 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Contrastive Learning with Dynamic Correlation for Multi-Phase Organ Segmentation
Oct 16, 2022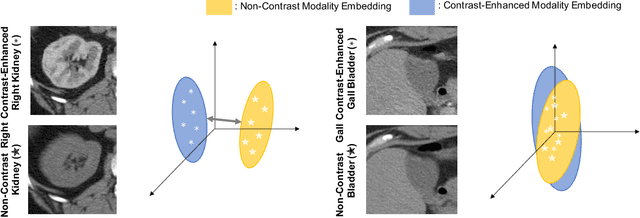
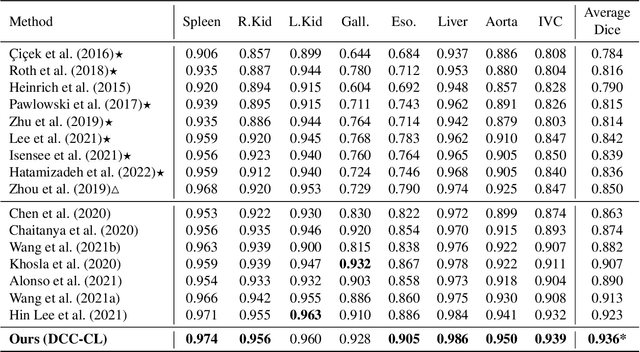
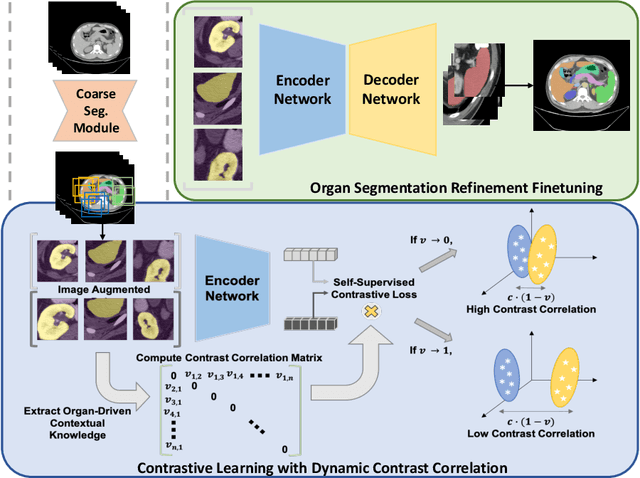
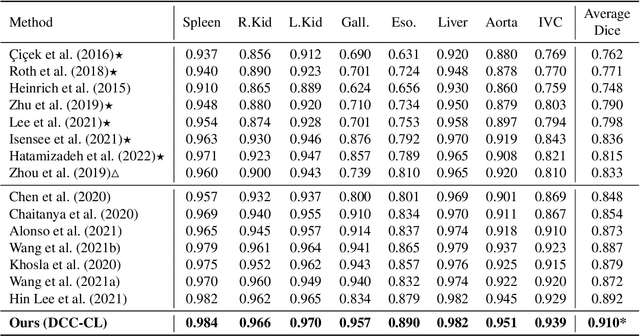
Recent studies have demonstrated the superior performance of introducing ``scan-wise" contrast labels into contrastive learning for multi-organ segmentation on multi-phase computed tomography (CT). However, such scan-wise labels are limited: (1) a coarse classification, which could not capture the fine-grained ``organ-wise" contrast variations across all organs; (2) the label (i.e., contrast phase) is typically manually provided, which is error-prone and may introduce manual biases of defining phases. In this paper, we propose a novel data-driven contrastive loss function that adapts the similar/dissimilar contrast relationship between samples in each minibatch at organ-level. Specifically, as variable levels of contrast exist between organs, we hypothesis that the contrast differences in the organ-level can bring additional context for defining representations in the latent space. An organ-wise contrast correlation matrix is computed with mean organ intensities under one-hot attention maps. The goal of adapting the organ-driven correlation matrix is to model variable levels of feature separability at different phases. We evaluate our proposed approach on multi-organ segmentation with both non-contrast CT (NCCT) datasets and the MICCAI 2015 BTCV Challenge contrast-enhance CT (CECT) datasets. Compared to the state-of-the-art approaches, our proposed contrastive loss yields a substantial and significant improvement of 1.41% (from 0.923 to 0.936, p-value$<$0.01) and 2.02% (from 0.891 to 0.910, p-value$<$0.01) on mean Dice scores across all organs with respect to NCCT and CECT cohorts. We further assess the trained model performance with the MICCAI 2021 FLARE Challenge CECT datasets and achieve a substantial improvement of mean Dice score from 0.927 to 0.934 (p-value$<$0.01). The code is available at: https://github.com/MASILab/DCC_CL
3D UX-Net: A Large Kernel Volumetric ConvNet Modernizing Hierarchical Transformer for Medical Image Segmentation
Oct 03, 2022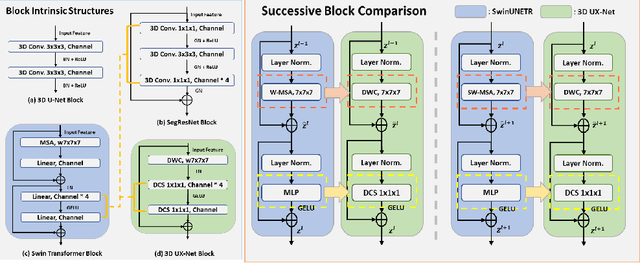
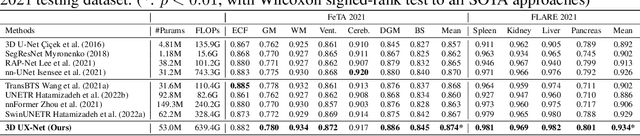
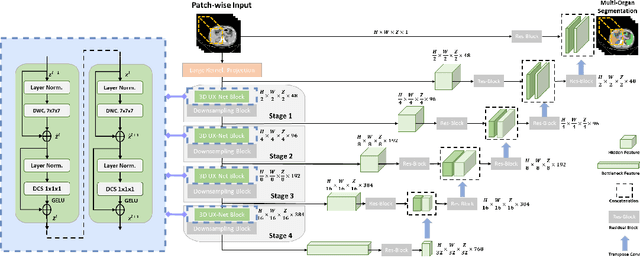
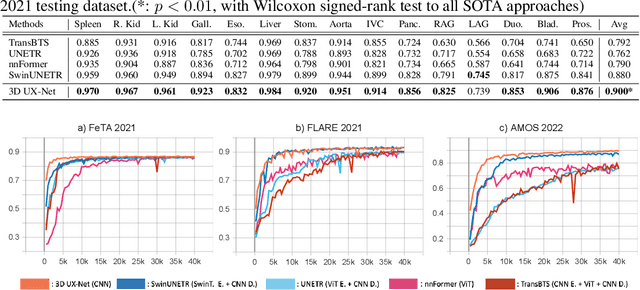
Vision transformers (ViTs) have quickly superseded convolutional networks (ConvNets) as the current state-of-the-art (SOTA) models for medical image segmentation. Hierarchical transformers (e.g., Swin Transformers) reintroduced several ConvNet priors and further enhanced the practical viability of adapting volumetric segmentation in 3D medical datasets. The effectiveness of hybrid approaches is largely credited to the large receptive field for non-local self-attention and the large number of model parameters. In this work, we propose a lightweight volumetric ConvNet, termed 3D UX-Net, which adapts the hierarchical transformer using ConvNet modules for robust volumetric segmentation. Specifically, we revisit volumetric depth-wise convolutions with large kernel size (e.g. starting from $7\times7\times7$) to enable the larger global receptive fields, inspired by Swin Transformer. We further substitute the multi-layer perceptron (MLP) in Swin Transformer blocks with pointwise depth convolutions and enhance model performances with fewer normalization and activation layers, thus reducing the number of model parameters. 3D UX-Net competes favorably with current SOTA transformers (e.g. SwinUNETR) using three challenging public datasets on volumetric brain and abdominal imaging: 1) MICCAI Challenge 2021 FLARE, 2) MICCAI Challenge 2021 FeTA, and 3) MICCAI Challenge 2022 AMOS. 3D UX-Net consistently outperforms SwinUNETR with improvement from 0.929 to 0.938 Dice (FLARE2021) and 0.867 to 0.874 Dice (Feta2021). We further evaluate the transfer learning capability of 3D UX-Net with AMOS2022 and demonstrates another improvement of $2.27\%$ Dice (from 0.880 to 0.900). The source code with our proposed model are available at https://github.com/MASILab/3DUX-Net.
Reducing Positional Variance in Cross-sectional Abdominal CT Slices with Deep Conditional Generative Models
Sep 28, 20222D low-dose single-slice abdominal computed tomography (CT) slice enables direct measurements of body composition, which are critical to quantitatively characterizing health relationships on aging. However, longitudinal analysis of body composition changes using 2D abdominal slices is challenging due to positional variance between longitudinal slices acquired in different years. To reduce the positional variance, we extend the conditional generative models to our C-SliceGen that takes an arbitrary axial slice in the abdominal region as the condition and generates a defined vertebral level slice by estimating the structural changes in the latent space. Experiments on 1170 subjects from an in-house dataset and 50 subjects from BTCV MICCAI Challenge 2015 show that our model can generate high quality images in terms of realism and similarity. External experiments on 20 subjects from the Baltimore Longitudinal Study of Aging (BLSA) dataset that contains longitudinal single abdominal slices validate that our method can harmonize the slice positional variance in terms of muscle and visceral fat area. Our approach provides a promising direction of mapping slices from different vertebral levels to a target slice to reduce positional variance for single slice longitudinal analysis. The source code is available at: https://github.com/MASILab/C-SliceGen.
* 11 pages, 4 figures
UNesT: Local Spatial Representation Learning with Hierarchical Transformer for Efficient Medical Segmentation
Sep 28, 2022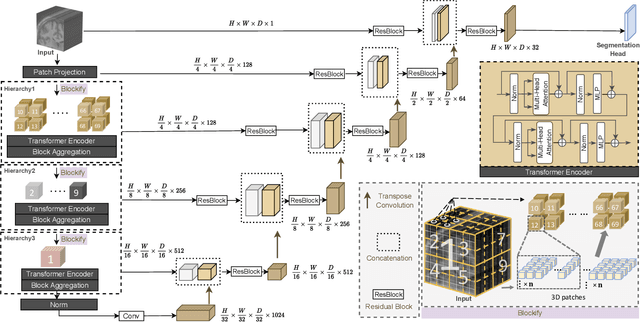

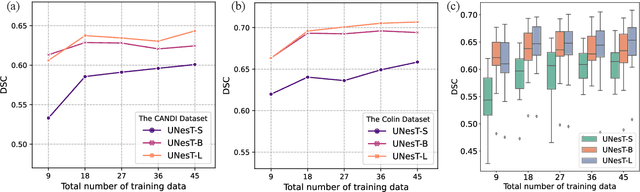
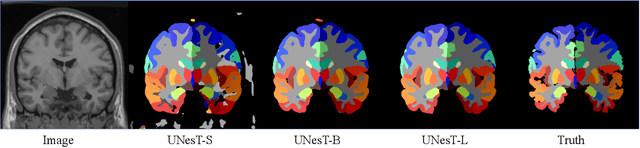
Transformer-based models, capable of learning better global dependencies, have recently demonstrated exceptional representation learning capabilities in computer vision and medical image analysis. Transformer reformats the image into separate patches and realize global communication via the self-attention mechanism. However, positional information between patches is hard to preserve in such 1D sequences, and loss of it can lead to sub-optimal performance when dealing with large amounts of heterogeneous tissues of various sizes in 3D medical image segmentation. Additionally, current methods are not robust and efficient for heavy-duty medical segmentation tasks such as predicting a large number of tissue classes or modeling globally inter-connected tissues structures. Inspired by the nested hierarchical structures in vision transformer, we proposed a novel 3D medical image segmentation method (UNesT), employing a simplified and faster-converging transformer encoder design that achieves local communication among spatially adjacent patch sequences by aggregating them hierarchically. We extensively validate our method on multiple challenging datasets, consisting anatomies of 133 structures in brain, 14 organs in abdomen, 4 hierarchical components in kidney, and inter-connected kidney tumors). We show that UNesT consistently achieves state-of-the-art performance and evaluate its generalizability and data efficiency. Particularly, the model achieves whole brain segmentation task complete ROI with 133 tissue classes in single network, outperforms prior state-of-the-art method SLANT27 ensembled with 27 network tiles, our model performance increases the mean DSC score of the publicly available Colin and CANDI dataset from 0.7264 to 0.7444 and from 0.6968 to 0.7025, respectively.
Longitudinal Variability Analysis on Low-dose Abdominal CT with Deep Learning-based Segmentation
Sep 28, 2022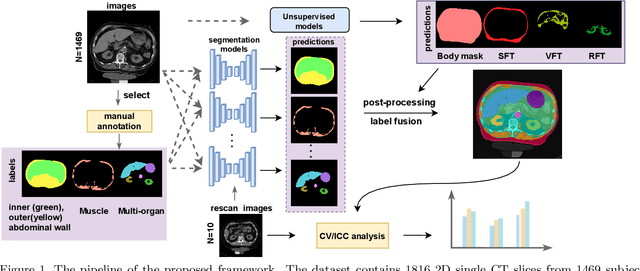

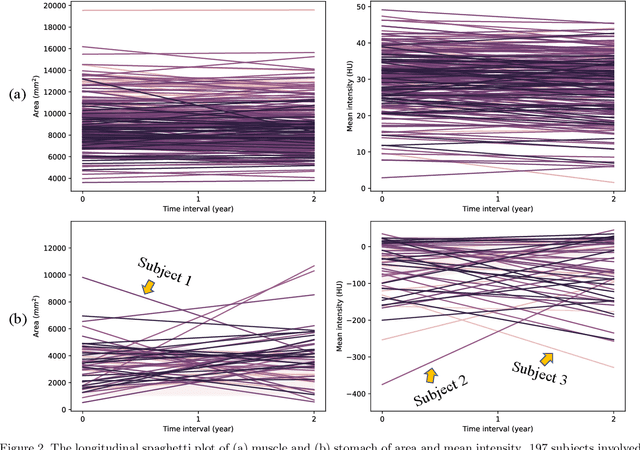
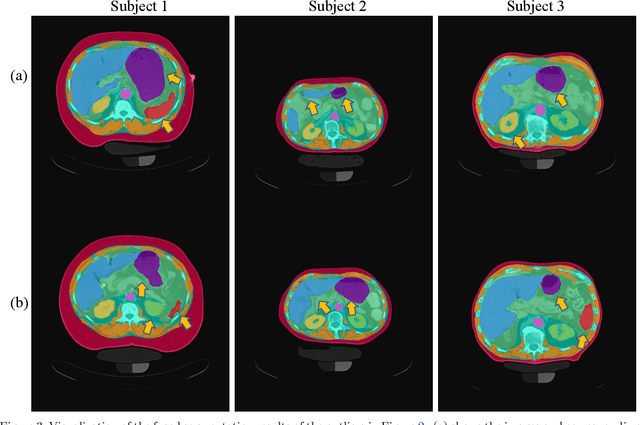
Metabolic health is increasingly implicated as a risk factor across conditions from cardiology to neurology, and efficiency assessment of body composition is critical to quantitatively characterizing these relationships. 2D low dose single slice computed tomography (CT) provides a high resolution, quantitative tissue map, albeit with a limited field of view. Although numerous potential analyses have been proposed in quantifying image context, there has been no comprehensive study for low-dose single slice CT longitudinal variability with automated segmentation. We studied a total of 1816 slices from 1469 subjects of Baltimore Longitudinal Study on Aging (BLSA) abdominal dataset using supervised deep learning-based segmentation and unsupervised clustering method. 300 out of 1469 subjects that have two year gap in their first two scans were pick out to evaluate longitudinal variability with measurements including intraclass correlation coefficient (ICC) and coefficient of variation (CV) in terms of tissues/organs size and mean intensity. We showed that our segmentation methods are stable in longitudinal settings with Dice ranged from 0.821 to 0.962 for thirteen target abdominal tissues structures. We observed high variability in most organ with ICC<0.5, low variability in the area of muscle, abdominal wall, fat and body mask with average ICC>0.8. We found that the variability in organ is highly related to the cross-sectional position of the 2D slice. Our efforts pave quantitative exploration and quality control to reduce uncertainties in longitudinal analysis.
Compound Figure Separation of Biomedical Images: Mining Large Datasets for Self-supervised Learning
Aug 30, 2022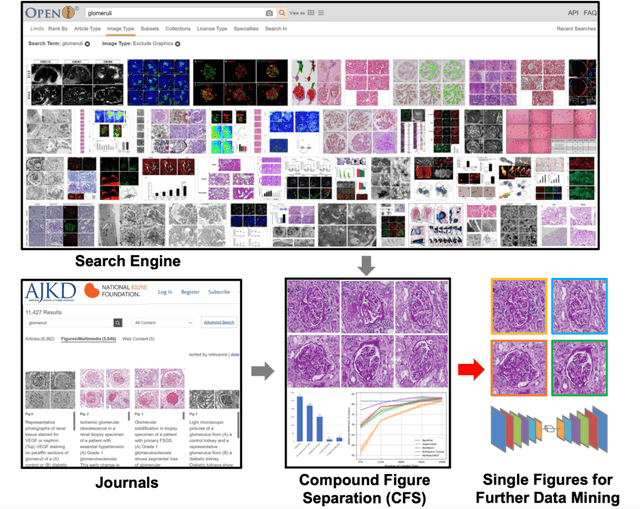
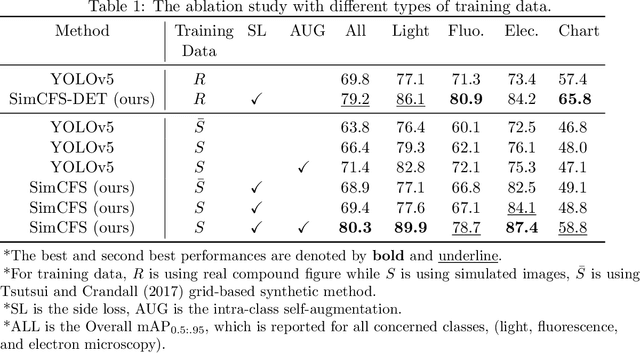
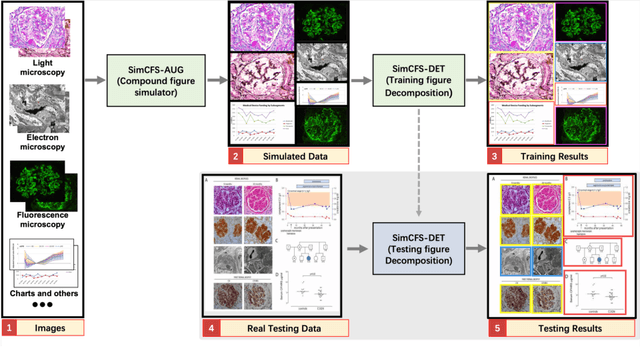
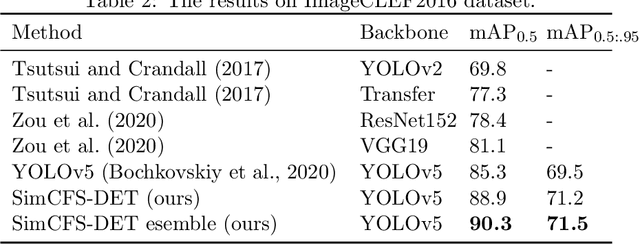
With the rapid development of self-supervised learning (e.g., contrastive learning), the importance of having large-scale images (even without annotations) for training a more generalizable AI model has been widely recognized in medical image analysis. However, collecting large-scale task-specific unannotated data at scale can be challenging for individual labs. Existing online resources, such as digital books, publications, and search engines, provide a new resource for obtaining large-scale images. However, published images in healthcare (e.g., radiology and pathology) consist of a considerable amount of compound figures with subplots. In order to extract and separate compound figures into usable individual images for downstream learning, we propose a simple compound figure separation (SimCFS) framework without using the traditionally required detection bounding box annotations, with a new loss function and a hard case simulation. Our technical contribution is four-fold: (1) we introduce a simulation-based training framework that minimizes the need for resource extensive bounding box annotations; (2) we propose a new side loss that is optimized for compound figure separation; (3) we propose an intra-class image augmentation method to simulate hard cases; and (4) to the best of our knowledge, this is the first study that evaluates the efficacy of leveraging self-supervised learning with compound image separation. From the results, the proposed SimCFS achieved state-of-the-art performance on the ImageCLEF 2016 Compound Figure Separation Database. The pretrained self-supervised learning model using large-scale mined figures improved the accuracy of downstream image classification tasks with a contrastive learning algorithm. The source code of SimCFS is made publicly available at https://github.com/hrlblab/ImageSeperation.
* Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://www.melba-journal.org/papers/2022:025.html. arXiv admin note: substantial text overlap with arXiv:2107.08650
Cross-scale Attention Guided Multi-instance Learning for Crohn's Disease Diagnosis with Pathological Images
Aug 15, 2022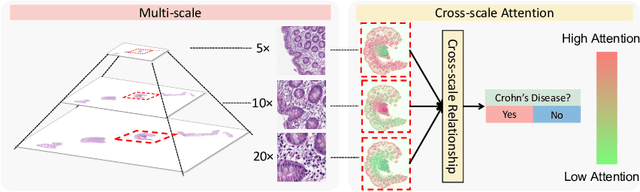
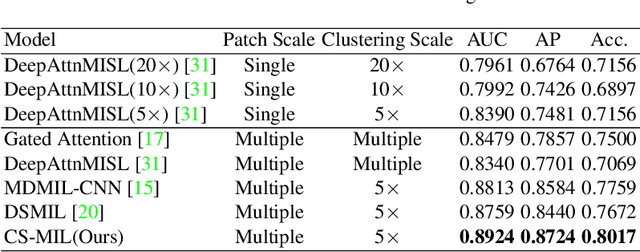
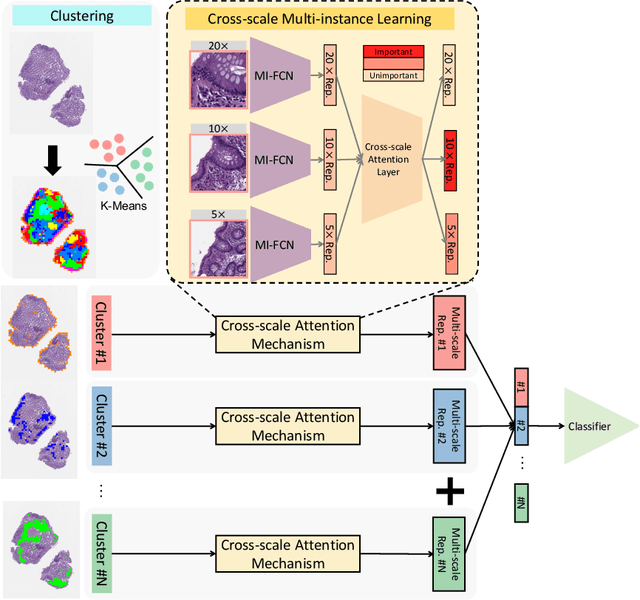
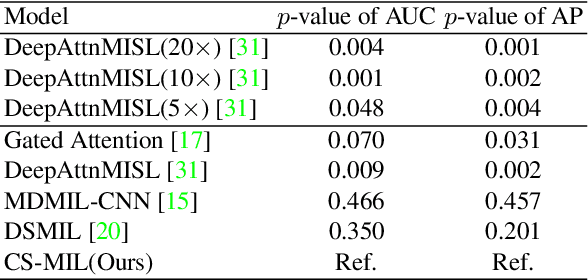
Multi-instance learning (MIL) is widely used in the computer-aided interpretation of pathological Whole Slide Images (WSIs) to solve the lack of pixel-wise or patch-wise annotations. Often, this approach directly applies "natural image driven" MIL algorithms which overlook the multi-scale (i.e. pyramidal) nature of WSIs. Off-the-shelf MIL algorithms are typically deployed on a single-scale of WSIs (e.g., 20x magnification), while human pathologists usually aggregate the global and local patterns in a multi-scale manner (e.g., by zooming in and out between different magnifications). In this study, we propose a novel cross-scale attention mechanism to explicitly aggregate inter-scale interactions into a single MIL network for Crohn's Disease (CD), which is a form of inflammatory bowel disease. The contribution of this paper is two-fold: (1) a cross-scale attention mechanism is proposed to aggregate features from different resolutions with multi-scale interaction; and (2) differential multi-scale attention visualizations are generated to localize explainable lesion patterns. By training ~250,000 H&E-stained Ascending Colon (AC) patches from 20 CD patient and 30 healthy control samples at different scales, our approach achieved a superior Area under the Curve (AUC) score of 0.8924 compared with baseline models. The official implementation is publicly available at https://github.com/hrlblab/CS-MIL.
Pseudo-Label Guided Multi-Contrast Generalization for Non-Contrast Organ-Aware Segmentation
May 12, 2022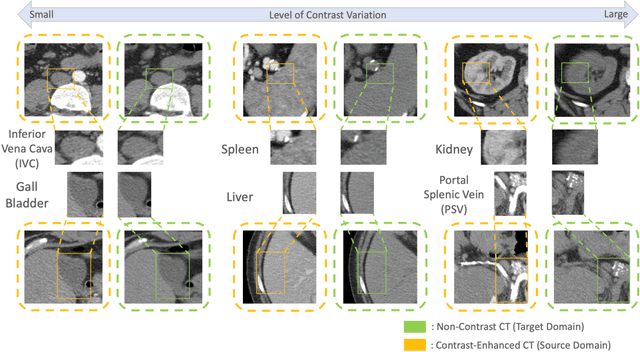
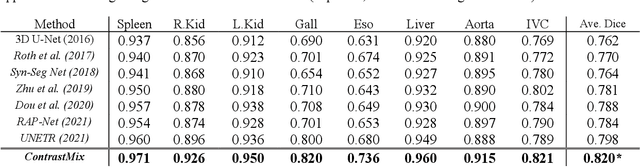
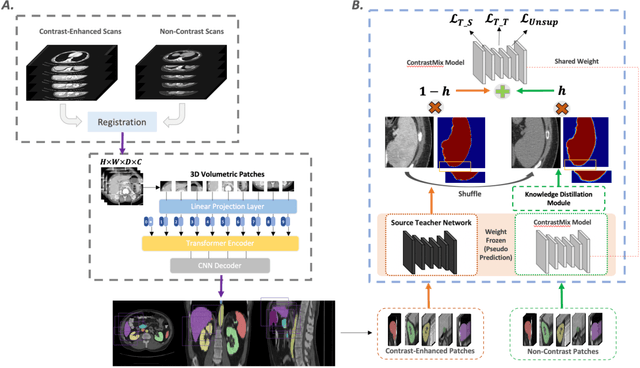
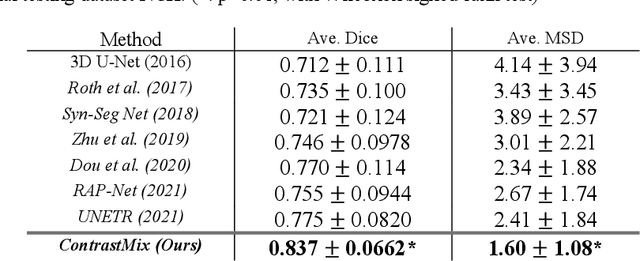
Non-contrast computed tomography (NCCT) is commonly acquired for lung cancer screening, assessment of general abdominal pain or suspected renal stones, trauma evaluation, and many other indications. However, the absence of contrast limits distinguishing organ in-between boundaries. In this paper, we propose a novel unsupervised approach that leverages pairwise contrast-enhanced CT (CECT) context to compute non-contrast segmentation without ground-truth label. Unlike generative adversarial approaches, we compute the pairwise morphological context with CECT to provide teacher guidance instead of generating fake anatomical context. Additionally, we further augment the intensity correlations in 'organ-specific' settings and increase the sensitivity to organ-aware boundary. We validate our approach on multi-organ segmentation with paired non-contrast & contrast-enhanced CT scans using five-fold cross-validation. Full external validations are performed on an independent non-contrast cohort for aorta segmentation. Compared with current abdominal organs segmentation state-of-the-art in fully supervised setting, our proposed pipeline achieves a significantly higher Dice by 3.98% (internal multi-organ annotated), and 8.00% (external aorta annotated) for abdominal organs segmentation. The code and pretrained models are publicly available at https://github.com/MASILab/ContrastMix.
Characterizing Renal Structures with 3D Block Aggregate Transformers
Mar 04, 2022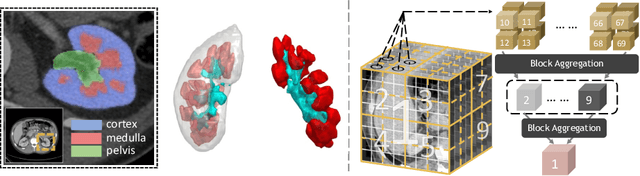
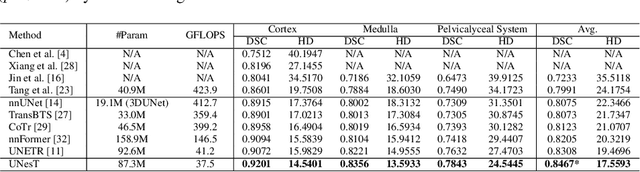
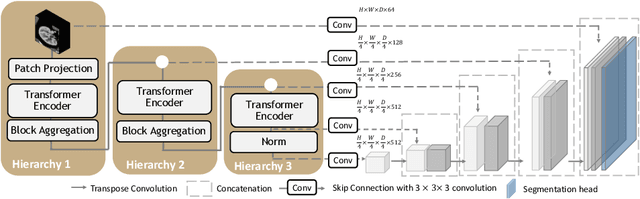

Efficiently quantifying renal structures can provide distinct spatial context and facilitate biomarker discovery for kidney morphology. However, the development and evaluation of the transformer model to segment the renal cortex, medulla, and collecting system remains challenging due to data inefficiency. Inspired by the hierarchical structures in vision transformer, we propose a novel method using a 3D block aggregation transformer for segmenting kidney components on contrast-enhanced CT scans. We construct the first cohort of renal substructures segmentation dataset with 116 subjects under institutional review board (IRB) approval. Our method yields the state-of-the-art performance (Dice of 0.8467) against the baseline approach of 0.8308 with the data-efficient design. The Pearson R achieves 0.9891 between the proposed method and manual standards and indicates the strong correlation and reproducibility for volumetric analysis. We extend the proposed method to the public KiTS dataset, the method leads to improved accuracy compared to transformer-based approaches. We show that the 3D block aggregation transformer can achieve local communication between sequence representations without modifying self-attention, and it can serve as an accurate and efficient quantification tool for characterizing renal structures.
Random Multi-Channel Image Synthesis for Multiplexed Immunofluorescence Imaging
Sep 18, 2021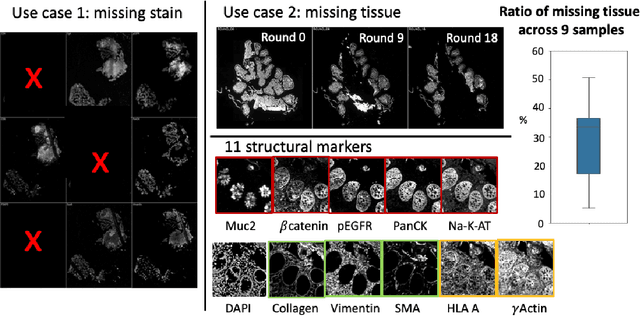
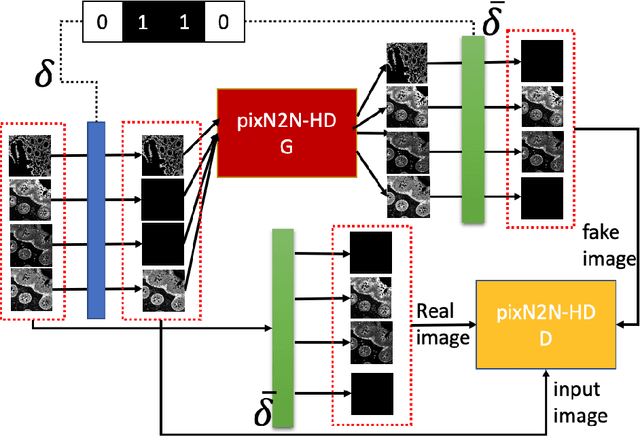
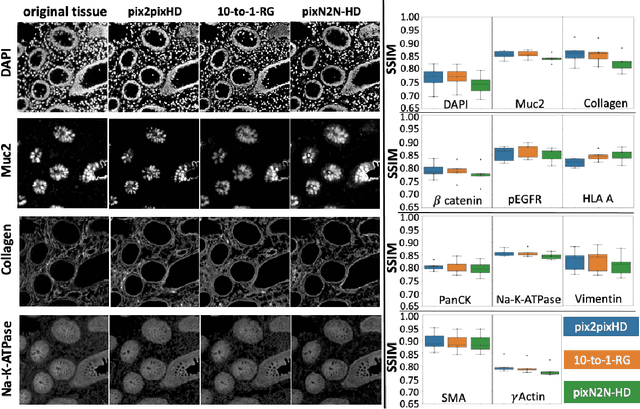
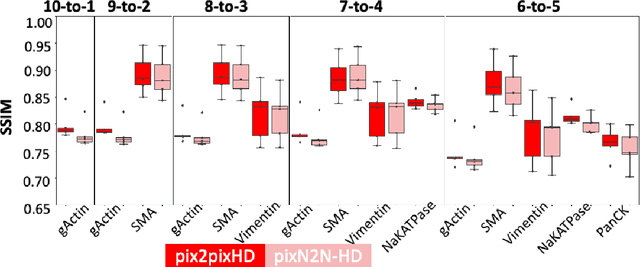
Multiplex immunofluorescence (MxIF) is an emerging imaging technique that produces the high sensitivity and specificity of single-cell mapping. With a tenet of 'seeing is believing', MxIF enables iterative staining and imaging extensive antibodies, which provides comprehensive biomarkers to segment and group different cells on a single tissue section. However, considerable depletion of the scarce tissue is inevitable from extensive rounds of staining and bleaching ('missing tissue'). Moreover, the immunofluorescence (IF) imaging can globally fail for particular rounds ('missing stain''). In this work, we focus on the 'missing stain' issue. It would be appealing to develop digital image synthesis approaches to restore missing stain images without losing more tissue physically. Herein, we aim to develop image synthesis approaches for eleven MxIF structural molecular markers (i.e., epithelial and stromal) on real samples. We propose a novel multi-channel high-resolution image synthesis approach, called pixN2N-HD, to tackle possible missing stain scenarios via a high-resolution generative adversarial network (GAN). Our contribution is three-fold: (1) a single deep network framework is proposed to tackle missing stain in MxIF; (2) the proposed 'N-to-N' strategy reduces theoretical four years of computational time to 20 hours when covering all possible missing stains scenarios, with up to five missing stains (e.g., '(N-1)-to-1', '(N-2)-to-2'); and (3) this work is the first comprehensive experimental study of investigating cross-stain synthesis in MxIF. Our results elucidate a promising direction of advancing MxIF imaging with deep image synthesis.