 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Index Item IDs for Recommendation Foundation Models
May 12, 2023Recommendation foundation model utilizes large language models (LLM) for recommendation by converting recommendation tasks into natural language tasks. It enables generative recommendation which directly generates the item(s) to recommend rather than calculating a ranking score for each and every candidate item in traditional recommendation models, simplifying the recommendation pipeline from multi-stage filtering to single-stage filtering. To avoid generating excessively long text when deciding which item(s) to recommend, creating LLM-compatible item IDs is essential for recommendation foundation models. In this study, we systematically examine the item indexing problem for recommendation foundation models, using P5 as the representative backbone model and replicating its results with various indexing methods. To emphasize the importance of item indexing, we first discuss the issues of several trivial item indexing methods, such as independent indexing, title indexing, and random indexing. We then propose four simple yet effective solutions, including sequential indexing, collaborative indexing, semantic (content-based) indexing, and hybrid indexing. Our reproducibility study of P5 highlights the significant influence of item indexing methods on the model performance, and our results on real-world datasets validate the effectiveness of our proposed solutions.
OpenAGI: When LLM Meets Domain Experts
Apr 12, 2023



Human intelligence has the remarkable ability to assemble basic skills into complex ones so as to solve complex tasks. This ability is equally important for Artificial Intelligence (AI), and thus, we assert that in addition to the development of large, comprehensive intelligent models, it is equally crucial to equip such models with the capability to harness various domain-specific expert models for complex task-solving in the pursuit of Artificial General Intelligence (AGI). Recent developments in Large Language Models (LLMs) have demonstrated remarkable learning and reasoning abilities, making them promising as a controller to select, synthesize, and execute external models to solve complex tasks. In this project, we develop OpenAGI, an open-source AGI research platform, specifically designed to offer complex, multi-step tasks and accompanied by task-specific datasets, evaluation metrics, and a diverse range of extensible models. OpenAGI formulates complex tasks as natural language queries, serving as input to the LLM. The LLM subsequently selects, synthesizes, and executes models provided by OpenAGI to address the task. Furthermore, we propose a Reinforcement Learning from Task Feedback (RLTF) mechanism, which uses the task-solving result as feedback to improve the LLM's task-solving ability. Thus, the LLM is responsible for synthesizing various external models for solving complex tasks, while RLTF provides feedback to improve its task-solving ability, enabling a feedback loop for self-improving AI. We believe that the paradigm of LLMs operating various expert models for complex task-solving is a promising approach towards AGI. To facilitate the community's long-term improvement and evaluation of AGI's ability, we open-source the code, benchmark, and evaluation methods of the OpenAGI project at https://github.com/agiresearch/OpenAGI.
Causal Inference for Recommendation: Foundations, Methods and Applications
Jan 08, 2023



Recommender systems are important and powerful tools for various personalized services. Traditionally, these systems use data mining and machine learning techniques to make recommendations based on correlations found in the data. However, relying solely on correlation without considering the underlying causal mechanism may lead to various practical issues such as fairness, explainability, robustness, bias, echo chamber and controllability problems. Therefore, researchers in related area have begun incorporating causality into recommendation systems to address these issues. In this survey, we review the existing literature on causal inference in recommender systems. We discuss the fundamental concepts of both recommender systems and causal inference as well as their relationship, and review the existing work on causal methods for different problems in recommender systems. Finally, we discuss open problems and future directions in the field of causal inference for recommendations.
Causal Structure Learning with Recommendation System
Oct 19, 2022
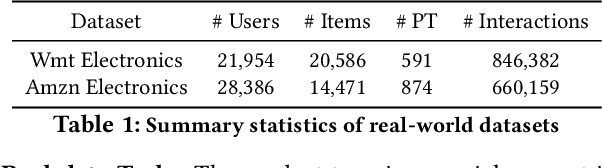
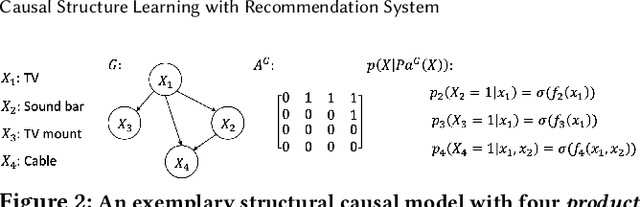
A fundamental challenge of recommendation systems (RS) is understanding the causal dynamics underlying users' decision making. Most existing literature addresses this problem by using causal structures inferred from domain knowledge. However, there are numerous phenomenons where domain knowledge is insufficient, and the causal mechanisms must be learnt from the feedback data. Discovering the causal mechanism from RS feedback data is both novel and challenging, since RS itself is a source of intervention that can influence both the users' exposure and their willingness to interact. Also for this reason, most existing solutions become inappropriate since they require data collected free from any RS. In this paper, we first formulate the underlying causal mechanism as a causal structural model and describe a general causal structure learning framework grounded in the real-world working mechanism of RS. The essence of our approach is to acknowledge the unknown nature of RS intervention. We then derive the learning objective from our framework and propose an augmented Lagrangian solver for efficient optimization. We conduct both simulation and real-world experiments to demonstrate how our approach compares favorably to existing solutions, together with the empirical analysis from sensitivity and ablation studies.
Dynamic Causal Collaborative Filtering
Aug 23, 2022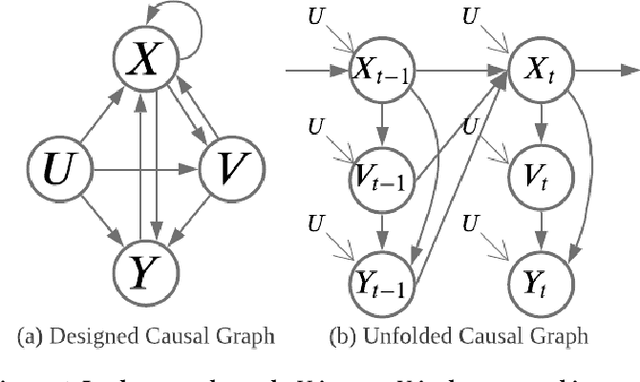

Causal graph, as an effective and powerful tool for causal modeling, is usually assumed as a Directed Acyclic Graph (DAG). However, recommender systems usually involve feedback loops, defined as the cyclic process of recommending items, incorporating user feedback in model updates, and repeating the procedure. As a result, it is important to incorporate loops into the causal graphs to accurately model the dynamic and iterative data generation process for recommender systems. However, feedback loops are not always beneficial since over time they may encourage more and more narrowed content exposure, which if left unattended, may results in echo chambers. As a result, it is important to understand when the recommendations will lead to echo chambers and how to mitigate echo chambers without hurting the recommendation performance. In this paper, we design a causal graph with loops to describe the dynamic process of recommendation. We then take Markov process to analyze the mathematical properties of echo chamber such as the conditions that lead to echo chambers. Inspired by the theoretical analysis, we propose a Dynamic Causal Collaborative Filtering ($\partial$CCF) model, which estimates users' post-intervention preference on items based on back-door adjustment and mitigates echo chamber with counterfactual reasoning. Multiple experiments are conducted on real-world datasets and results show that our framework can mitigate echo chambers better than other state-of-the-art frameworks while achieving comparable recommendation performance with the base recommendation models.
A Survey on Trustworthy Recommender Systems
Jul 25, 2022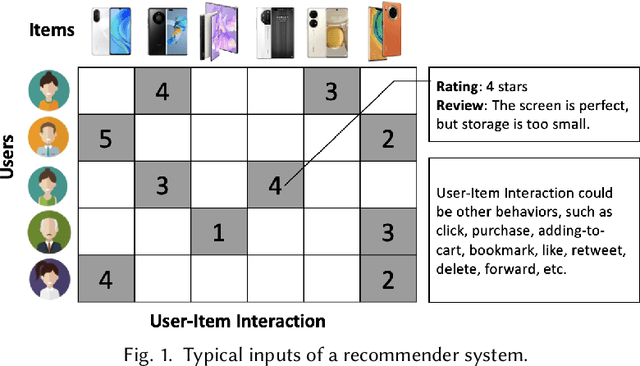

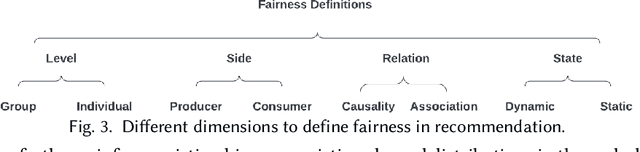

Recommender systems (RS), serving at the forefront of Human-centered AI, are widely deployed in almost every corner of the web and facilitate the human decision-making process. However, despite their enormous capabilities and potential, RS may also lead to undesired counter-effects on users, items, producers, platforms, or even the society at large, such as compromised user trust due to non-transparency, unfair treatment of different consumers, or producers, privacy concerns due to extensive use of user's private data for personalization, just to name a few. All of these create an urgent need for Trustworthy Recommender Systems (TRS) so as to mitigate or avoid such adverse impacts and risks. In this survey, we will introduce techniques related to trustworthy and responsible recommendation, including but not limited to explainable recommendation, fairness in recommendation, privacy-aware recommendation, robustness in recommendation, user controllable recommendation, as well as the relationship between these different perspectives in terms of trustworthy and responsible recommendation. Through this survey, we hope to deliver readers with a comprehensive view of the research area and raise attention to the community about the importance, existing research achievements, and future research directions on trustworthy recommendation.
Fairness in Recommendation: A Survey
Jun 01, 2022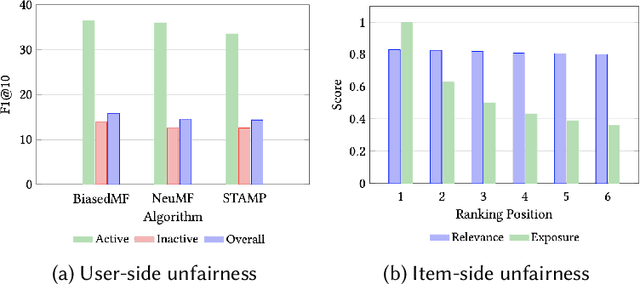
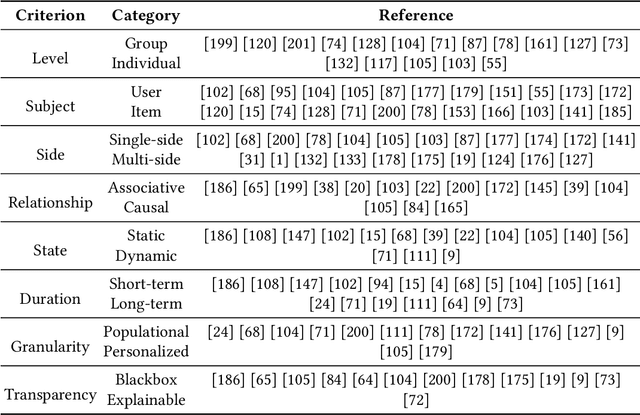
As one of the most pervasive applications of machine learning, recommender systems are playing an important role on assisting human decision making. The satisfaction of users and the interests of platforms are closely related to the quality of the generated recommendation results. However, as a highly data-driven system, recommender system could be affected by data or algorithmic bias and thus generate unfair results, which could weaken the reliance of the systems. As a result, it is crucial to address the potential unfairness problems in recommendation settings. Recently, there has been growing attention on fairness considerations in recommender systems with more and more literature on approaches to promote fairness in recommendation. However, the studies are rather fragmented and lack a systematic organization, thus making it difficult to penetrate for new researchers to the domain. This motivates us to provide a systematic survey of existing works on fairness in recommendation. This survey focuses on the foundations for fairness in recommendation literature. It first presents a brief introduction about fairness in basic machine learning tasks such as classification and ranking in order to provide a general overview of fairness research, as well as introduce the more complex situations and challenges that need to be considered when studying fairness in recommender systems. After that, the survey will introduce fairness in recommendation with a focus on the taxonomies of current fairness definitions, the typical techniques for improving fairness, as well as the datasets for fairness studies in recommendation. The survey also talks about the challenges and opportunities in fairness research with the hope of promoting the fair recommendation research area and beyond.
Learning and Evaluating Graph Neural Network Explanations based on Counterfactual and Factual Reasoning
Feb 17, 2022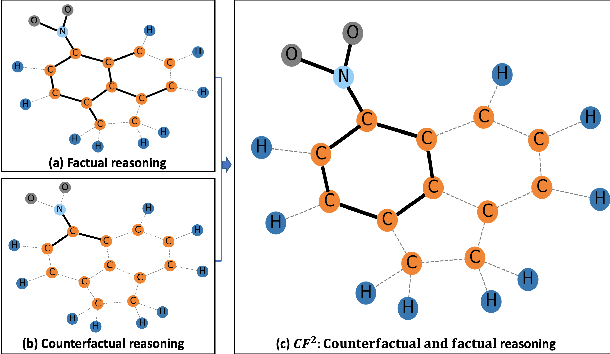
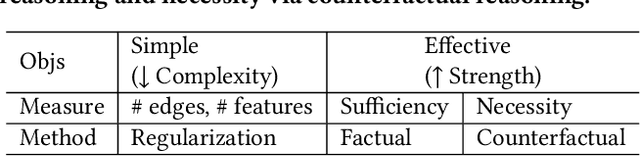

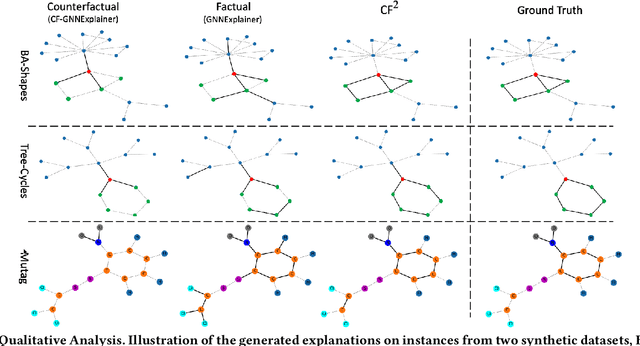
Structural data well exists in Web applications, such as social networks in social media, citation networks in academic websites, and threads data in online forums. Due to the complex topology, it is difficult to process and make use of the rich information within such data. Graph Neural Networks (GNNs) have shown great advantages on learning representations for structural data. However, the non-transparency of the deep learning models makes it non-trivial to explain and interpret the predictions made by GNNs. Meanwhile, it is also a big challenge to evaluate the GNN explanations, since in many cases, the ground-truth explanations are unavailable. In this paper, we take insights of Counterfactual and Factual (CF^2) reasoning from causal inference theory, to solve both the learning and evaluation problems in explainable GNNs. For generating explanations, we propose a model-agnostic framework by formulating an optimization problem based on both of the two casual perspectives. This distinguishes CF^2 from previous explainable GNNs that only consider one of them. Another contribution of the work is the evaluation of GNN explanations. For quantitatively evaluating the generated explanations without the requirement of ground-truth, we design metrics based on Counterfactual and Factual reasoning to evaluate the necessity and sufficiency of the explanations. Experiments show that no matter ground-truth explanations are available or not, CF^2 generates better explanations than previous state-of-the-art methods on real-world datasets. Moreover, the statistic analysis justifies the correlation between the performance on ground-truth evaluation and our proposed metrics.
Deconfounded Causal Collaborative Filtering
Oct 14, 2021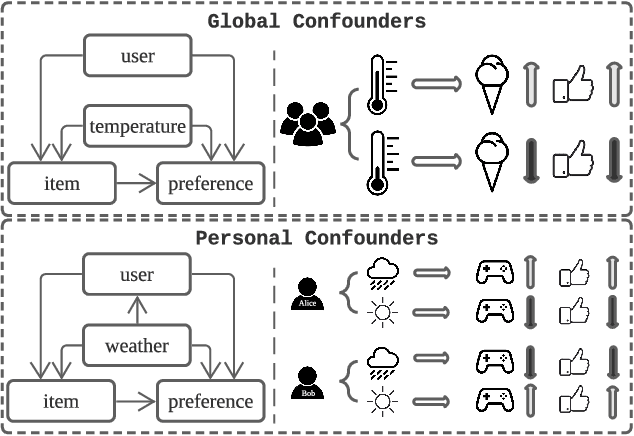
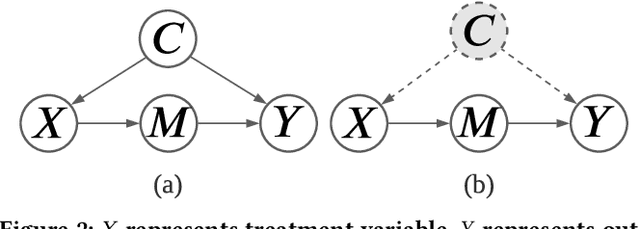
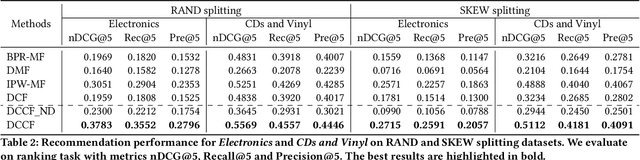
Recommender systems may be confounded by various types of confounding factors (also called confounders) that may lead to inaccurate recommendations and sacrificed recommendation performance. Current approaches to solving the problem usually design each specific model for each specific confounder. However, real-world systems may include a huge number of confounders and thus designing each specific model for each specific confounder is unrealistic. More importantly, except for those "explicit confounders" that researchers can manually identify and process such as item's position in the ranking list, there are also many "latent confounders" that are beyond the imagination of researchers. For example, users' rating on a song may depend on their current mood or the current weather, and users' preference on ice creams may depend on the air temperature. Such latent confounders may be unobservable in the recorded training data. To solve the problem, we propose a deconfounded causal collaborative filtering model. We first frame user behaviors with unobserved confounders into a causal graph, and then we design a front-door adjustment model carefully fused with machine learning to deconfound the influence of unobserved confounders. The proposed model is able to handle both global confounders and personalized confounders. Experiments on real-world e-commerce datasets show that our method is able to deconfound unobserved confounders to achieve better recommendation performance.
Counterfactual Evaluation for Explainable AI
Sep 05, 2021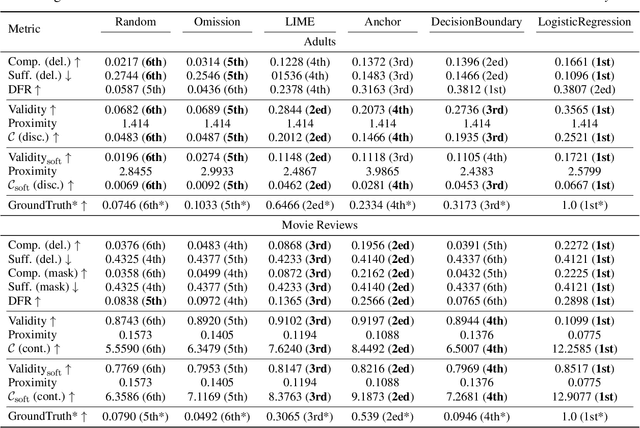
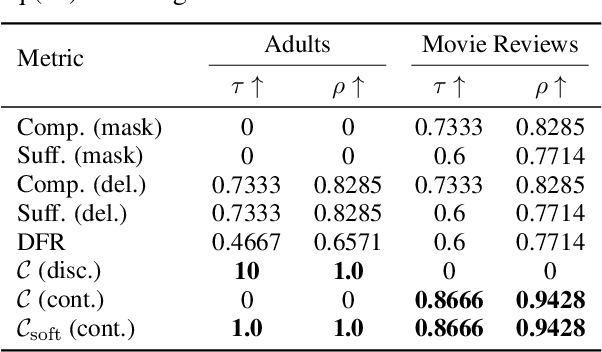
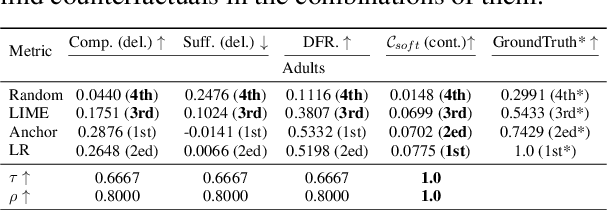
While recent years have witnessed the emergence of various explainable methods in machine learning, to what degree the explanations really represent the reasoning process behind the model prediction -- namely, the faithfulness of explanation -- is still an open problem. One commonly used way to measure faithfulness is \textit{erasure-based} criteria. Though conceptually simple, erasure-based criterion could inevitably introduce biases and artifacts. We propose a new methodology to evaluate the faithfulness of explanations from the \textit{counterfactual reasoning} perspective: the model should produce substantially different outputs for the original input and its corresponding counterfactual edited on a faithful feature. Specially, we introduce two algorithms to find the proper counterfactuals in both discrete and continuous scenarios and then use the acquired counterfactuals to measure faithfulness. Empirical results on several datasets show that compared with existing metrics, our proposed counterfactual evaluation method can achieve top correlation with the ground truth under diffe