 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Exploiting Pseudo Future Contexts for Emotion Recognition in Conversations
Jun 27, 2023With the extensive accumulation of conversational data on the Internet, emotion recognition in conversations (ERC) has received increasing attention. Previous efforts of this task mainly focus on leveraging contextual and speaker-specific features, or integrating heterogeneous external commonsense knowledge. Among them, some heavily rely on future contexts, which, however, are not always available in real-life scenarios. This fact inspires us to generate pseudo future contexts to improve ERC. Specifically, for an utterance, we generate its future context with pre-trained language models, potentially containing extra beneficial knowledge in a conversational form homogeneous with the historical ones. These characteristics make pseudo future contexts easily fused with historical contexts and historical speaker-specific contexts, yielding a conceptually simple framework systematically integrating multi-contexts. Experimental results on four ERC datasets demonstrate our method's superiority. Further in-depth analyses reveal that pseudo future contexts can rival real ones to some extent, especially in relatively context-independent conversations.
MUSIED: A Benchmark for Event Detection from Multi-Source Heterogeneous Informal Texts
Nov 25, 2022



Event detection (ED) identifies and classifies event triggers from unstructured texts, serving as a fundamental task for information extraction. Despite the remarkable progress achieved in the past several years, most research efforts focus on detecting events from formal texts (e.g., news articles, Wikipedia documents, financial announcements). Moreover, the texts in each dataset are either from a single source or multiple yet relatively homogeneous sources. With massive amounts of user-generated text accumulating on the Web and inside enterprises, identifying meaningful events in these informal texts, usually from multiple heterogeneous sources, has become a problem of significant practical value. As a pioneering exploration that expands event detection to the scenarios involving informal and heterogeneous texts, we propose a new large-scale Chinese event detection dataset based on user reviews, text conversations, and phone conversations in a leading e-commerce platform for food service. We carefully investigate the proposed dataset's textual informality and multi-source heterogeneity characteristics by inspecting data samples quantitatively and qualitatively. Extensive experiments with state-of-the-art event detection methods verify the unique challenges posed by these characteristics, indicating that multi-source informal event detection remains an open problem and requires further efforts. Our benchmark and code are released at \url{https://github.com/myeclipse/MUSIED}.
A Low-Cost, Controllable and Interpretable Task-Oriented Chatbot: With Real-World After-Sale Services as Example
May 13, 2022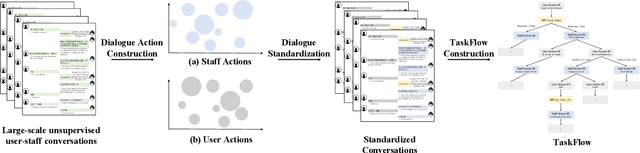
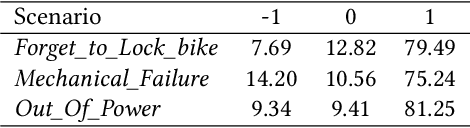
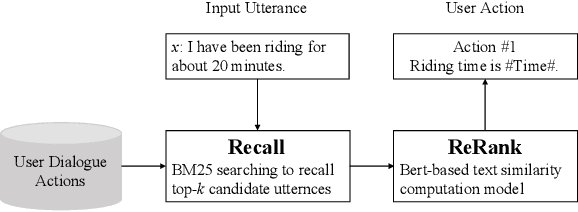
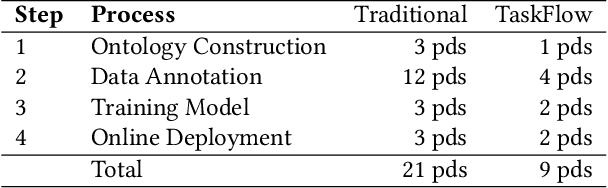
Though widely used in industry, traditional task-oriented dialogue systems suffer from three bottlenecks: (i) difficult ontology construction (e.g., intents and slots); (ii) poor controllability and interpretability; (iii) annotation-hungry. In this paper, we propose to represent utterance with a simpler concept named Dialogue Action, upon which we construct a tree-structured TaskFlow and further build task-oriented chatbot with TaskFlow as core component. A framework is presented to automatically construct TaskFlow from large-scale dialogues and deploy online. Our experiments on real-world after-sale customer services show TaskFlow can satisfy the major needs, as well as reduce the developer burden effectively.