 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoisy Boundaries: Lemon or Lemonade for Semi-supervised Instance Segmentation?
Mar 25, 2022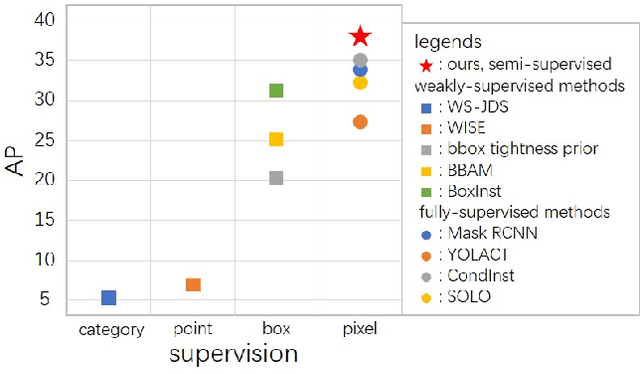
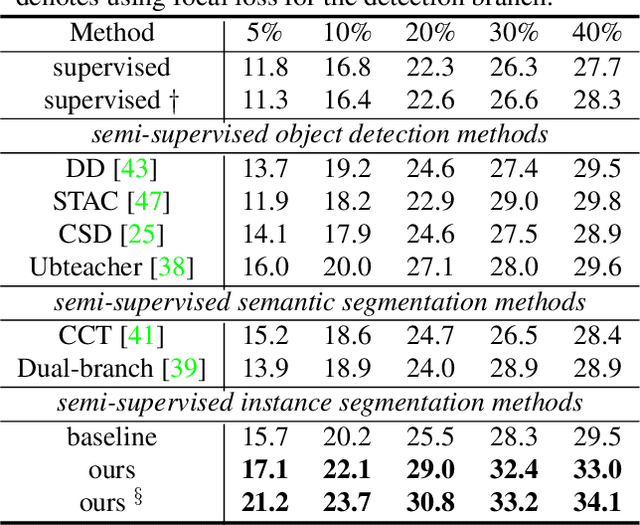
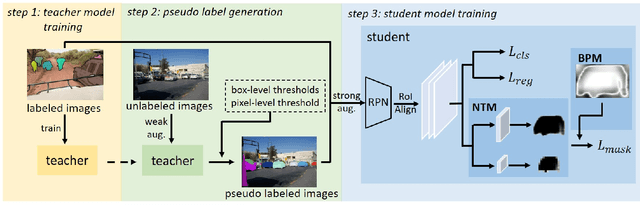
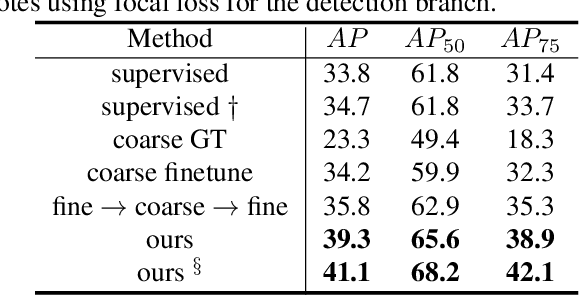
Current instance segmentation methods rely heavily on pixel-level annotated images. The huge cost to obtain such fully-annotated images restricts the dataset scale and limits the performance. In this paper, we formally address semi-supervised instance segmentation, where unlabeled images are employed to boost the performance. We construct a framework for semi-supervised instance segmentation by assigning pixel-level pseudo labels. Under this framework, we point out that noisy boundaries associated with pseudo labels are double-edged. We propose to exploit and resist them in a unified manner simultaneously: 1) To combat the negative effects of noisy boundaries, we propose a noise-tolerant mask head by leveraging low-resolution features. 2) To enhance the positive impacts, we introduce a boundary-preserving map for learning detailed information within boundary-relevant regions. We evaluate our approach by extensive experiments. It behaves extraordinarily, outperforming the supervised baseline by a large margin, more than 6% on Cityscapes, 7% on COCO and 4.5% on BDD100k. On Cityscapes, our method achieves comparable performance by utilizing only 30% labeled images.
Delving into Probabilistic Uncertainty for Unsupervised Domain Adaptive Person Re-Identification
Dec 28, 2021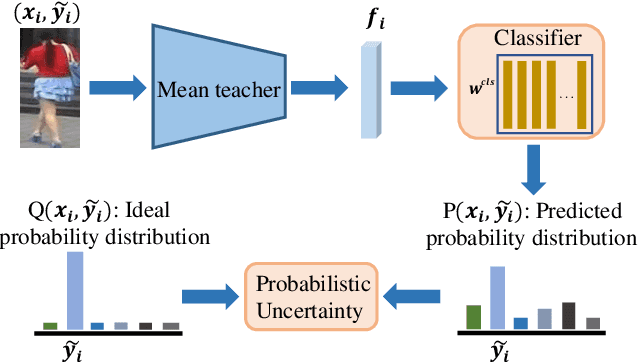
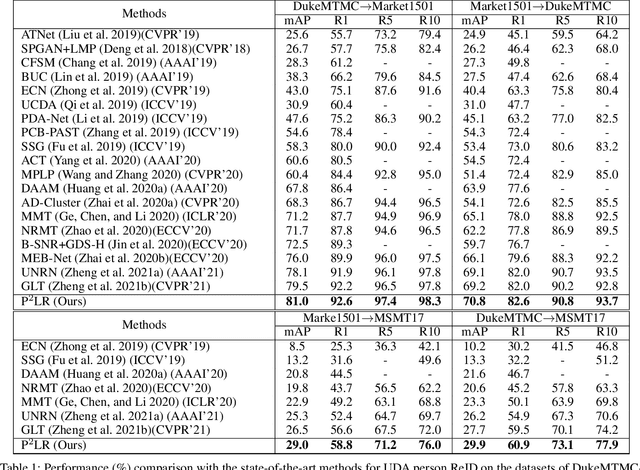
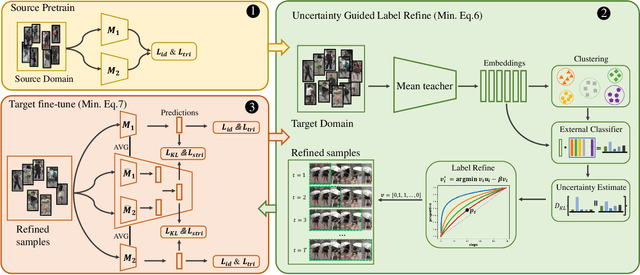
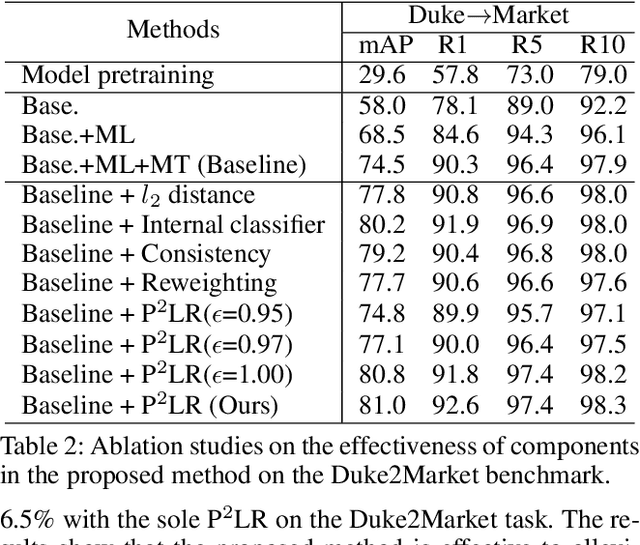
Clustering-based unsupervised domain adaptive (UDA) person re-identification (ReID) reduces exhaustive annotations. However, owing to unsatisfactory feature embedding and imperfect clustering, pseudo labels for target domain data inherently contain an unknown proportion of wrong ones, which would mislead feature learning. In this paper, we propose an approach named probabilistic uncertainty guided progressive label refinery (P$^2$LR) for domain adaptive person re-identification. First, we propose to model the labeling uncertainty with the probabilistic distance along with ideal single-peak distributions. A quantitative criterion is established to measure the uncertainty of pseudo labels and facilitate the network training. Second, we explore a progressive strategy for refining pseudo labels. With the uncertainty-guided alternative optimization, we balance between the exploration of target domain data and the negative effects of noisy labeling. On top of a strong baseline, we obtain significant improvements and achieve the state-of-the-art performance on four UDA ReID benchmarks. Specifically, our method outperforms the baseline by 6.5% mAP on the Duke2Market task, while surpassing the state-of-the-art method by 2.5% mAP on the Market2MSMT task.
Adaptive Affinity for Associations in Multi-Target Multi-Camera Tracking
Dec 14, 2021
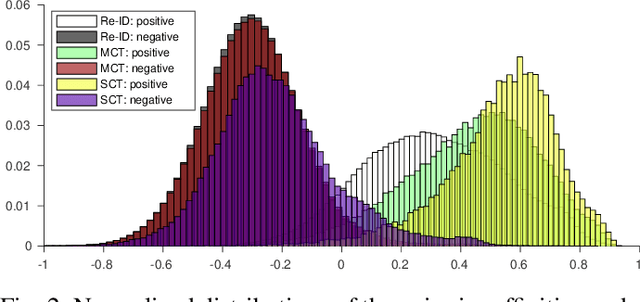
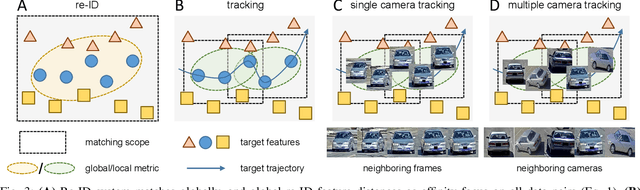
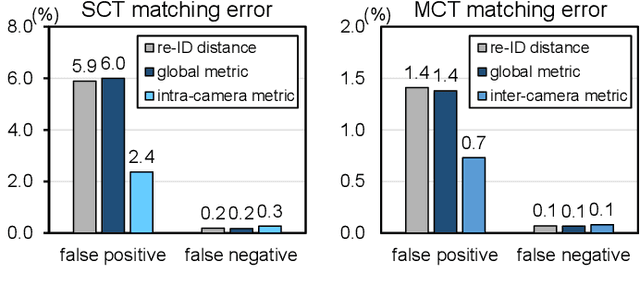
Data associations in multi-target multi-camera tracking (MTMCT) usually estimate affinity directly from re-identification (re-ID) feature distances. However, we argue that it might not be the best choice given the difference in matching scopes between re-ID and MTMCT problems. Re-ID systems focus on global matching, which retrieves targets from all cameras and all times. In contrast, data association in tracking is a local matching problem, since its candidates only come from neighboring locations and time frames. In this paper, we design experiments to verify such misfit between global re-ID feature distances and local matching in tracking, and propose a simple yet effective approach to adapt affinity estimations to corresponding matching scopes in MTMCT. Instead of trying to deal with all appearance changes, we tailor the affinity metric to specialize in ones that might emerge during data associations. To this end, we introduce a new data sampling scheme with temporal windows originally used for data associations in tracking. Minimizing the mismatch, the adaptive affinity module brings significant improvements over global re-ID distance, and produces competitive performance on CityFlow and DukeMTMC datasets.
Combating Noise: Semi-supervised Learning by Region Uncertainty Quantification
Nov 01, 2021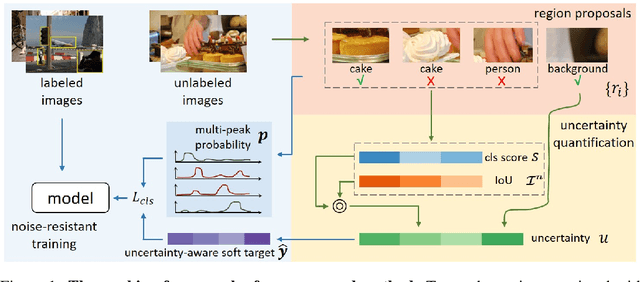
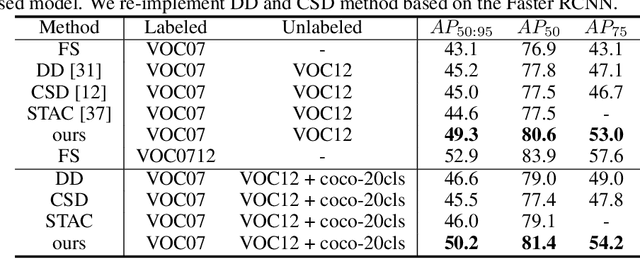
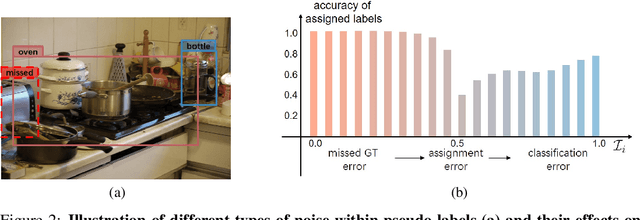
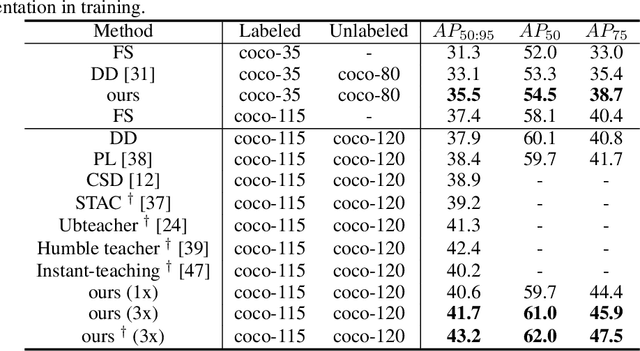
Semi-supervised learning aims to leverage a large amount of unlabeled data for performance boosting. Existing works primarily focus on image classification. In this paper, we delve into semi-supervised learning for object detection, where labeled data are more labor-intensive to collect. Current methods are easily distracted by noisy regions generated by pseudo labels. To combat the noisy labeling, we propose noise-resistant semi-supervised learning by quantifying the region uncertainty. We first investigate the adverse effects brought by different forms of noise associated with pseudo labels. Then we propose to quantify the uncertainty of regions by identifying the noise-resistant properties of regions over different strengths. By importing the region uncertainty quantification and promoting multipeak probability distribution output, we introduce uncertainty into training and further achieve noise-resistant learning. Experiments on both PASCAL VOC and MS COCO demonstrate the extraordinary performance of our method.
EFENet: Reference-based Video Super-Resolution with Enhanced Flow Estimation
Oct 28, 2021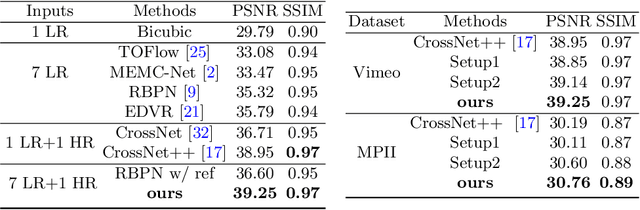
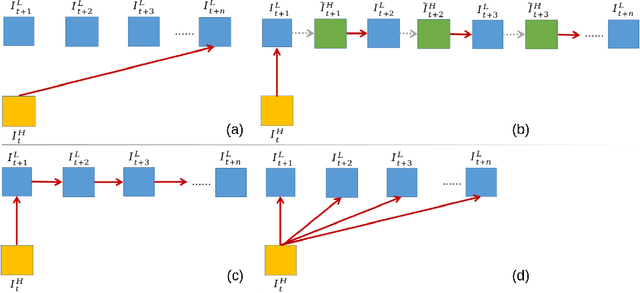

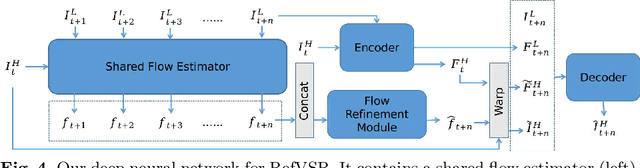
In this paper, we consider the problem of reference-based video super-resolution(RefVSR), i.e., how to utilize a high-resolution (HR) reference frame to super-resolve a low-resolution (LR) video sequence. The existing approaches to RefVSR essentially attempt to align the reference and the input sequence, in the presence of resolution gap and long temporal range. However, they either ignore temporal structure within the input sequence, or suffer accumulative alignment errors. To address these issues, we propose EFENet to exploit simultaneously the visual cues contained in the HR reference and the temporal information contained in the LR sequence. EFENet first globally estimates cross-scale flow between the reference and each LR frame. Then our novel flow refinement module of EFENet refines the flow regarding the furthest frame using all the estimated flows, which leverages the global temporal information within the sequence and therefore effectively reduces the alignment errors. We provide comprehensive evaluations to validate the strengths of our approach, and to demonstrate that the proposed framework outperforms the state-of-the-art methods. Code is available at https://github.com/IndigoPurple/EFENet.
Towards Discriminative Representation Learning for Unsupervised Person Re-identification
Aug 16, 2021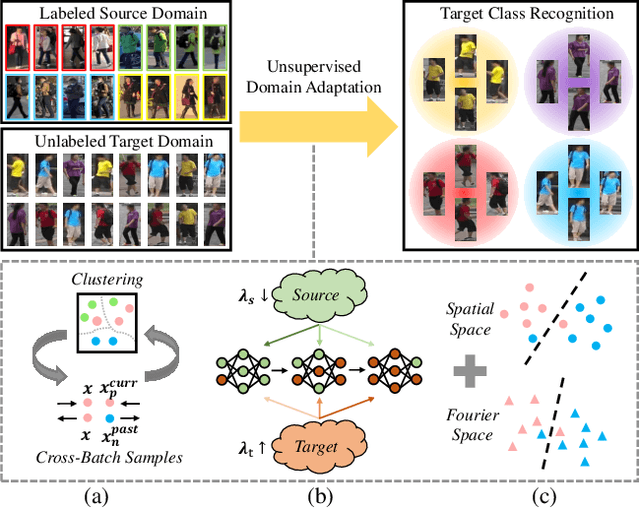
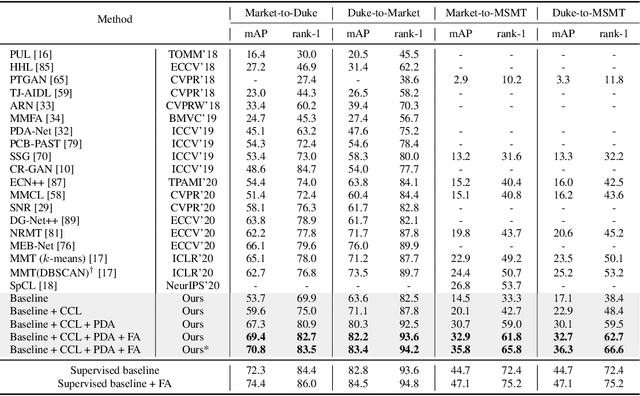
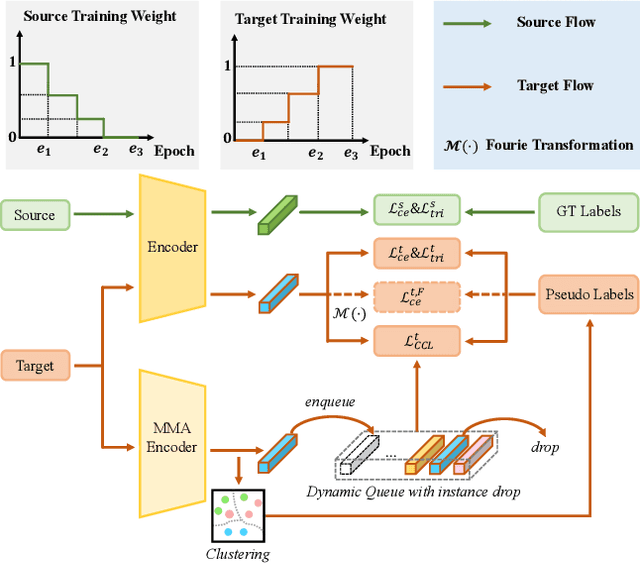
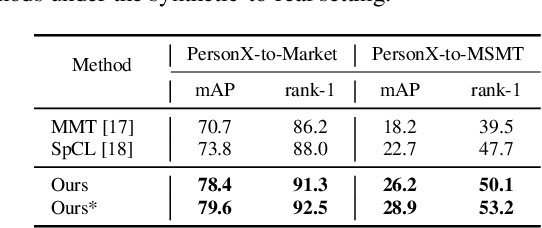
In this work, we address the problem of unsupervised domain adaptation for person re-ID where annotations are available for the source domain but not for target. Previous methods typically follow a two-stage optimization pipeline, where the network is first pre-trained on source and then fine-tuned on target with pseudo labels created by feature clustering. Such methods sustain two main limitations. (1) The label noise may hinder the learning of discriminative features for recognizing target classes. (2) The domain gap may hinder knowledge transferring from source to target. We propose three types of technical schemes to alleviate these issues. First, we propose a cluster-wise contrastive learning algorithm (CCL) by iterative optimization of feature learning and cluster refinery to learn noise-tolerant representations in the unsupervised manner. Second, we adopt a progressive domain adaptation (PDA) strategy to gradually mitigate the domain gap between source and target data. Third, we propose Fourier augmentation (FA) for further maximizing the class separability of re-ID models by imposing extra constraints in the Fourier space. We observe that these proposed schemes are capable of facilitating the learning of discriminative feature representations. Experiments demonstrate that our method consistently achieves notable improvements over the state-of-the-art unsupervised re-ID methods on multiple benchmarks, e.g., surpassing MMT largely by 8.1\%, 9.9\%, 11.4\% and 11.1\% mAP on the Market-to-Duke, Duke-to-Market, Market-to-MSMT and Duke-to-MSMT tasks, respectively.
Do Different Tracking Tasks Require Different Appearance Models?
Jul 05, 2021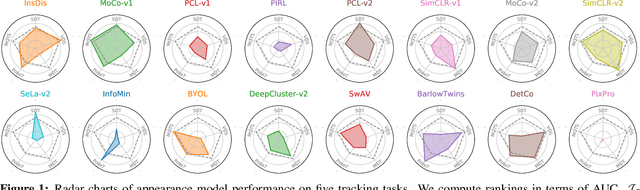


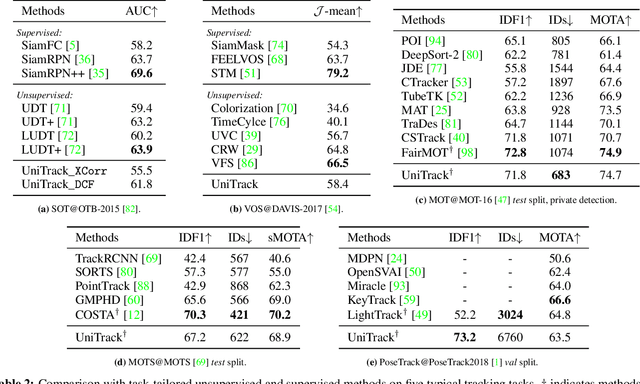
Tracking objects of interest in a video is one of the most popular and widely applicable problems in computer vision. However, with the years, a Cambrian explosion of use cases and benchmarks has fragmented the problem in a multitude of different experimental setups. As a consequence, the literature has fragmented too, and now the novel approaches proposed by the community are usually specialised to fit only one specific setup. To understand to what extent this specialisation is actually necessary, in this work we present UniTrack, a unified tracking solution to address five different tasks within the same framework. UniTrack consists of a single and task-agnostic appearance model, which can be learned in a supervised or self-supervised fashion, and multiple "heads" to address individual tasks and that do not require training. We show how most tracking tasks can be solved within this framework, and that the same appearance model can be used to obtain performance that is competitive against specialised methods for all the five tasks considered. The framework also allows us to analyse appearance models obtained with the most recent self-supervised methods, thus significantly extending their evaluation and comparison to a larger variety of important problems. Code available at https://github.com/Zhongdao/UniTrack.
AdaZoom: Adaptive Zoom Network for Multi-Scale Object Detection in Large Scenes
Jun 19, 2021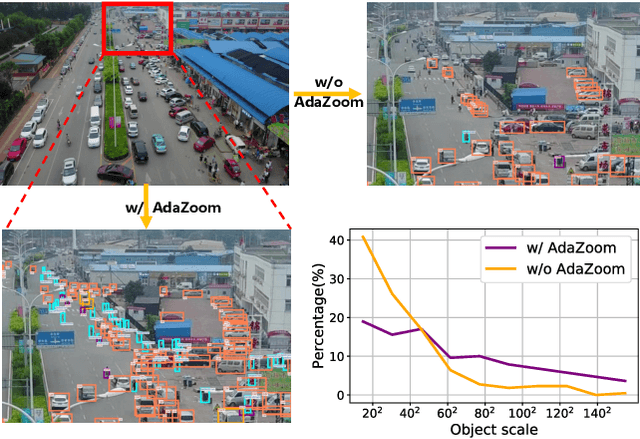
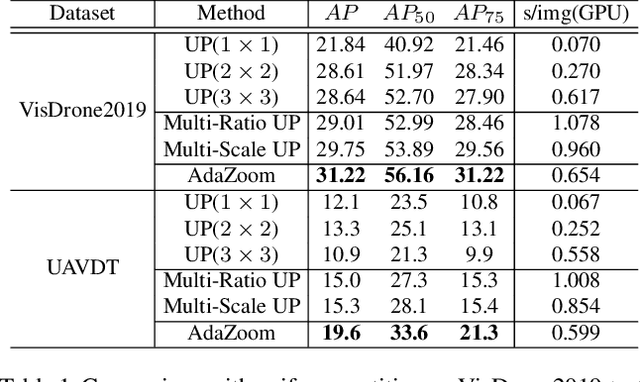
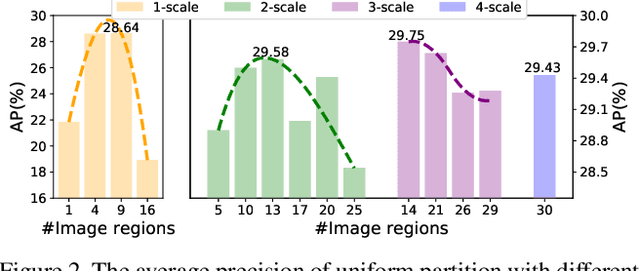
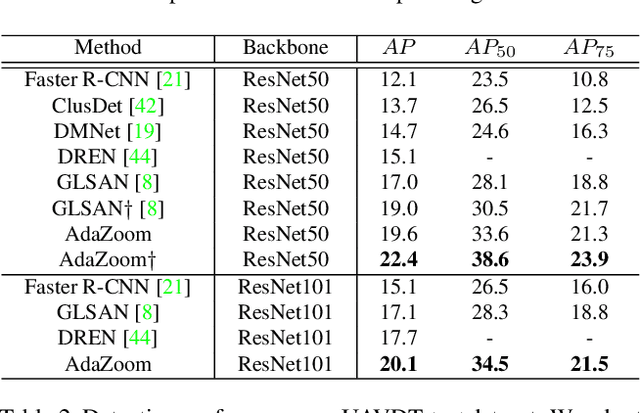
Detection in large-scale scenes is a challenging problem due to small objects and extreme scale variation. It is essential to focus on the image regions of small objects. In this paper, we propose a novel Adaptive Zoom (AdaZoom) network as a selective magnifier with flexible shape and focal length to adaptively zoom the focus regions for object detection. Based on policy gradient, we construct a reinforcement learning framework for focus region generation, with the reward formulated by object distributions. The scales and aspect ratios of the generated regions are adaptive to the scales and distribution of objects inside. We apply variable magnification according to the scale of the region for adaptive multi-scale detection. We further propose collaborative training to complementarily promote the performance of AdaZoom and the detection network. To validate the effectiveness, we conduct extensive experiments on VisDrone2019, UAVDT, and DOTA datasets. The experiments show AdaZoom brings a consistent and significant improvement over different detection networks, achieving state-of-the-art performance on these datasets, especially outperforming the existing methods by AP of 4.64% on Vis-Drone2019.
Multi-Target Domain Adaptation with Collaborative Consistency Learning
Jun 07, 2021
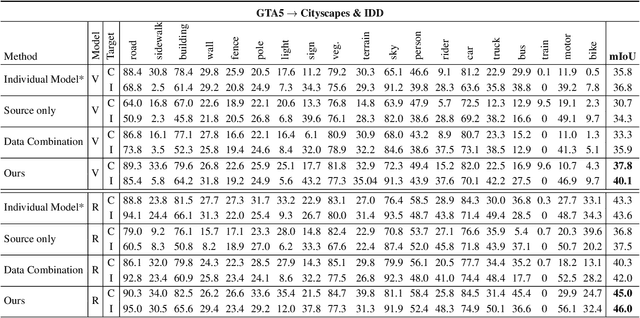
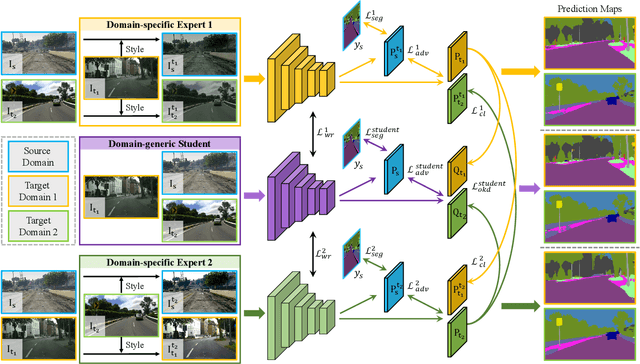
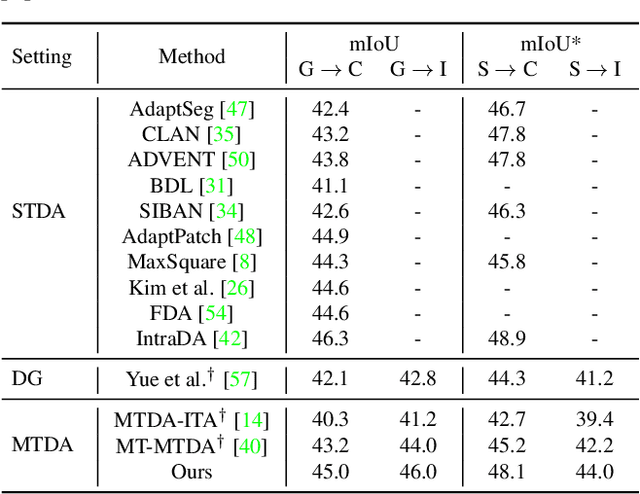
Recently unsupervised domain adaptation for the semantic segmentation task has become more and more popular due to high-cost of pixel-level annotation on real-world images. However, most domain adaptation methods are only restricted to single-source-single-target pair, and can not be directly extended to multiple target domains. In this work, we propose a collaborative learning framework to achieve unsupervised multi-target domain adaptation. An unsupervised domain adaptation expert model is first trained for each source-target pair and is further encouraged to collaborate with each other through a bridge built between different target domains. These expert models are further improved by adding the regularization of making the consistent pixel-wise prediction for each sample with the same structured context. To obtain a single model that works across multiple target domains, we propose to simultaneously learn a student model which is trained to not only imitate the output of each expert on the corresponding target domain, but also to pull different expert close to each other with regularization on their weights. Extensive experiments demonstrate that the proposed method can effectively exploit rich structured information contained in both labeled source domain and multiple unlabeled target domains. Not only does it perform well across multiple target domains but also performs favorably against state-of-the-art unsupervised domain adaptation methods specially trained on a single source-target pair
A^2-FPN: Attention Aggregation based Feature Pyramid Network for Instance Segmentation
May 07, 2021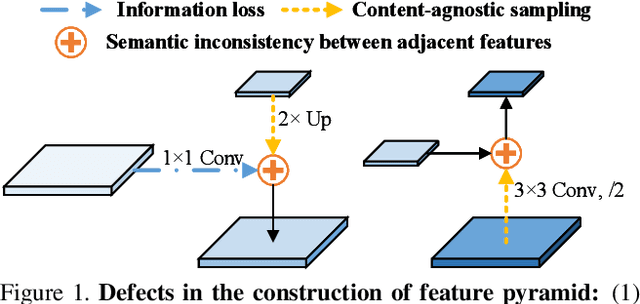
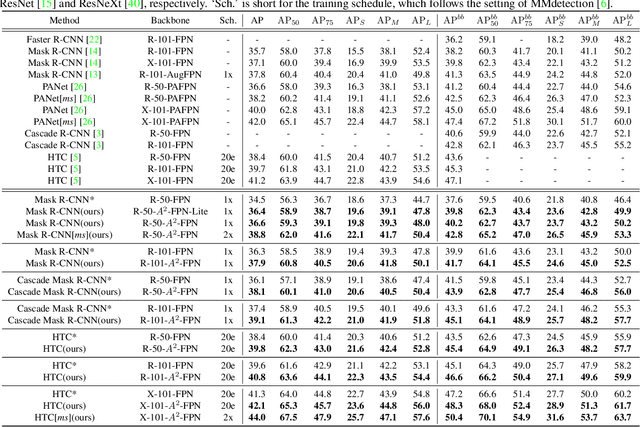
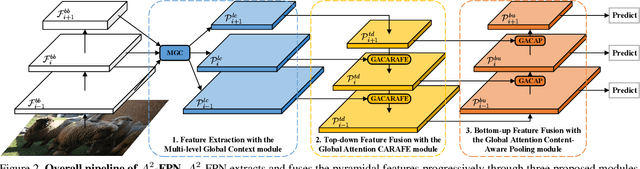
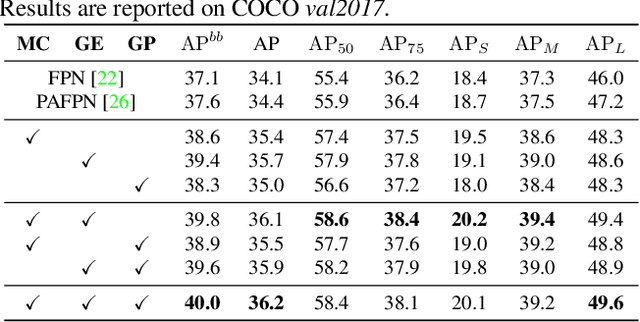
Learning pyramidal feature representations is crucial for recognizing object instances at different scales. Feature Pyramid Network (FPN) is the classic architecture to build a feature pyramid with high-level semantics throughout. However, intrinsic defects in feature extraction and fusion inhibit FPN from further aggregating more discriminative features. In this work, we propose Attention Aggregation based Feature Pyramid Network (A^2-FPN), to improve multi-scale feature learning through attention-guided feature aggregation. In feature extraction, it extracts discriminative features by collecting-distributing multi-level global context features, and mitigates the semantic information loss due to drastically reduced channels. In feature fusion, it aggregates complementary information from adjacent features to generate location-wise reassembly kernels for content-aware sampling, and employs channel-wise reweighting to enhance the semantic consistency before element-wise addition. A^2-FPN shows consistent gains on different instance segmentation frameworks. By replacing FPN with A^2-FPN in Mask R-CNN, our model boosts the performance by 2.1% and 1.6% mask AP when using ResNet-50 and ResNet-101 as backbone, respectively. Moreover, A^2-FPN achieves an improvement of 2.0% and 1.4% mask AP when integrated into the strong baselines such as Cascade Mask R-CNN and Hybrid Task Cascade.