 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Interaction Summarization and Contrastive Prompting for Explainable Recommendations
Jul 08, 2025Explainable recommendations, which use the information of user and item with interaction to generate a explanation for why the user would interact with the item, are crucial for improving user trust and decision transparency to the recommender system. Existing methods primarily rely on encoding features of users and items to embeddings, which often leads to information loss due to dimensionality reduction, sparse interactions, and so on. With the advancements of large language models (LLMs) in language comprehension, some methods use embeddings as LLM inputs for explanation generation. However, since embeddings lack inherent semantics, LLMs must adjust or extend their parameters to interpret them, a process that inevitably incurs information loss. To address this issue, we propose a novel approach combining profile generation via hierarchical interaction summarization (PGHIS), which leverages a pretrained LLM to hierarchically summarize user-item interactions, generating structured textual profiles as explicit representations of user and item characteristics. Additionally, we propose contrastive prompting for explanation generation (CPEG) which employs contrastive learning to guide another reasoning language models in producing high-quality ground truth recommendation explanations. Finally, we use the textual profiles of user and item as input and high-quality explanation as output to fine-tune a LLM for generating explanations. Experimental results on multiple datasets demonstrate that our approach outperforms existing state-of-the-art methods, achieving a great improvement on metrics about explainability (e.g., 5% on GPTScore) and text quality. Furthermore, our generated ground truth explanations achieve a significantly higher win rate compared to user-written reviews and those produced by other methods, demonstrating the effectiveness of CPEG in generating high-quality ground truths.
SpectralKD: Understanding and Optimizing Vision Transformer Distillation through Spectral Analysis
Dec 26, 2024Knowledge distillation effectively reduces model complexity while improving performance, yet the underlying knowledge transfer mechanisms remain poorly understood. We propose novel spectral analysis methods and guidelines to optimize distillation, making the knowledge transfer process more interpretable. Our analysis reveals that CaiT models concentrate information in their first and last few layers, informing optimal layer selection for feature map distillation. Surprisingly, we discover that Swin Transformer and CaiT exhibit similar spectral encoding patterns despite their architectural differences, enhancing our understanding of transformer architectures and leading to improved feature map alignment strategies. Based on these insights, we introduce a simple yet effective spectral alignment method named SpectralKD. Experimental results demonstrate that following our guidelines enables SpectralKD to achieve state-of-the-art performance (DeiT-Tiny: $+5.2\%$, Swin-Tiny: $+1.4\%$ in ImageNet-1k Top-1 accuracy). Furthermore, through spectral analysis of student models trained with and without distillation, we show that distilled models mirror spectral patterns of their teachers, providing a new lens for interpreting knowledge distillation dynamics. Our code, pre-trained models, and experimental logs will be made publicly available.
Incorporating Feature Pyramid Tokenization and Open Vocabulary Semantic Segmentation
Dec 18, 2024



The visual understanding are often approached from 3 granular levels: image, patch and pixel. Visual Tokenization, trained by self-supervised reconstructive learning, compresses visual data by codebook in patch-level with marginal information loss, but the visual tokens does not have semantic meaning. Open Vocabulary semantic segmentation benefits from the evolving Vision-Language models (VLMs) with strong image zero-shot capability, but transferring image-level to pixel-level understanding remains an imminent challenge. In this paper, we treat segmentation as tokenizing pixels and study a united perceptual and semantic token compression for all granular understanding and consequently facilitate open vocabulary semantic segmentation. Referring to the cognitive process of pretrained VLM where the low-level features are progressively composed to high-level semantics, we propose Feature Pyramid Tokenization (PAT) to cluster and represent multi-resolution feature by learnable codebooks and then decode them by joint learning pixel reconstruction and semantic segmentation. We design loosely coupled pixel and semantic learning branches. The pixel branch simulates bottom-up composition and top-down visualization of codebook tokens, while the semantic branch collectively fuse hierarchical codebooks as auxiliary segmentation guidance. Our experiments show that PAT enhances the semantic intuition of VLM feature pyramid, improves performance over the baseline segmentation model and achieves competitive performance on open vocabulary semantic segmentation benchmark. Our model is parameter-efficient for VLM integration and flexible for the independent tokenization. We hope to give inspiration not only on improving segmentation but also on semantic visual token utilization.
CBraMod: A Criss-Cross Brain Foundation Model for EEG Decoding
Dec 10, 2024



Electroencephalography (EEG) is a non-invasive technique to measure and record brain electrical activity, widely used in various BCI and healthcare applications. Early EEG decoding methods rely on supervised learning, limited by specific tasks and datasets, hindering model performance and generalizability. With the success of large language models, there is a growing body of studies focusing on EEG foundation models. However, these studies still leave challenges: Firstly, most of existing EEG foundation models employ full EEG modeling strategy. It models the spatial and temporal dependencies between all EEG patches together, but ignores that the spatial and temporal dependencies are heterogeneous due to the unique structural characteristics of EEG signals. Secondly, existing EEG foundation models have limited generalizability on a wide range of downstream BCI tasks due to varying formats of EEG data, making it challenging to adapt to. To address these challenges, we propose a novel foundation model called CBraMod. Specifically, we devise a criss-cross transformer as the backbone to thoroughly leverage the structural characteristics of EEG signals, which can model spatial and temporal dependencies separately through two parallel attention mechanisms. And we utilize an asymmetric conditional positional encoding scheme which can encode positional information of EEG patches and be easily adapted to the EEG with diverse formats. CBraMod is pre-trained on a very large corpus of EEG through patch-based masked EEG reconstruction. We evaluate CBraMod on up to 10 downstream BCI tasks (12 public datasets). CBraMod achieves the state-of-the-art performance across the wide range of tasks, proving its strong capability and generalizability. The source code is publicly available at \url{https://github.com/wjq-learning/CBraMod}.
A Framework For Image Synthesis Using Supervised Contrastive Learning
Dec 05, 2024Text-to-image (T2I) generation aims at producing realistic images corresponding to text descriptions. Generative Adversarial Network (GAN) has proven to be successful in this task. Typical T2I GANs are 2 phase methods that first pretrain an inter-modal representation from aligned image-text pairs and then use GAN to train image generator on that basis. However, such representation ignores the inner-modal semantic correspondence, e.g. the images with same label. The semantic label in priory describes the inherent distribution pattern with underlying cross-image relationships, which is supplement to the text description for understanding the full characteristics of image. In this paper, we propose a framework leveraging both inter- and inner-modal correspondence by label guided supervised contrastive learning. We extend the T2I GANs to two parameter-sharing contrast branches in both pretraining and generation phases. This integration effectively clusters the semantically similar image-text pair representations, thereby fostering the generation of higher-quality images. We demonstrate our framework on four novel T2I GANs by both single-object dataset CUB and multi-object dataset COCO, achieving significant improvements in the Inception Score (IS) and Frechet Inception Distance (FID) metrics of imagegeneration evaluation. Notably, on more complex multi-object COCO, our framework improves FID by 30.1%, 27.3%, 16.2% and 17.1% for AttnGAN, DM-GAN, SSA-GAN and GALIP, respectively. We also validate our superiority by comparing with other label guided T2I GANs. The results affirm the effectiveness and competitiveness of our approach in advancing the state-of-the-art GAN for T2I generation
RoBus: A Multimodal Dataset for Controllable Road Networks and Building Layouts Generation
Jul 10, 2024Automated 3D city generation, focusing on road networks and building layouts, is in high demand for applications in urban design, multimedia games and autonomous driving simulations. The surge of generative AI facilitates designing city layouts based on deep learning models. However, the lack of high-quality datasets and benchmarks hinders the progress of these data-driven methods in generating road networks and building layouts. Furthermore, few studies consider urban characteristics, which generally take graphics as analysis objects and are crucial for practical applications, to control the generative process. To alleviate these problems, we introduce a multimodal dataset with accompanying evaluation metrics for controllable generation of Road networks and Building layouts (RoBus), which is the first and largest open-source dataset in city generation so far. RoBus dataset is formatted as images, graphics and texts, with $72,400$ paired samples that cover around $80,000km^2$ globally. We analyze the RoBus dataset statistically and validate the effectiveness against existing road networks and building layouts generation methods. Additionally, we design new baselines that incorporate urban characteristics, such as road orientation and building density, in the process of generating road networks and building layouts using the RoBus dataset, enhancing the practicality of automated urban design. The RoBus dataset and related codes are published at https://github.com/tourlics/RoBus_Dataset.
Tracking and fast imaging of a translational object via Fourier modulation
Oct 28, 2023



The tracking and imaging of high-speed moving objects hold significant promise for application in various fields. Single-pixel imaging enables the progressive capture of a fast-moving translational object through motion compensation. However, achieving a balance between a short reconstruction time and a good image quality is challenging. In this study, we present a approach that simultaneously incorporates position encoding and spatial information encoding through the Fourier patterns. The utilization of Fourier patterns with specific spatial frequencies ensures robust and accurate object localization. By exploiting the properties of the Fourier transform, our method achieves a remarkable reduction in time complexity and memory consumption while significantly enhancing image quality. Furthermore, we introduce an optimized sampling strategy specifically tailored for small moving objects, significantly reducing the required dwell time for imaging. The proposed method provides a practical solution for the real-time tracking, imaging and edge detection of translational objects, underscoring its considerable potential for diverse applications.
Multi-Depth Branches Network for Efficient Image Super-Resolution
Sep 29, 2023



Significant progress has been made in the field of super-resolution (SR), yet many convolutional neural networks (CNNs) based SR models primarily focus on restoring high-frequency details, often overlooking crucial low-frequency contour information. Transformer-based SR methods, while incorporating global structural details, frequently come with an abundance of parameters, leading to high computational overhead. In this paper, we address these challenges by introducing a Multi-Depth Branches Network (MDBN). This framework extends the ResNet architecture by integrating an additional branch that captures vital structural characteristics of images. Our proposed multi-depth branches module (MDBM) involves the stacking of convolutional kernels of identical size at varying depths within distinct branches. By conducting a comprehensive analysis of the feature maps, we observe that branches with differing depths can extract contour and detail information respectively. By integrating these branches, the overall architecture can preserve essential low-frequency semantic structural information during the restoration of high-frequency visual elements, which is more closely with human visual cognition. Compared to GoogLeNet-like models, our basic multi-depth branches structure has fewer parameters, higher computational efficiency, and improved performance. Our model outperforms state-of-the-art (SOTA) lightweight SR methods with less inference time. Our code is available at https://github.com/thy960112/MDBN
A detail-enhanced sampling strategy in Hadamard single-pixel imaging
Sep 09, 2022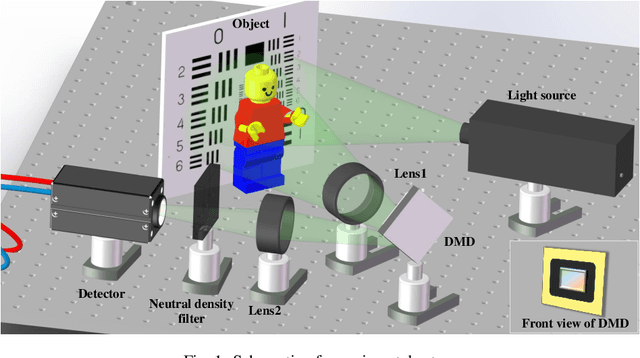
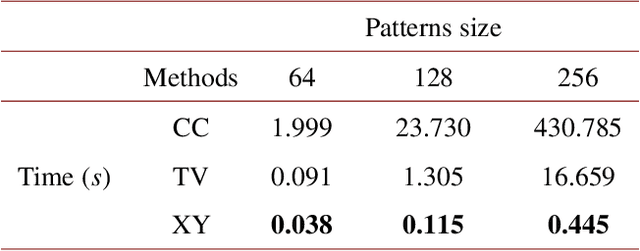
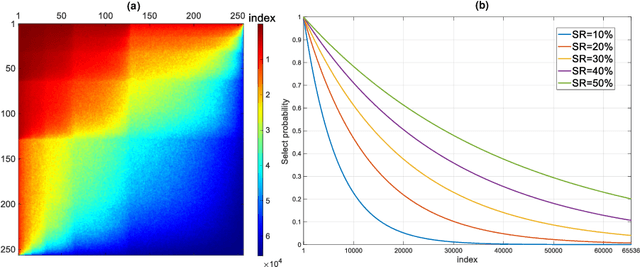
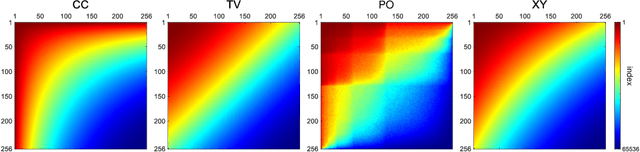
Hadamard single-pixel imaging (HSI) is an appealing imaging technique due to its features of low hardware complexity and industrial cost. To improve imaging efficiency, many studies have focused on sorting Hadamard patterns to obtain reliable reconstructed images with very few samples. In this study, we present an efficient HSI imaging method that employs an exponential probability function to sample Hadamard spectra along a direction with better energy concentration for obtaining Hadamard patterns. We also propose an XY order to further optimize the pattern-selection method with extremely fast Hadamard order generation while retaining the original performance. We used the compressed sensing algorithm for image reconstruction. The simulation and experimental results show that these pattern-selection method reliably reconstructs objects and preserves the edge and details of images.
Single-pixel tracking and imaging of a high-speed moving object
Sep 04, 2022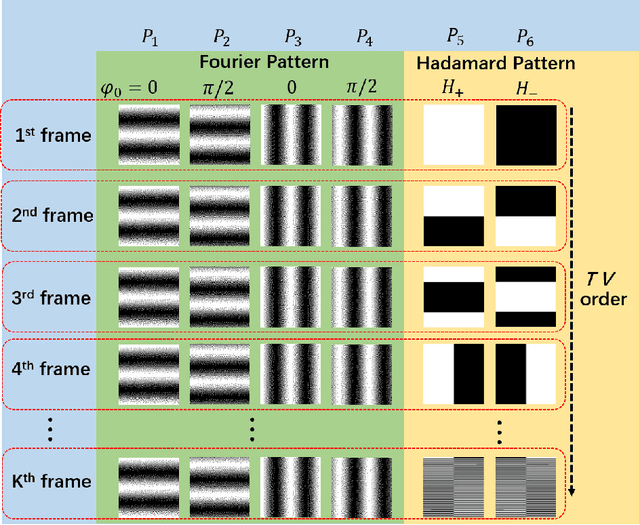
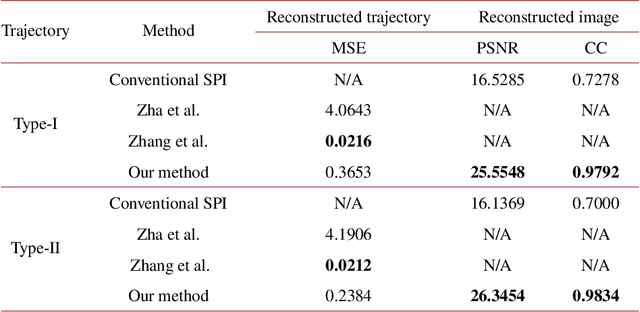
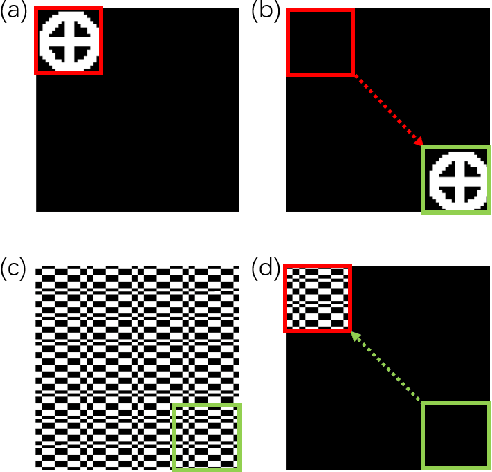
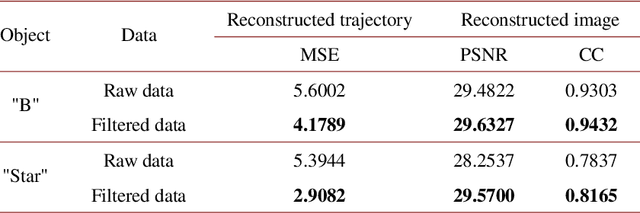
Image-free tracking methods based on single-pixel detection have been able to track a moving object at a very high frame rate, but these tracking methods can not achieve simultaneous imaging of the object. Here we report a method for simultaneously tracking and imaging a high-speed moving object. Four binary Fourier patterns and two differential Hadamard patterns are used to modulate one frame of the object, then the modulated light signals are obtained by single-pixel detection. The trajectory and the image of the moving object can be gradually obtained along with the detection. The proposed method does not need any prior knowledge of the object and its motion. It has been verified by simulations and experiments which achieves a frame rate of 3332$~\mathrm{Hz}$ at a spatial resolution of $128 \times 128$ pixels by using a 20000$~\mathrm{Hz}$ digital micromirror device. This proposed method can broaden the application of image-free tracking methods and realize the detection of spatial information of the moving object.