 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-efficient density quantum machine learning
May 30, 2024Quantum machine learning requires powerful, flexible and efficiently trainable models to be successful in solving challenging problems. In this work, we present density quantum neural networks, a learning model incorporating randomisation over a set of trainable unitaries. These models generalise quantum neural networks using parameterised quantum circuits, and allow a trade-off between expressibility and efficient trainability, particularly on quantum hardware. We demonstrate the flexibility of the formalism by applying it to two recently proposed model families. The first are commuting-block quantum neural networks (QNNs) which are efficiently trainable but may be limited in expressibility. The second are orthogonal (Hamming-weight preserving) quantum neural networks which provide well-defined and interpretable transformations on data but are challenging to train at scale on quantum devices. Density commuting QNNs improve capacity with minimal gradient complexity overhead, and density orthogonal neural networks admit a quadratic-to-constant gradient query advantage with minimal to no performance loss. We conduct numerical experiments on synthetic translationally invariant data and MNIST image data with hyperparameter optimisation to support our findings. Finally, we discuss the connection to post-variational quantum neural networks, measurement-based quantum machine learning and the dropout mechanism.
Quantum Deep Hedging
Mar 29, 2023



Quantum machine learning has the potential for a transformative impact across industry sectors and in particular in finance. In our work we look at the problem of hedging where deep reinforcement learning offers a powerful framework for real markets. We develop quantum reinforcement learning methods based on policy-search and distributional actor-critic algorithms that use quantum neural network architectures with orthogonal and compound layers for the policy and value functions. We prove that the quantum neural networks we use are trainable, and we perform extensive simulations that show that quantum models can reduce the number of trainable parameters while achieving comparable performance and that the distributional approach obtains better performance than other standard approaches, both classical and quantum. We successfully implement the proposed models on a trapped-ion quantum processor, utilizing circuits with up to $16$ qubits, and observe performance that agrees well with noiseless simulation. Our quantum techniques are general and can be applied to other reinforcement learning problems beyond hedging.
Quantum Vision Transformers
Sep 16, 2022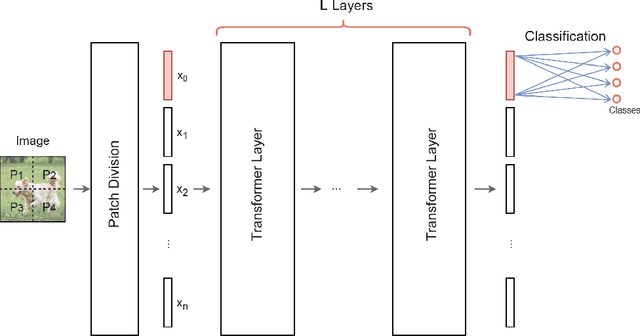
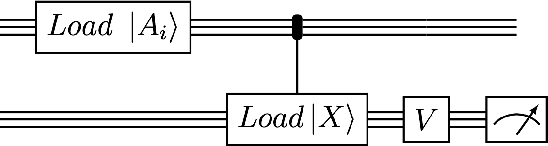
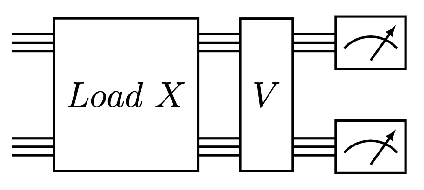
We design and analyse quantum transformers, extending the state-of-the-art classical transformer neural network architectures known to be very performant in natural language processing and image analysis. Building upon the previous work of parametrised quantum circuits for data loading and orthogonal neural layers, we introduce three quantum attention mechanisms, including a quantum transformer based on compound matrices. These quantum architectures can be built using shallow quantum circuits and can provide qualitatively different classification models. We performed extensive simulations of the quantum transformers on standard medical image datasets that showed competitive, and at times better, performance compared with the best classical transformers and other classical benchmarks. The computational complexity of our quantum attention layer proves to be advantageous compared with the classical algorithm with respect to the size of the classified images. Our quantum architectures have thousands of parameters compared with the best classical methods with millions of parameters. Finally, we have implemented our quantum transformers on superconducting quantum computers and obtained encouraging results for up to six qubit experiments.
Quantum Reinforcement Learning via Policy Iteration
Mar 03, 2022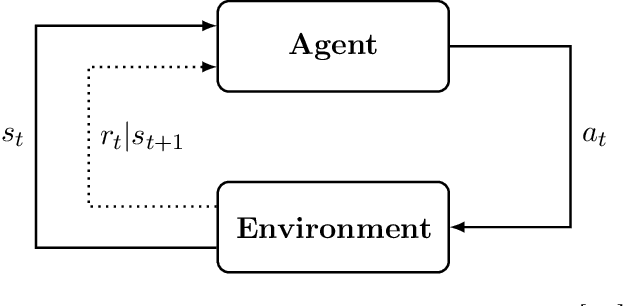
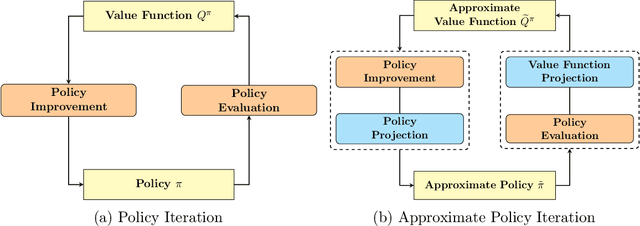
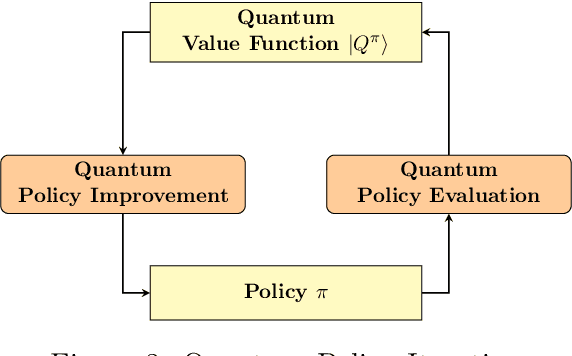
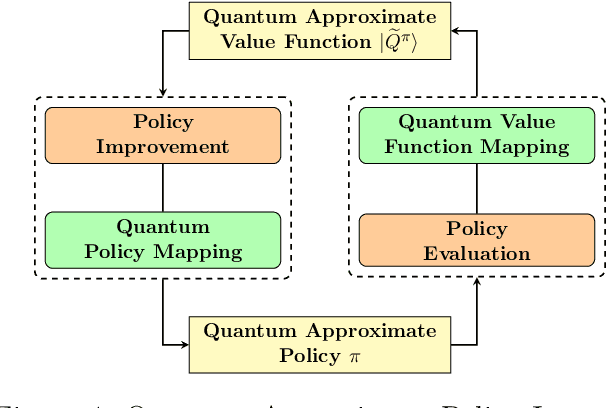
Quantum computing has shown the potential to substantially speed up machine learning applications, in particular for supervised and unsupervised learning. Reinforcement learning, on the other hand, has become essential for solving many decision making problems and policy iteration methods remain the foundation of such approaches. In this paper, we provide a general framework for performing quantum reinforcement learning via policy iteration. We validate our framework by designing and analyzing: \emph{quantum policy evaluation} methods for infinite horizon discounted problems by building quantum states that approximately encode the value function of a policy $\pi$; and \emph{quantum policy improvement} methods by post-processing measurement outcomes on these quantum states. Last, we study the theoretical and experimental performance of our quantum algorithms on two environments from OpenAI's Gym.