 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight Forcing: Accelerating Autoregressive Video Diffusion via Sparse Attention
Feb 04, 2026Advanced autoregressive (AR) video generation models have improved visual fidelity and interactivity, but the quadratic complexity of attention remains a primary bottleneck for efficient deployment. While existing sparse attention solutions have shown promise on bidirectional models, we identify that applying these solutions to AR models leads to considerable performance degradation for two reasons: isolated consideration of chunk generation and insufficient utilization of past informative context. Motivated by these observations, we propose \textsc{Light Forcing}, the \textit{first} sparse attention solution tailored for AR video generation models. It incorporates a \textit{Chunk-Aware Growth} mechanism to quantitatively estimate the contribution of each chunk, which determines their sparsity allocation. This progressive sparsity increase strategy enables the current chunk to inherit prior knowledge in earlier chunks during generation. Additionally, we introduce a \textit{Hierarchical Sparse Attention} to capture informative historical and local context in a coarse-to-fine manner. Such two-level mask selection strategy (\ie, frame and block level) can adaptively handle diverse attention patterns. Extensive experiments demonstrate that our method outperforms existing sparse attention in quality (\eg, 84.5 on VBench) and efficiency (\eg, $1.2{\sim}1.3\times$ end-to-end speedup). Combined with FP8 quantization and LightVAE, \textsc{Light Forcing} further achieves a $2.3\times$ speedup and 19.7\,FPS on an RTX~5090 GPU. Code will be released at \href{https://github.com/chengtao-lv/LightForcing}{https://github.com/chengtao-lv/LightForcing}.
BadSFL: Backdoor Attack against Scaffold Federated Learning
Nov 26, 2024



Federated learning (FL) enables the training of deep learning models on distributed clients to preserve data privacy. However, this learning paradigm is vulnerable to backdoor attacks, where malicious clients can upload poisoned local models to embed backdoors into the global model, leading to attacker-desired predictions. Existing backdoor attacks mainly focus on FL with independently and identically distributed (IID) scenarios, while real-world FL training data are typically non-IID. Current strategies for non-IID backdoor attacks suffer from limitations in maintaining effectiveness and durability. To address these challenges, we propose a novel backdoor attack method, BadSFL, specifically designed for the FL framework using the scaffold aggregation algorithm in non-IID settings. BadSFL leverages a Generative Adversarial Network (GAN) based on the global model to complement the training set, achieving high accuracy on both backdoor and benign samples. It utilizes a specific feature as the backdoor trigger to ensure stealthiness, and exploits the Scaffold's control variate to predict the global model's convergence direction, ensuring the backdoor's persistence. Extensive experiments on three benchmark datasets demonstrate the high effectiveness, stealthiness, and durability of BadSFL. Notably, our attack remains effective over 60 rounds in the global model and up to 3 times longer than existing baseline attacks after stopping the injection of malicious updates.
Learning Compact Neural Networks with Deep Overparameterised Multitask Learning
Aug 25, 2023Compact neural network offers many benefits for real-world applications. However, it is usually challenging to train the compact neural networks with small parameter sizes and low computational costs to achieve the same or better model performance compared to more complex and powerful architecture. This is particularly true for multitask learning, with different tasks competing for resources. We present a simple, efficient and effective multitask learning overparameterisation neural network design by overparameterising the model architecture in training and sharing the overparameterised model parameters more effectively across tasks, for better optimisation and generalisation. Experiments on two challenging multitask datasets (NYUv2 and COCO) demonstrate the effectiveness of the proposed method across various convolutional networks and parameter sizes.
Optimising Stochastic Routing for Taxi Fleets with Model Enhanced Reinforcement Learning
Oct 22, 2020
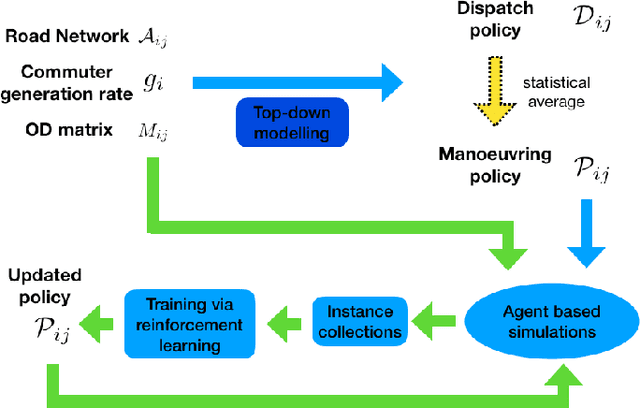
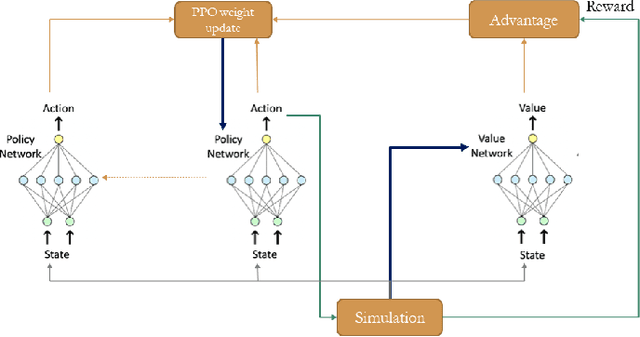
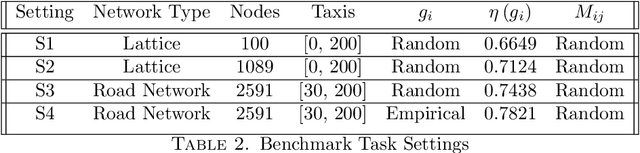
The future of mobility-as-a-Service (Maas)should embrace an integrated system of ride-hailing, street-hailing and ride-sharing with optimised intelligent vehicle routing in response to a real-time, stochastic demand pattern. We aim to optimise routing policies for a large fleet of vehicles for street-hailing services, given a stochastic demand pattern in small to medium-sized road networks. A model-based dispatch algorithm, a high performance model-free reinforcement learning based algorithm and a novel hybrid algorithm combining the benefits of both the top-down approach and the model-free reinforcement learning have been proposed to route the \emph{vacant} vehicles. We design our reinforcement learning based routing algorithm using proximal policy optimisation and combined intrinsic and extrinsic rewards to strike a balance between exploration and exploitation. Using a large-scale agent-based microscopic simulation platform to evaluate our proposed algorithms, our model-free reinforcement learning and hybrid algorithm show excellent performance on both artificial road network and community-based Singapore road network with empirical demands, and our hybrid algorithm can significantly accelerate the model-free learner in the process of learning.