 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoving Batch Normalization Boosts Adversarial Training
Jul 04, 2022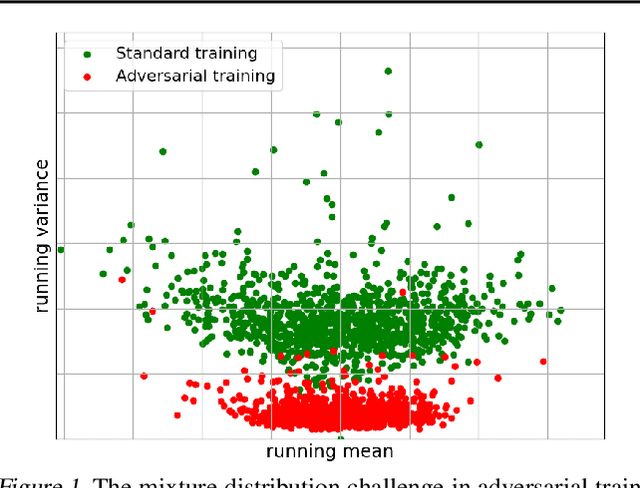
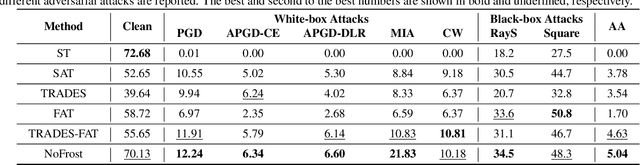
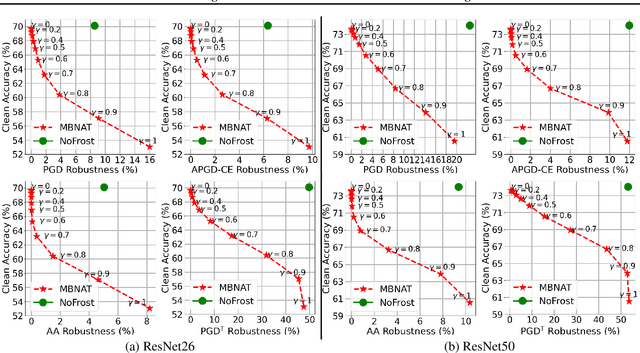
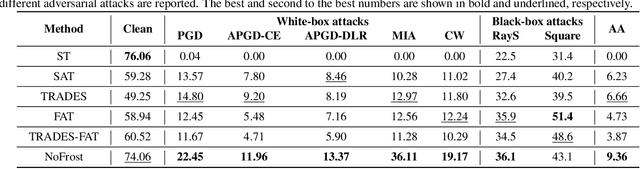
Adversarial training (AT) defends deep neural networks against adversarial attacks. One challenge that limits its practical application is the performance degradation on clean samples. A major bottleneck identified by previous works is the widely used batch normalization (BN), which struggles to model the different statistics of clean and adversarial training samples in AT. Although the dominant approach is to extend BN to capture this mixture of distribution, we propose to completely eliminate this bottleneck by removing all BN layers in AT. Our normalizer-free robust training (NoFrost) method extends recent advances in normalizer-free networks to AT for its unexplored advantage on handling the mixture distribution challenge. We show that NoFrost achieves adversarial robustness with only a minor sacrifice on clean sample accuracy. On ImageNet with ResNet50, NoFrost achieves $74.06\%$ clean accuracy, which drops merely $2.00\%$ from standard training. In contrast, BN-based AT obtains $59.28\%$ clean accuracy, suffering a significant $16.78\%$ drop from standard training. In addition, NoFrost achieves a $23.56\%$ adversarial robustness against PGD attack, which improves the $13.57\%$ robustness in BN-based AT. We observe better model smoothness and larger decision margins from NoFrost, which make the models less sensitive to input perturbations and thus more robust. Moreover, when incorporating more data augmentations into NoFrost, it achieves comprehensive robustness against multiple distribution shifts. Code and pre-trained models are public at https://github.com/amazon-research/normalizer-free-robust-training.
Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022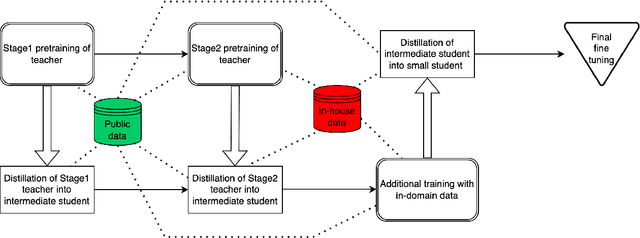
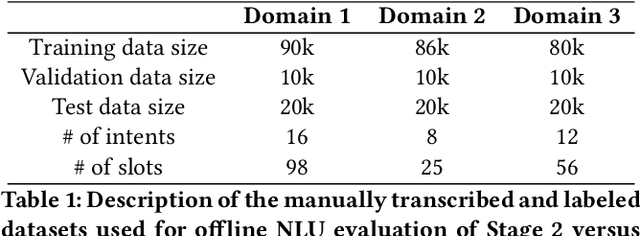
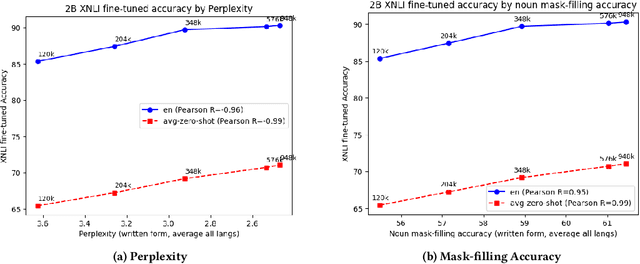
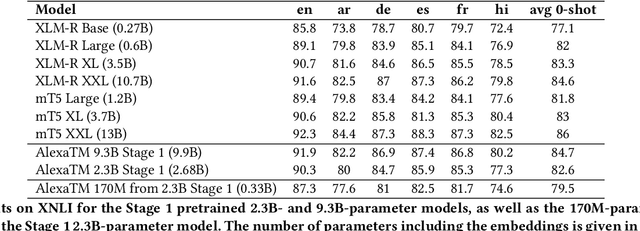
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022
Multi-modal Graph Learning for Disease Prediction
Mar 11, 2022
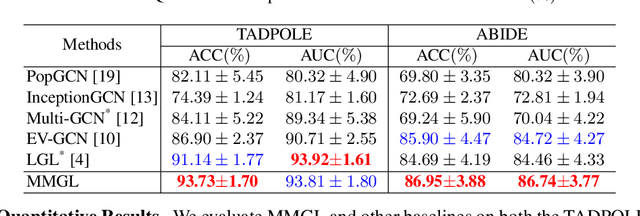
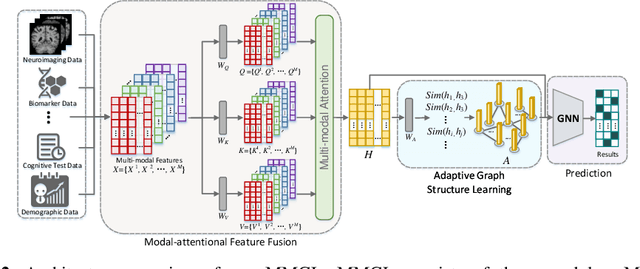
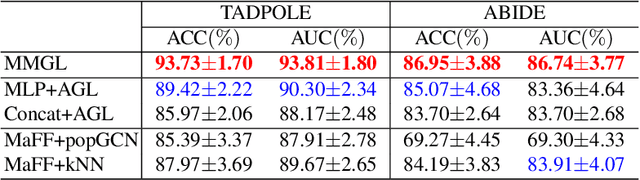
Benefiting from the powerful expressive capability of graphs, graph-based approaches have been popularly applied to handle multi-modal medical data and achieved impressive performance in various biomedical applications. For disease prediction tasks, most existing graph-based methods tend to define the graph manually based on specified modality (e.g., demographic information), and then integrated other modalities to obtain the patient representation by Graph Representation Learning (GRL). However, constructing an appropriate graph in advance is not a simple matter for these methods. Meanwhile, the complex correlation between modalities is ignored. These factors inevitably yield the inadequacy of providing sufficient information about the patient's condition for a reliable diagnosis. To this end, we propose an end-to-end Multi-modal Graph Learning framework (MMGL) for disease prediction with multi-modality. To effectively exploit the rich information across multi-modality associated with the disease, modality-aware representation learning is proposed to aggregate the features of each modality by leveraging the correlation and complementarity between the modalities. Furthermore, instead of defining the graph manually, the latent graph structure is captured through an effective way of adaptive graph learning. It could be jointly optimized with the prediction model, thus revealing the intrinsic connections among samples. Our model is also applicable to the scenario of inductive learning for those unseen data. An extensive group of experiments on two disease prediction tasks demonstrates that the proposed MMGL achieves more favorable performance. The code of MMGL is available at \url{https://github.com/SsGood/MMGL}.
ZSD-YOLO: Zero-Shot YOLO Detection using Vision-Language KnowledgeDistillation
Sep 24, 2021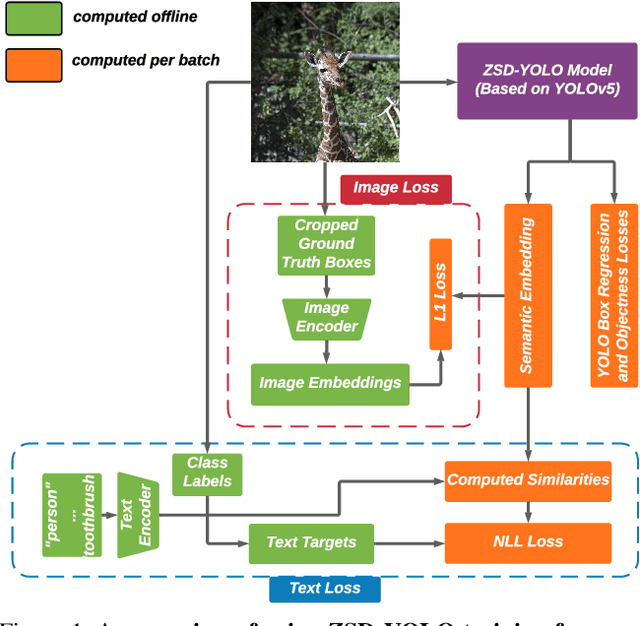
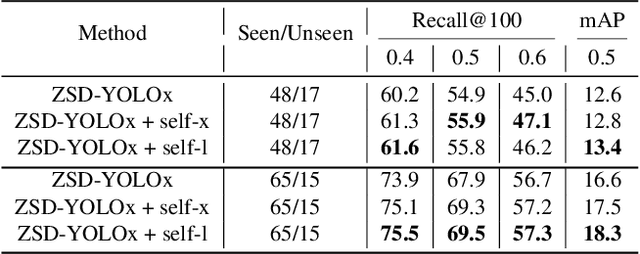
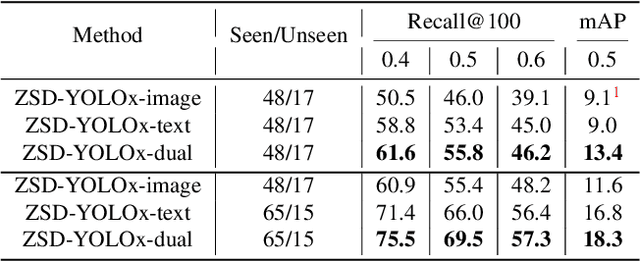

Real-world object sampling produces long-tailed distributions requiring exponentially more images for rare types. Zero-shot detection, which aims to detect unseen objects, is one direction to address this problem. A dataset such as COCO is extensively annotated across many images but with a sparse number of categories and annotating all object classes across a diverse domain is expensive and challenging. To advance zero-shot detection, we develop a Vision-Language distillation method that aligns both image and text embeddings from a zero-shot pre-trained model such as CLIP to a modified semantic prediction head from a one-stage detector like YOLOv5. With this method, we are able to train an object detector that achieves state-of-the-art accuracy on the COCO zero-shot detection splits with fewer model parameters. During inference, our model can be adapted to detect any number of object classes without additional training. We also find that the improvements provided by the scaling of our method are consistent across various YOLOv5 scales. Furthermore, we develop a self-training method that provides a significant score improvement without needing extra images nor labels.
CETransformer: Casual Effect Estimation via Transformer Based Representation Learning
Jul 19, 2021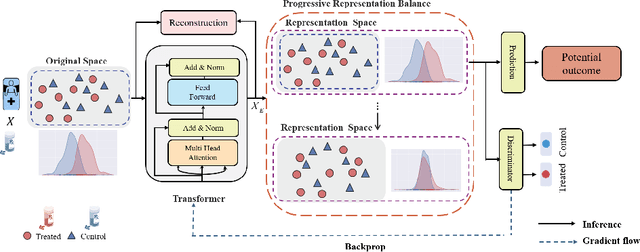
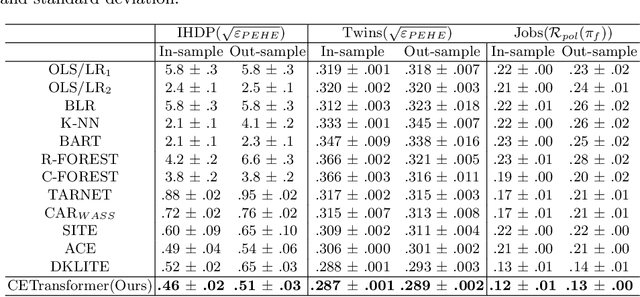
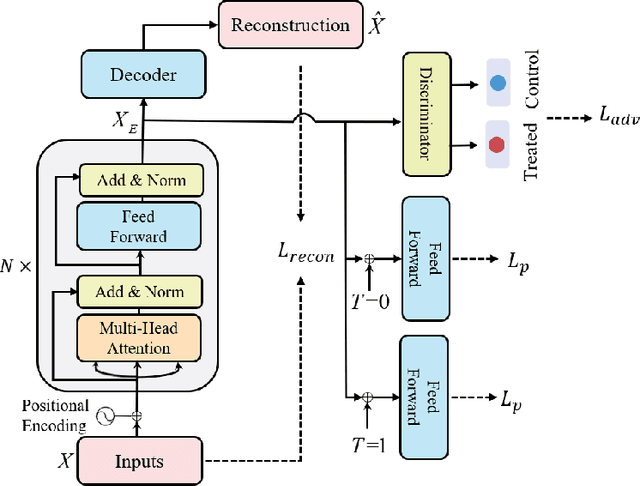
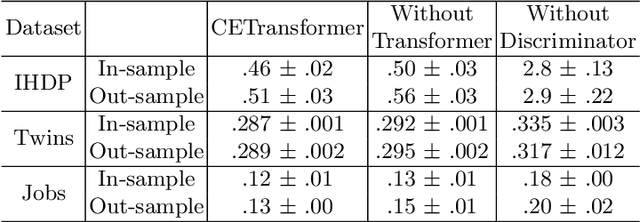
Treatment effect estimation, which refers to the estimation of causal effects and aims to measure the strength of the causal relationship, is of great importance in many fields but is a challenging problem in practice. As present, data-driven causal effect estimation faces two main challenges, i.e., selection bias and the missing of counterfactual. To address these two issues, most of the existing approaches tend to reduce the selection bias by learning a balanced representation, and then to estimate the counterfactual through the representation. However, they heavily rely on the finely hand-crafted metric functions when learning balanced representations, which generally doesn't work well for the situations where the original distribution is complicated. In this paper, we propose a CETransformer model for casual effect estimation via transformer based representation learning. To learn the representation of covariates(features) robustly, a self-supervised transformer is proposed, by which the correlation between covariates can be well exploited through self-attention mechanism. In addition, an adversarial network is adopted to balance the distribution of the treated and control groups in the representation space. Experimental results on three real-world datasets demonstrate the advantages of the proposed CETransformer, compared with the state-of-the-art treatment effect estimation methods.
Compressed Communication for Distributed Training: Adaptive Methods and System
May 17, 2021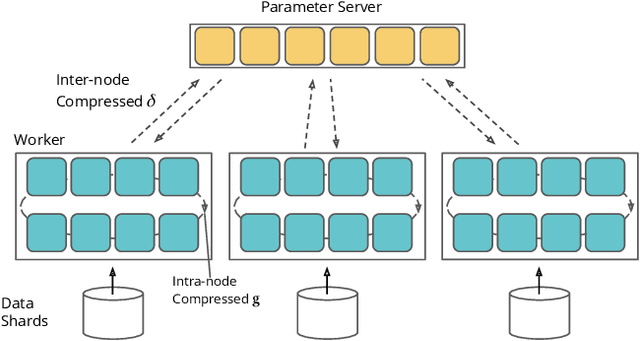

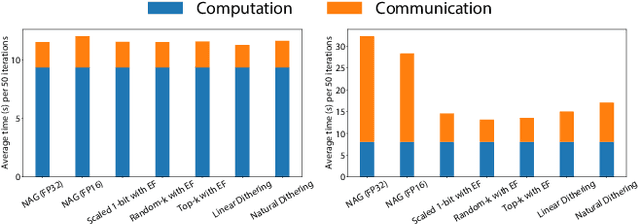
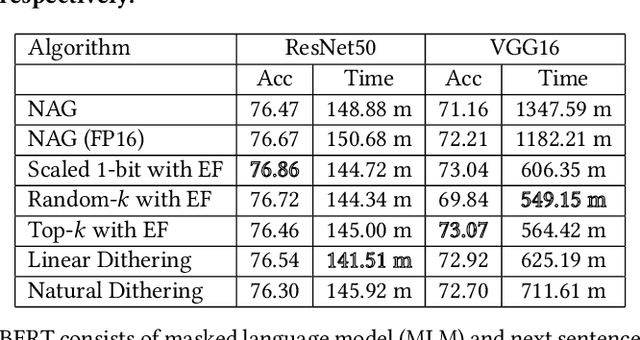
Communication overhead severely hinders the scalability of distributed machine learning systems. Recently, there has been a growing interest in using gradient compression to reduce the communication overhead of the distributed training. However, there is little understanding of applying gradient compression to adaptive gradient methods. Moreover, its performance benefits are often limited by the non-negligible compression overhead. In this paper, we first introduce a novel adaptive gradient method with gradient compression. We show that the proposed method has a convergence rate of $\mathcal{O}(1/\sqrt{T})$ for non-convex problems. In addition, we develop a scalable system called BytePS-Compress for two-way compression, where the gradients are compressed in both directions between workers and parameter servers. BytePS-Compress pipelines the compression and decompression on CPUs and achieves a high degree of parallelism. Empirical evaluations show that we improve the training time of ResNet50, VGG16, and BERT-base by 5.0%, 58.1%, 23.3%, respectively, without any accuracy loss with 25 Gb/s networking. Furthermore, for training the BERT models, we achieve a compression rate of 333x compared to the mixed-precision training.
Deep Time Series Models for Scarce Data
Mar 16, 2021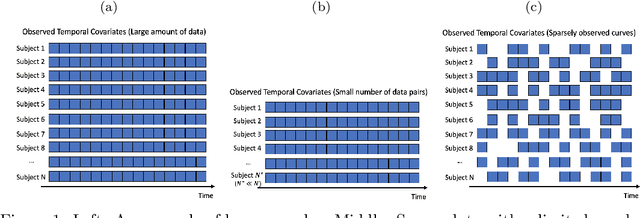
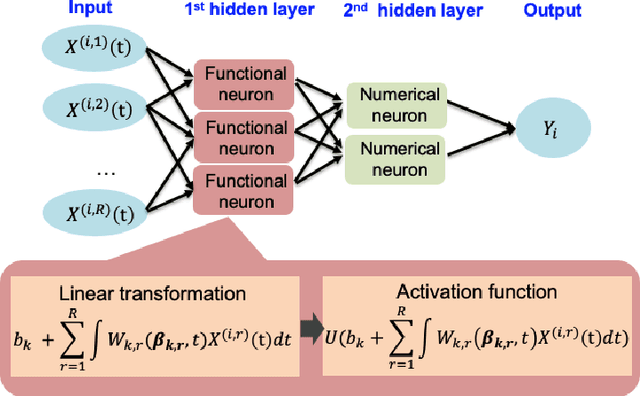
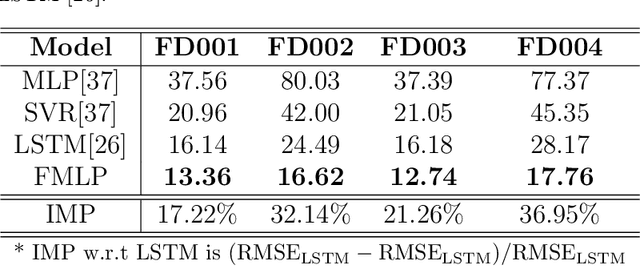
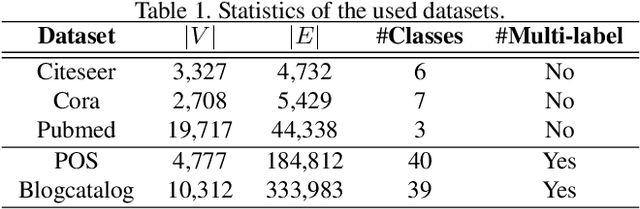
Time series data have grown at an explosive rate in numerous domains and have stimulated a surge of time series modeling research. A comprehensive comparison of different time series models, for a considered data analytics task, provides useful guidance on model selection for data analytics practitioners. Data scarcity is a universal issue that occurs in a vast range of data analytics problems, due to the high costs associated with collecting, generating, and labeling data as well as some data quality issues such as missing data. In this paper, we focus on the temporal classification/regression problem that attempts to build a mathematical mapping from multivariate time series inputs to a discrete class label or a real-valued response variable. For this specific problem, we identify two types of scarce data: scarce data with small samples and scarce data with sparsely and irregularly observed time series covariates. Observing that all existing works are incapable of utilizing the sparse time series inputs for proper modeling building, we propose a model called sparse functional multilayer perceptron (SFMLP) for handling the sparsity in the time series covariates. The effectiveness of the proposed SFMLP under each of the two types of data scarcity, in comparison with the conventional deep sequential learning models (e.g., Recurrent Neural Network, and Long Short-Term Memory), is investigated through mathematical arguments and numerical experiments.
Margin Preserving Self-paced Contrastive Learning Towards Domain Adaptation for Medical Image Segmentation
Mar 15, 2021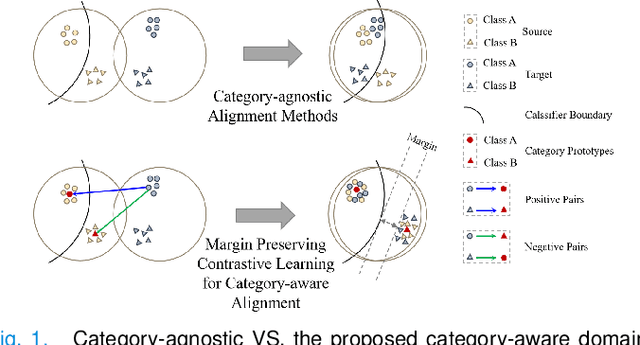
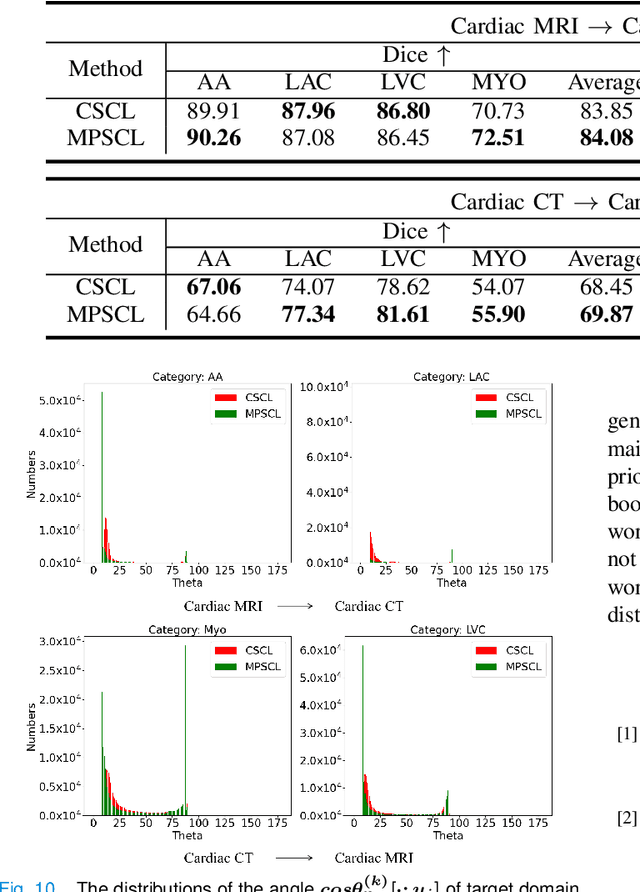
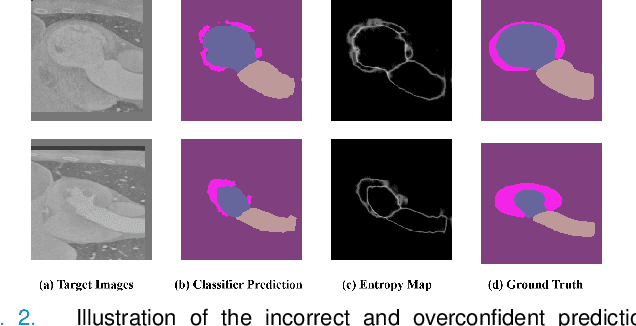
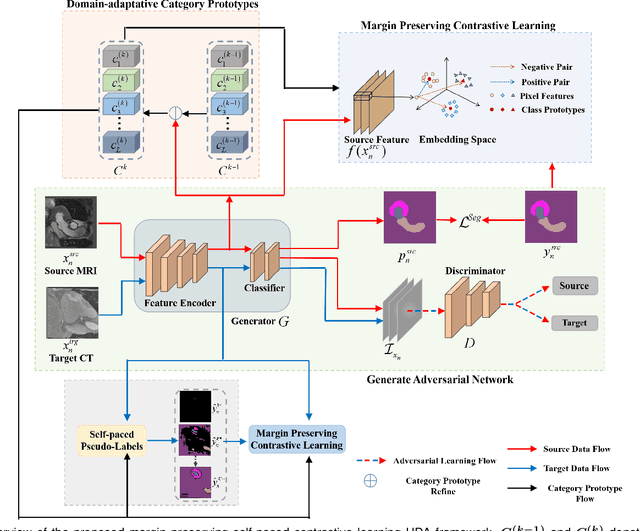
To bridge the gap between the source and target domains in unsupervised domain adaptation (UDA), the most common strategy puts focus on matching the marginal distributions in the feature space through adversarial learning. However, such category-agnostic global alignment lacks of exploiting the class-level joint distributions, causing the aligned distribution less discriminative. To address this issue, we propose in this paper a novel margin preserving self-paced contrastive Learning (MPSCL) model for cross-modal medical image segmentation. Unlike the conventional construction of contrastive pairs in contrastive learning, the domain-adaptive category prototypes are utilized to constitute the positive and negative sample pairs. With the guidance of progressively refined semantic prototypes, a novel margin preserving contrastive loss is proposed to boost the discriminability of embedded representation space. To enhance the supervision for contrastive learning, more informative pseudo-labels are generated in target domain in a self-paced way, thus benefiting the category-aware distribution alignment for UDA. Furthermore, the domain-invariant representations are learned through joint contrastive learning between the two domains. Extensive experiments on cross-modal cardiac segmentation tasks demonstrate that MPSCL significantly improves semantic segmentation performance, and outperforms a wide variety of state-of-the-art methods by a large margin.
Adversarial Graph Disentanglement
Mar 12, 2021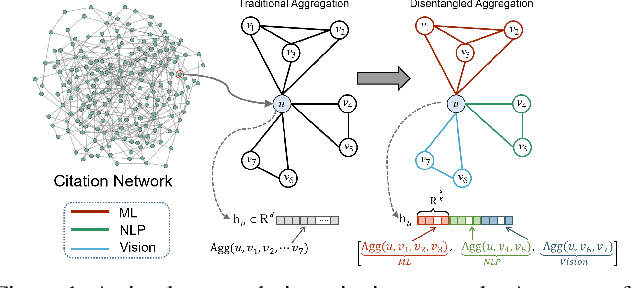
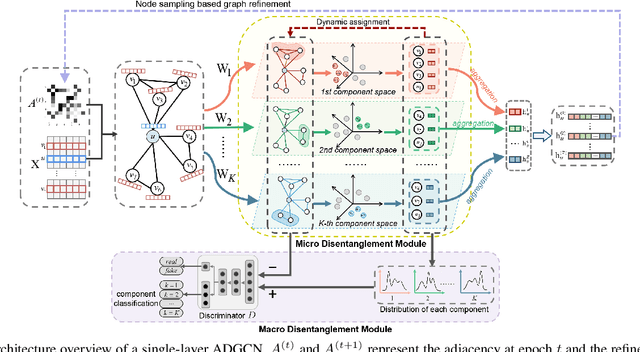
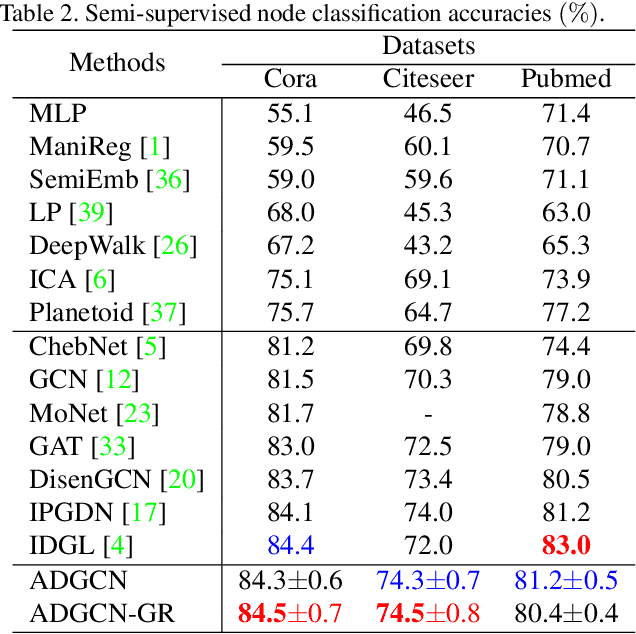
A real-world graph has a complex topology structure, which is often formed by the interaction of different latent factors. Disentanglement of these latent factors can effectively improve the robustness and interpretability of node representation of the graph. However, most existing methods lack consideration of the intrinsic differences in links caused by factor entanglement. In this paper, we propose an Adversarial Disentangled Graph Convolutional Network (ADGCN) for disentangled graph representation learning. Specifically, a dynamic multi-component convolution layer is designed to achieve micro-disentanglement by inferring latent components that caused links between nodes. On the basis of micro-disentanglement, we further propose a macro-disentanglement adversarial regularizer that improves the separability between component distributions, thus restricting interdependence among components. Additionally, to learn collaboratively a better disentangled representation and topological structure, a diversity preserving node sampling-based progressive refinement of graph structure is proposed. The experimental results on various real-world graph data verify that our ADGCN obtains remarkably more favorable performance over currently available alternatives.