 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Architecture Search for Speech Emotion Recognition
Mar 31, 2022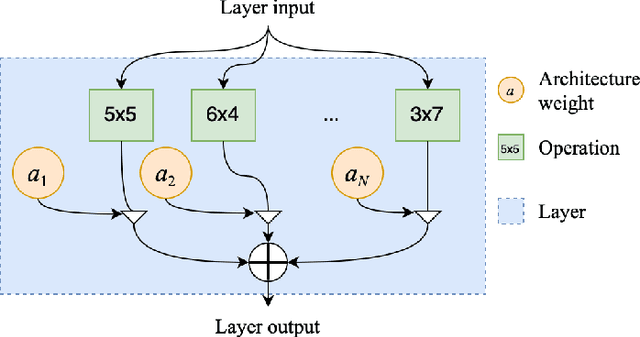
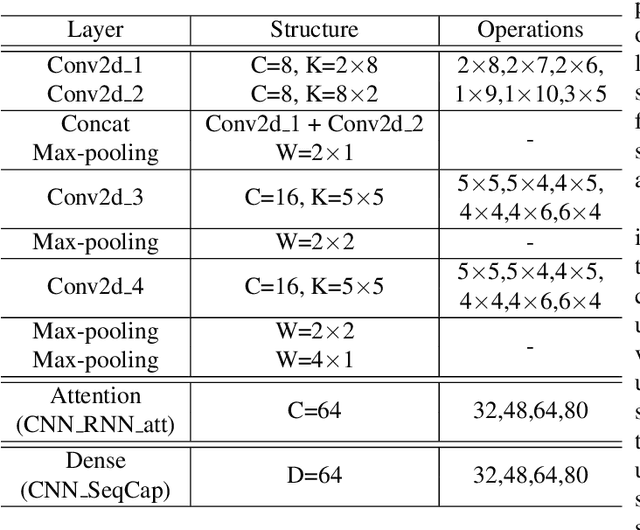
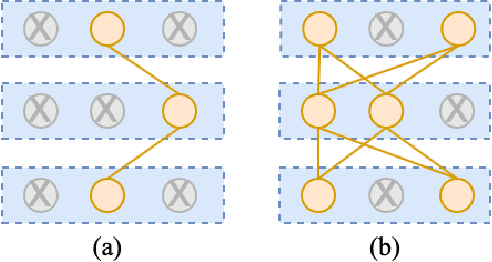
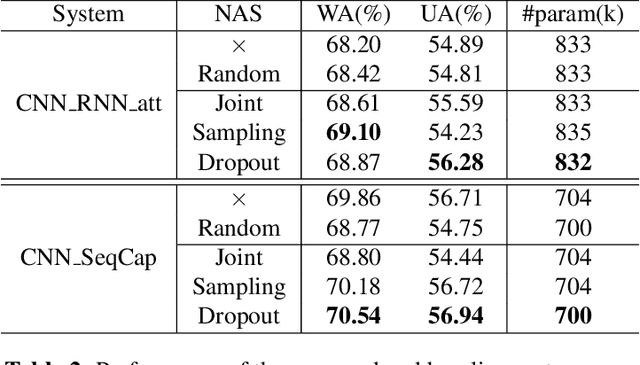
Deep neural networks have brought significant advancements to speech emotion recognition (SER). However, the architecture design in SER is mainly based on expert knowledge and empirical (trial-and-error) evaluations, which is time-consuming and resource intensive. In this paper, we propose to apply neural architecture search (NAS) techniques to automatically configure the SER models. To accelerate the candidate architecture optimization, we propose a uniform path dropout strategy to encourage all candidate architecture operations to be equally optimized. Experimental results of two different neural structures on IEMOCAP show that NAS can improve SER performance (54.89\% to 56.28\%) while maintaining model parameter sizes. The proposed dropout strategy also shows superiority over the previous approaches.
Exploiting Cross Domain Acoustic-to-articulatory Inverted Features For Disordered Speech Recognition
Mar 19, 2022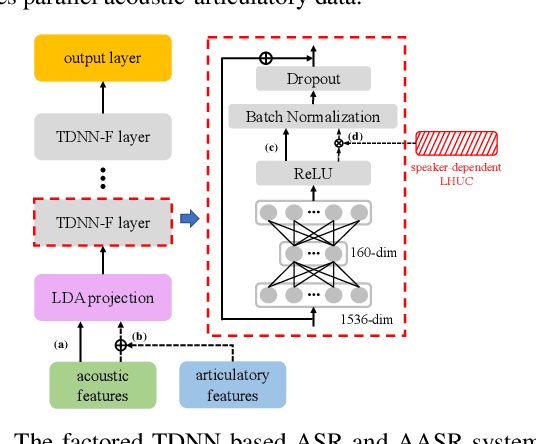
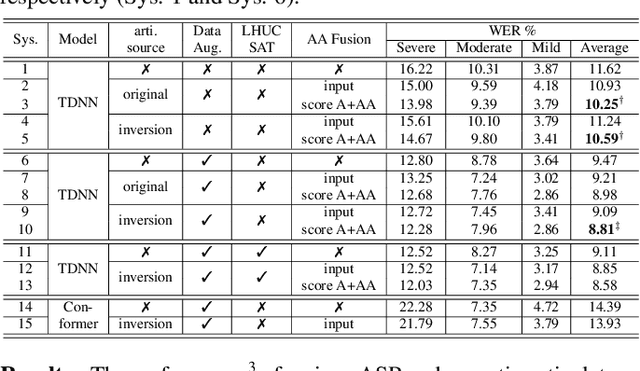
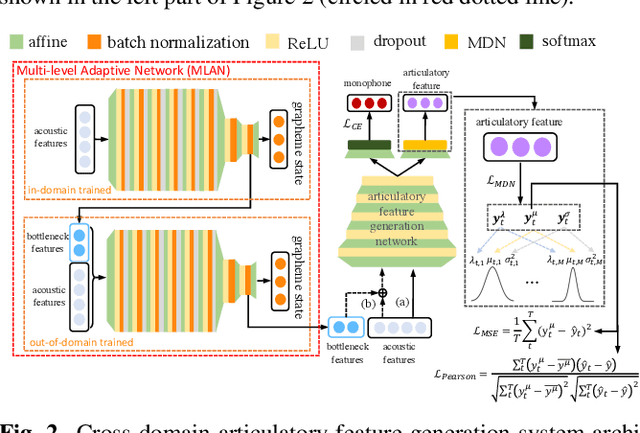
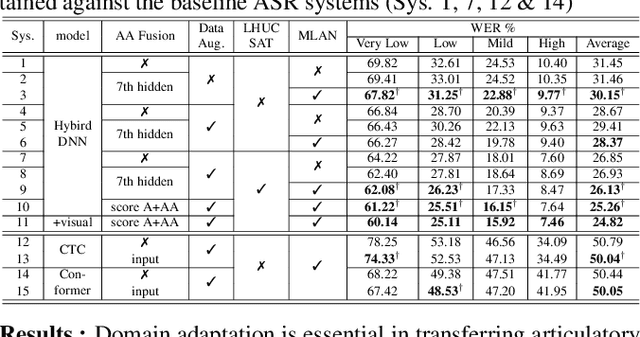
Articulatory features are inherently invariant to acoustic signal distortion and have been successfully incorporated into automatic speech recognition (ASR) systems for normal speech. Their practical application to disordered speech recognition is often limited by the difficulty in collecting such specialist data from impaired speakers. This paper presents a cross-domain acoustic-to-articulatory (A2A) inversion approach that utilizes the parallel acoustic-articulatory data of the 15-hour TORGO corpus in model training before being cross-domain adapted to the 102.7-hour UASpeech corpus and to produce articulatory features. Mixture density networks based neural A2A inversion models were used. A cross-domain feature adaptation network was also used to reduce the acoustic mismatch between the TORGO and UASpeech data. On both tasks, incorporating the A2A generated articulatory features consistently outperformed the baseline hybrid DNN/TDNN, CTC and Conformer based end-to-end systems constructed using acoustic features only. The best multi-modal system incorporating video modality and the cross-domain articulatory features as well as data augmentation and learning hidden unit contributions (LHUC) speaker adaptation produced the lowest published word error rate (WER) of 24.82% on the 16 dysarthric speakers of the benchmark UASpeech task.
Recent Progress in the CUHK Dysarthric Speech Recognition System
Jan 15, 2022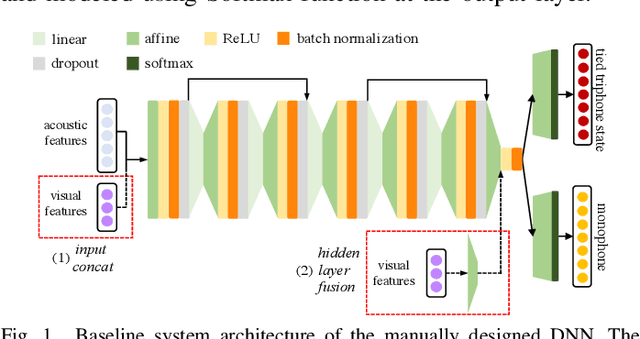
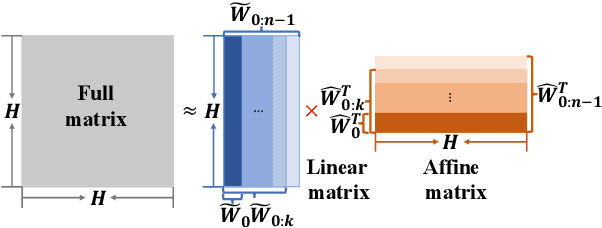
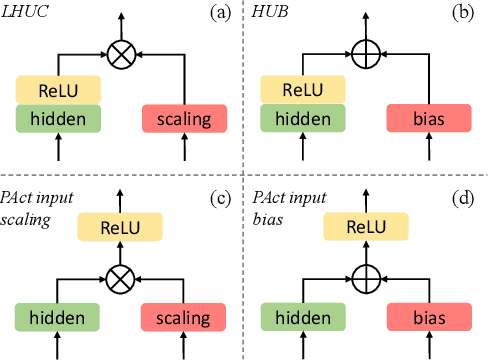
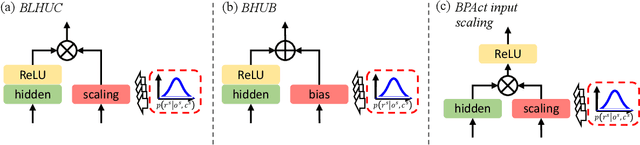
Despite the rapid progress of automatic speech recognition (ASR) technologies in the past few decades, recognition of disordered speech remains a highly challenging task to date. Disordered speech presents a wide spectrum of challenges to current data intensive deep neural networks (DNNs) based ASR technologies that predominantly target normal speech. This paper presents recent research efforts at the Chinese University of Hong Kong (CUHK) to improve the performance of disordered speech recognition systems on the largest publicly available UASpeech dysarthric speech corpus. A set of novel modelling techniques including neural architectural search, data augmentation using spectra-temporal perturbation, model based speaker adaptation and cross-domain generation of visual features within an audio-visual speech recognition (AVSR) system framework were employed to address the above challenges. The combination of these techniques produced the lowest published word error rate (WER) of 25.21% on the UASpeech test set 16 dysarthric speakers, and an overall WER reduction of 5.4% absolute (17.6% relative) over the CUHK 2018 dysarthric speech recognition system featuring a 6-way DNN system combination and cross adaptation of out-of-domain normal speech data trained systems. Bayesian model adaptation further allows rapid adaptation to individual dysarthric speakers to be performed using as little as 3.06 seconds of speech. The efficacy of these techniques were further demonstrated on a CUDYS Cantonese dysarthric speech recognition task.
Investigation of Data Augmentation Techniques for Disordered Speech Recognition
Jan 14, 2022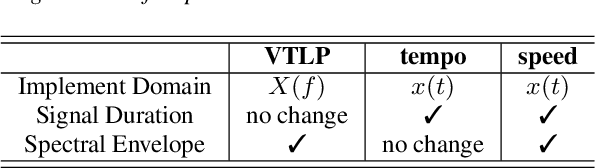
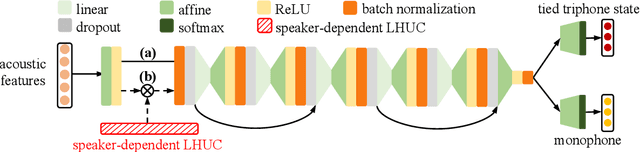
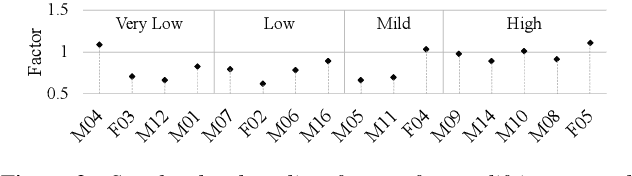
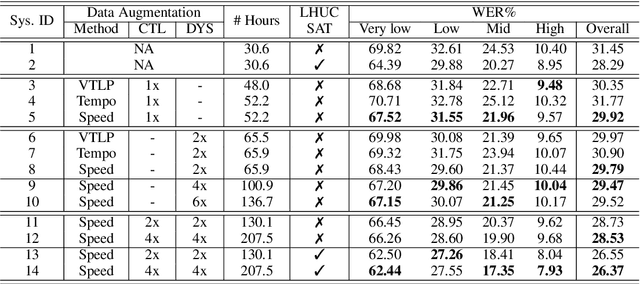
Disordered speech recognition is a highly challenging task. The underlying neuro-motor conditions of people with speech disorders, often compounded with co-occurring physical disabilities, lead to the difficulty in collecting large quantities of speech required for system development. This paper investigates a set of data augmentation techniques for disordered speech recognition, including vocal tract length perturbation (VTLP), tempo perturbation and speed perturbation. Both normal and disordered speech were exploited in the augmentation process. Variability among impaired speakers in both the original and augmented data was modeled using learning hidden unit contributions (LHUC) based speaker adaptive training. The final speaker adapted system constructed using the UASpeech corpus and the best augmentation approach based on speed perturbation produced up to 2.92% absolute (9.3% relative) word error rate (WER) reduction over the baseline system without data augmentation, and gave an overall WER of 26.37% on the test set containing 16 dysarthric speakers.
Spectro-Temporal Deep Features for Disordered Speech Assessment and Recognition
Jan 14, 2022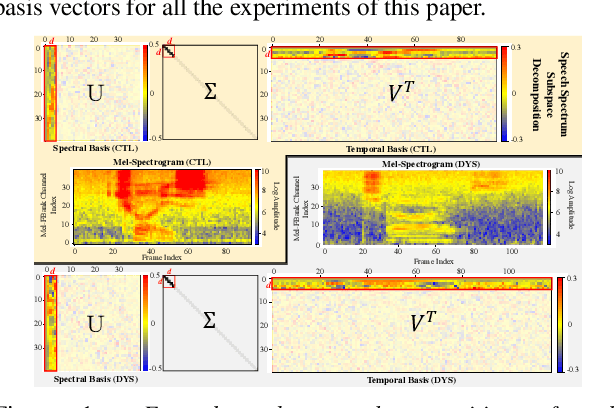
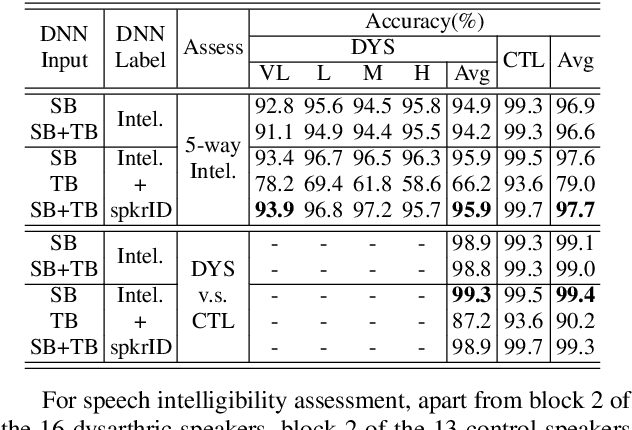
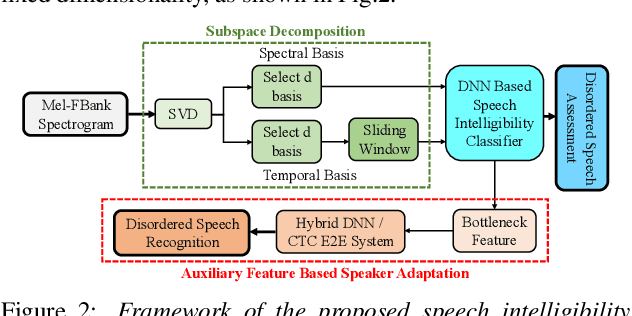
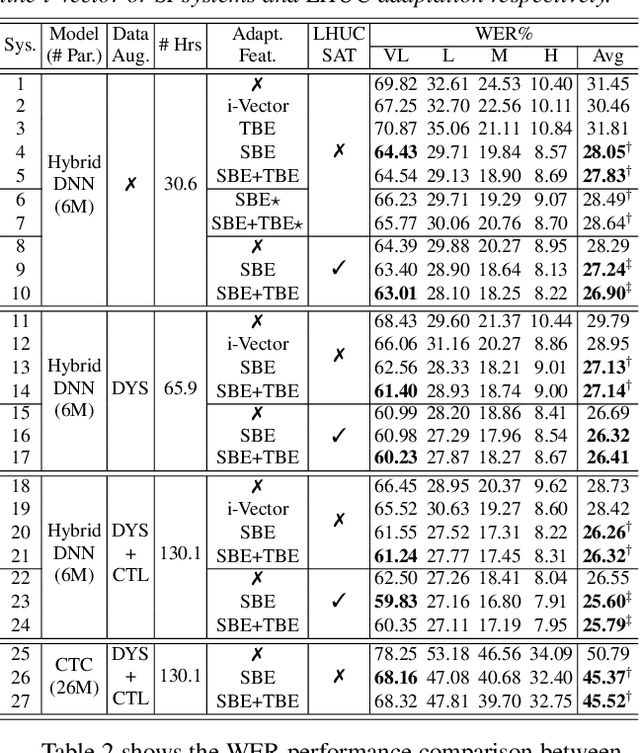
Automatic recognition of disordered speech remains a highly challenging task to date. Sources of variability commonly found in normal speech including accent, age or gender, when further compounded with the underlying causes of speech impairment and varying severity levels, create large diversity among speakers. To this end, speaker adaptation techniques play a vital role in current speech recognition systems. Motivated by the spectro-temporal level differences between disordered and normal speech that systematically manifest in articulatory imprecision, decreased volume and clarity, slower speaking rates and increased dysfluencies, novel spectro-temporal subspace basis embedding deep features derived by SVD decomposition of speech spectrum are proposed to facilitate both accurate speech intelligibility assessment and auxiliary feature based speaker adaptation of state-of-the-art hybrid DNN and end-to-end disordered speech recognition systems. Experiments conducted on the UASpeech corpus suggest the proposed spectro-temporal deep feature adapted systems consistently outperformed baseline i-Vector adaptation by up to 2.63% absolute (8.6% relative) reduction in word error rate (WER) with or without data augmentation. Learning hidden unit contribution (LHUC) based speaker adaptation was further applied. The final speaker adapted system using the proposed spectral basis embedding features gave an overall WER of 25.6% on the UASpeech test set of 16 dysarthric speakers
Neural Architecture Search For LF-MMI Trained Time Delay Neural Networks
Jan 12, 2022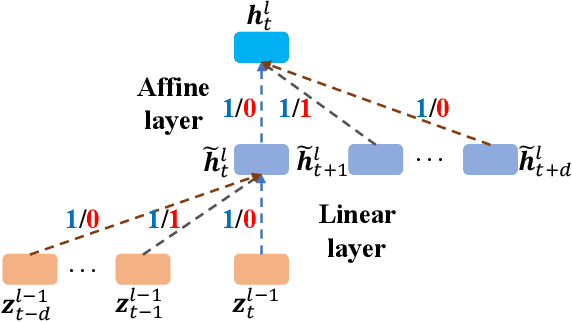
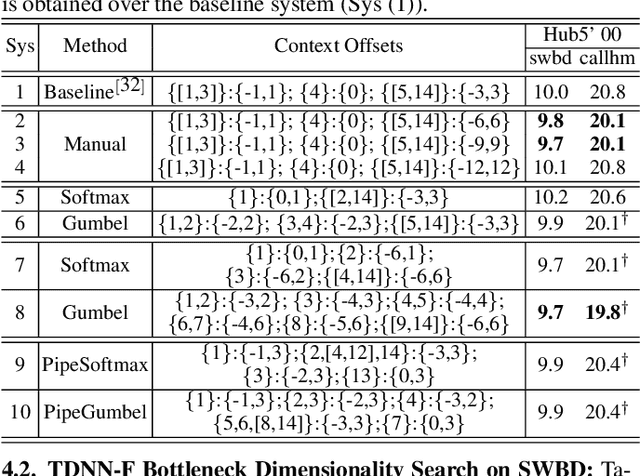
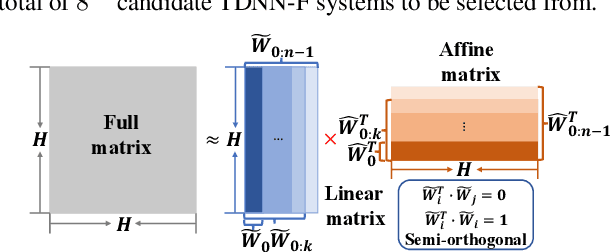
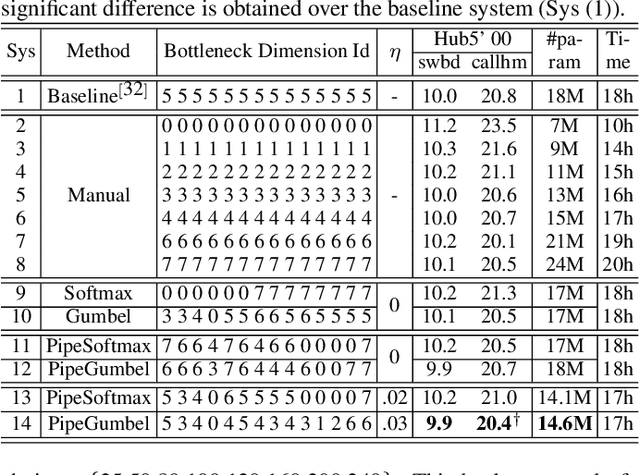
State-of-the-art automatic speech recognition (ASR) system development is data and computation intensive. The optimal design of deep neural networks (DNNs) for these systems often require expert knowledge and empirical evaluation. In this paper, a range of neural architecture search (NAS) techniques are used to automatically learn two types of hyper-parameters of factored time delay neural networks (TDNN-Fs): i) the left and right splicing context offsets; and ii) the dimensionality of the bottleneck linear projection at each hidden layer. These techniques include the differentiable neural architecture search (DARTS) method integrating architecture learning with lattice-free MMI training; Gumbel-Softmax and pipelined DARTS methods reducing the confusion over candidate architectures and improving the generalization of architecture selection; and Penalized DARTS incorporating resource constraints to balance the trade-off between performance and system complexity. Parameter sharing among TDNN-F architectures allows an efficient search over up to 7^28 different systems. Statistically significant word error rate (WER) reductions of up to 1.2% absolute and relative model size reduction of 31% were obtained over a state-of-the-art 300-hour Switchboard corpus trained baseline LF-MMI TDNN-F system featuring speed perturbation, i-Vector and learning hidden unit contribution (LHUC) based speaker adaptation as well as RNNLM rescoring. Performance contrasts on the same task against recent end-to-end systems reported in the literature suggest the best NAS auto-configured system achieves state-of-the-art WERs of 9.9% and 11.1% on the NIST Hub5' 00 and Rt03s test sets respectively with up to 96% model size reduction. Further analysis using Bayesian learning shows that ...
Mixed Precision Low-bit Quantization of Neural Network Language Models for Speech Recognition
Nov 29, 2021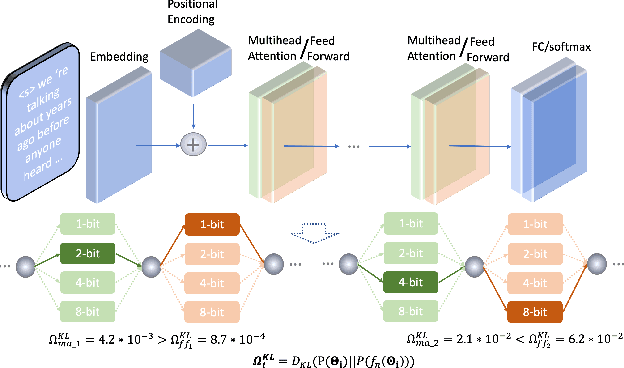
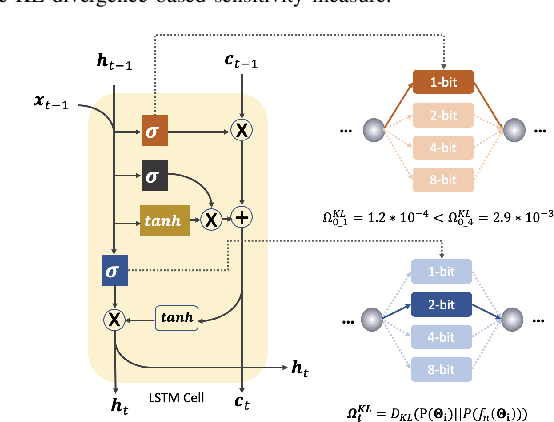
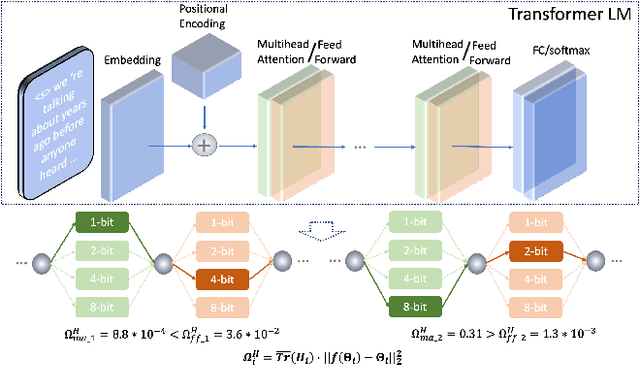
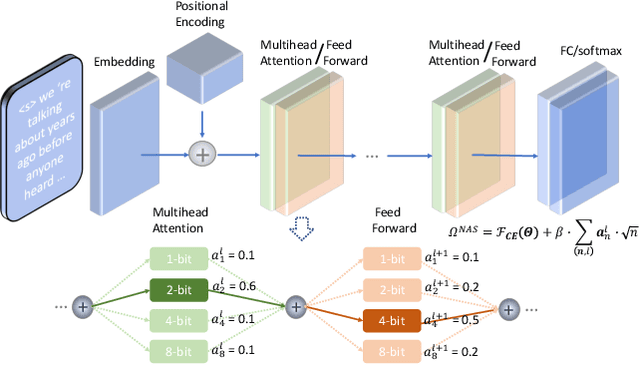
State-of-the-art language models (LMs) represented by long-short term memory recurrent neural networks (LSTM-RNNs) and Transformers are becoming increasingly complex and expensive for practical applications. Low-bit neural network quantization provides a powerful solution to dramatically reduce their model size. Current quantization methods are based on uniform precision and fail to account for the varying performance sensitivity at different parts of LMs to quantization errors. To this end, novel mixed precision neural network LM quantization methods are proposed in this paper. The optimal local precision choices for LSTM-RNN and Transformer based neural LMs are automatically learned using three techniques. The first two approaches are based on quantization sensitivity metrics in the form of either the KL-divergence measured between full precision and quantized LMs, or Hessian trace weighted quantization perturbation that can be approximated efficiently using matrix free techniques. The third approach is based on mixed precision neural architecture search. In order to overcome the difficulty in using gradient descent methods to directly estimate discrete quantized weights, alternating direction methods of multipliers (ADMM) are used to efficiently train quantized LMs. Experiments were conducted on state-of-the-art LF-MMI CNN-TDNN systems featuring speed perturbation, i-Vector and learning hidden unit contribution (LHUC) based speaker adaptation on two tasks: Switchboard telephone speech and AMI meeting transcription. The proposed mixed precision quantization techniques achieved "lossless" quantization on both tasks, by producing model size compression ratios of up to approximately 16 times over the full precision LSTM and Transformer baseline LMs, while incurring no statistically significant word error rate increase.
Mixed Precision of Quantization of Transformer Language Models for Speech Recognition
Nov 29, 2021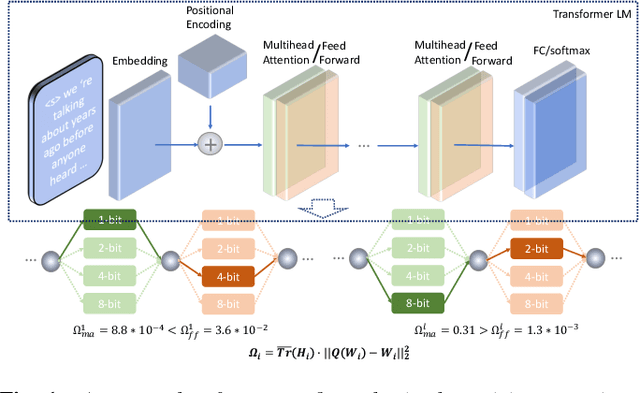
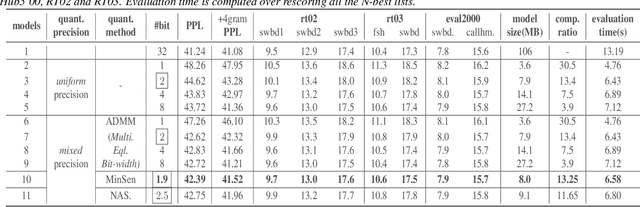
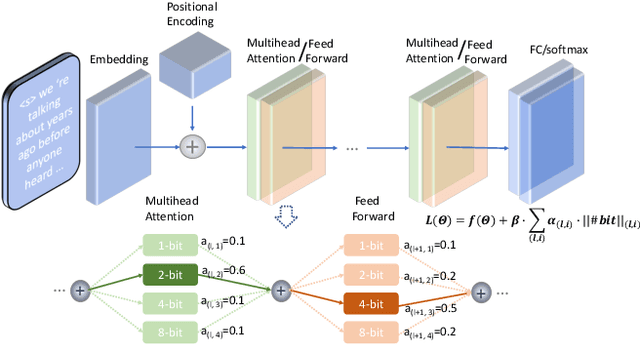
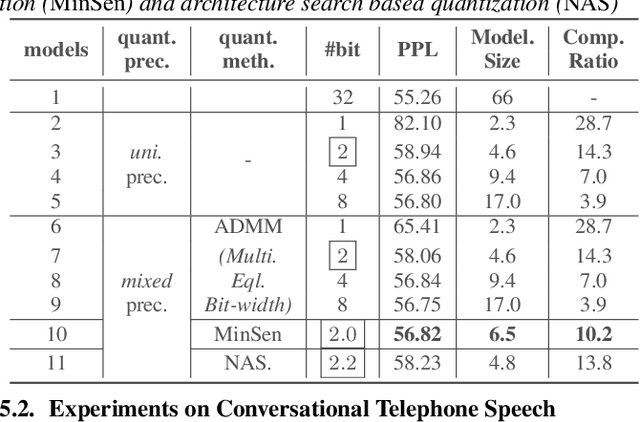
State-of-the-art neural language models represented by Transformers are becoming increasingly complex and expensive for practical applications. Low-bit deep neural network quantization techniques provides a powerful solution to dramatically reduce their model size. Current low-bit quantization methods are based on uniform precision and fail to account for the varying performance sensitivity at different parts of the system to quantization errors. To this end, novel mixed precision DNN quantization methods are proposed in this paper. The optimal local precision settings are automatically learned using two techniques. The first is based on a quantization sensitivity metric in the form of Hessian trace weighted quantization perturbation. The second is based on mixed precision Transformer architecture search. Alternating direction methods of multipliers (ADMM) are used to efficiently train mixed precision quantized DNN systems. Experiments conducted on Penn Treebank (PTB) and a Switchboard corpus trained LF-MMI TDNN system suggest the proposed mixed precision Transformer quantization techniques achieved model size compression ratios of up to 16 times over the full precision baseline with no recognition performance degradation. When being used to compress a larger full precision Transformer LM with more layers, overall word error rate (WER) reductions up to 1.7% absolute (18% relative) were obtained.
Low-bit Quantization of Recurrent Neural Network Language Models Using Alternating Direction Methods of Multipliers
Nov 29, 2021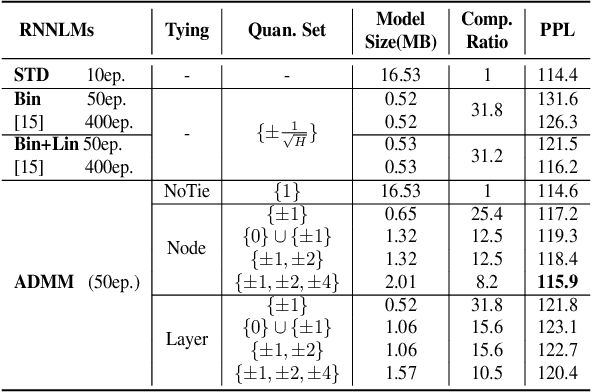
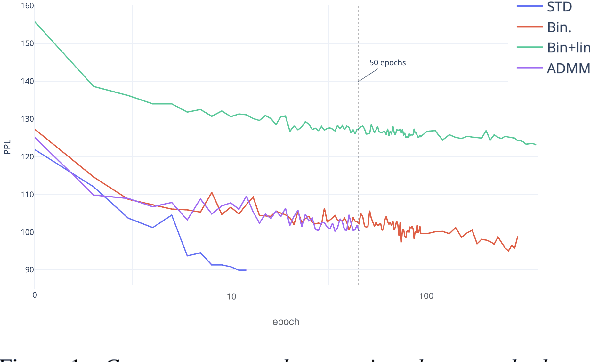
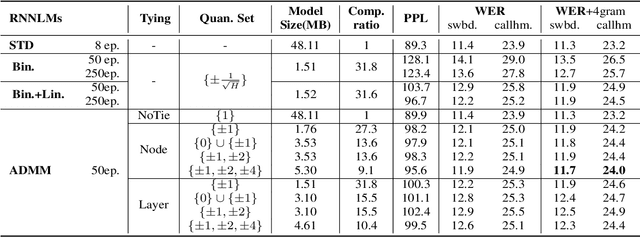
The high memory consumption and computational costs of Recurrent neural network language models (RNNLMs) limit their wider application on resource constrained devices. In recent years, neural network quantization techniques that are capable of producing extremely low-bit compression, for example, binarized RNNLMs, are gaining increasing research interests. Directly training of quantized neural networks is difficult. By formulating quantized RNNLMs training as an optimization problem, this paper presents a novel method to train quantized RNNLMs from scratch using alternating direction methods of multipliers (ADMM). This method can also flexibly adjust the trade-off between the compression rate and model performance using tied low-bit quantization tables. Experiments on two tasks: Penn Treebank (PTB), and Switchboard (SWBD) suggest the proposed ADMM quantization achieved a model size compression factor of up to 31 times over the full precision baseline RNNLMs. Faster convergence of 5 times in model training over the baseline binarized RNNLM quantization was also obtained. Index Terms: Language models, Recurrent neural networks, Quantization, Alternating direction methods of multipliers.
DHA: End-to-End Joint Optimization of Data Augmentation Policy, Hyper-parameter and Architecture
Sep 13, 2021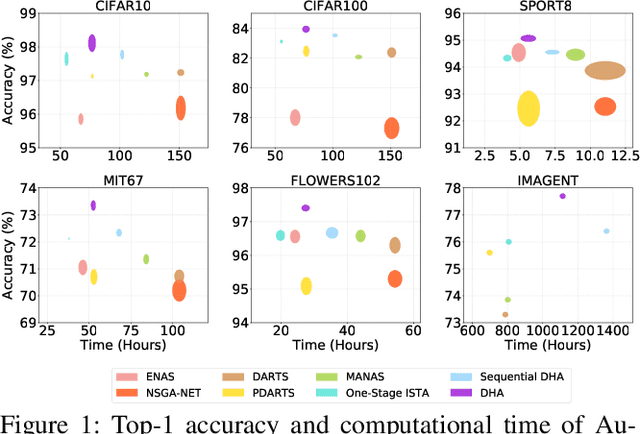

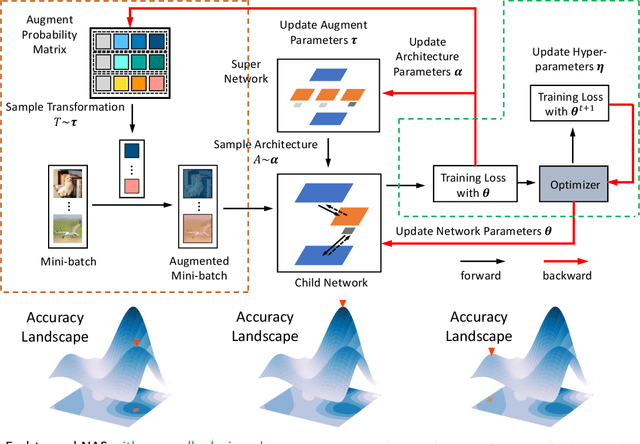
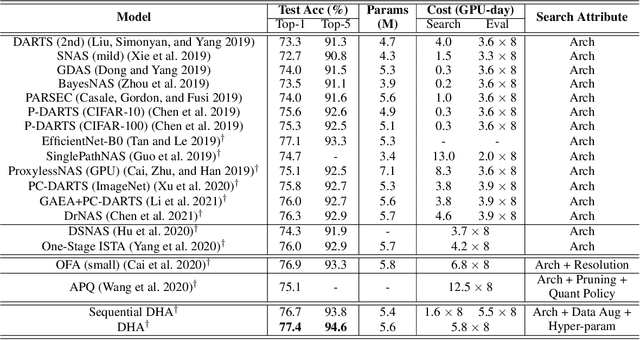
Automated machine learning (AutoML) usually involves several crucial components, such as Data Augmentation (DA) policy, Hyper-Parameter Optimization (HPO), and Neural Architecture Search (NAS). Although many strategies have been developed for automating these components in separation, joint optimization of these components remains challenging due to the largely increased search dimension and the variant input types of each component. Meanwhile, conducting these components in a sequence often requires careful coordination by human experts and may lead to sub-optimal results. In parallel to this, the common practice of searching for the optimal architecture first and then retraining it before deployment in NAS often suffers from low performance correlation between the search and retraining stages. An end-to-end solution that integrates the AutoML components and returns a ready-to-use model at the end of the search is desirable. In view of these, we propose DHA, which achieves joint optimization of Data augmentation policy, Hyper-parameter and Architecture. Specifically, end-to-end NAS is achieved in a differentiable manner by optimizing a compressed lower-dimensional feature space, while DA policy and HPO are updated dynamically at the same time. Experiments show that DHA achieves state-of-the-art (SOTA) results on various datasets, especially 77.4\% accuracy on ImageNet with cell based search space, which is higher than current SOTA by 0.5\%. To the best of our knowledge, we are the first to efficiently and jointly optimize DA policy, NAS, and HPO in an end-to-end manner without retraining.