 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised Semantic Segmentation by Iteratively Mining Common Object Features
Jun 12, 2018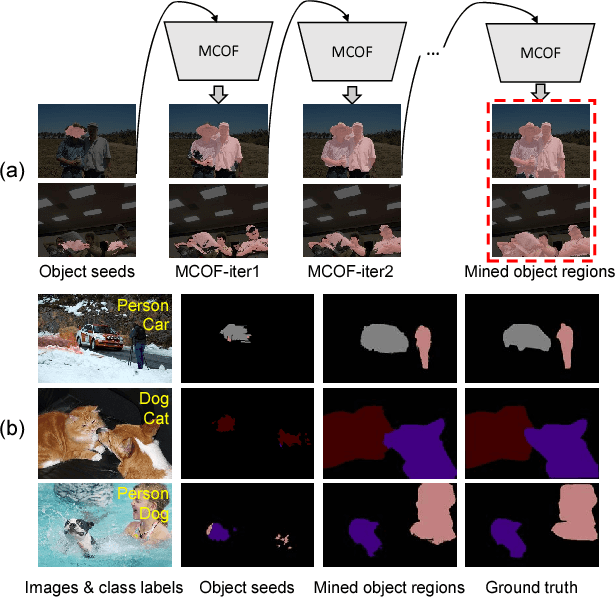
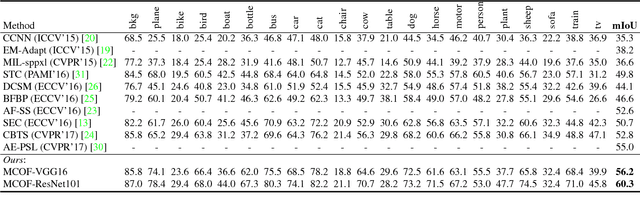
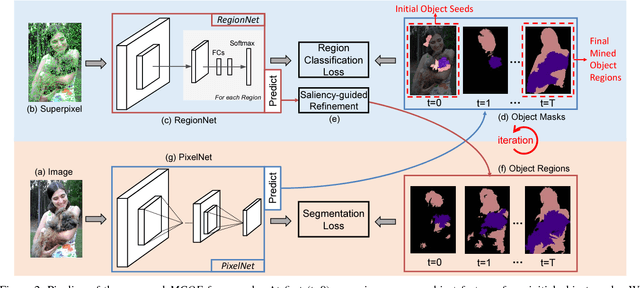
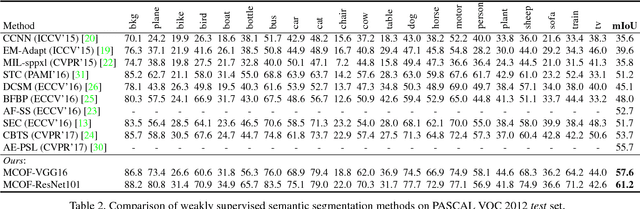
Weakly-supervised semantic segmentation under image tags supervision is a challenging task as it directly associates high-level semantic to low-level appearance. To bridge this gap, in this paper, we propose an iterative bottom-up and top-down framework which alternatively expands object regions and optimizes segmentation network. We start from initial localization produced by classification networks. While classification networks are only responsive to small and coarse discriminative object regions, we argue that, these regions contain significant common features about objects. So in the bottom-up step, we mine common object features from the initial localization and expand object regions with the mined features. To supplement non-discriminative regions, saliency maps are then considered under Bayesian framework to refine the object regions. Then in the top-down step, the refined object regions are used as supervision to train the segmentation network and to predict object masks. These object masks provide more accurate localization and contain more regions of object. Further, we take these object masks as initial localization and mine common object features from them. These processes are conducted iteratively to progressively produce fine object masks and optimize segmentation networks. Experimental results on Pascal VOC 2012 dataset demonstrate that the proposed method outperforms previous state-of-the-art methods by a large margin.
JTAV: Jointly Learning Social Media Content Representation by Fusing Textual, Acoustic, and Visual Features
Jun 05, 2018
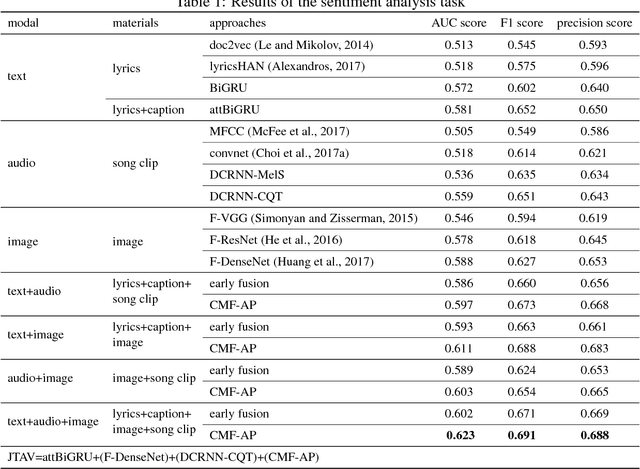
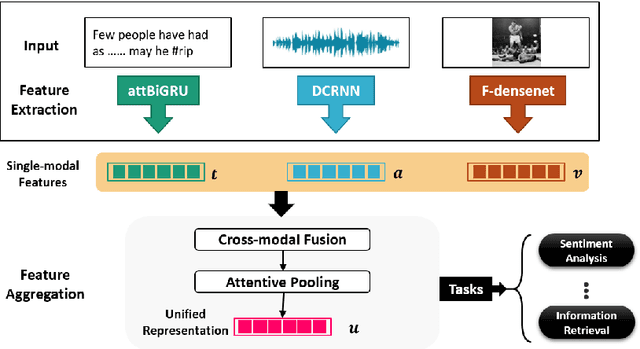
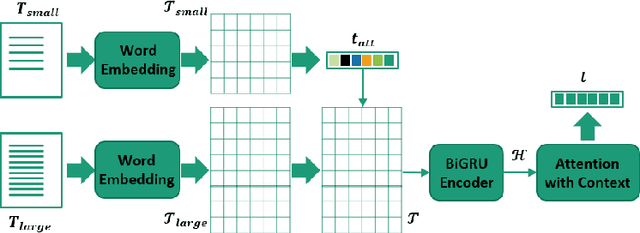
Learning social media content is the basis of many real-world applications, including information retrieval and recommendation systems, among others. In contrast with previous works that focus mainly on single modal or bi-modal learning, we propose to learn social media content by fusing jointly textual, acoustic, and visual information (JTAV). Effective strategies are proposed to extract fine-grained features of each modality, that is, attBiGRU and DCRNN. We also introduce cross-modal fusion and attentive pooling techniques to integrate multi-modal information comprehensively. Extensive experimental evaluation conducted on real-world datasets demonstrates our proposed model outperforms the state-of-the-art approaches by a large margin.
Differentiating Objects by Motion: Joint Detection and Tracking of Small Flying Objects
May 15, 2018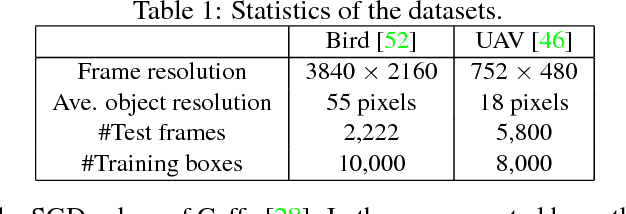
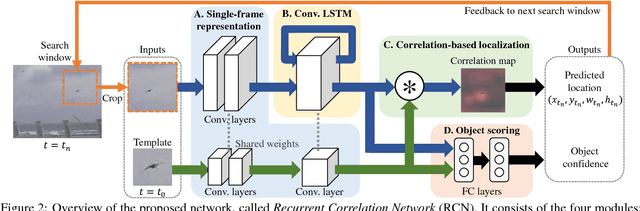
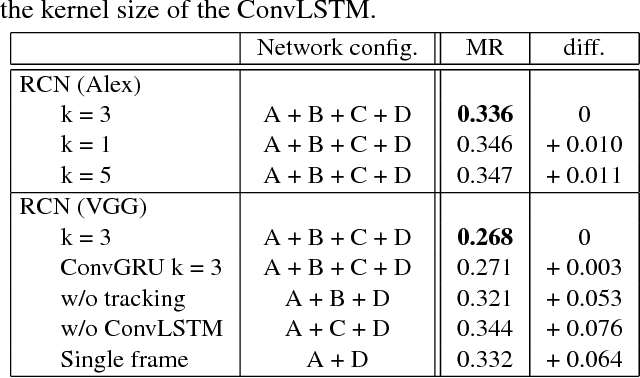
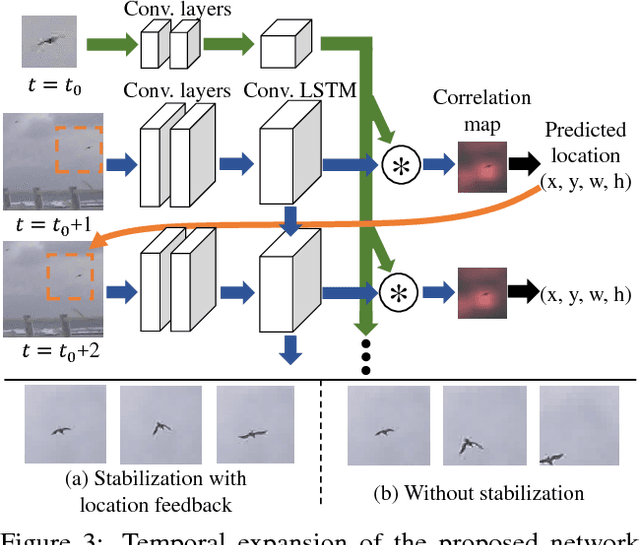
While generic object detection has achieved large improvements with rich feature hierarchies from deep nets, detecting small objects with poor visual cues remains challenging. Motion cues from multiple frames may be more informative for detecting such hard-to-distinguish objects in each frame. However, how to encode discriminative motion patterns, such as deformations and pose changes that characterize objects, has remained an open question. To learn them and thereby realize small object detection, we present a neural model called the Recurrent Correlational Network, where detection and tracking are jointly performed over a multi-frame representation learned through a single, trainable, and end-to-end network. A convolutional long short-term memory network is utilized for learning informative appearance change for detection, while learned representation is shared in tracking for enhancing its performance. In experiments with datasets containing images of scenes with small flying objects, such as birds and unmanned aerial vehicles, the proposed method yielded consistent improvements in detection performance over deep single-frame detectors and existing motion-based detectors. Furthermore, our network performs as well as state-of-the-art generic object trackers when it was evaluated as a tracker on the bird dataset.
Cross-connected Networks for Multi-task Learning of Detection and Segmentation
May 15, 2018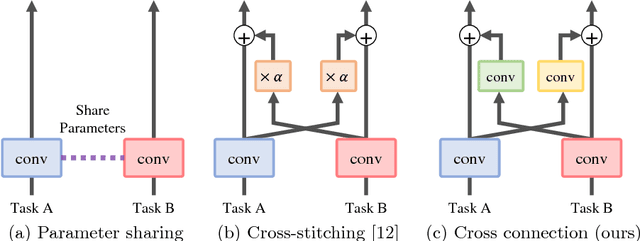

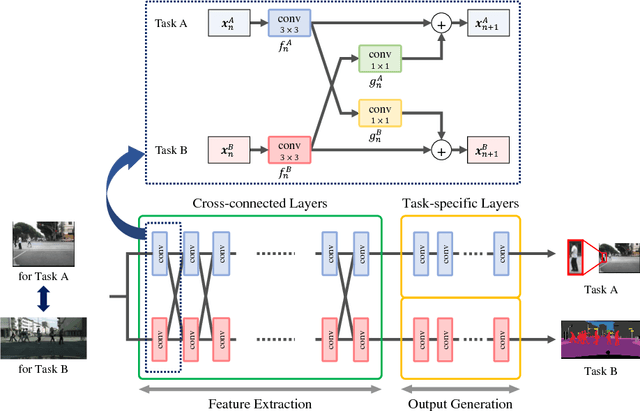
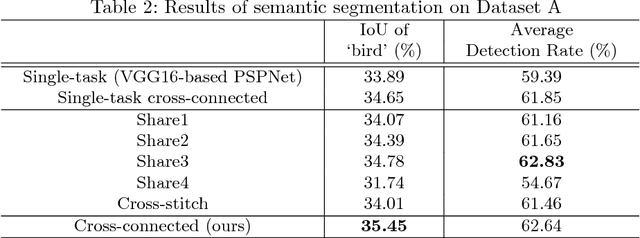
Multi-task learning improves generalization performance by sharing knowledge among related tasks. Existing models are for task combinations annotated on the same dataset, while there are cases where multiple datasets are available for each task. How to utilize knowledge of successful single-task CNNs that are trained on each dataset has been explored less than multi-task learning with a single dataset. We propose a cross-connected CNN, a new architecture that connects single-task CNNs through convolutional layers, which transfer useful information for the counterpart. We evaluated our proposed architecture on a combination of detection and segmentation using two datasets. Experiments on pedestrians show our CNN achieved a higher detection performance compared to baseline CNNs, while maintaining high quality for segmentation. It is the first known attempt to tackle multi-task learning with different training datasets between detection and segmentation. Experiments with wild birds demonstrate how our CNN learns general representations from limited datasets.
Deep Texture and Structure Aware Filtering Network for Image Smoothing
May 08, 2018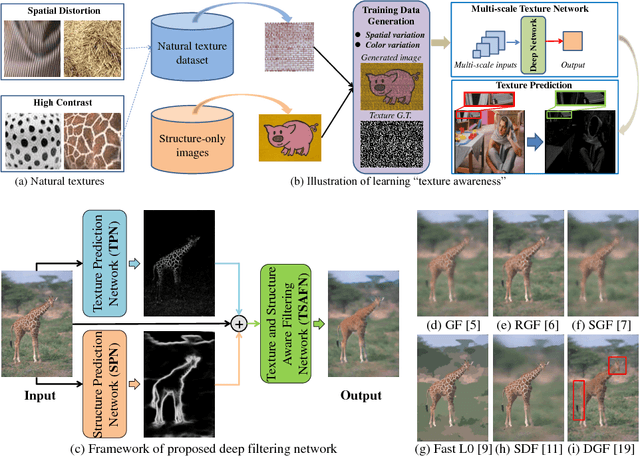
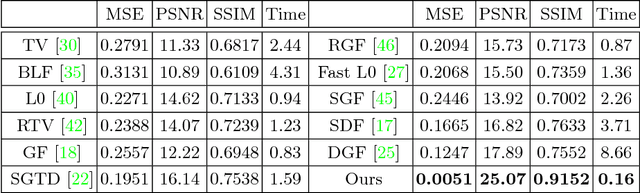
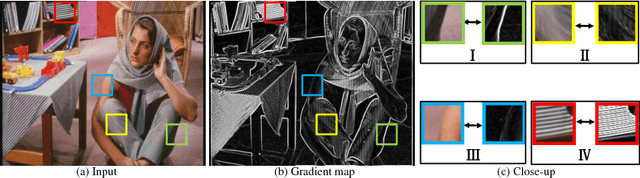

Image smoothing is a fundamental task in computer vision, that aims to retain salient structures and remove insignificant textures. In this paper, we aim to address the fundamental shortcomings of existing image smoothing methods, which cannot properly distinguish textures and structures with similar low-level appearance. While deep learning approaches have started to explore the preservation of structure through image smoothing, existing work does not yet properly address textures. To this end, we generate a large dataset by blending natural textures with clean structure-only images, and then build a texture prediction network (TPN) that predicts the location and magnitude of textures. We then combine the TPN with a semantic structure prediction network (SPN) so that the final texture and structure aware filtering network (TSAFN) is able to identify the textures to remove ("texture-awareness") and the structures to preserve ("structure-awareness"). The proposed model is easy to understand and implement, and shows excellent performance on real images in the wild as well as our generated dataset.
Semantic Single-Image Dehazing
Apr 18, 2018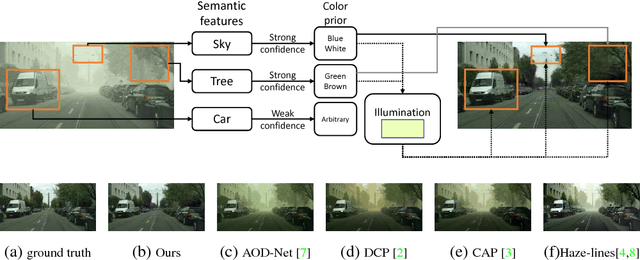


Single-image haze-removal is challenging due to limited information contained in one single image. Previous solutions largely rely on handcrafted priors to compensate for this deficiency. Recent convolutional neural network (CNN) models have been used to learn haze-related priors but they ultimately work as advanced image filters. In this paper we propose a novel semantic ap- proach towards single image haze removal. Unlike existing methods, we infer color priors based on extracted semantic features. We argue that semantic context can be exploited to give informative cues for (a) learning color prior on clean image and (b) estimating ambient illumination. This design allowed our model to recover clean images from challenging cases with strong ambiguity, e.g. saturated illumination color and sky regions in image. In experiments, we validate our ap- proach upon synthetic and real hazy images, where our method showed superior performance over state-of-the-art approaches, suggesting semantic information facilitates the haze removal task.
A Frequency Domain Neural Network for Fast Image Super-resolution
Dec 08, 2017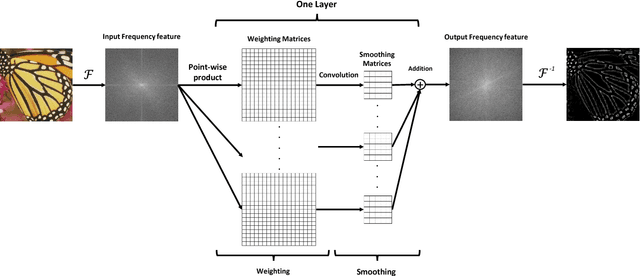
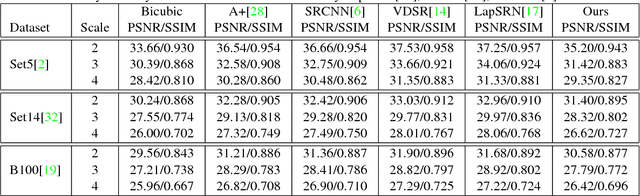
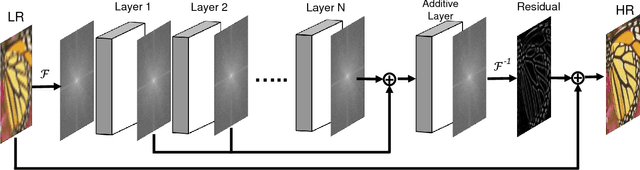
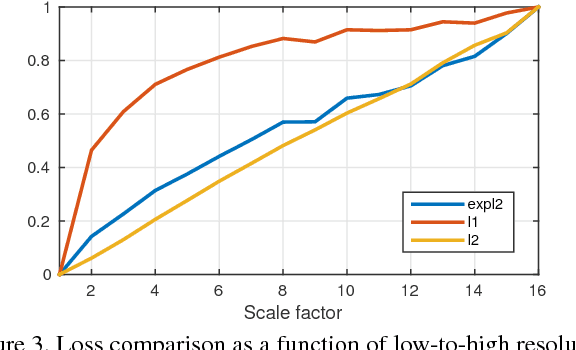
In this paper, we present a frequency domain neural network for image super-resolution. The network employs the convolution theorem so as to cast convolutions in the spatial domain as products in the frequency domain. Moreover, the non-linearity in deep nets, often achieved by a rectifier unit, is here cast as a convolution in the frequency domain. This not only yields a network which is very computationally efficient at testing but also one whose parameters can all be learnt accordingly. The network can be trained using back propagation and is devoid of complex numbers due to the use of the Hartley transform as an alternative to the Fourier transform. Moreover, the network is potentially applicable to other problems elsewhere in computer vision and image processing which are often cast in the frequency domain. We show results on super-resolution and compare against alternatives elsewhere in the literature. In our experiments, our network is one to two orders of magnitude faster than the alternatives with an imperceptible loss of performance.
Edge Preserving and Multi-Scale Contextual Neural Network for Salient Object Detection
Sep 22, 2017
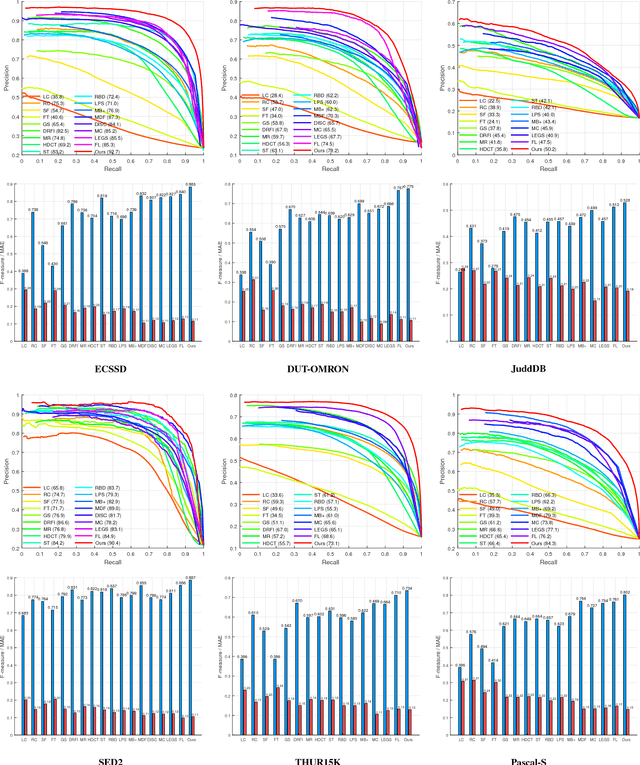

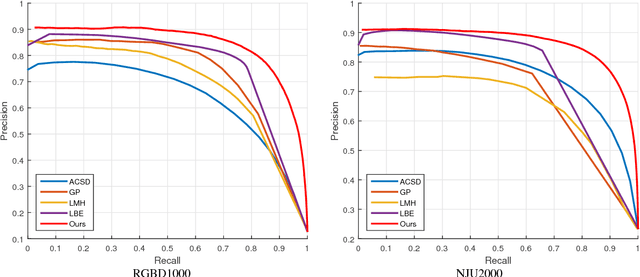
In this paper, we propose a novel edge preserving and multi-scale contextual neural network for salient object detection. The proposed framework is aiming to address two limits of the existing CNN based methods. First, region-based CNN methods lack sufficient context to accurately locate salient object since they deal with each region independently. Second, pixel-based CNN methods suffer from blurry boundaries due to the presence of convolutional and pooling layers. Motivated by these, we first propose an end-to-end edge-preserved neural network based on Fast R-CNN framework (named RegionNet) to efficiently generate saliency map with sharp object boundaries. Later, to further improve it, multi-scale spatial context is attached to RegionNet to consider the relationship between regions and the global scenes. Furthermore, our method can be generally applied to RGB-D saliency detection by depth refinement. The proposed framework achieves both clear detection boundary and multi-scale contextual robustness simultaneously for the first time, and thus achieves an optimized performance. Experiments on six RGB and two RGB-D benchmark datasets demonstrate that the proposed method achieves state-of-the-art performance.
Automatic Generation of Grounded Visual Questions
May 29, 2017
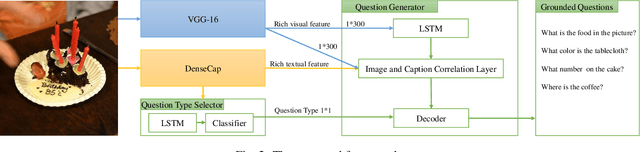


In this paper, we propose the first model to be able to generate visually grounded questions with diverse types for a single image. Visual question generation is an emerging topic which aims to ask questions in natural language based on visual input. To the best of our knowledge, it lacks automatic methods to generate meaningful questions with various types for the same visual input. To circumvent the problem, we propose a model that automatically generates visually grounded questions with varying types. Our model takes as input both images and the captions generated by a dense caption model, samples the most probable question types, and generates the questions in sequel. The experimental results on two real world datasets show that our model outperforms the strongest baseline in terms of both correctness and diversity with a wide margin.
* VQA
Learning RGB-D Salient Object Detection using background enclosure, depth contrast, and top-down features
May 10, 2017
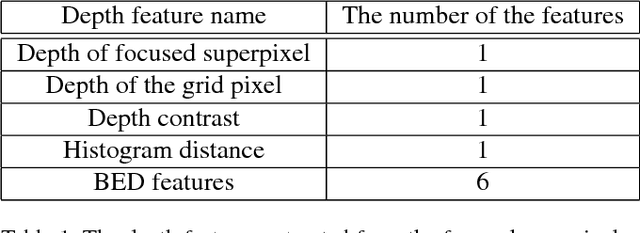
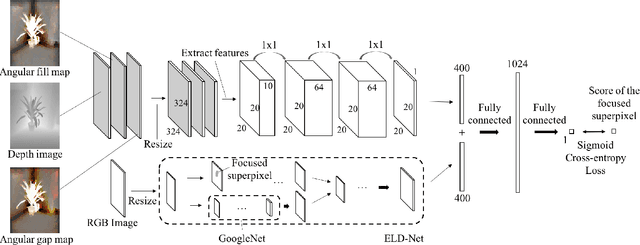
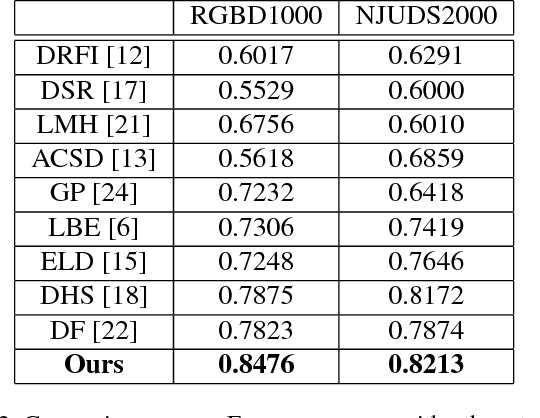
Recently, deep Convolutional Neural Networks (CNN) have demonstrated strong performance on RGB salient object detection. Although, depth information can help improve detection results, the exploration of CNNs for RGB-D salient object detection remains limited. Here we propose a novel deep CNN architecture for RGB-D salient object detection that exploits high-level, mid-level, and low level features. Further, we present novel depth features that capture the ideas of background enclosure and depth contrast that are suitable for a learned approach. We show improved results compared to state-of-the-art RGB-D salient object detection methods. We also show that the low-level and mid-level depth features both contribute to improvements in the results. Especially, F-Score of our method is 0.848 on RGBD1000 dataset, which is 10.7% better than the second place.