 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Beamforming Design for RIS-enabled Integrated Positioning and Communication in Millimeter Wave Systems
May 20, 2023

Integrated positioning and communication (IPAC) system and reconfigurable intelligent surface (RIS) are both considered to be key technologies for future wireless networks. Therefore, in this paper, we propose a RIS-enabled IPAC scheme with the millimeter wave system. First, we derive the explicit expressions of the time-of-arrival (ToA)-based Cram\'er-Rao bound (CRB) and positioning error bound (PEB) for the RIS-aided system as the positioning metrics. Then, we formulate the IPAC system by jointly optimizing active beamforming in the base station (BS) and passive beamforming in the RIS to minimize the transmit power, while satisfying the communication data rate and PEB constraints. Finally, we propose an efficient two-stage algorithm to solve the optimization problem based on a series of methods such as the exhaustive search and semidefinite relaxation (SDR). Simulation results show that by changing various critical system parameters, the proposed RIS-enabled IPAC system can cater to both reliable data rates and high-precision positioning in different transmission environments.
Robust Power Allocation for Integrated Visible Light Positioning and Communication Networks
May 17, 2023



Integrated visible light positioning and communication (VLPC), capable of combining advantages of visible light communications (VLC) and visible light positioning (VLP), is a promising key technology for the future Internet of Things. In VLPC networks, positioning and communications are inherently coupled, which has not been sufficiently explored in the literature. We propose a robust power allocation scheme for integrated VLPC Networks by exploiting the intrinsic relationship between positioning and communications. Specifically, we derive explicit relationships between random positioning errors, following both a Gaussian distribution and an arbitrary distribution, and channel state information errors. Then, we minimize the Cramer-Rao lower bound (CRLB) of positioning errors, subject to the rate outage constraint and the power constraints, which is a chance-constrained optimization problem and generally computationally intractable. To circumvent the nonconvex challenge, we conservatively transform the chance constraints to deterministic forms by using the Bernstein-type inequality and the conditional value-at-risk for the Gaussian and arbitrary distributed positioning errors, respectively, and then approximate them as convex semidefinite programs. Finally, simulation results verify the robustness and effectiveness of our proposed integrated VLPC design schemes.
Mathematical Characterization of Signal Semantics and Rethinking of the Mathematical Theory of Information
Mar 26, 2023



Shannon information theory is established based on probability and bits, and the communication technology based on this theory realizes the information age. The original goal of Shannon's information theory is to describe and transmit information content. However, due to information is related to cognition, and cognition is considered to be subjective, Shannon information theory is to describe and transmit information-bearing signals. With the development of the information age to the intelligent age, the traditional signal-oriented processing needs to be upgraded to content-oriented processing. For example, chat generative pre-trained transformer (ChatGPT) has initially realized the content processing capability based on massive data. For many years, researchers have been searching for the answer to what the information content in the signal is, because only when the information content is mathematically and accurately described can information-based machines be truly intelligent. This paper starts from rethinking the essence of the basic concepts of the information, such as semantics, meaning, information and knowledge, presents the mathematical characterization of the information content, investigate the relationship between them, studies the transformation from Shannon's signal information theory to semantic information theory, and therefore proposes a content-oriented semantic communication framework. Furthermore, we propose semantic decomposition and composition scheme to achieve conversion between complex and simple semantics. Finally, we verify the proposed characterization of information-related concepts by implementing evolvable knowledge-based semantic recognition.
Features Disentangled Semantic Broadcast Communication Networks
Mar 03, 2023



Single-user semantic communications have attracted extensive research recently, but multi-user semantic broadcast communication (BC) is still in its infancy. In this paper, we propose a practical robust features-disentangled multi-user semantic BC framework, where the transmitter includes a feature selection module and each user has a feature completion module. Instead of broadcasting all extracted features, the semantic encoder extracts the disentangled semantic features, and then only the users' intended semantic features are selected for broadcasting, which can further improve the transmission efficiency. Within this framework, we further investigate two information-theoretic metrics, including the ultimate compression rate under both the distortion and perception constraints, and the achievable rate region of the semantic BC. Furthermore, to realize the proposed semantic BC framework, we design a lightweight robust semantic BC network by exploiting a supervised autoencoder (AE), which can controllably disentangle sematic features. Moreover, we design the first hardware proof-of-concept prototype of the semantic BC network, where the proposed semantic BC network can be implemented in real time. Simulations and experiments demonstrate that the proposed robust semantic BC network can significantly improve transmission efficiency.
Task-oriented Explainable Semantic Communications
Feb 27, 2023



Semantic communications utilize the transceiver computing resources to alleviate scarce transmission resources, such as bandwidth and energy. Although the conventional deep learning (DL) based designs may achieve certain transmission efficiency, the uninterpretability issue of extracted features is the major challenge in the development of semantic communications. In this paper, we propose an explainable and robust semantic communication framework by incorporating the well-established bit-level communication system, which not only extracts and disentangles features into independent and semantically interpretable features, but also only selects task-relevant features for transmission, instead of all extracted features. Based on this framework, we derive the optimal input for rate-distortion-perception theory, and derive both lower and upper bounds on the semantic channel capacity. Furthermore, based on the $\beta $-variational autoencoder ($\beta $-VAE), we propose a practical explainable semantic communication system design, which simultaneously achieves semantic features selection and is robust against semantic channel noise. We further design a real-time wireless mobile semantic communication proof-of-concept prototype. Our simulations and experiments demonstrate that our proposed explainable semantic communications system can significantly improve transmission efficiency, and also verify the effectiveness of our proposed robust semantic transmission scheme.
Global Algorithms for Mean-Variance Optimization in Markov Decision Processes
Feb 27, 2023Dynamic optimization of mean and variance in Markov decision processes (MDPs) is a long-standing challenge caused by the failure of dynamic programming. In this paper, we propose a new approach to find the globally optimal policy for combined metrics of steady-state mean and variance in an infinite-horizon undiscounted MDP. By introducing the concepts of pseudo mean and pseudo variance, we convert the original problem to a bilevel MDP problem, where the inner one is a standard MDP optimizing pseudo mean-variance and the outer one is a single parameter selection problem optimizing pseudo mean. We use the sensitivity analysis of MDPs to derive the properties of this bilevel problem. By solving inner standard MDPs for pseudo mean-variance optimization, we can identify worse policy spaces dominated by optimal policies of the pseudo problems. We propose an optimization algorithm which can find the globally optimal policy by repeatedly removing worse policy spaces. The convergence and complexity of the algorithm are studied. Another policy dominance property is also proposed to further improve the algorithm efficiency. Numerical experiments demonstrate the performance and efficiency of our algorithms. To the best of our knowledge, our algorithm is the first that efficiently finds the globally optimal policy of mean-variance optimization in MDPs. These results are also valid for solely minimizing the variance metrics in MDPs.
Competent but Rigid: Identifying the Gap in Empowering AI to Participate Equally in Group Decision-Making
Feb 17, 2023



Existing research on human-AI collaborative decision-making focuses mainly on the interaction between AI and individual decision-makers. There is a limited understanding of how AI may perform in group decision-making. This paper presents a wizard-of-oz study in which two participants and an AI form a committee to rank three English essays. One novelty of our study is that we adopt a speculative design by endowing AI equal power to humans in group decision-making.We enable the AI to discuss and vote equally with other human members. We find that although the voice of AI is considered valuable, AI still plays a secondary role in the group because it cannot fully follow the dynamics of the discussion and make progressive contributions. Moreover, the divergent opinions of our participants regarding an "equal AI" shed light on the possible future of human-AI relations.
Who Should I Trust: AI or Myself? Leveraging Human and AI Correctness Likelihood to Promote Appropriate Trust in AI-Assisted Decision-Making
Jan 14, 2023



In AI-assisted decision-making, it is critical for human decision-makers to know when to trust AI and when to trust themselves. However, prior studies calibrated human trust only based on AI confidence indicating AI's correctness likelihood (CL) but ignored humans' CL, hindering optimal team decision-making. To mitigate this gap, we proposed to promote humans' appropriate trust based on the CL of both sides at a task-instance level. We first modeled humans' CL by approximating their decision-making models and computing their potential performance in similar instances. We demonstrated the feasibility and effectiveness of our model via two preliminary studies. Then, we proposed three CL exploitation strategies to calibrate users' trust explicitly/implicitly in the AI-assisted decision-making process. Results from a between-subjects experiment (N=293) showed that our CL exploitation strategies promoted more appropriate human trust in AI, compared with only using AI confidence. We further provided practical implications for more human-compatible AI-assisted decision-making.
Joint Beamforming and PD Orientation Design for Mobile Visible Light Communications
Dec 21, 2022



In this paper, we propose joint beamforming and photo-detector (PD) orientation (BO) optimization schemes for mobile visible light communication (VLC) with the orientation adjustable receiver (OAR). Since VLC is sensitive to line-of-sight propagation, we first establish the OAR model and the human body blockage model for mobile VLC user equipment (UE). To guarantee the quality of service (QoS) of mobile VLC, we jointly optimize BO with minimal UE the power consumption for both fixed and random UE orientation cases. For the fixed UE orientation case, since the {transmit} beamforming and the PD orientation are mutually coupled, the joint BO optimization problem is nonconvex and intractable. To address this challenge, we propose an alternating optimization algorithm to obtain the transmit beamforming and the PD orientation. For the random UE orientation case, we further propose a robust alternating BO optimization algorithm to ensure the worst-case QoS requirement of the mobile UE. Finally, the performance of joint BO optimization design schemes are evaluated for mobile VLC through numerical experiments.
HORIZON: A High-Resolution Panorama Synthesis Framework
Oct 10, 2022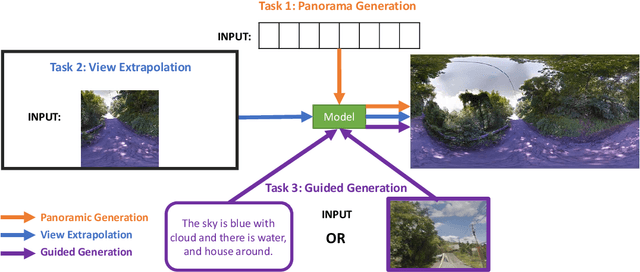
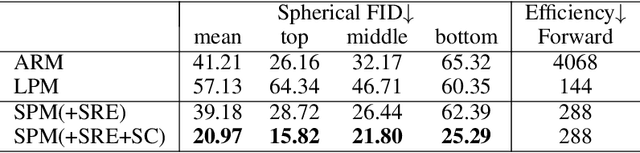
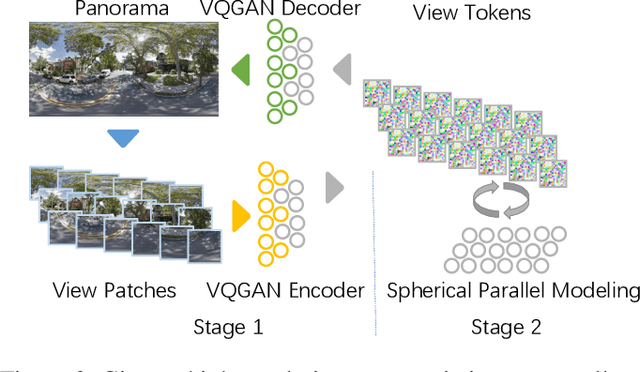

Panorama synthesis aims to generate a visual scene with all 360-degree views and enables an immersive virtual world. If the panorama synthesis process can be semantically controlled, we can then build an interactive virtual world and form an unprecedented human-computer interaction experience. Existing panoramic synthesis methods mainly focus on dealing with the inherent challenges brought by panoramas' spherical structure such as the projection distortion and the in-continuity problem when stitching edges, but is hard to effectively control semantics. The recent success of visual synthesis like DALL.E generates promising 2D flat images with semantic control, however, it is hard to directly be applied to panorama synthesis which inevitably generates distorted content. Besides, both of the above methods can not effectively synthesize high-resolution panoramas either because of quality or inference speed. In this work, we propose a new generation framework for high-resolution panorama images. The contributions include 1) alleviating the spherical distortion and edge in-continuity problem through spherical modeling, 2) supporting semantic control through both image and text hints, and 3) effectively generating high-resolution panoramas through parallel decoding. Our experimental results on a large-scale high-resolution Street View dataset validated the superiority of our approach quantitatively and qualitatively.