 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParticle clustering in turbulence: Prediction of spatial and statistical properties with deep learning
Oct 05, 2022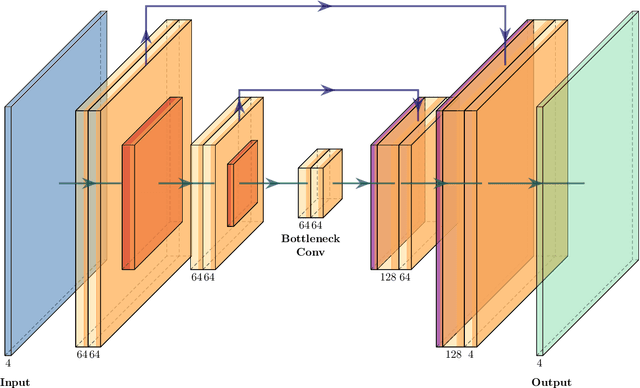
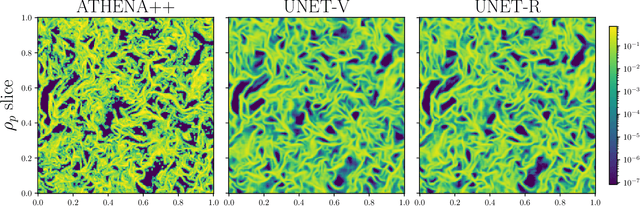
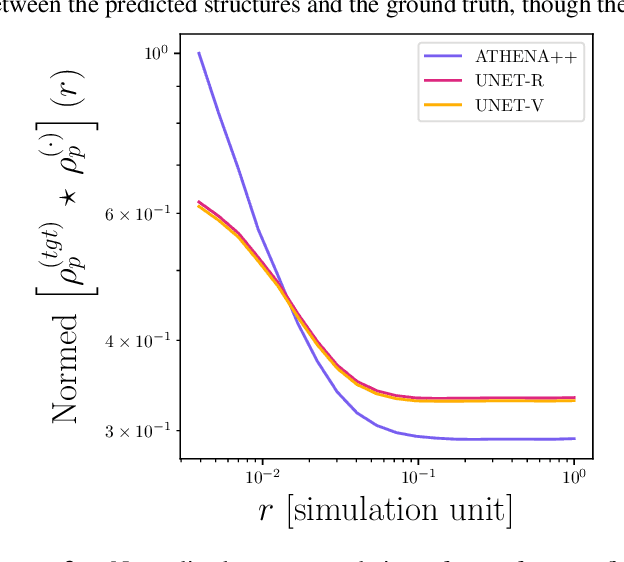
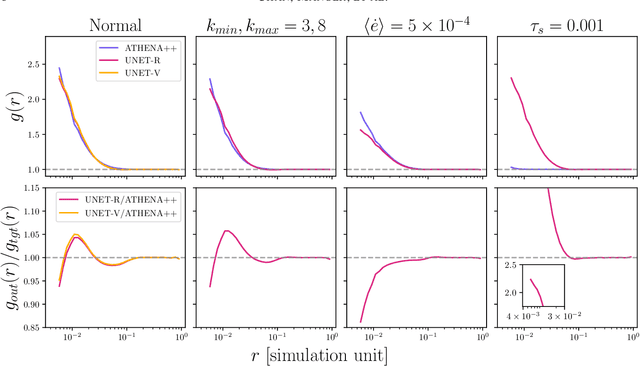
We demonstrate the utility of deep learning for modeling the clustering of particles that are aerodynamically coupled to turbulent fluids. Using a Lagrangian particle module within the ATHENA++ hydrodynamics code, we simulate the dynamics of particles in the Epstein drag regime within a periodic domain of isotropic forced hydrodynamic turbulence. This setup is an idealized model relevant to the collisional growth of micron to mmsized dust particles in early stage planet formation. The simulation data is used to train a U-Net deep learning model to predict gridded three-dimensional representations of the particle density and velocity fields, given as input the corresponding fluid fields. The trained model qualitatively captures the filamentary structure of clustered particles in a highly non-linear regime. We assess model fidelity by calculating metrics of the density structure (the radial distribution function) and of the velocity field (the relative velocity and the relative radial velocity between particles). Although trained only on the spatial fields, the model predicts these statistical quantities with errors that are typically < 10%. Our results suggest that, given appropriately expanded training data, deep learning could be used to accelerate calculations of particle clustering and collision outcomes both in protoplanetary disks, and in related two-fluid turbulence problems that arise in other disciplines.
The SZ flux-mass relation at low halo masses: improvements with symbolic regression and strong constraints on baryonic feedback
Sep 05, 2022
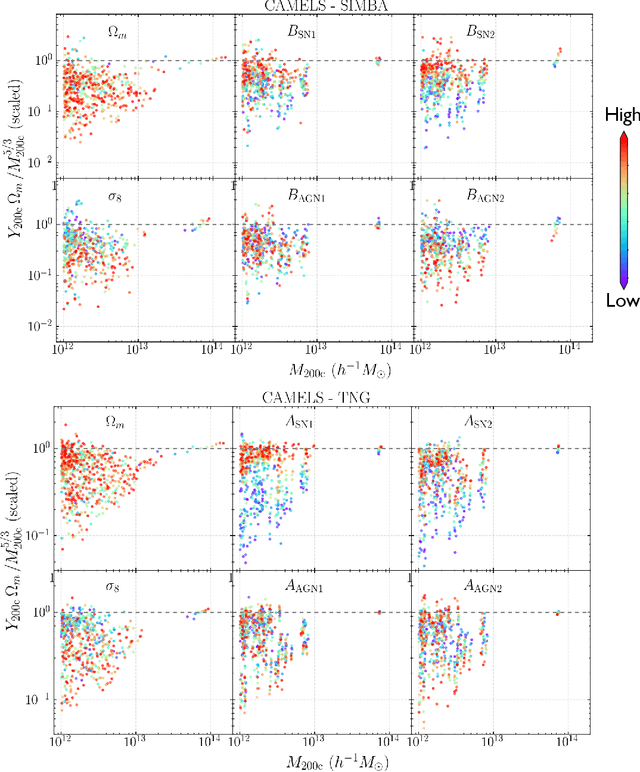
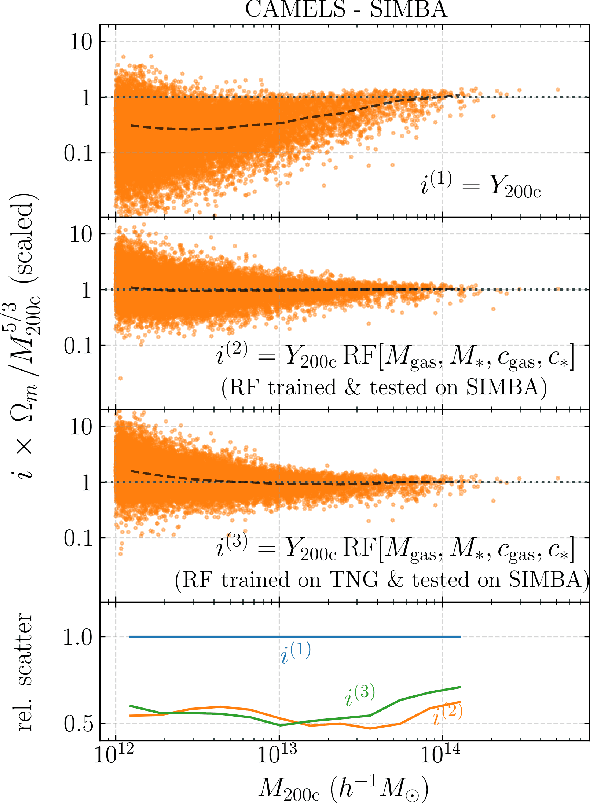

Ionized gas in the halo circumgalactic medium leaves an imprint on the cosmic microwave background via the thermal Sunyaev-Zeldovich (tSZ) effect. Feedback from active galactic nuclei (AGN) and supernovae can affect the measurements of the integrated tSZ flux of halos ($Y_\mathrm{SZ}$) and cause its relation with the halo mass ($Y_\mathrm{SZ}-M$) to deviate from the self-similar power-law prediction of the virial theorem. We perform a comprehensive study of such deviations using CAMELS, a suite of hydrodynamic simulations with extensive variations in feedback prescriptions. We use a combination of two machine learning tools (random forest and symbolic regression) to search for analogues of the $Y-M$ relation which are more robust to feedback processes for low masses ($M\lesssim 10^{14}\, h^{-1} \, M_\odot$); we find that simply replacing $Y\rightarrow Y(1+M_*/M_\mathrm{gas})$ in the relation makes it remarkably self-similar. This could serve as a robust multiwavelength mass proxy for low-mass clusters and galaxy groups. Our methodology can also be generally useful to improve the domain of validity of other astrophysical scaling relations. We also forecast that measurements of the $Y-M$ relation could provide percent-level constraints on certain combinations of feedback parameters and/or rule out a major part of the parameter space of supernova and AGN feedback models used in current state-of-the-art hydrodynamic simulations. Our results can be useful for using upcoming SZ surveys (e.g. SO, CMB-S4) and galaxy surveys (e.g. DESI and Rubin) to constrain the nature of baryonic feedback. Finally, we find that the an alternative relation, $Y-M_*$, provides complementary information on feedback than $Y-M$.
Robust Simulation-Based Inference in Cosmology with Bayesian Neural Networks
Jul 20, 2022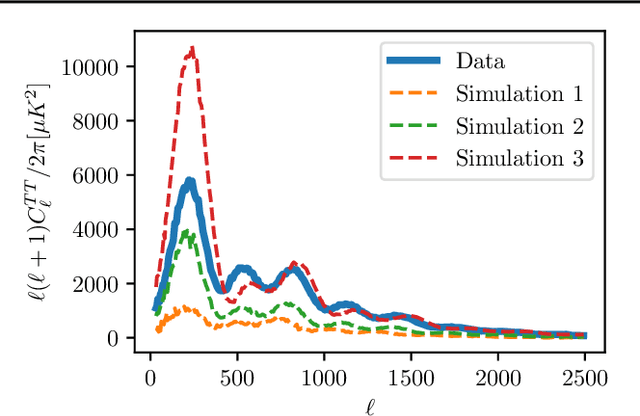
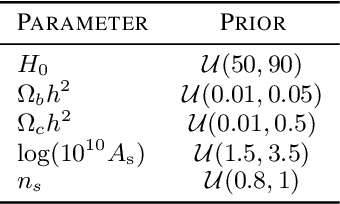
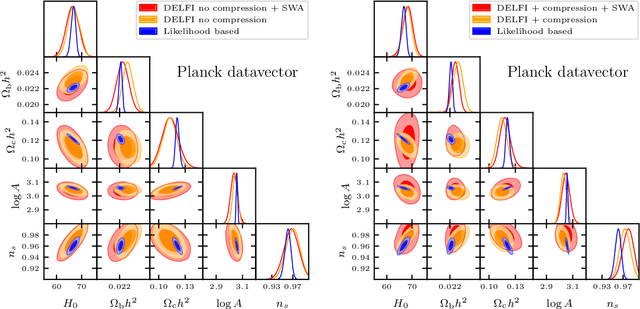
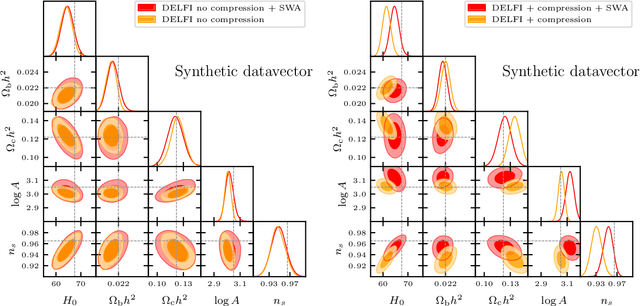
Simulation-based inference (SBI) is rapidly establishing itself as a standard machine learning technique for analyzing data in cosmological surveys. Despite continual improvements to the quality of density estimation by learned models, applications of such techniques to real data are entirely reliant on the generalization power of neural networks far outside the training distribution, which is mostly unconstrained. Due to the imperfections in scientist-created simulations, and the large computational expense of generating all possible parameter combinations, SBI methods in cosmology are vulnerable to such generalization issues. Here, we discuss the effects of both issues, and show how using a Bayesian neural network framework for training SBI can mitigate biases, and result in more reliable inference outside the training set. We introduce cosmoSWAG, the first application of Stochastic Weight Averaging to cosmology, and apply it to SBI trained for inference on the cosmic microwave background.
Simple lessons from complex learning: what a neural network model learns about cosmic structure formation
Jun 14, 2022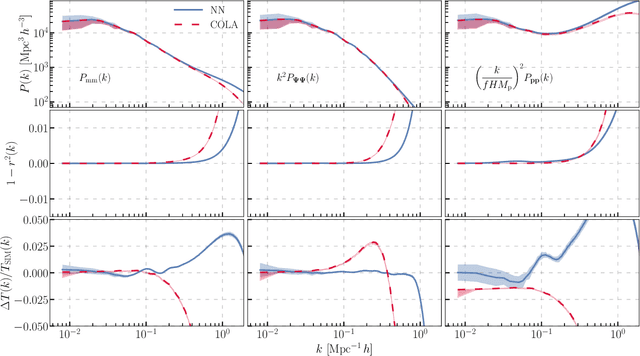
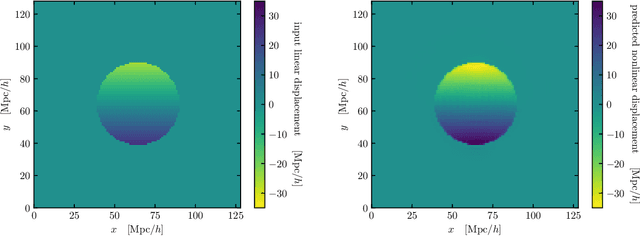
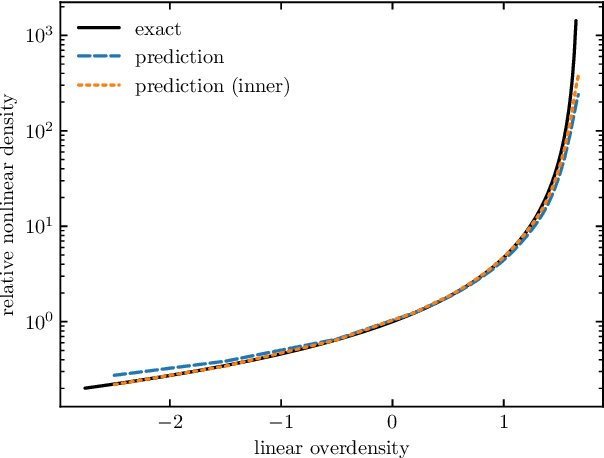
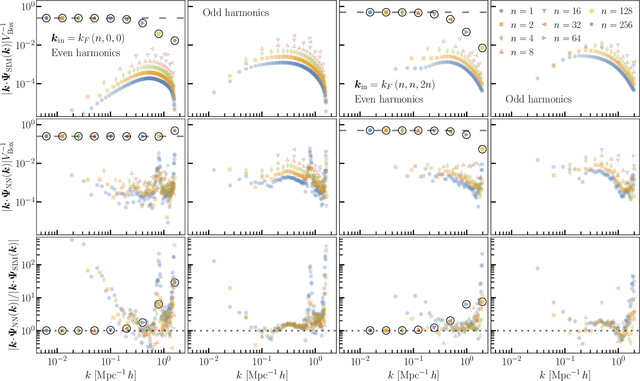
We train a neural network model to predict the full phase space evolution of cosmological N-body simulations. Its success implies that the neural network model is accurately approximating the Green's function expansion that relates the initial conditions of the simulations to its outcome at later times in the deeply nonlinear regime. We test the accuracy of this approximation by assessing its performance on well understood simple cases that have either known exact solutions or well understood expansions. These scenarios include spherical configurations, isolated plane waves, and two interacting plane waves: initial conditions that are very different from the Gaussian random fields used for training. We find our model generalizes well to these well understood scenarios, demonstrating that the networks have inferred general physical principles and learned the nonlinear mode couplings from the complex, random Gaussian training data. These tests also provide a useful diagnostic for finding the model's strengths and weaknesses, and identifying strategies for model improvement. We also test the model on initial conditions that contain only transverse modes, a family of modes that differ not only in their phases but also in their evolution from the longitudinal growing modes used in the training set. When the network encounters these initial conditions that are orthogonal to the training set, the model fails completely. In addition to these simple configurations, we evaluate the model's predictions for the density, displacement, and momentum power spectra with standard initial conditions for N-body simulations. We compare these summary statistics against N-body results and an approximate, fast simulation method called COLA. Our model achieves percent level accuracy at nonlinear scales of $k\sim 1\ \mathrm{Mpc}^{-1}\, h$, representing a significant improvement over COLA.
Field Level Neural Network Emulator for Cosmological N-body Simulations
Jun 14, 2022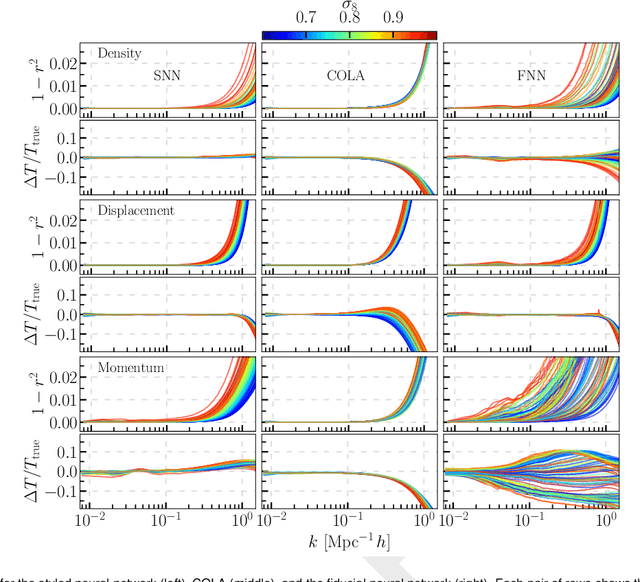
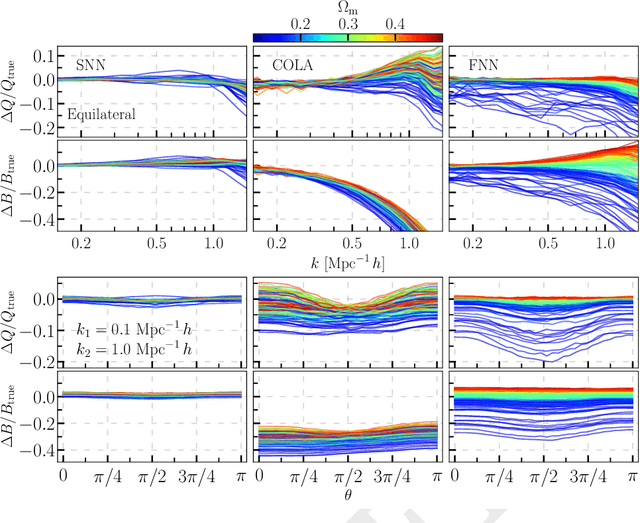
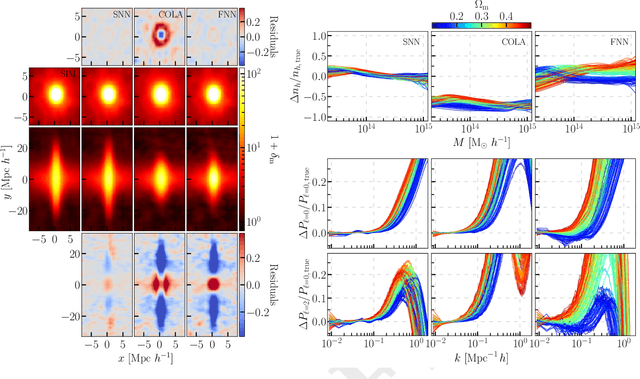
We build a field level emulator for cosmic structure formation that is accurate in the nonlinear regime. Our emulator consists of two convolutional neural networks trained to output the nonlinear displacements and velocities of N-body simulation particles based on their linear inputs. Cosmology dependence is encoded in the form of style parameters at each layer of the neural network, enabling the emulator to effectively interpolate the outcomes of structure formation between different flat $\Lambda$CDM cosmologies over a wide range of background matter densities. The neural network architecture makes the model differentiable by construction, providing a powerful tool for fast field level inference. We test the accuracy of our method by considering several summary statistics, including the density power spectrum with and without redshift space distortions, the displacement power spectrum, the momentum power spectrum, the density bispectrum, halo abundances, and halo profiles with and without redshift space distortions. We compare these statistics from our emulator with the full N-body results, the COLA method, and a fiducial neural network with no cosmological dependence. We find our emulator gives accurate results down to scales of $k \sim 1\ \mathrm{Mpc}^{-1}\, h$, representing a considerable improvement over both COLA and the fiducial neural network. We also demonstrate that our emulator generalizes well to initial conditions containing primordial non-Gaussianity, without the need for any additional style parameters or retraining.
Predicting the Thermal Sunyaev-Zel'dovich Field using Modular and Equivariant Set-Based Neural Networks
Feb 28, 2022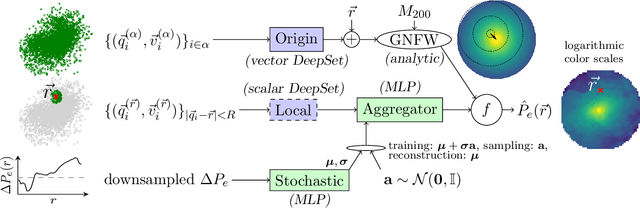
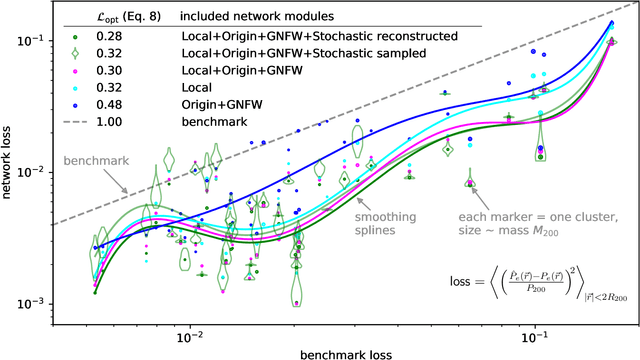
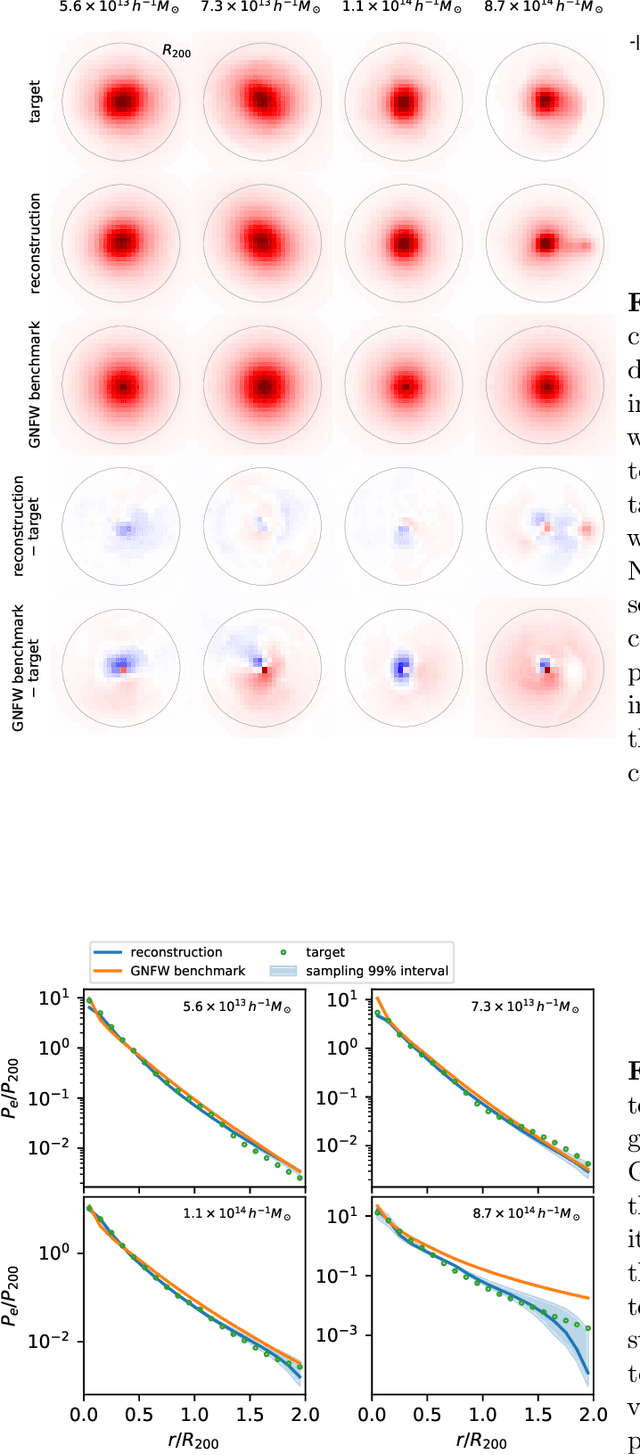
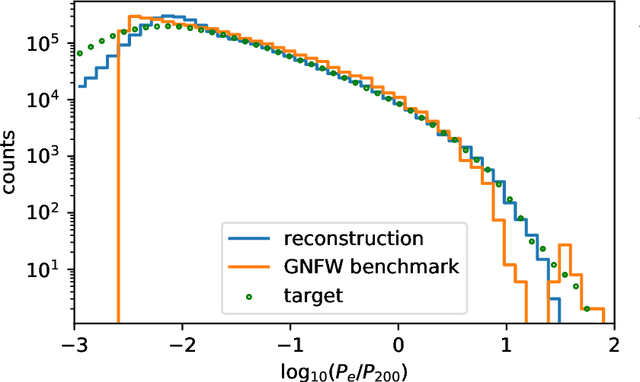
Theoretical uncertainty limits our ability to extract cosmological information from baryonic fields such as the thermal Sunyaev-Zel'dovich (tSZ) effect. Being sourced by the electron pressure field, the tSZ effect depends on baryonic physics that is usually modeled by expensive hydrodynamic simulations. We train neural networks on the IllustrisTNG-300 cosmological simulation to predict the continuous electron pressure field in galaxy clusters from gravity-only simulations. Modeling clusters is challenging for neural networks as most of the gas pressure is concentrated in a handful of voxels and even the largest hydrodynamical simulations contain only a few hundred clusters that can be used for training. Instead of conventional convolutional neural net (CNN) architectures, we choose to employ a rotationally equivariant DeepSets architecture to operate directly on the set of dark matter particles. We argue that set-based architectures provide distinct advantages over CNNs. For example, we can enforce exact rotational and permutation equivariance, incorporate existing knowledge on the tSZ field, and work with sparse fields as are standard in cosmology. We compose our architecture with separate, physically meaningful modules, making it amenable to interpretation. For example, we can separately study the influence of local and cluster-scale environment, determine that cluster triaxiality has negligible impact, and train a module that corrects for mis-centering. Our model improves by 70 % on analytic profiles fit to the same simulation data. We argue that the electron pressure field, viewed as a function of a gravity-only simulation, has inherent stochasticity, and model this property through a conditional-VAE extension to the network. This modification yields further improvement by 7 %, it is limited by our small training set however. (abridged)
Rediscovering orbital mechanics with machine learning
Feb 04, 2022
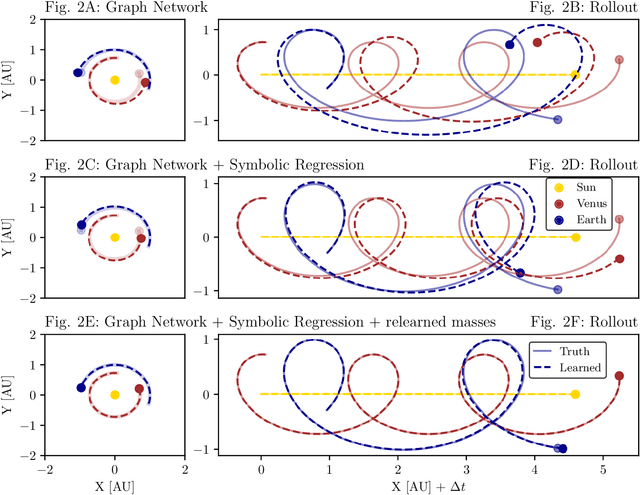
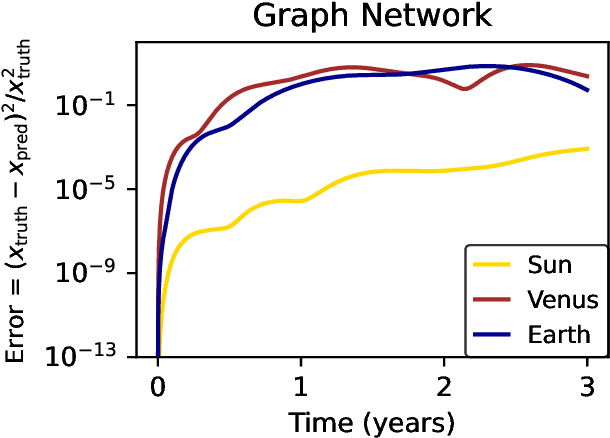
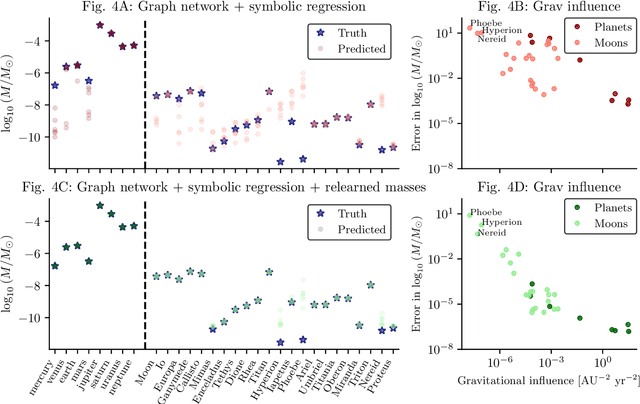
We present an approach for using machine learning to automatically discover the governing equations and hidden properties of real physical systems from observations. We train a "graph neural network" to simulate the dynamics of our solar system's Sun, planets, and large moons from 30 years of trajectory data. We then use symbolic regression to discover an analytical expression for the force law implicitly learned by the neural network, which our results showed is equivalent to Newton's law of gravitation. The key assumptions that were required were translational and rotational equivariance, and Newton's second and third laws of motion. Our approach correctly discovered the form of the symbolic force law. Furthermore, our approach did not require any assumptions about the masses of planets and moons or physical constants. They, too, were accurately inferred through our methods. Though, of course, the classical law of gravitation has been known since Isaac Newton, our result serves as a validation that our method can discover unknown laws and hidden properties from observed data. More broadly this work represents a key step toward realizing the potential of machine learning for accelerating scientific discovery.
Augmenting astrophysical scaling relations with machine learning : application to reducing the SZ flux-mass scatter
Jan 17, 2022
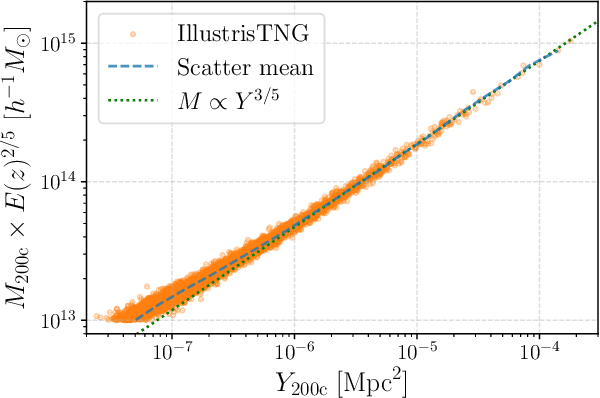
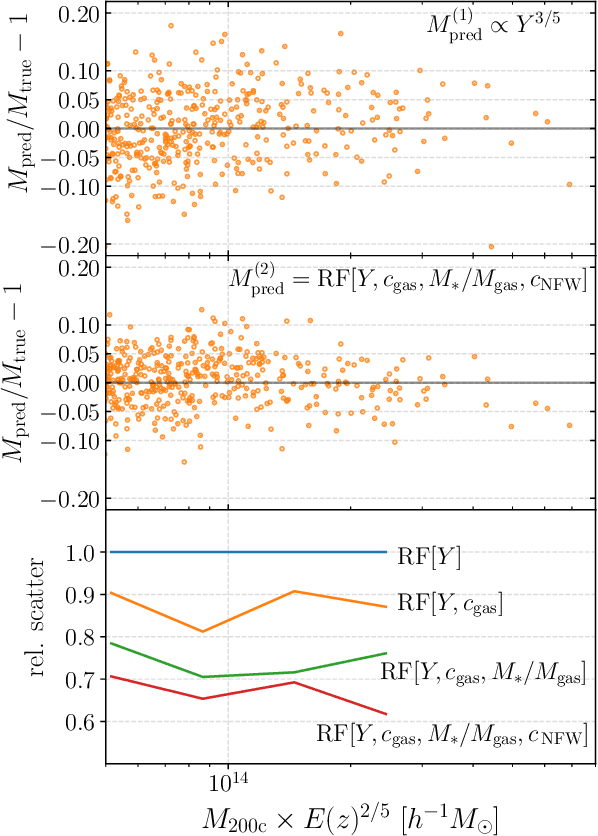
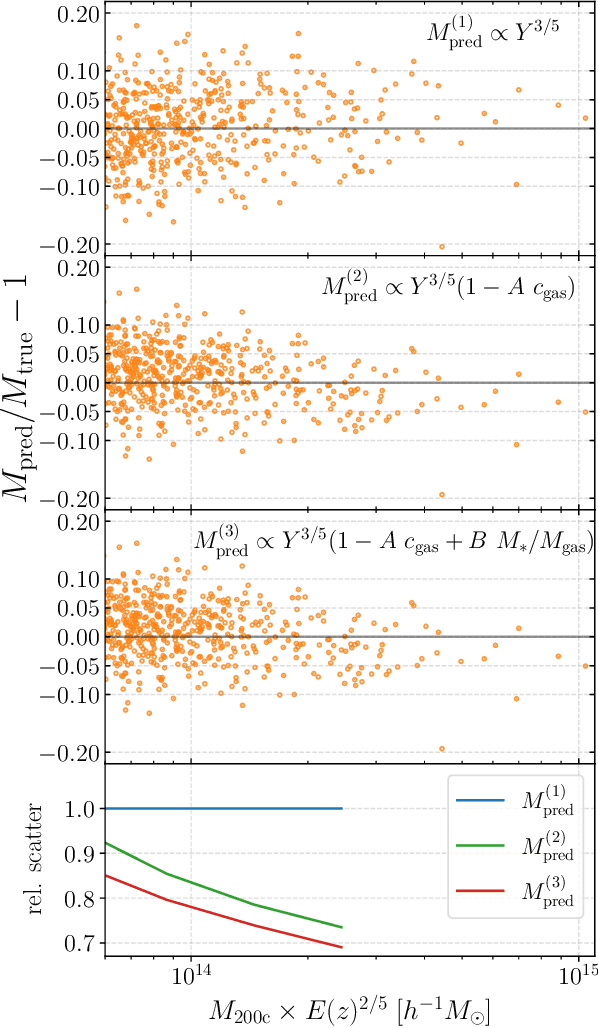
Complex systems (stars, supernovae, galaxies, and clusters) often exhibit low scatter relations between observable properties (e.g., luminosity, velocity dispersion, oscillation period, temperature). These scaling relations can illuminate the underlying physics and can provide observational tools for estimating masses and distances. Machine learning can provide a systematic way to search for new scaling relations (or for simple extensions to existing relations) in abstract high-dimensional parameter spaces. We use a machine learning tool called symbolic regression (SR), which models the patterns in a given dataset in the form of analytic equations. We focus on the Sunyaev-Zeldovich flux$-$cluster mass relation ($Y_\mathrm{SZ}-M$), the scatter in which affects inference of cosmological parameters from cluster abundance data. Using SR on the data from the IllustrisTNG hydrodynamical simulation, we find a new proxy for cluster mass which combines $Y_\mathrm{SZ}$ and concentration of ionized gas ($c_\mathrm{gas}$): $M \propto Y_\mathrm{conc}^{3/5} \equiv Y_\mathrm{SZ}^{3/5} (1-A\, c_\mathrm{gas})$. $Y_\mathrm{conc}$ reduces the scatter in the predicted $M$ by $\sim 20-30$% for large clusters ($M\gtrsim 10^{14}\, h^{-1} \, M_\odot$) at both high and low redshifts, as compared to using just $Y_\mathrm{SZ}$. We show that the dependence on $c_\mathrm{gas}$ is linked to cores of clusters exhibiting larger scatter than their outskirts. Finally, we test $Y_\mathrm{conc}$ on clusters from simulations of the CAMELS project and show that $Y_\mathrm{conc}$ is robust against variations in cosmology, astrophysics, subgrid physics, and cosmic variance. Our results and methodology can be useful for accurate multiwavelength cluster mass estimation from current and upcoming CMB and X-ray surveys like ACT, SO, SPT, eROSITA and CMB-S4.
Learned Coarse Models for Efficient Turbulence Simulation
Jan 04, 2022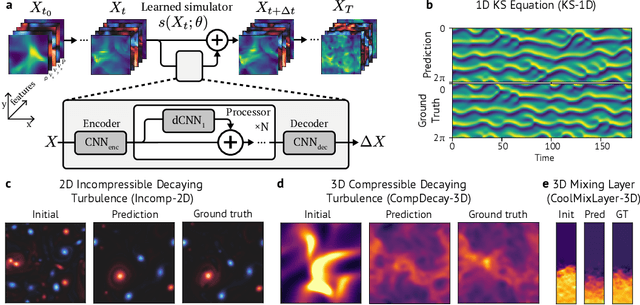
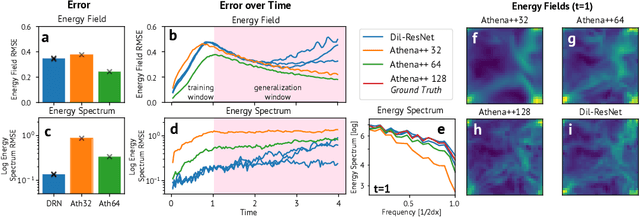
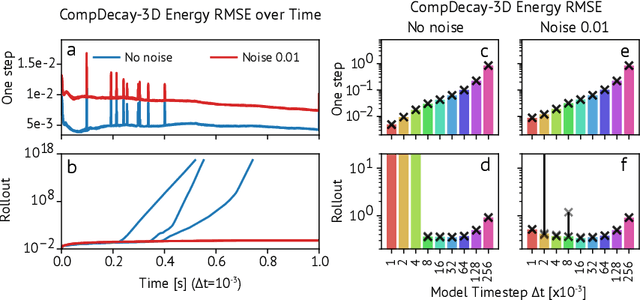

Turbulence simulation with classical numerical solvers requires very high-resolution grids to accurately resolve dynamics. Here we train learned simulators at low spatial and temporal resolutions to capture turbulent dynamics generated at high resolution. We show that our proposed model can simulate turbulent dynamics more accurately than classical numerical solvers at the same low resolutions across various scientifically relevant metrics. Our model is trained end-to-end from data and is capable of learning a range of challenging chaotic and turbulent dynamics at low resolution, including trajectories generated by the state-of-the-art Athena++ engine. We show that our simpler, general-purpose architecture outperforms various more specialized, turbulence-specific architectures from the learned turbulence simulation literature. In general, we see that learned simulators yield unstable trajectories; however, we show that tuning training noise and temporal downsampling solves this problem. We also find that while generalization beyond the training distribution is a challenge for learned models, training noise, convolutional architectures, and added loss constraints can help. Broadly, we conclude that our learned simulator outperforms traditional solvers run on coarser grids, and emphasize that simple design choices can offer stability and robust generalization.
Super-resolving Dark Matter Halos using Generative Deep Learning
Nov 11, 2021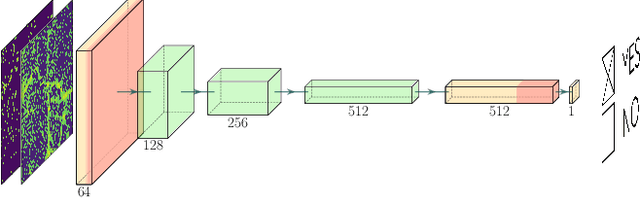
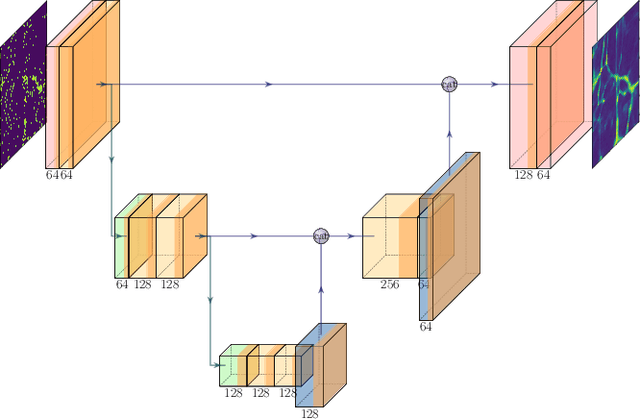
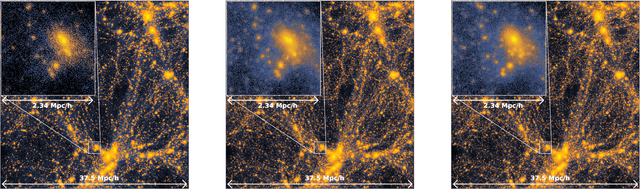
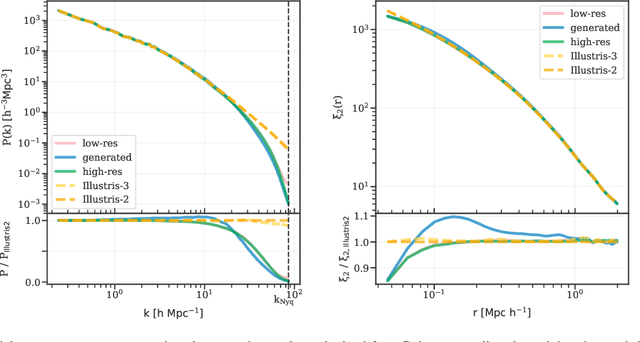
Generative deep learning methods built upon Convolutional Neural Networks (CNNs) provide a great tool for predicting non-linear structure in cosmology. In this work we predict high resolution dark matter halos from large scale, low resolution dark matter only simulations. This is achieved by mapping lower resolution to higher resolution density fields of simulations sharing the same cosmology, initial conditions and box-sizes. To resolve structure down to a factor of 8 increase in mass resolution, we use a variation of U-Net with a conditional GAN, generating output that visually and statistically matches the high resolution target extremely well. This suggests that our method can be used to create high resolution density output over Gpc/h box-sizes from low resolution simulations with negligible computational effort.