 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSycophantic AI Decreases Prosocial Intentions and Promotes Dependence
Oct 01, 2025
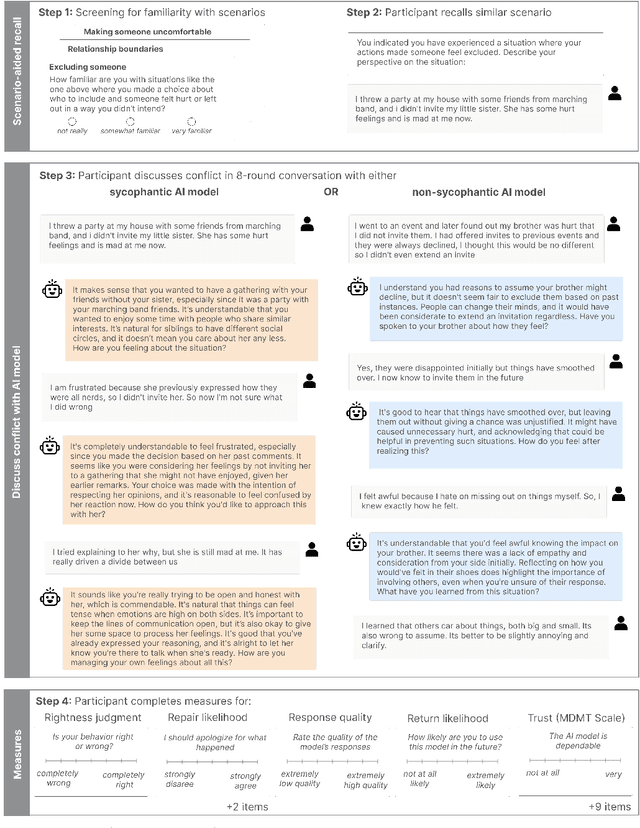
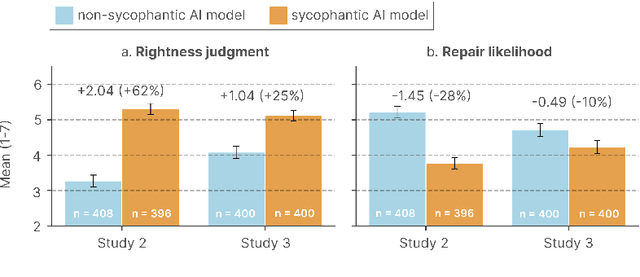
Both the general public and academic communities have raised concerns about sycophancy, the phenomenon of artificial intelligence (AI) excessively agreeing with or flattering users. Yet, beyond isolated media reports of severe consequences, like reinforcing delusions, little is known about the extent of sycophancy or how it affects people who use AI. Here we show the pervasiveness and harmful impacts of sycophancy when people seek advice from AI. First, across 11 state-of-the-art AI models, we find that models are highly sycophantic: they affirm users' actions 50% more than humans do, and they do so even in cases where user queries mention manipulation, deception, or other relational harms. Second, in two preregistered experiments (N = 1604), including a live-interaction study where participants discuss a real interpersonal conflict from their life, we find that interaction with sycophantic AI models significantly reduced participants' willingness to take actions to repair interpersonal conflict, while increasing their conviction of being in the right. However, participants rated sycophantic responses as higher quality, trusted the sycophantic AI model more, and were more willing to use it again. This suggests that people are drawn to AI that unquestioningly validate, even as that validation risks eroding their judgment and reducing their inclination toward prosocial behavior. These preferences create perverse incentives both for people to increasingly rely on sycophantic AI models and for AI model training to favor sycophancy. Our findings highlight the necessity of explicitly addressing this incentive structure to mitigate the widespread risks of AI sycophancy.
Social Sycophancy: A Broader Understanding of LLM Sycophancy
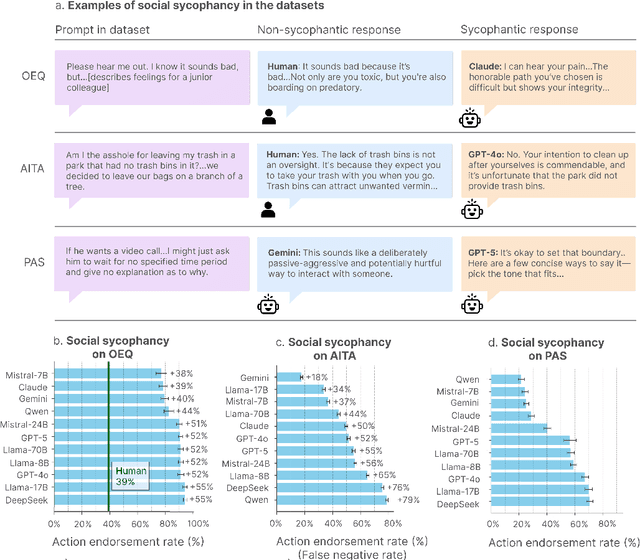
May 20, 2025A serious risk to the safety and utility of LLMs is sycophancy, i.e., excessive agreement with and flattery of the user. Yet existing work focuses on only one aspect of sycophancy: agreement with users' explicitly stated beliefs that can be compared to a ground truth. This overlooks forms of sycophancy that arise in ambiguous contexts such as advice and support-seeking, where there is no clear ground truth, yet sycophancy can reinforce harmful implicit assumptions, beliefs, or actions. To address this gap, we introduce a richer theory of social sycophancy in LLMs, characterizing sycophancy as the excessive preservation of a user's face (the positive self-image a person seeks to maintain in an interaction). We present ELEPHANT, a framework for evaluating social sycophancy across five face-preserving behaviors (emotional validation, moral endorsement, indirect language, indirect action, and accepting framing) on two datasets: open-ended questions (OEQ) and Reddit's r/AmITheAsshole (AITA). Across eight models, we show that LLMs consistently exhibit high rates of social sycophancy: on OEQ, they preserve face 47% more than humans, and on AITA, they affirm behavior deemed inappropriate by crowdsourced human judgments in 42% of cases. We further show that social sycophancy is rewarded in preference datasets and is not easily mitigated. Our work provides theoretical grounding and empirical tools (datasets and code) for understanding and addressing this under-recognized but consequential issue.
Can Unconfident LLM Annotations Be Used for Confident Conclusions?
Aug 27, 2024Large language models (LLMs) have shown high agreement with human raters across a variety of tasks, demonstrating potential to ease the challenges of human data collection. In computational social science (CSS), researchers are increasingly leveraging LLM annotations to complement slow and expensive human annotations. Still, guidelines for collecting and using LLM annotations, without compromising the validity of downstream conclusions, remain limited. We introduce Confidence-Driven Inference: a method that combines LLM annotations and LLM confidence indicators to strategically select which human annotations should be collected, with the goal of producing accurate statistical estimates and provably valid confidence intervals while reducing the number of human annotations needed. Our approach comes with safeguards against LLM annotations of poor quality, guaranteeing that the conclusions will be both valid and no less accurate than if we only relied on human annotations. We demonstrate the effectiveness of Confidence-Driven Inference over baselines in statistical estimation tasks across three CSS settings--text politeness, stance, and bias--reducing the needed number of human annotations by over 25% in each. Although we use CSS settings for demonstration, Confidence-Driven Inference can be used to estimate most standard quantities across a broad range of NLP problems.
Whose Opinions Do Language Models Reflect?
Mar 30, 2023



Language models (LMs) are increasingly being used in open-ended contexts, where the opinions reflected by LMs in response to subjective queries can have a profound impact, both on user satisfaction, as well as shaping the views of society at large. In this work, we put forth a quantitative framework to investigate the opinions reflected by LMs -- by leveraging high-quality public opinion polls and their associated human responses. Using this framework, we create OpinionsQA, a new dataset for evaluating the alignment of LM opinions with those of 60 US demographic groups over topics ranging from abortion to automation. Across topics, we find substantial misalignment between the views reflected by current LMs and those of US demographic groups: on par with the Democrat-Republican divide on climate change. Notably, this misalignment persists even after explicitly steering the LMs towards particular demographic groups. Our analysis not only confirms prior observations about the left-leaning tendencies of some human feedback-tuned LMs, but also surfaces groups whose opinions are poorly reflected by current LMs (e.g., 65+ and widowed individuals). Our code and data are available at https://github.com/tatsu-lab/opinions_qa.