 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilizing Equilibrium Models by Jacobian Regularization
Jun 28, 2021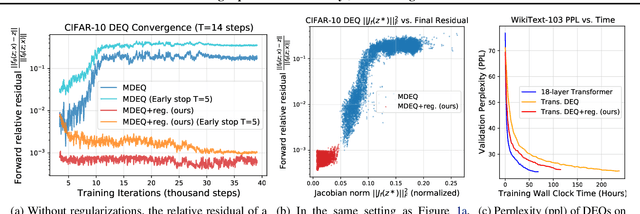
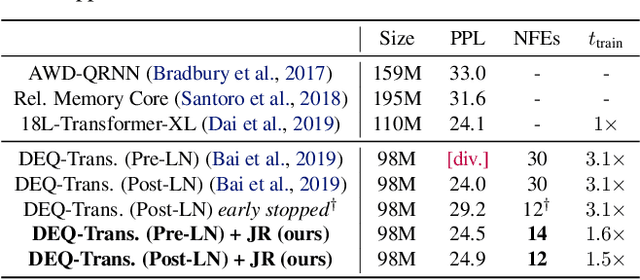
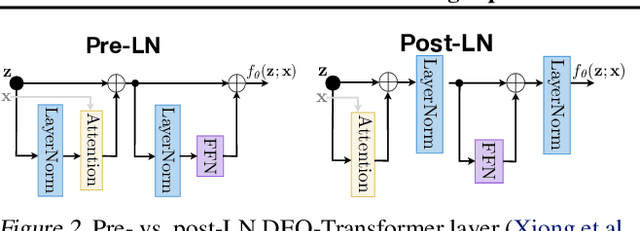
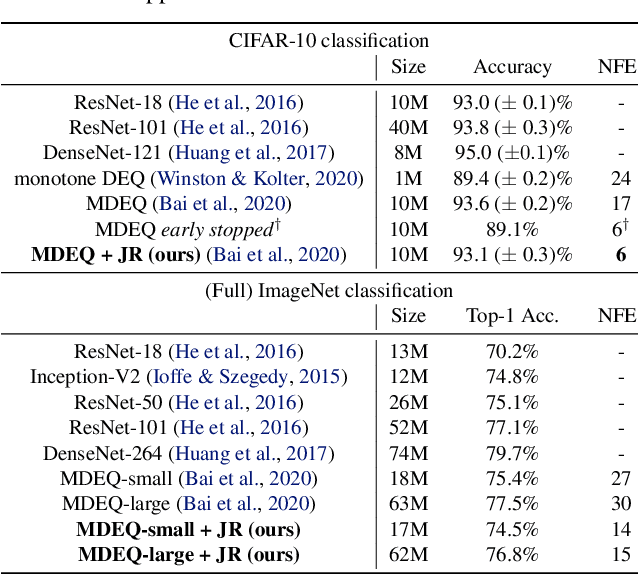
Deep equilibrium networks (DEQs) are a new class of models that eschews traditional depth in favor of finding the fixed point of a single nonlinear layer. These models have been shown to achieve performance competitive with the state-of-the-art deep networks while using significantly less memory. Yet they are also slower, brittle to architectural choices, and introduce potential instability to the model. In this paper, we propose a regularization scheme for DEQ models that explicitly regularizes the Jacobian of the fixed-point update equations to stabilize the learning of equilibrium models. We show that this regularization adds only minimal computational cost, significantly stabilizes the fixed-point convergence in both forward and backward passes, and scales well to high-dimensional, realistic domains (e.g., WikiText-103 language modeling and ImageNet classification). Using this method, we demonstrate, for the first time, an implicit-depth model that runs with approximately the same speed and level of performance as popular conventional deep networks such as ResNet-101, while still maintaining the constant memory footprint and architectural simplicity of DEQs. Code is available at https://github.com/locuslab/deq .
SHINE: SHaring the INverse Estimate from the forward pass for bi-level optimization and implicit models
Jun 24, 2021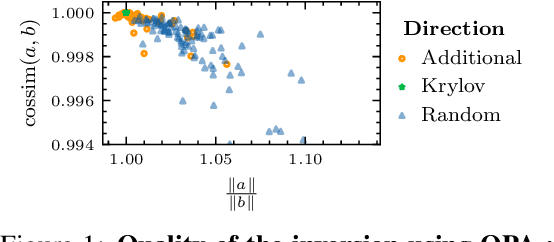
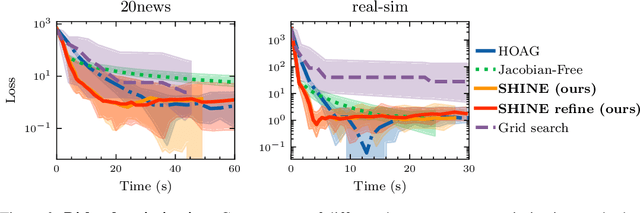
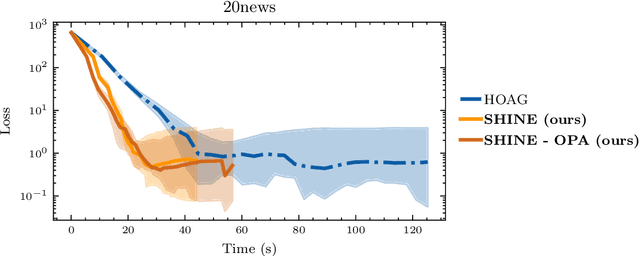
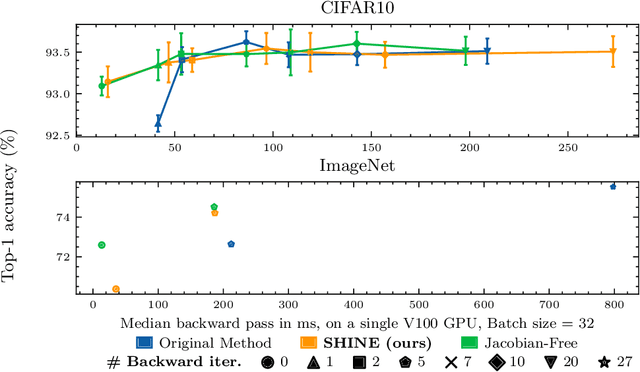
In recent years, implicit deep learning has emerged as a method to increase the depth of deep neural networks. While their training is memory-efficient, they are still significantly slower to train than their explicit counterparts. In Deep Equilibrium Models (DEQs), the training is performed as a bi-level problem, and its computational complexity is partially driven by the iterative inversion of a huge Jacobian matrix. In this paper, we propose a novel strategy to tackle this computational bottleneck from which many bi-level problems suffer. The main idea is to use the quasi-Newton matrices from the forward pass to efficiently approximate the inverse Jacobian matrix in the direction needed for the gradient computation. We provide a theorem that motivates using our method with the original forward algorithms. In addition, by modifying these forward algorithms, we further provide theoretical guarantees that our method asymptotically estimates the true implicit gradient. We empirically study this approach in many settings, ranging from hyperparameter optimization to large Multiscale DEQs applied to CIFAR and ImageNet. We show that it reduces the computational cost of the backward pass by up to two orders of magnitude. All this is achieved while retaining the excellent performance of the original models in hyperparameter optimization and on CIFAR, and giving encouraging and competitive results on ImageNet.
A Note on Connecting Barlow Twins with Negative-Sample-Free Contrastive Learning
Apr 28, 2021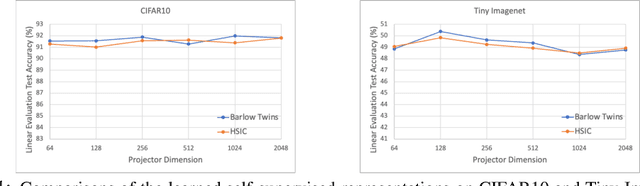
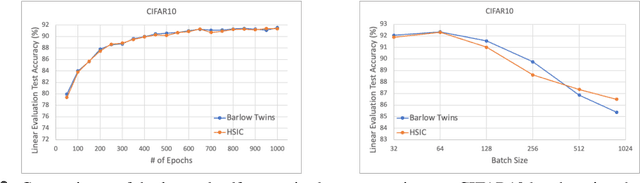
In this report, we relate the algorithmic design of Barlow Twins' method to the Hilbert-Schmidt Independence Criterion (HSIC), thus establishing it as a contrastive learning approach that is free of negative samples. Through this perspective, we argue that Barlow Twins (and thus the class of negative-sample-free contrastive learning methods) suggests a possibility to bridge the two major families of self-supervised learning philosophies: non-contrastive and contrastive approaches. In particular, Barlow twins exemplified how we could combine the best practices of both worlds: avoiding the need of large training batch size and negative sample pairing (like non-contrastive methods) and avoiding symmetry-breaking network designs (like contrastive methods).
A community-powered search of machine learning strategy space to find NMR property prediction models
Aug 13, 2020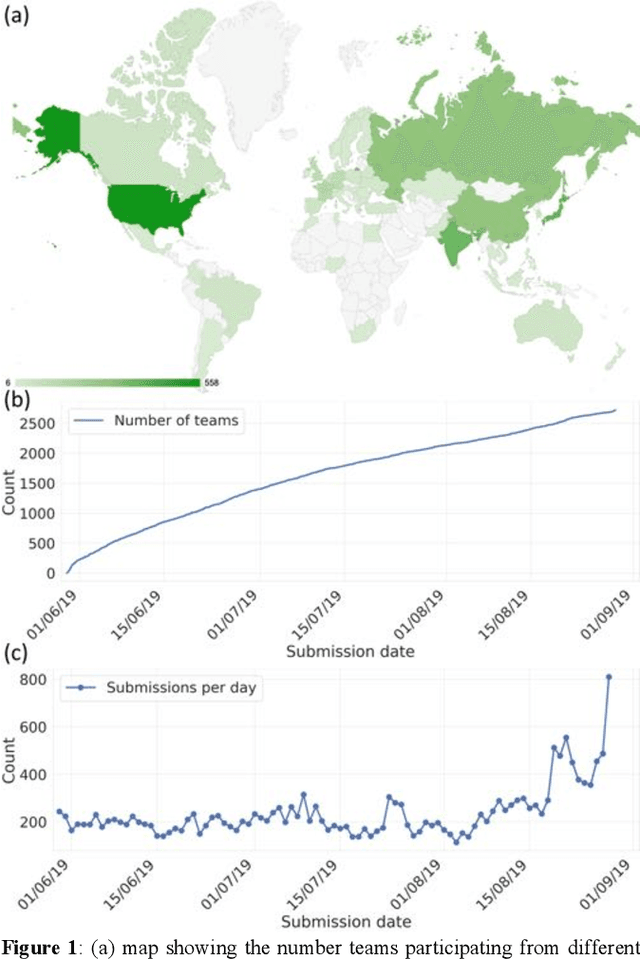
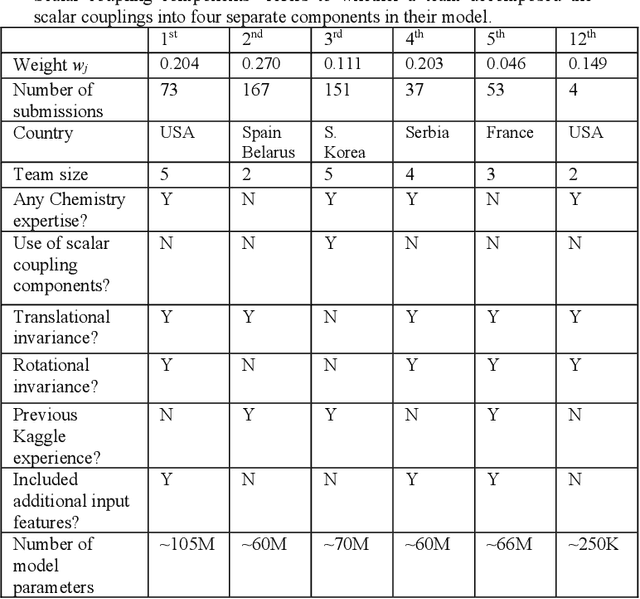
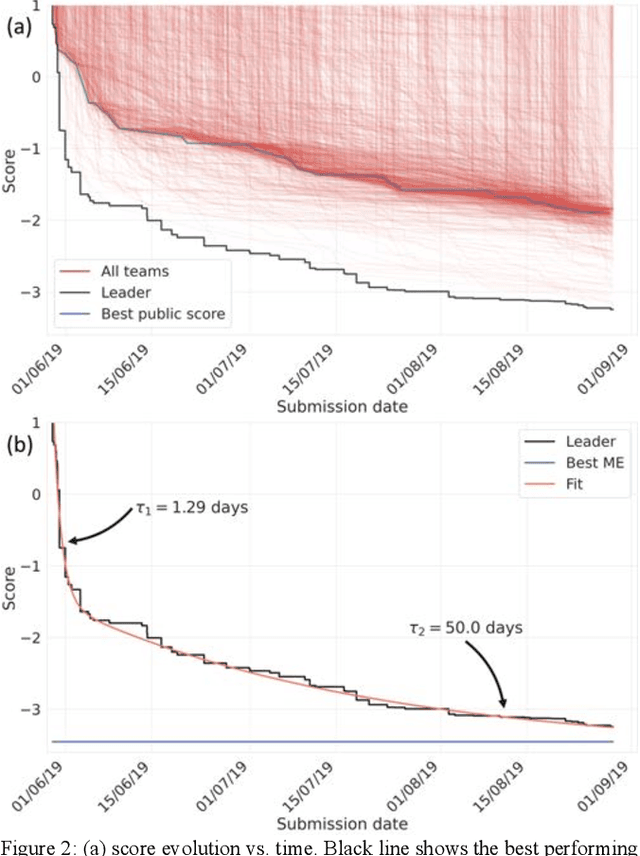
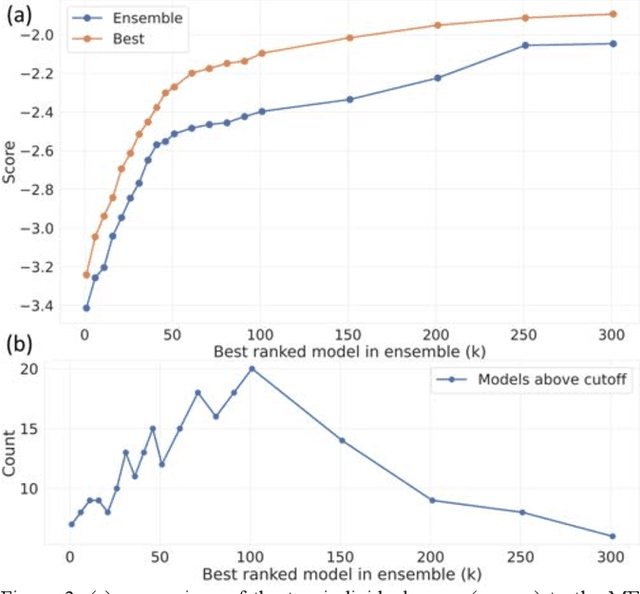
The rise of machine learning (ML) has created an explosion in the potential strategies for using data to make scientific predictions. For physical scientists wishing to apply ML strategies to a particular domain, it can be difficult to assess in advance what strategy to adopt within a vast space of possibilities. Here we outline the results of an online community-powered effort to swarm search the space of ML strategies and develop algorithms for predicting atomic-pairwise nuclear magnetic resonance (NMR) properties in molecules. Using an open-source dataset, we worked with Kaggle to design and host a 3-month competition which received 47,800 ML model predictions from 2,700 teams in 84 countries. Within 3 weeks, the Kaggle community produced models with comparable accuracy to our best previously published "in-house" efforts. A meta-ensemble model constructed as a linear combination of the top predictions has a prediction accuracy which exceeds that of any individual model, 7-19x better than our previous state-of-the-art. The results highlight the potential of transformer architectures for predicting quantum mechanical (QM) molecular properties.
Multiscale Deep Equilibrium Models
Jun 15, 2020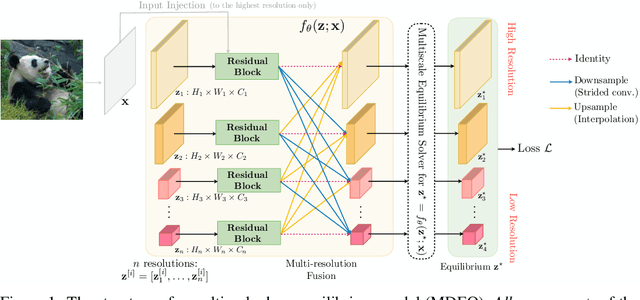
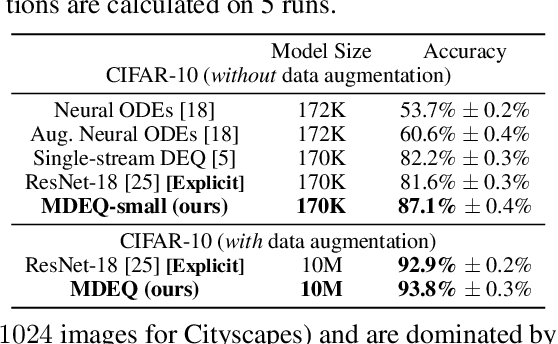
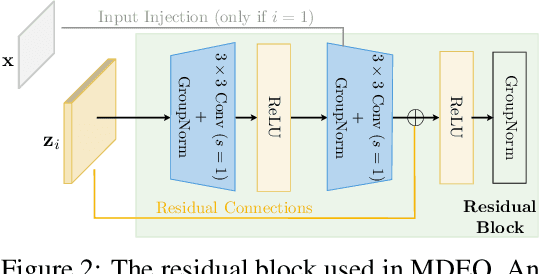
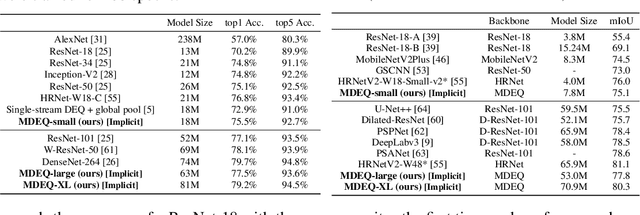
We propose a new class of implicit networks, the multiscale deep equilibrium model (MDEQ), suited to large-scale and highly hierarchical pattern recognition domains. An MDEQ directly solves for and backpropagates through the equilibrium points of multiple feature resolutions simultaneously, using implicit differentiation to avoid storing intermediate states (and thus requiring only O(1) memory consumption). These simultaneously-learned multi-resolution features allow us to train a single model on a diverse set of tasks and loss functions, such as using a single MDEQ to perform both image classification and semantic segmentation. We illustrate the effectiveness of this approach on two large-scale vision tasks: ImageNet classification and semantic segmentation on high-resolution images from the Cityscapes dataset. In both settings, MDEQs are able to match or exceed the performance of recent competitive computer vision models: the first time such performance and scale have been achieved by an implicit deep learning approach. The code and pre-trained models are at https://github.com/locuslab/mdeq .
Deep Equilibrium Models
Sep 03, 2019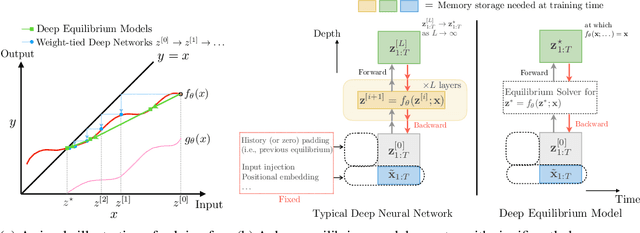

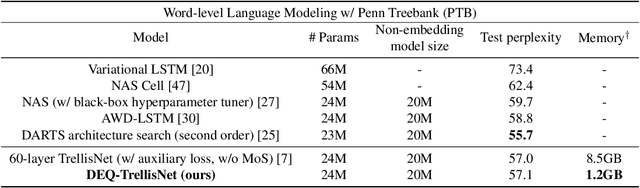
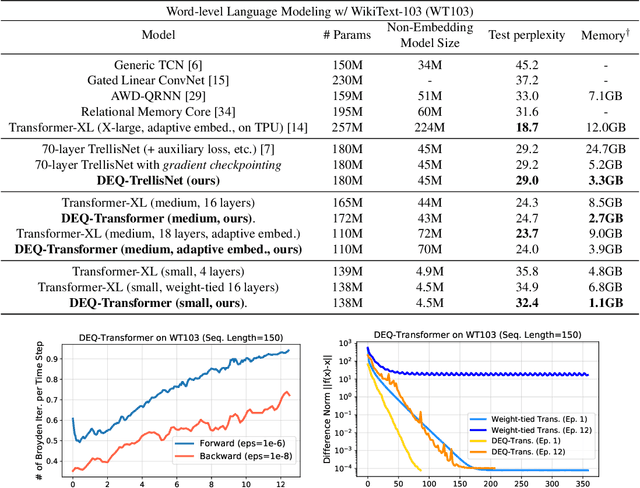
We present a new approach to modeling sequential data: the deep equilibrium model (DEQ). Motivated by an observation that the hidden layers of many existing deep sequence models converge towards some fixed point, we propose the DEQ approach that directly finds these equilibrium points via root-finding. Such a method is equivalent to running an infinite depth (weight-tied) feedforward network, but has the notable advantage that we can analytically backpropagate through the equilibrium point using implicit differentiation. Using this approach, training and prediction in these networks require only constant memory, regardless of the effective "depth" of the network. We demonstrate how DEQs can be applied to two state-of-the-art deep sequence models: self-attention transformers and trellis networks. On large-scale language modeling tasks, such as the WikiText-103 benchmark, we show that DEQs 1) often improve performance over these state-of-the-art models (for similar parameter counts); 2) have similar computational requirements as existing models; and 3) vastly reduce memory consumption (often the bottleneck for training large sequence models), demonstrating an up-to 88% memory reduction in our experiments. The code is available at https://github. com/locuslab/deq .
Transformer Dissection: An Unified Understanding for Transformer's Attention via the Lens of Kernel
Aug 30, 2019
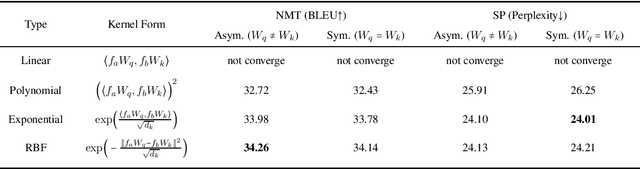

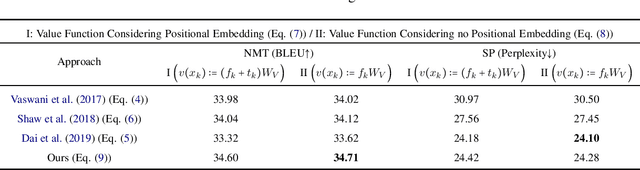
Transformer is a powerful architecture that achieves superior performance on various sequence learning tasks, including neural machine translation, language understanding, and sequence prediction. At the core of the Transformer is the attention mechanism, which concurrently processes all inputs in the streams. In this paper, we present a new formulation of attention via the lens of the kernel. To be more precise, we realize that the attention can be seen as applying kernel smoother over the inputs with the kernel scores being the similarities between inputs. This new formulation gives us a better way to understand individual components of the Transformer's attention, such as the better way to integrate the positional embedding. Another important advantage of our kernel-based formulation is that it paves the way to a larger space of composing Transformer's attention. As an example, we propose a new variant of Transformer's attention which models the input as a product of symmetric kernels. This approach achieves competitive performance to the current state of the art model with less computation. In our experiments, we empirically study different kernel construction strategies on two widely used tasks: neural machine translation and sequence prediction.
Multimodal Transformer for Unaligned Multimodal Language Sequences
Jun 01, 2019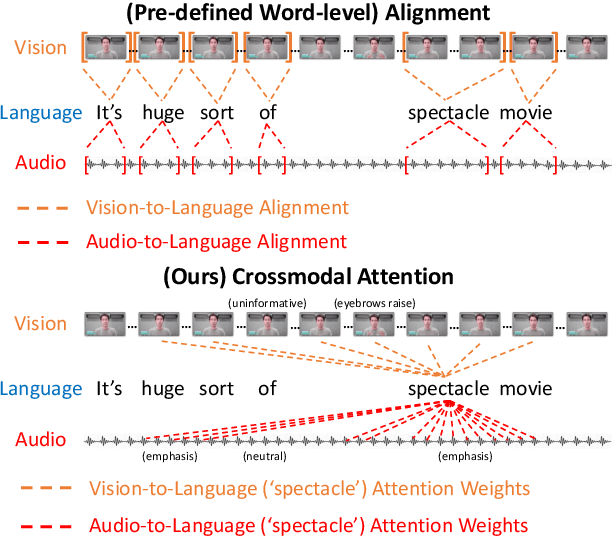
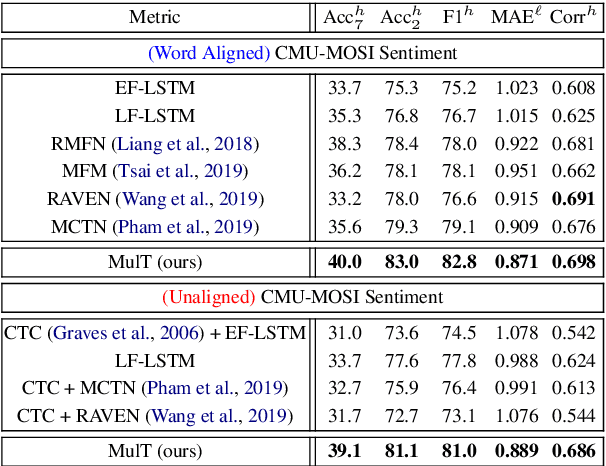
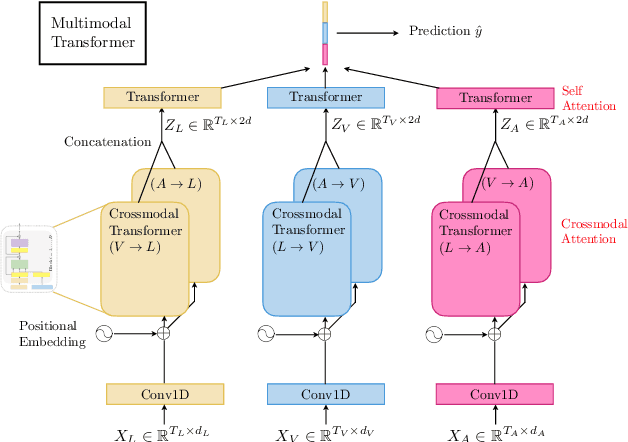
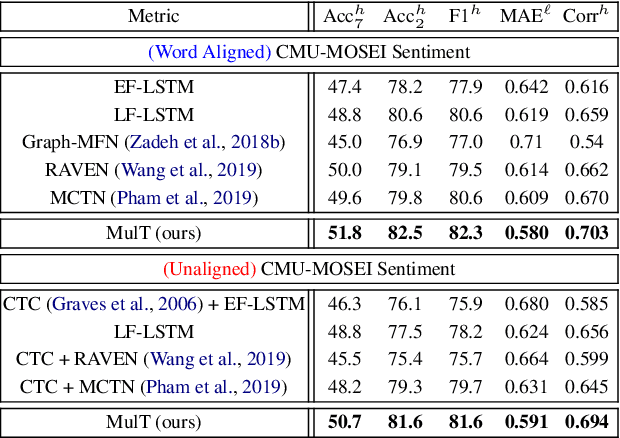
Human language is often multimodal, which comprehends a mixture of natural language, facial gestures, and acoustic behaviors. However, two major challenges in modeling such multimodal human language time-series data exist: 1) inherent data non-alignment due to variable sampling rates for the sequences from each modality; and 2) long-range dependencies between elements across modalities. In this paper, we introduce the Multimodal Transformer (MulT) to generically address the above issues in an end-to-end manner without explicitly aligning the data. At the heart of our model is the directional pairwise crossmodal attention, which attends to interactions between multimodal sequences across distinct time steps and latently adapt streams from one modality to another. Comprehensive experiments on both aligned and non-aligned multimodal time-series show that our model outperforms state-of-the-art methods by a large margin. In addition, empirical analysis suggests that correlated crossmodal signals are able to be captured by the proposed crossmodal attention mechanism in MulT.
Trellis Networks for Sequence Modeling
Oct 15, 2018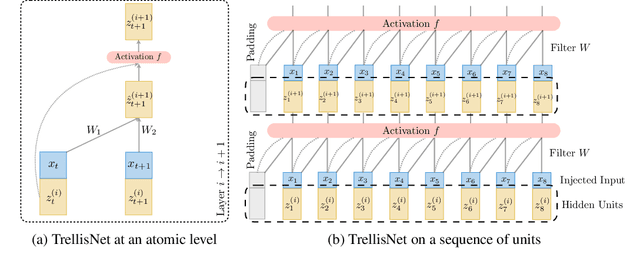
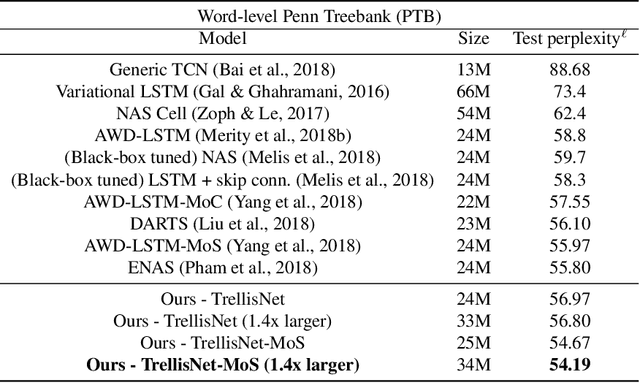
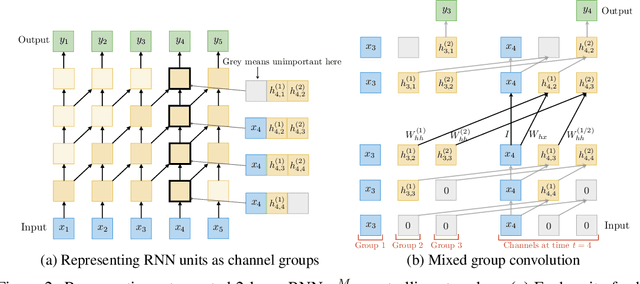
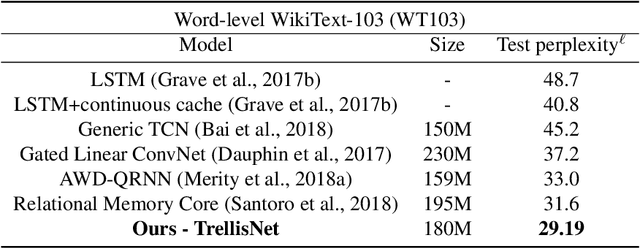
We present trellis networks, a new architecture for sequence modeling. On the one hand, a trellis network is a temporal convolutional network with special structure, characterized by weight tying across depth and direct injection of the input into deep layers. On the other hand, we show that truncated recurrent networks are equivalent to trellis networks with special sparsity structure in their weight matrices. Thus trellis networks with general weight matrices generalize truncated recurrent networks. We leverage these connections to design high-performing trellis networks that absorb structural and algorithmic elements from both recurrent and convolutional models. Experiments demonstrate that trellis networks outperform the current state of the art on a variety of challenging benchmarks, including word-level language modeling on Penn Treebank and WikiText-103, character-level language modeling on Penn Treebank, and stress tests designed to evaluate long-term memory retention. The code is available at https://github.com/locuslab/trellisnet .
An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling
Apr 19, 2018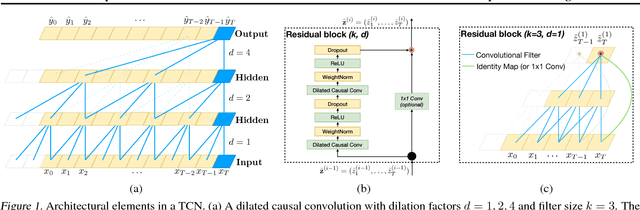
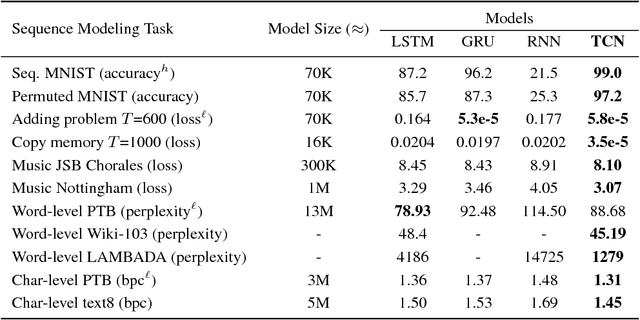
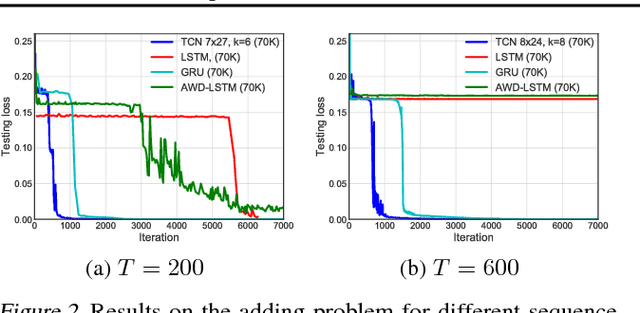
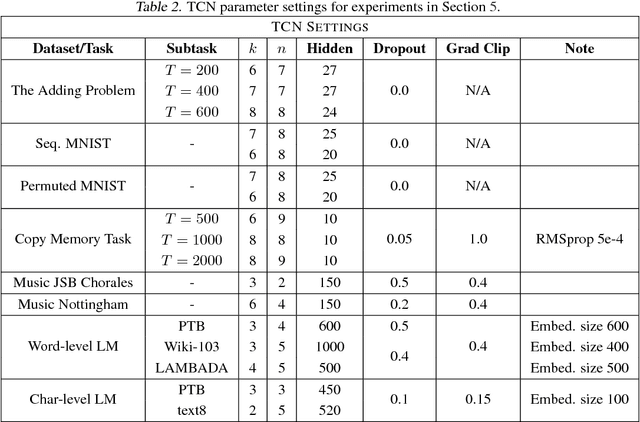
For most deep learning practitioners, sequence modeling is synonymous with recurrent networks. Yet recent results indicate that convolutional architectures can outperform recurrent networks on tasks such as audio synthesis and machine translation. Given a new sequence modeling task or dataset, which architecture should one use? We conduct a systematic evaluation of generic convolutional and recurrent architectures for sequence modeling. The models are evaluated across a broad range of standard tasks that are commonly used to benchmark recurrent networks. Our results indicate that a simple convolutional architecture outperforms canonical recurrent networks such as LSTMs across a diverse range of tasks and datasets, while demonstrating longer effective memory. We conclude that the common association between sequence modeling and recurrent networks should be reconsidered, and convolutional networks should be regarded as a natural starting point for sequence modeling tasks. To assist related work, we have made code available at http://github.com/locuslab/TCN .