 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Before You Lie: How Reasoning Leads to Honesty
Mar 16, 2026While existing evaluations of large language models (LLMs) measure deception rates, the underlying conditions that give rise to deceptive behavior are poorly understood. We investigate this question using a novel dataset of realistic moral trade-offs where honesty incurs variable costs. Contrary to humans, who tend to become less honest given time to deliberate (Capraro, 2017; Capraro et al., 2019), we find that reasoning consistently increases honesty across scales and for several LLM families. This effect is not only a function of the reasoning content, as reasoning traces are often poor predictors of final behaviors. Rather, we show that the underlying geometry of the representational space itself contributes to the effect. Namely, we observe that deceptive regions within this space are metastable: deceptive answers are more easily destabilized by input paraphrasing, output resampling, and activation noise than honest ones. We interpret the effect of reasoning in this vein: generating deliberative tokens as part of moral reasoning entails the traversal of a biased representational space, ultimately nudging the model toward its more stable, honest defaults.
Think Before You Lie: How Reasoning Improves Honesty
Mar 10, 2026While existing evaluations of large language models (LLMs) measure deception rates, the underlying conditions that give rise to deceptive behavior are poorly understood. We investigate this question using a novel dataset of realistic moral trade-offs where honesty incurs variable costs. Contrary to humans, who tend to become less honest given time to deliberate (Capraro, 2017; Capraro et al., 2019), we find that reasoning consistently increases honesty across scales and for several LLM families. This effect is not only a function of the reasoning content, as reasoning traces are often poor predictors of final behaviors. Rather, we show that the underlying geometry of the representational space itself contributes to the effect. Namely, we observe that deceptive regions within this space are metastable: deceptive answers are more easily destabilized by input paraphrasing, output resampling, and activation noise than honest ones. We interpret the effect of reasoning in this vein: generating deliberative tokens as part of moral reasoning entails the traversal of a biased representational space, ultimately nudging the model toward its more stable, honest defaults.
On Mitigating Affinity Bias through Bandits with Evolving Biased Feedback
Mar 07, 2025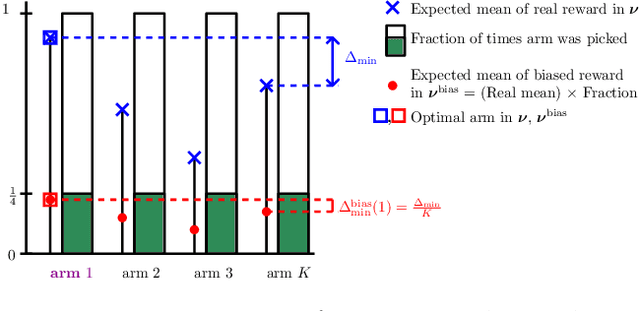

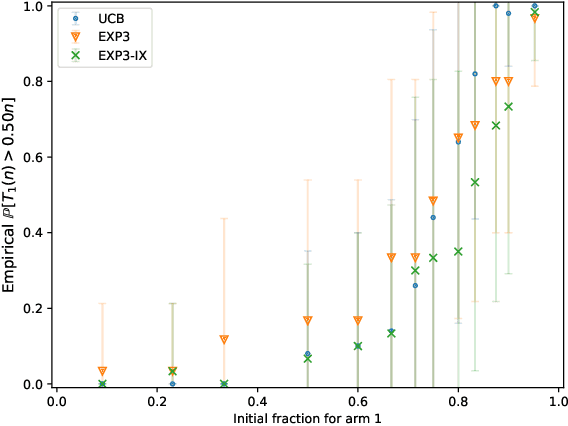
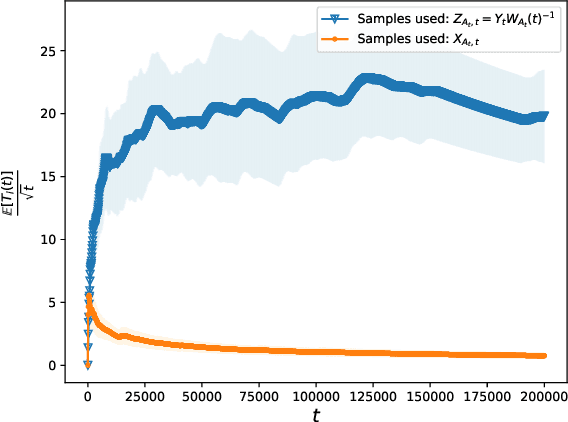
Unconscious bias has been shown to influence how we assess our peers, with consequences for hiring, promotions and admissions. In this work, we focus on affinity bias, the component of unconscious bias which leads us to prefer people who are similar to us, despite no deliberate intention of favoritism. In a world where the people hired today become part of the hiring committee of tomorrow, we are particularly interested in understanding (and mitigating) how affinity bias affects this feedback loop. This problem has two distinctive features: 1) we only observe the biased value of a candidate, but we want to optimize with respect to their real value 2) the bias towards a candidate with a specific set of traits depends on the fraction of people in the hiring committee with the same set of traits. We introduce a new bandits variant that exhibits those two features, which we call affinity bandits. Unsurprisingly, classical algorithms such as UCB often fail to identify the best arm in this setting. We prove a new instance-dependent regret lower bound, which is larger than that in the standard bandit setting by a multiplicative function of $K$. Since we treat rewards that are time-varying and dependent on the policy's past actions, deriving this lower bound requires developing proof techniques beyond the standard bandit techniques. Finally, we design an elimination-style algorithm which nearly matches this regret, despite never observing the real rewards.
Improving Neutral Point of View Text Generation through Parameter-Efficient Reinforcement Learning and a Small-Scale High-Quality Dataset
Mar 05, 2025This paper describes the construction of a dataset and the evaluation of training methods to improve generative large language models' (LLMs) ability to answer queries on sensitive topics with a Neutral Point of View (NPOV), i.e., to provide significantly more informative, diverse and impartial answers. The dataset, the SHQ-NPOV dataset, comprises 300 high-quality, human-written quadruplets: a query on a sensitive topic, an answer, an NPOV rating, and a set of links to source texts elaborating the various points of view. The first key contribution of this paper is a new methodology to create such datasets through iterative rounds of human peer-critique and annotator training, which we release alongside the dataset. The second key contribution is the identification of a highly effective training regime for parameter-efficient reinforcement learning (PE-RL) to improve NPOV generation. We compare and extensively evaluate PE-RL and multiple baselines-including LoRA finetuning (a strong baseline), SFT and RLHF. PE-RL not only improves on overall NPOV quality compared to the strongest baseline ($97.06\%\rightarrow 99.08\%$), but also scores much higher on features linguists identify as key to separating good answers from the best answers ($60.25\%\rightarrow 85.21\%$ for presence of supportive details, $68.74\%\rightarrow 91.43\%$ for absence of oversimplification). A qualitative analysis corroborates this. Finally, our evaluation finds no statistical differences between results on topics that appear in the training dataset and those on separated evaluation topics, which provides strong evidence that our approach to training PE-RL exhibits very effective out of topic generalization.
PERL: Parameter Efficient Reinforcement Learning from Human Feedback
Mar 15, 2024



Reinforcement Learning from Human Feedback (RLHF) has proven to be a strong method to align Pretrained Large Language Models (LLMs) with human preferences. But training models with RLHF is computationally expensive, and an overall complex process. In this work, we study RLHF where the underlying models are trained using the parameter efficient method of Low-Rank Adaptation (LoRA) introduced by Hu et al. [2021]. We investigate the setup of "Parameter Efficient Reinforcement Learning" (PERL), in which we perform reward model training and reinforcement learning using LoRA. We compare PERL to conventional fine-tuning (full-tuning) across various configurations for 7 benchmarks, including 2 novel datasets, of reward modeling and reinforcement learning. We find that PERL performs on par with the conventional RLHF setting, while training faster, and with less memory. This enables the high performance of RLHF, while reducing the computational burden that limits its adoption as an alignment technique for Large Language Models. We also release 2 novel thumbs up/down preference datasets: "Taskmaster Coffee", and "Taskmaster Ticketing" to promote research around RLHF.
Detecting Hallucination and Coverage Errors in Retrieval Augmented Generation for Controversial Topics
Mar 13, 2024



We explore a strategy to handle controversial topics in LLM-based chatbots based on Wikipedia's Neutral Point of View (NPOV) principle: acknowledge the absence of a single true answer and surface multiple perspectives. We frame this as retrieval augmented generation, where perspectives are retrieved from a knowledge base and the LLM is tasked with generating a fluent and faithful response from the given perspectives. As a starting point, we use a deterministic retrieval system and then focus on common LLM failure modes that arise during this approach to text generation, namely hallucination and coverage errors. We propose and evaluate three methods to detect such errors based on (1) word-overlap, (2) salience, and (3) LLM-based classifiers. Our results demonstrate that LLM-based classifiers, even when trained only on synthetic errors, achieve high error detection performance, with ROC AUC scores of 95.3% for hallucination and 90.5% for coverage error detection on unambiguous error cases. We show that when no training data is available, our other methods still yield good results on hallucination (84.0%) and coverage error (85.2%) detection.
Decoding-time Realignment of Language Models
Feb 05, 2024Aligning language models with human preferences is crucial for reducing errors and biases in these models. Alignment techniques, such as reinforcement learning from human feedback (RLHF), are typically cast as optimizing a tradeoff between human preference rewards and a proximity regularization term that encourages staying close to the unaligned model. Selecting an appropriate level of regularization is critical: insufficient regularization can lead to reduced model capabilities due to reward hacking, whereas excessive regularization hinders alignment. Traditional methods for finding the optimal regularization level require retraining multiple models with varying regularization strengths. This process, however, is resource-intensive, especially for large models. To address this challenge, we propose decoding-time realignment (DeRa), a simple method to explore and evaluate different regularization strengths in aligned models without retraining. DeRa enables control over the degree of alignment, allowing users to smoothly transition between unaligned and aligned models. It also enhances the efficiency of hyperparameter tuning by enabling the identification of effective regularization strengths using a validation dataset.
Towards Agile Text Classifiers for Everyone
Feb 13, 2023



Text-based safety classifiers are widely used for content moderation and increasingly to tune generative language model behavior - a topic of growing concern for the safety of digital assistants and chatbots. However, different policies require different classifiers, and safety policies themselves improve from iteration and adaptation. This paper introduces and evaluates methods for agile text classification, whereby classifiers are trained using small, targeted datasets that can be quickly developed for a particular policy. Experimenting with 7 datasets from three safety-related domains, comprising 15 annotation schemes, led to our key finding: prompt-tuning large language models, like PaLM 62B, with a labeled dataset of as few as 80 examples can achieve state-of-the-art performance. We argue that this enables a paradigm shift for text classification, especially for models supporting safer online discourse. Instead of collecting millions of examples to attempt to create universal safety classifiers over months or years, classifiers could be tuned using small datasets, created by individuals or small organizations, tailored for specific use cases, and iterated on and adapted in the time-span of a day.
Fairness for Image Generation with Uncertain Sensitive Attributes
Jul 02, 2021
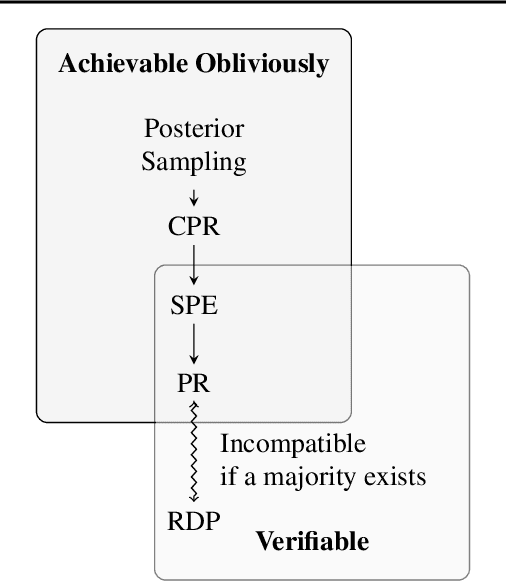
This work tackles the issue of fairness in the context of generative procedures, such as image super-resolution, which entail different definitions from the standard classification setting. Moreover, while traditional group fairness definitions are typically defined with respect to specified protected groups -- camouflaging the fact that these groupings are artificial and carry historical and political motivations -- we emphasize that there are no ground truth identities. For instance, should South and East Asians be viewed as a single group or separate groups? Should we consider one race as a whole or further split by gender? Choosing which groups are valid and who belongs in them is an impossible dilemma and being "fair" with respect to Asians may require being "unfair" with respect to South Asians. This motivates the introduction of definitions that allow algorithms to be \emph{oblivious} to the relevant groupings. We define several intuitive notions of group fairness and study their incompatibilities and trade-offs. We show that the natural extension of demographic parity is strongly dependent on the grouping, and \emph{impossible} to achieve obliviously. On the other hand, the conceptually new definition we introduce, Conditional Proportional Representation, can be achieved obliviously through Posterior Sampling. Our experiments validate our theoretical results and achieve fair image reconstruction using state-of-the-art generative models.
Adversarial Graph Embeddings for Fair Influence Maximization over Social Networks
May 11, 2020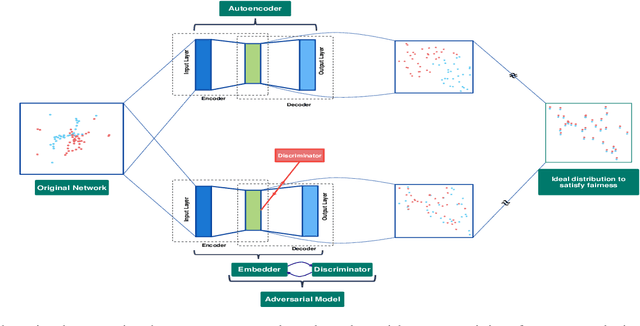
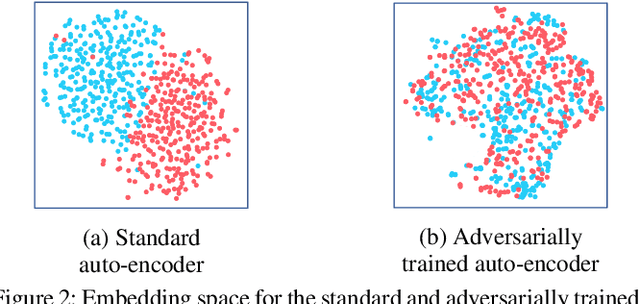
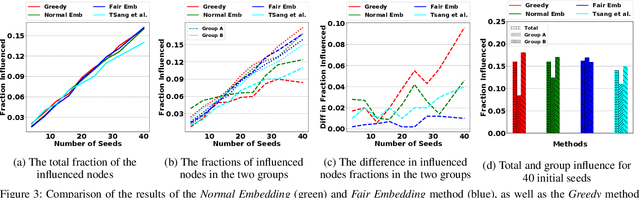
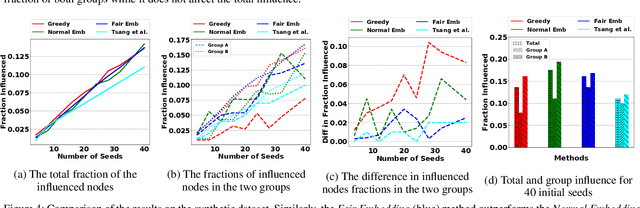
Influence maximization is a widely studied topic in network science, where the aim is to reach the maximum possible number of nodes, while only targeting a small initial set of individuals. It has critical applications in many fields, including viral marketing, information propagation, news dissemination, and vaccinations. However, the objective does not usually take into account whether the final set of influenced nodes is fair with respect to sensitive attributes, such as race or gender. Here we address fair influence maximization, aiming to reach minorities more equitably. We introduce Adversarial Graph Embeddings: we co-train an auto-encoder for graph embedding and a discriminator to discern sensitive attributes. This leads to embeddings which are similarly distributed across sensitive attributes. We then find a good initial set by clustering the embeddings. We believe we are the first to use embeddings for the task of fair influence maximization. While there are typically trade-offs between fairness and influence maximization objectives, our experiments on synthetic and real-world datasets show that our approach dramatically reduces disparity while remaining competitive with state-of-the-art influence maximization methods.