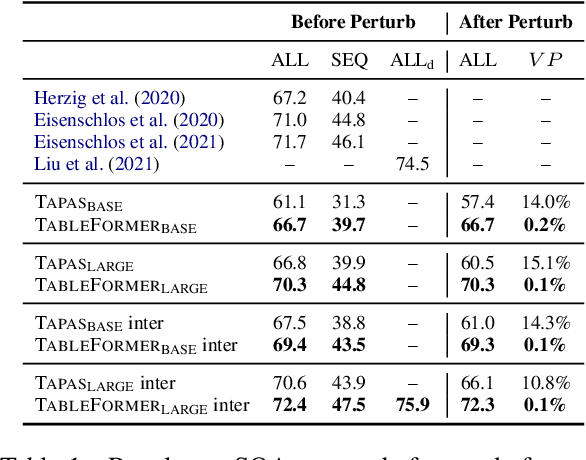
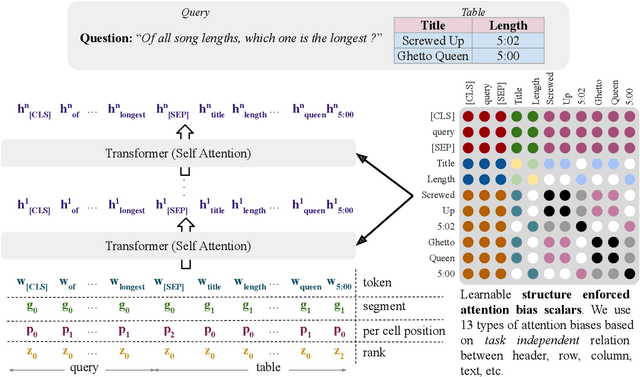
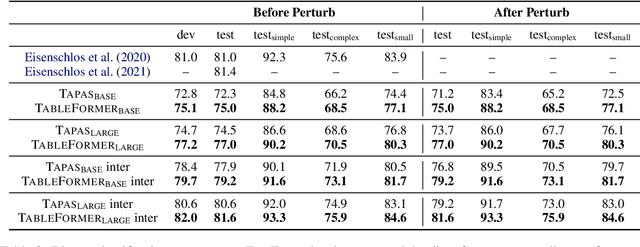
Understanding tables is an important aspect of natural language understanding. Existing models for table understanding require linearization of the table structure, where row or column order is encoded as an unwanted bias. Such spurious biases make the model vulnerable to row and column order perturbations. Additionally, prior work has not thoroughly modeled the table structures or table-text alignments, hindering the table-text understanding ability. In this work, we propose a robust and structurally aware table-text encoding architecture TableFormer, where tabular structural biases are incorporated completely through learnable attention biases. TableFormer is (1) strictly invariant to row and column orders, and, (2) could understand tables better due to its tabular inductive biases. Our evaluations showed that TableFormer outperforms strong baselines in all settings on SQA, WTQ and TabFact table reasoning datasets, and achieves state-of-the-art performance on SQA, especially when facing answer-invariant row and column order perturbations (6% improvement over the best baseline), because previous SOTA models' performance drops by 4% - 6% when facing such perturbations while TableFormer is not affected.
TIMEDIAL: Temporal Commonsense Reasoning in Dialog
Jun 08, 2021
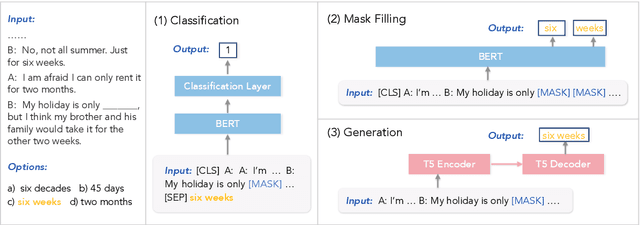

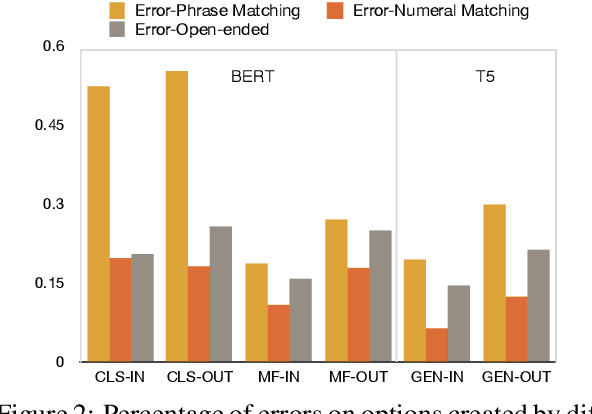
Everyday conversations require understanding everyday events, which in turn, requires understanding temporal commonsense concepts interwoven with those events. Despite recent progress with massive pre-trained language models (LMs) such as T5 and GPT-3, their capability of temporal reasoning in dialogs remains largely under-explored. In this paper, we present the first study to investigate pre-trained LMs for their temporal reasoning capabilities in dialogs by introducing a new task and a crowd-sourced English challenge set, TIMEDIAL. We formulate TIME-DIAL as a multiple-choice cloze task with over 1.1K carefully curated dialogs. Empirical results demonstrate that even the best performing models struggle on this task compared to humans, with 23 absolute points of gap in accuracy. Furthermore, our analysis reveals that the models fail to reason about dialog context correctly; instead, they rely on shallow cues based on existing temporal patterns in context, motivating future research for modeling temporal concepts in text and robust contextual reasoning about them. The dataset is publicly available at: https://github.com/google-research-datasets/timedial.
Disfl-QA: A Benchmark Dataset for Understanding Disfluencies in Question Answering
Jun 08, 2021
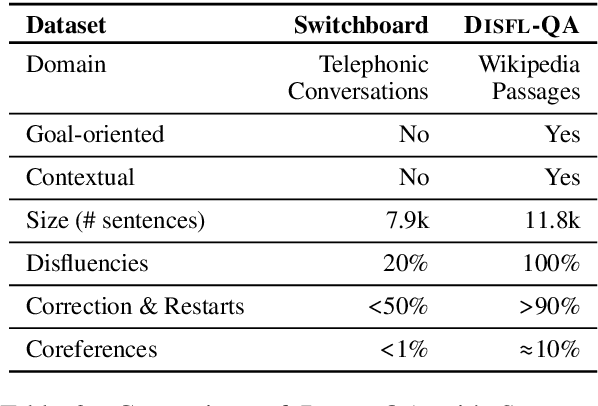


Disfluencies is an under-studied topic in NLP, even though it is ubiquitous in human conversation. This is largely due to the lack of datasets containing disfluencies. In this paper, we present a new challenge question answering dataset, Disfl-QA, a derivative of SQuAD, where humans introduce contextual disfluencies in previously fluent questions. Disfl-QA contains a variety of challenging disfluencies that require a more comprehensive understanding of the text than what was necessary in prior datasets. Experiments show that the performance of existing state-of-the-art question answering models degrades significantly when tested on Disfl-QA in a zero-shot setting.We show data augmentation methods partially recover the loss in performance and also demonstrate the efficacy of using gold data for fine-tuning. We argue that we need large-scale disfluency datasets in order for NLP models to be robust to them. The dataset is publicly available at: https://github.com/google-research-datasets/disfl-qa.
Attention Interpretability Across NLP Tasks
Sep 24, 2019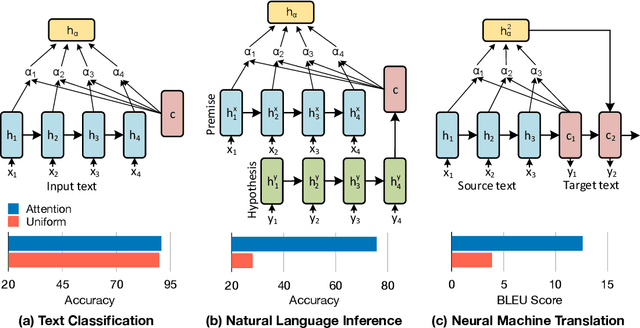
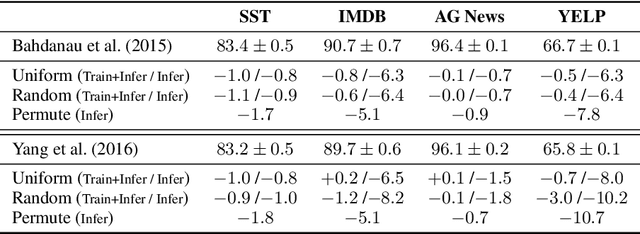
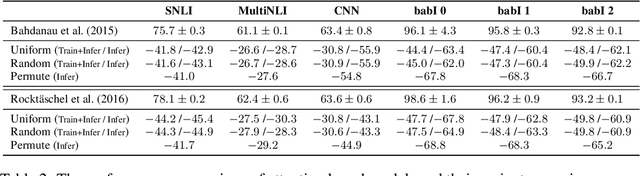
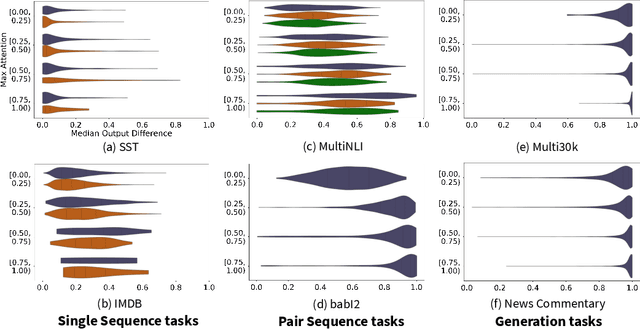
The attention layer in a neural network model provides insights into the model's reasoning behind its prediction, which are usually criticized for being opaque. Recently, seemingly contradictory viewpoints have emerged about the interpretability of attention weights (Jain & Wallace, 2019; Vig & Belinkov, 2019). Amid such confusion arises the need to understand attention mechanism more systematically. In this work, we attempt to fill this gap by giving a comprehensive explanation which justifies both kinds of observations (i.e., when is attention interpretable and when it is not). Through a series of experiments on diverse NLP tasks, we validate our observations and reinforce our claim of interpretability of attention through manual evaluation.
Bootstrapping Transliteration with Constrained Discovery for Low-Resource Languages
Sep 20, 2018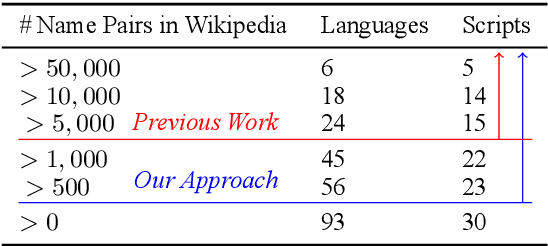
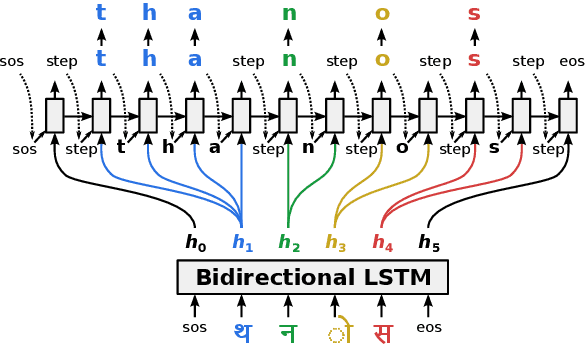
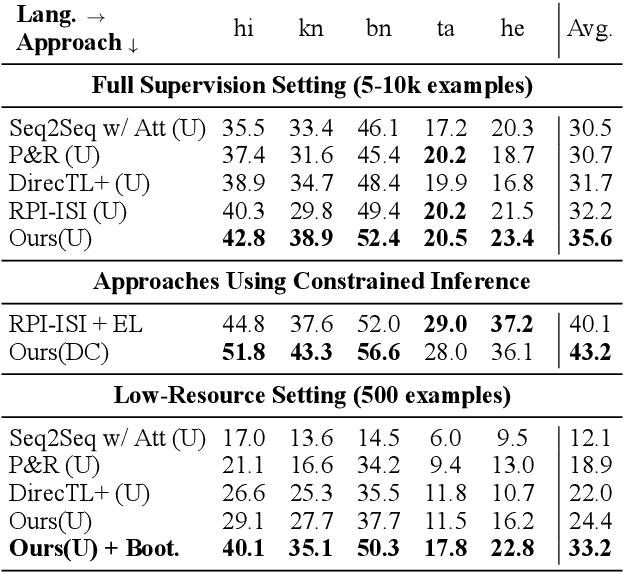
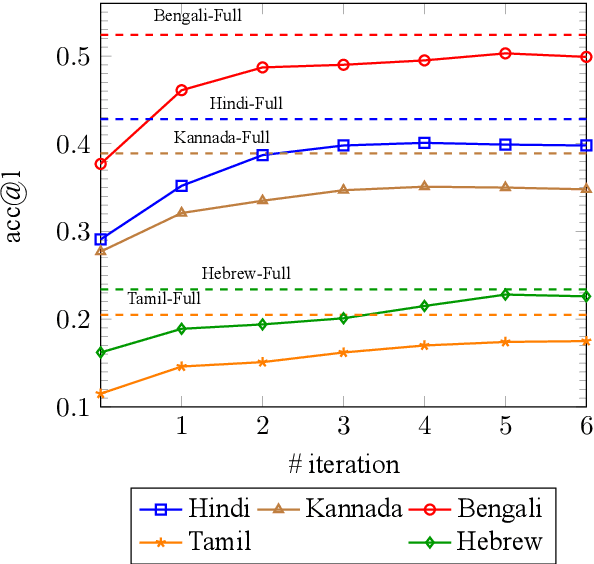
Generating the English transliteration of a name written in a foreign script is an important and challenging step in multilingual knowledge acquisition and information extraction. Existing approaches to transliteration generation require a large (>5000) number of training examples. This difficulty contrasts with transliteration discovery, a somewhat easier task that involves picking a plausible transliteration from a given list. In this work, we present a bootstrapping algorithm that uses constrained discovery to improve generation, and can be used with as few as 500 training examples, which we show can be sourced from annotators in a matter of hours. This opens the task to languages for which large number of training examples are unavailable. We evaluate transliteration generation performance itself, as well the improvement it brings to cross-lingual candidate generation for entity linking, a typical downstream task. We present a comprehensive evaluation of our approach on nine languages, each written in a unique script.
Joint Multilingual Supervision for Cross-lingual Entity Linking
Sep 20, 2018
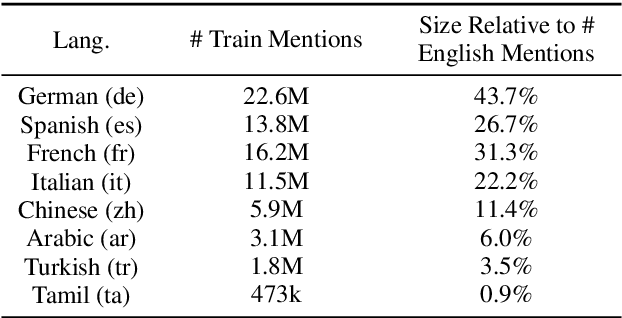
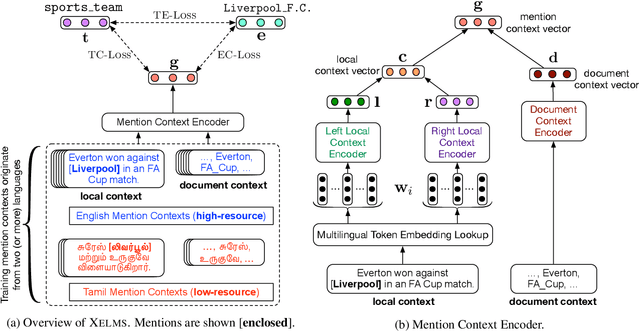
Cross-lingual Entity Linking (XEL) aims to ground entity mentions written in any language to an English Knowledge Base (KB), such as Wikipedia. XEL for most languages is challenging, owing to limited availability of resources as supervision. We address this challenge by developing the first XEL approach that combines supervision from multiple languages jointly. This enables our approach to: (a) augment the limited supervision in the target language with additional supervision from a high-resource language (like English), and (b) train a single entity linking model for multiple languages, improving upon individually trained models for each language. Extensive evaluation on three benchmark datasets across 8 languages shows that our approach significantly improves over the current state-of-the-art. We also provide analyses in two limited resource settings: (a) zero-shot setting, when no supervision in the target language is available, and in (b) low-resource setting, when some supervision in the target language is available. Our analysis provides insights into the limitations of zero-shot XEL approaches in realistic scenarios, and shows the value of joint supervision in low-resource settings.
Robust Cross-lingual Hypernymy Detection using Dependency Context
Mar 30, 2018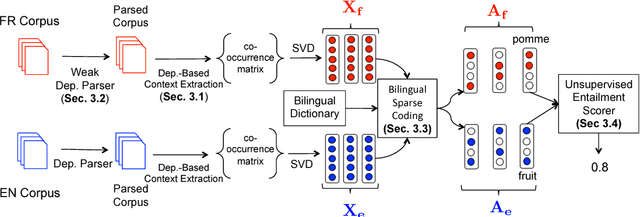

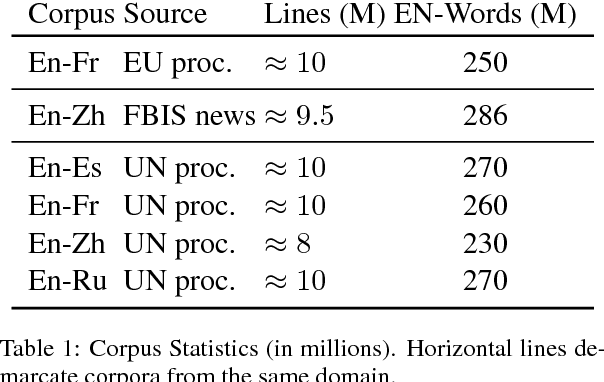
Cross-lingual Hypernymy Detection involves determining if a word in one language ("fruit") is a hypernym of a word in another language ("pomme" i.e. apple in French). The ability to detect hypernymy cross-lingually can aid in solving cross-lingual versions of tasks such as textual entailment and event coreference. We propose BISPARSE-DEP, a family of unsupervised approaches for cross-lingual hypernymy detection, which learns sparse, bilingual word embeddings based on dependency contexts. We show that BISPARSE-DEP can significantly improve performance on this task, compared to approaches based only on lexical context. Our approach is also robust, showing promise for low-resource settings: our dependency-based embeddings can be learned using a parser trained on related languages, with negligible loss in performance. We also crowd-source a challenging dataset for this task on four languages -- Russian, French, Arabic, and Chinese. Our embeddings and datasets are publicly available.
Beyond Bilingual: Multi-sense Word Embeddings using Multilingual Context
Jun 25, 2017
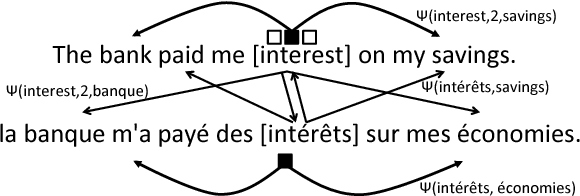
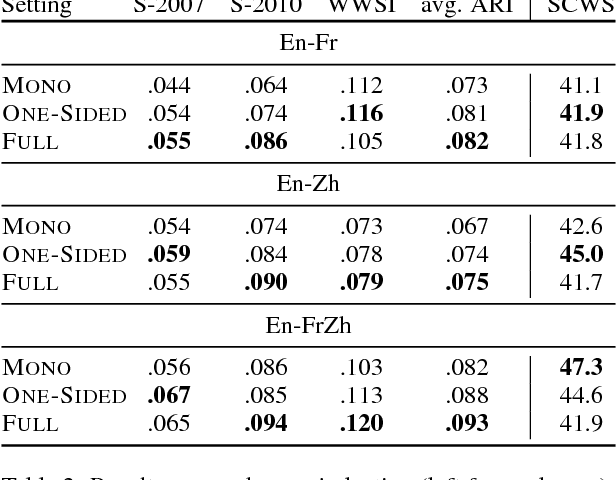
Word embeddings, which represent a word as a point in a vector space, have become ubiquitous to several NLP tasks. A recent line of work uses bilingual (two languages) corpora to learn a different vector for each sense of a word, by exploiting crosslingual signals to aid sense identification. We present a multi-view Bayesian non-parametric algorithm which improves multi-sense word embeddings by (a) using multilingual (i.e., more than two languages) corpora to significantly improve sense embeddings beyond what one achieves with bilingual information, and (b) uses a principled approach to learn a variable number of senses per word, in a data-driven manner. Ours is the first approach with the ability to leverage multilingual corpora efficiently for multi-sense representation learning. Experiments show that multilingual training significantly improves performance over monolingual and bilingual training, by allowing us to combine different parallel corpora to leverage multilingual context. Multilingual training yields comparable performance to a state of the art mono-lingual model trained on five times more training data.
Annotating Derivations: A New Evaluation Strategy and Dataset for Algebra Word Problems
Jan 10, 2017
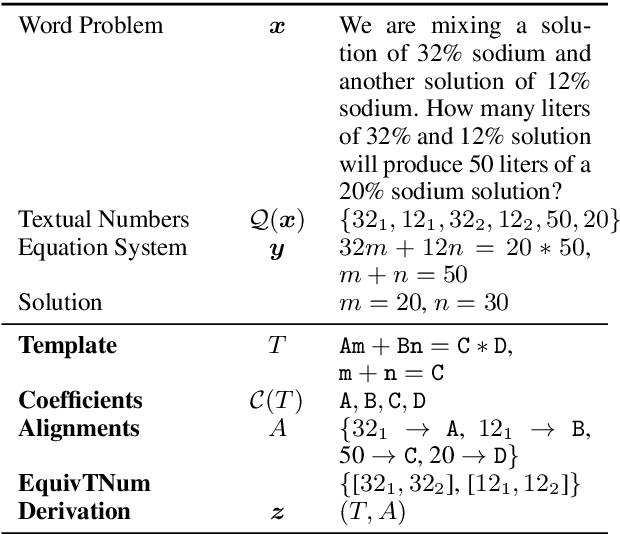
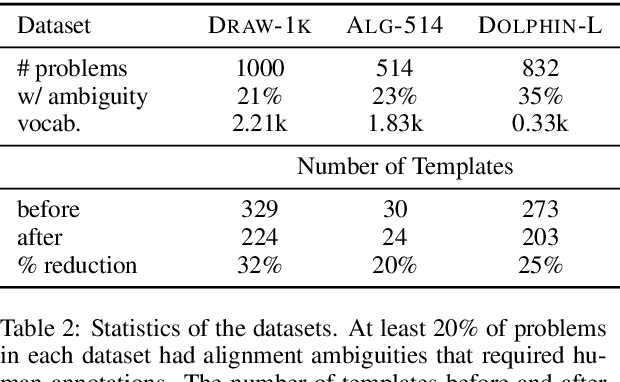
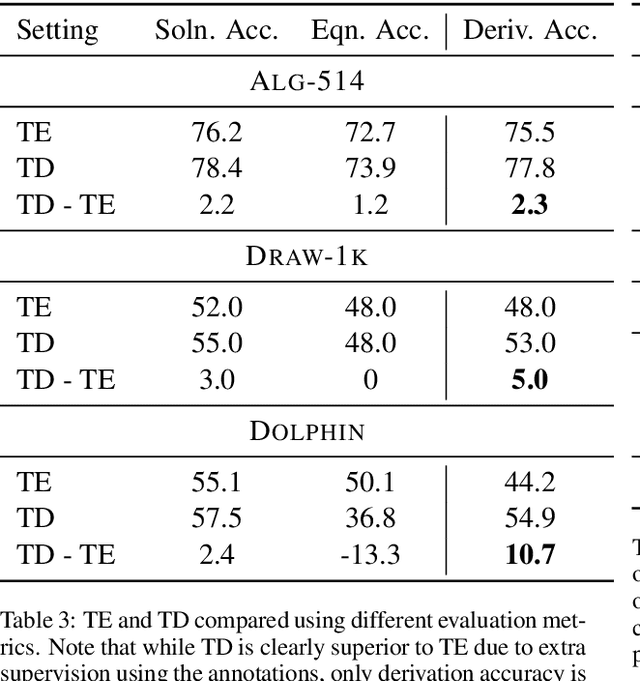
We propose a new evaluation for automatic solvers for algebra word problems, which can identify mistakes that existing evaluations overlook. Our proposal is to evaluate such solvers using derivations, which reflect how an equation system was constructed from the word problem. To accomplish this, we develop an algorithm for checking the equivalence between two derivations, and show how derivation an- notations can be semi-automatically added to existing datasets. To make our experiments more comprehensive, we include the derivation annotation for DRAW-1K, a new dataset containing 1000 general algebra word problems. In our experiments, we found that the annotated derivations enable a more accurate evaluation of automatic solvers than previously used metrics. We release derivation annotations for over 2300 algebra word problems for future evaluations.
Equation Parsing: Mapping Sentences to Grounded Equations
Sep 28, 2016



Identifying mathematical relations expressed in text is essential to understanding a broad range of natural language text from election reports, to financial news, to sport commentaries to mathematical word problems. This paper focuses on identifying and understanding mathematical relations described within a single sentence. We introduce the problem of Equation Parsing -- given a sentence, identify noun phrases which represent variables, and generate the mathematical equation expressing the relation described in the sentence. We introduce the notion of projective equation parsing and provide an efficient algorithm to parse text to projective equations. Our system makes use of a high precision lexicon of mathematical expressions and a pipeline of structured predictors, and generates correct equations in $70\%$ of the cases. In $60\%$ of the time, it also identifies the correct noun phrase $\rightarrow$ variables mapping, significantly outperforming baselines. We also release a new annotated dataset for task evaluation.