 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Collapse in Sign Language Production: A Diagnostic and a Scaling Argument
Jun 01, 2026Sign Language Production (SLP) is the task of generating avatar sign language motion from natural language text. The quality of the generated motion is typically evaluated by a motion-space Fréchet distance (FID) and back-translation (BT) BLEU score on benchmarks such as How2Sign. Both metrics can improve substantially while the underlying generator fails to faithfully represent the sign language gestures. In this work we propose to evaluate the generated motion at three independent levels: ($\tau1$) initial-pose conditioning, ($\tau2$) output diversity, and ($\tau3$) target faithfulness. We compute these as pairwise-distance ratios using latent representations of a frozen motion autoencoder (MoAE). We evaluate 14 SLP model checkpoints on the How2Sign dataset, including a re-implemented Neural Sign Actors (NSA), and show that $\tau3$ faithfulness is never attained, while FID varies by nearly two orders of magnitude and is uncorrelated with faithfulness. We show that on the isolated gloss dataset ASL3DWord favorable $\tau3$ can be attained, hence isolating the size of the sentence-level paired-dataset as the bottleneck.
To See or To Please: Uncovering Visual Sycophancy and Split Beliefs in VLMs
Mar 19, 2026When VLMs answer correctly, do they genuinely rely on visual information or exploit language shortcuts? We introduce the Tri-Layer Diagnostic Framework, which disentangles hallucination sources via three metrics: Latent Anomaly Detection (perceptual awareness), Visual Necessity Score (visual dependency, measured via KL divergence), and Competition Score (conflict between visual grounding and instruction following). Using counterfactual interventions (blind, noise, and conflict images) across 7 VLMs and 7,000 model-sample pairs, our taxonomy reveals that 69.6% of samples exhibit Visual Sycophancy--models detect visual anomalies but hallucinate to satisfy user expectations--while zero samples show Robust Refusal, indicating alignment training has systematically suppressed truthful uncertainty acknowledgment. A scaling analysis (Qwen2.5-VL 7B to 72B) shows larger models reduce Language Shortcuts but amplify Visual Sycophancy, demonstrating scale alone cannot resolve the grounding problem. Diagnostic scores further enable a post-hoc selective prediction strategy achieving up to +9.5pp accuracy at 50% coverage with no additional training cost.
Toward Phonology-Guided Sign Language Motion Generation: A Diffusion Baseline and Conditioning Analysis
Mar 18, 2026Generating natural, correct, and visually smooth 3D avatar sign language motion conditioned on the text inputs continues to be very challenging. In this work, we train a generative model of 3D body motion and explore the role of phonological attribute conditioning for sign language motion generation, using ASL-LEX 2.0 annotations such as hand shape, hand location and movement. We first establish a strong diffusion baseline using an Human Motion MDM-style diffusion model with SMPL-X representation, which outperforms SignAvatar, a state-of-the-art CVAE method, on gloss discriminability metrics. We then systematically study the role of text conditioning using different text encoders (CLIP vs. T5), conditioning modes (gloss-only vs. gloss+phonological attributes), and attribute notation format (symbolic vs. natural language). Our analysis reveals that translating symbolic ASL-LEX notations to natural language is a necessary condition for effective CLIP-based attribute conditioning, while T5 is largely unaffected by this translation. Furthermore, our best-performing variant (CLIP with mapped attributes) outperforms SignAvatar across all metrics. These findings highlight input representation as a critical factor for text-encoder-based attribute conditioning, and motivate structured conditioning approaches where gloss and phonological attributes are encoded through independent pathways.
Gesture-Aware Pretraining and Token Fusion for 3D Hand Pose Estimation
Mar 18, 2026Estimating 3D hand pose from monocular RGB images is fundamental for applications in AR/VR, human-computer interaction, and sign language understanding. In this work we focus on a scenario where a discrete set of gesture labels is available and show that gesture semantics can serve as a powerful inductive bias for 3D pose estimation. We present a two-stage framework: gesture-aware pretraining that learns an informative embedding space using coarse and fine gesture labels from InterHand2.6M, followed by a per-joint token Transformer guided by gesture embeddings as intermediate representations for final regression of MANO hand parameters. Training is driven by a layered objective over parameters, joints, and structural constraints. Experiments on InterHand2.6M demonstrate that gesture-aware pretraining consistently improves single-hand accuracy over the state-of-the-art EANet baseline, and that the benefit transfers across architectures without any modification.
Motion-Adaptive Temporal Attention for Lightweight Video Generation with Stable Diffusion
Mar 18, 2026We present a motion-adaptive temporal attention mechanism for parameter-efficient video generation built upon frozen Stable Diffusion models. Rather than treating all video content uniformly, our method dynamically adjusts temporal attention receptive fields based on estimated motion content: high-motion sequences attend locally across frames to preserve rapidly changing details, while low-motion sequences attend globally to enforce scene consistency. We inject lightweight temporal attention modules into all UNet transformer blocks via a cascaded strategy -- global attention in down-sampling and middle blocks for semantic stabilization, motion-adaptive attention in up-sampling blocks for fine-grained refinement. Combined with temporally correlated noise initialization and motion-aware gating, the system adds only 25.8M trainable parameters (2.9\% of the base UNet) while achieving competitive results on WebVid validation when trained on 100K videos. We demonstrate that the standard denoising objective alone provides sufficient implicit temporal regularization, outperforming approaches that add explicit temporal consistency losses. Our ablation studies reveal a clear trade-off between noise correlation and motion amplitude, providing a practical inference-time control for diverse generation behaviors.
* 6 pages, 3 figures, 4 tables. Published at IS&T Electronic Imaging 2026, GENAI Track
Predicting Quantum Potentials by Deep Neural Network and Metropolis Sampling
Jun 06, 2021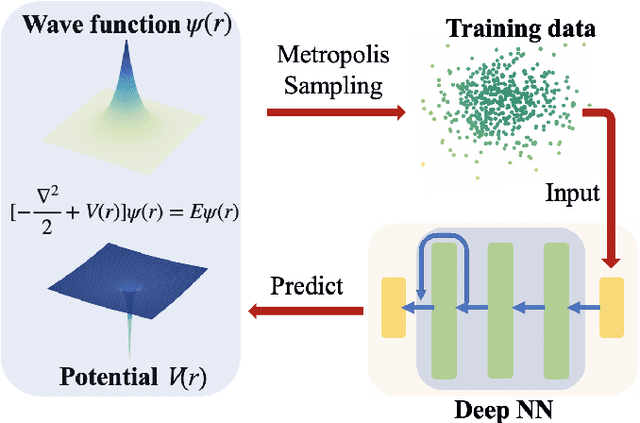
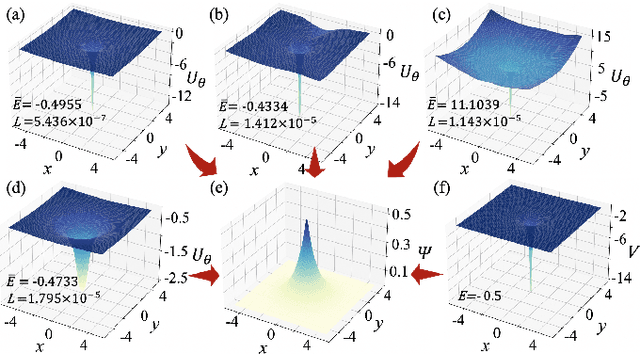
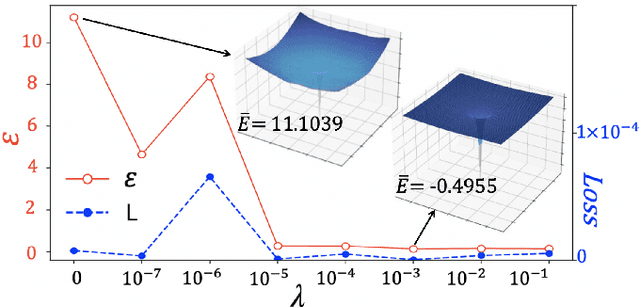
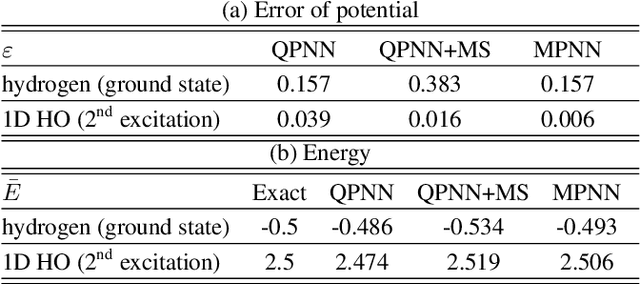
The hybridizations of machine learning and quantum physics have caused essential impacts to the methodology in both fields. Inspired by quantum potential neural network, we here propose to solve the potential in the Schrodinger equation provided the eigenstate, by combining Metropolis sampling with deep neural network, which we dub as Metropolis potential neural network (MPNN). A loss function is proposed to explicitly involve the energy in the optimization for its accurate evaluation. Benchmarking on the harmonic oscillator and hydrogen atom, MPNN shows excellent accuracy and stability on predicting not just the potential to satisfy the Schrodinger equation, but also the eigen-energy. Our proposal could be potentially applied to the ab-initio simulations, and to inversely solving other partial differential equations in physics and beyond.
Automatically Differentiable Quantum Circuit for Many-qubit State Preparation
Apr 30, 2021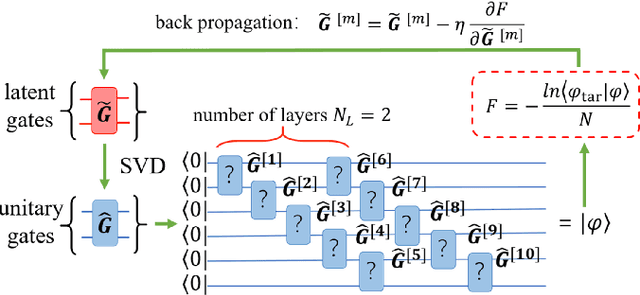
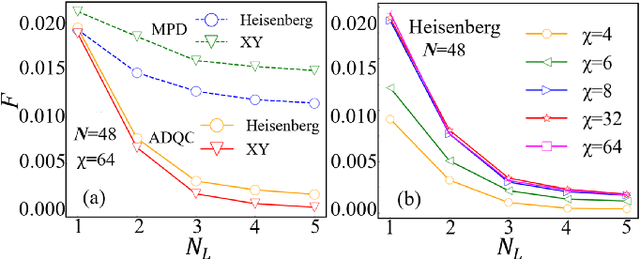
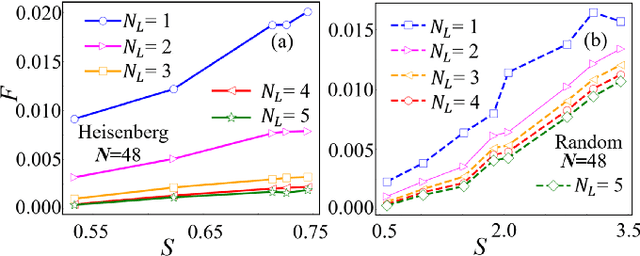
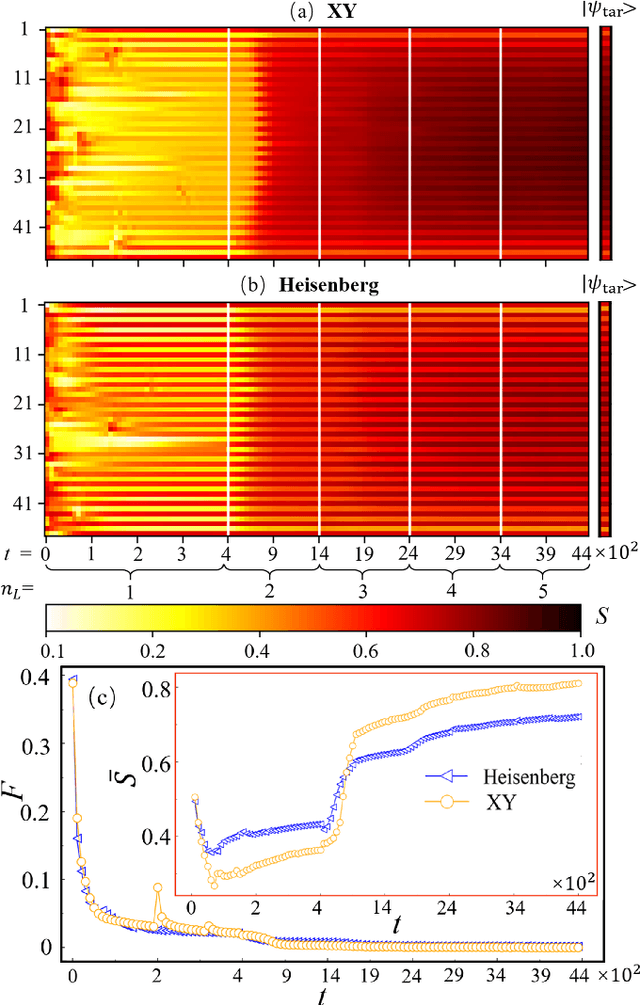
Constructing quantum circuits for efficient state preparation belongs to the central topics in the field of quantum information and computation. As the number of qubits grows fast, methods to derive large-scale quantum circuits are strongly desired. In this work, we propose the automatically differentiable quantum circuit (ADQC) approach to efficiently prepare arbitrary quantum many-qubit states. A key ingredient is to introduce the latent gates whose decompositions give the unitary gates that form the quantum circuit. The circuit is optimized by updating the latent gates using back propagation to minimize the distance between the evolved and target states. Taking the ground states of quantum lattice models and random matrix product states as examples, with the number of qubits where processing the full coefficients is unlikely, ADQC obtains high fidelities with small numbers of layers $N_L \sim O(1)$. Superior accuracy is reached compared with the existing state-preparation approach based on the matrix product disentangler. The parameter complexity of MPS can be significantly reduced by ADQC with the compression ratio $r \sim O(10^{-3})$. Our work sheds light on the "intelligent construction" of quantum circuits for many-qubit systems by combining with the machine learning methods.