 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Incentives that Shape Behaviour
Jan 20, 2020

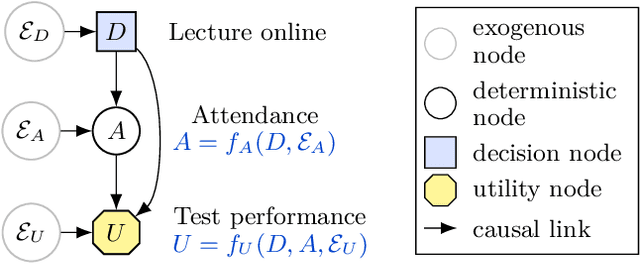
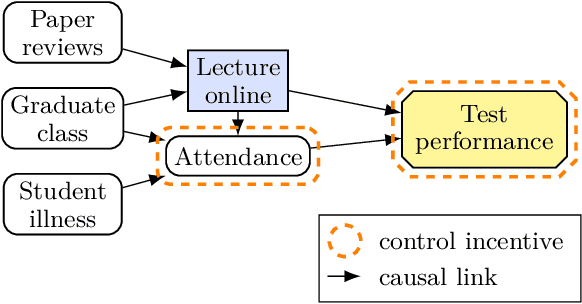
Which variables does an agent have an incentive to control with its decision, and which variables does it have an incentive to respond to? We formalise these incentives, and demonstrate unique graphical criteria for detecting them in any single decision causal influence diagram. To this end, we introduce structural causal influence models, a hybrid of the influence diagram and structural causal model frameworks. Finally, we illustrate how these incentives predict agent incentives in both fairness and AI safety applications.
Learning Human Objectives by Evaluating Hypothetical Behavior
Dec 05, 2019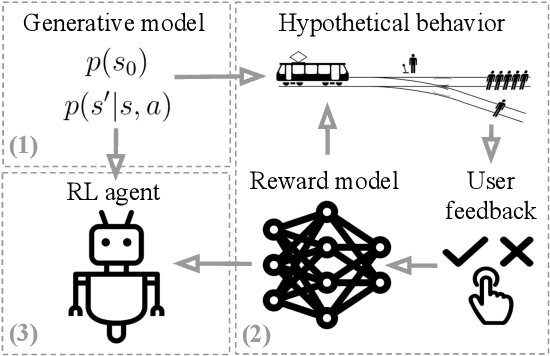
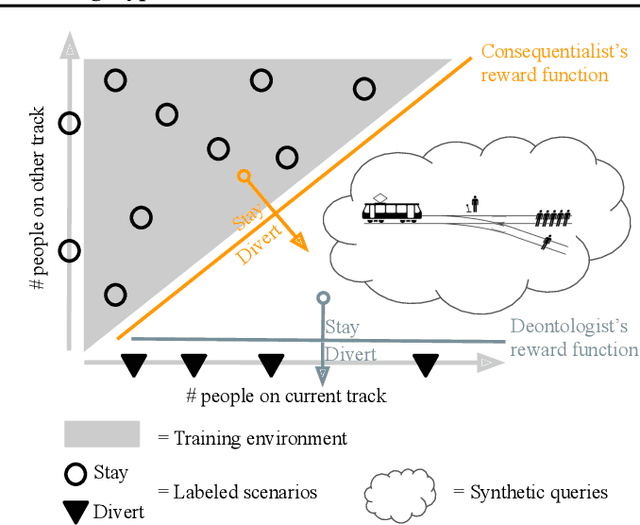
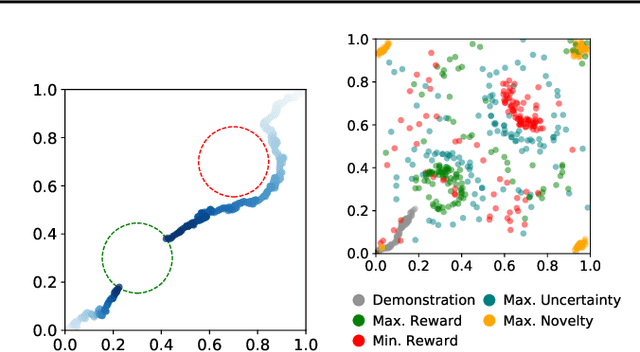
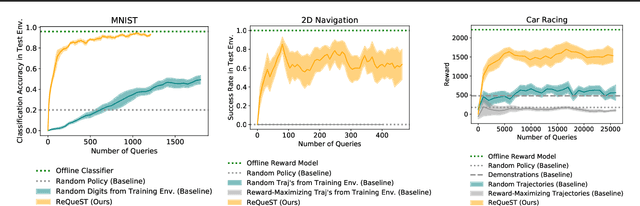
We seek to align agent behavior with a user's objectives in a reinforcement learning setting with unknown dynamics, an unknown reward function, and unknown unsafe states. The user knows the rewards and unsafe states, but querying the user is expensive. To address this challenge, we propose an algorithm that safely and interactively learns a model of the user's reward function. We start with a generative model of initial states and a forward dynamics model trained on off-policy data. Our method uses these models to synthesize hypothetical behaviors, asks the user to label the behaviors with rewards, and trains a neural network to predict the rewards. The key idea is to actively synthesize the hypothetical behaviors from scratch by maximizing tractable proxies for the value of information, without interacting with the environment. We call this method reward query synthesis via trajectory optimization (ReQueST). We evaluate ReQueST with simulated users on a state-based 2D navigation task and the image-based Car Racing video game. The results show that ReQueST significantly outperforms prior methods in learning reward models that transfer to new environments with different initial state distributions. Moreover, ReQueST safely trains the reward model to detect unsafe states, and corrects reward hacking before deploying the agent.
Modeling AGI Safety Frameworks with Causal Influence Diagrams
Jun 20, 2019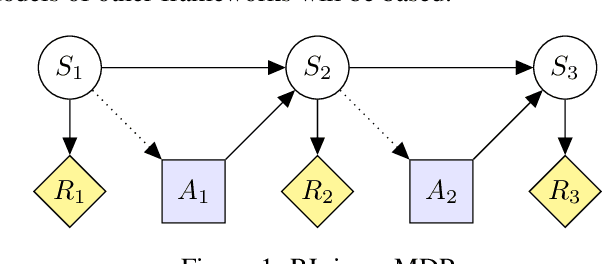
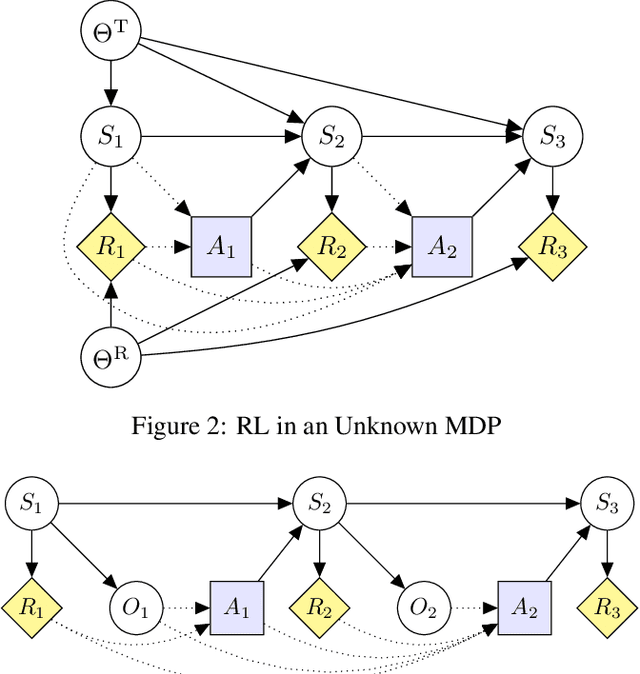
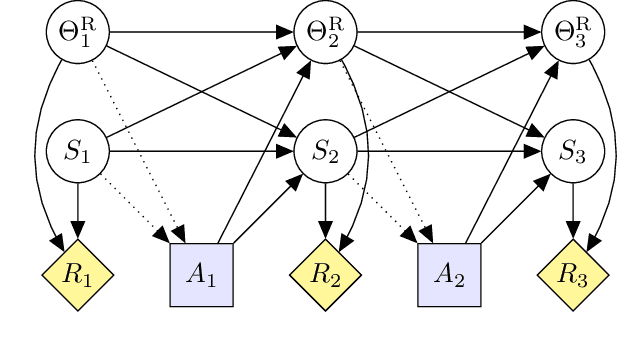
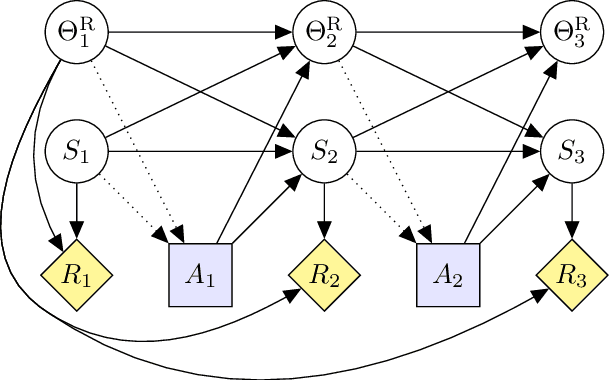
Proposals for safe AGI systems are typically made at the level of frameworks, specifying how the components of the proposed system should be trained and interact with each other. In this paper, we model and compare the most promising AGI safety frameworks using causal influence diagrams. The diagrams show the optimization objective and causal assumptions of the framework. The unified representation permits easy comparison of frameworks and their assumptions. We hope that the diagrams will serve as an accessible and visual introduction to the main AGI safety frameworks.
Meta-learning of Sequential Strategies
May 08, 2019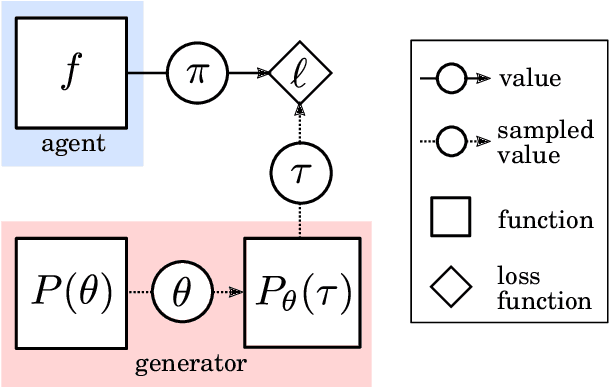
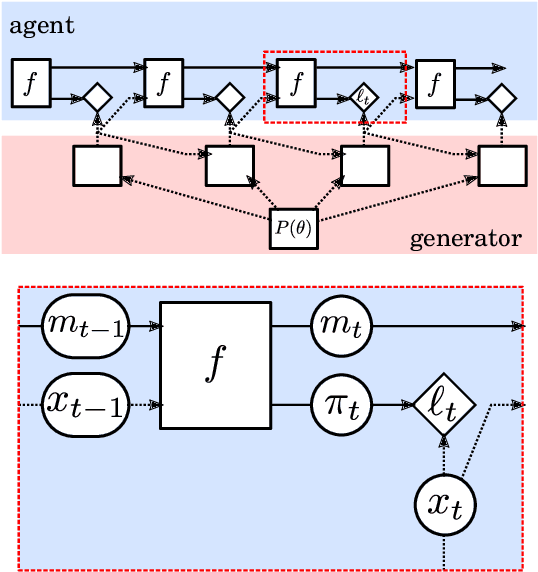
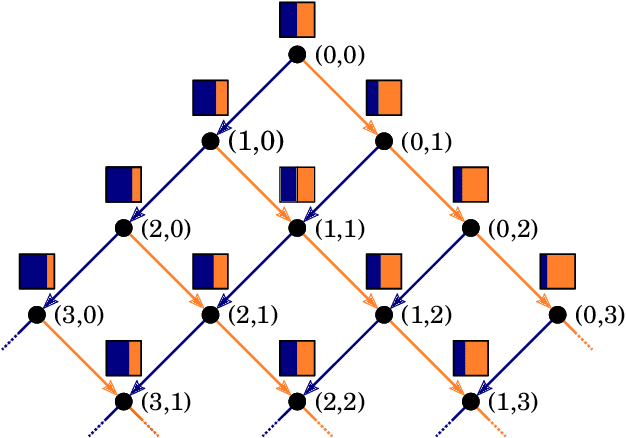
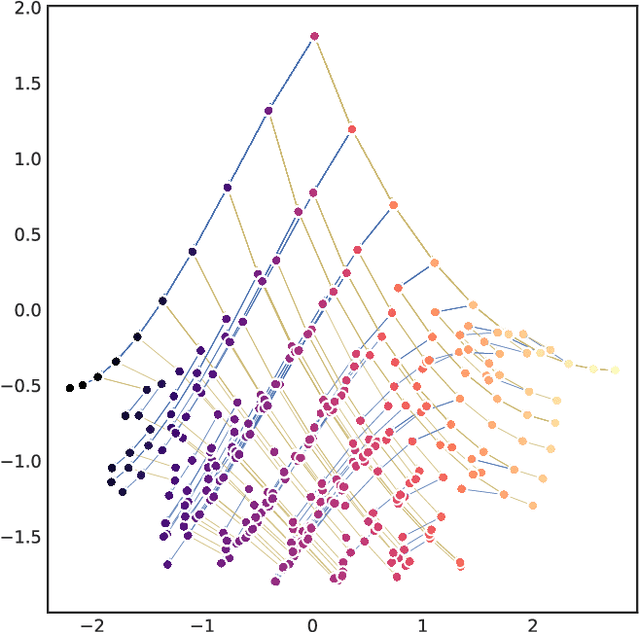
In this report we review memory-based meta-learning as a tool for building sample-efficient strategies that learn from past experience to adapt to any task within a target class. Our goal is to equip the reader with the conceptual foundations of this tool for building new, scalable agents that operate on broad domains. To do so, we present basic algorithmic templates for building near-optimal predictors and reinforcement learners which behave as if they had a probabilistic model that allowed them to efficiently exploit task structure. Furthermore, we recast memory-based meta-learning within a Bayesian framework, showing that the meta-learned strategies are near-optimal because they amortize Bayes-filtered data, where the adaptation is implemented in the memory dynamics as a state-machine of sufficient statistics. Essentially, memory-based meta-learning translates the hard problem of probabilistic sequential inference into a regression problem.
Understanding Agent Incentives using Causal Influence Diagrams. Part I: Single Action Settings
Mar 12, 2019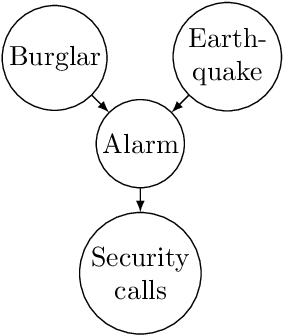

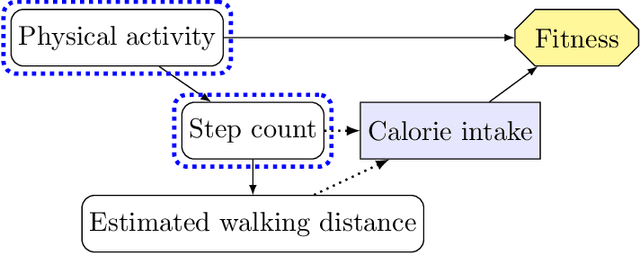
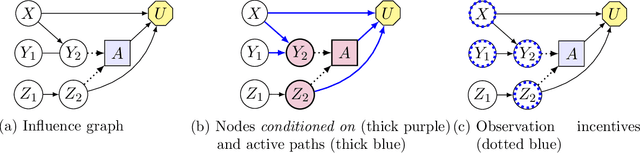
Agents are systems that optimize an objective function in an environment. Together, the goal and the environment induce secondary objectives, incentives. Modeling the agent-environment interaction in graphical models called influence diagrams, we can answer two fundamental questions about an agent's incentives directly from the graph: (1) which nodes is the agent incentivized to observe, and (2) which nodes is the agent incentivized to influence? The answers tell us which information and influence points need extra protection. For example, we may want a classifier for job applications to not use the ethnicity of the candidate, and a reinforcement learning agent not to take direct control of its reward mechanism. Different algorithms and training paradigms can lead to different influence diagrams, so our method can be used to identify algorithms with problematic incentives and help in designing algorithms with better incentives.
Soft-Bayes: Prod for Mixtures of Experts with Log-Loss
Jan 08, 2019We consider prediction with expert advice under the log-loss with the goal of deriving efficient and robust algorithms. We argue that existing algorithms such as exponentiated gradient, online gradient descent and online Newton step do not adequately satisfy both requirements. Our main contribution is an analysis of the Prod algorithm that is robust to any data sequence and runs in linear time relative to the number of experts in each round. Despite the unbounded nature of the log-loss, we derive a bound that is independent of the largest loss and of the largest gradient, and depends only on the number of experts and the time horizon. Furthermore we give a Bayesian interpretation of Prod and adapt the algorithm to derive a tracking regret.
Scaling shared model governance via model splitting
Dec 14, 2018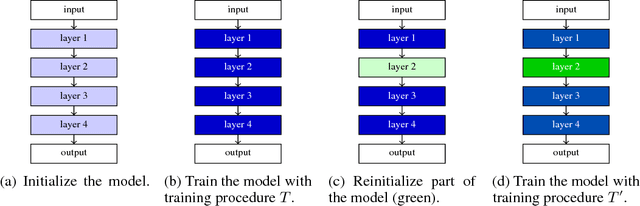

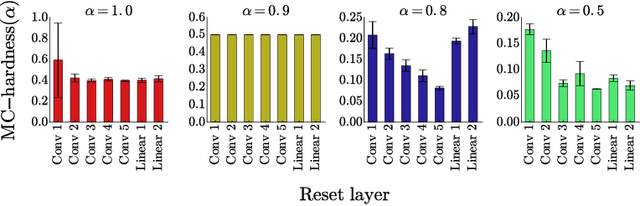

Currently the only techniques for sharing governance of a deep learning model are homomorphic encryption and secure multiparty computation. Unfortunately, neither of these techniques is applicable to the training of large neural networks due to their large computational and communication overheads. As a scalable technique for shared model governance, we propose splitting deep learning model between multiple parties. This paper empirically investigates the security guarantee of this technique, which is introduced as the problem of model completion: Given the entire training data set or an environment simulator, and a subset of the parameters of a trained deep learning model, how much training is required to recover the model's original performance? We define a metric for evaluating the hardness of the model completion problem and study it empirically in both supervised learning on ImageNet and reinforcement learning on Atari and DeepMind~Lab. Our experiments show that (1) the model completion problem is harder in reinforcement learning than in supervised learning because of the unavailability of the trained agent's trajectories, and (2) its hardness depends not primarily on the number of parameters of the missing part, but more so on their type and location. Our results suggest that model splitting might be a feasible technique for shared model governance in some settings where training is very expensive.
Scalable agent alignment via reward modeling: a research direction
Nov 19, 2018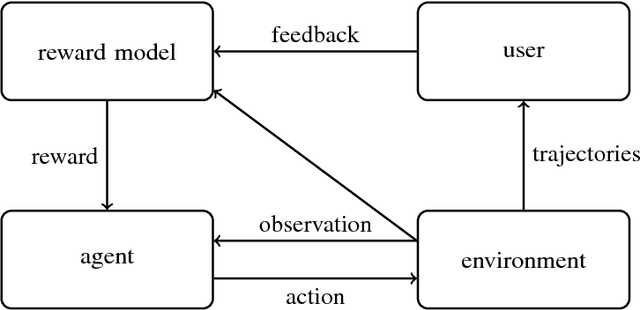
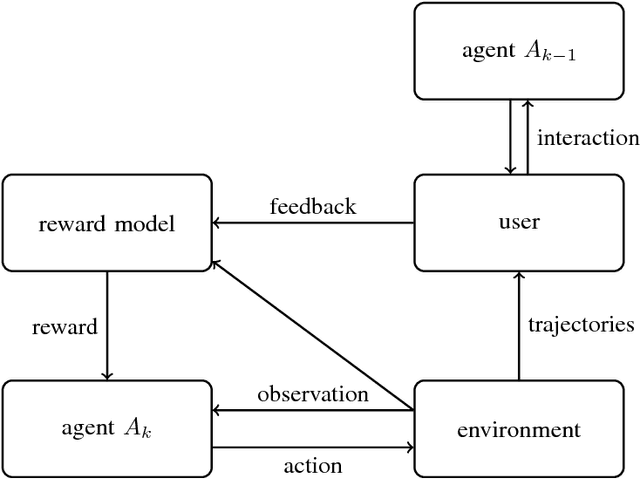

One obstacle to applying reinforcement learning algorithms to real-world problems is the lack of suitable reward functions. Designing such reward functions is difficult in part because the user only has an implicit understanding of the task objective. This gives rise to the agent alignment problem: how do we create agents that behave in accordance with the user's intentions? We outline a high-level research direction to solve the agent alignment problem centered around reward modeling: learning a reward function from interaction with the user and optimizing the learned reward function with reinforcement learning. We discuss the key challenges we expect to face when scaling reward modeling to complex and general domains, concrete approaches to mitigate these challenges, and ways to establish trust in the resulting agents.
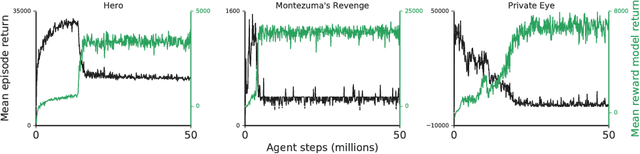
Reward learning from human preferences and demonstrations in Atari
Nov 15, 2018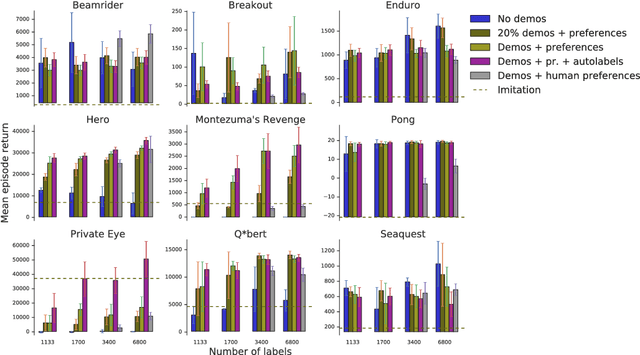
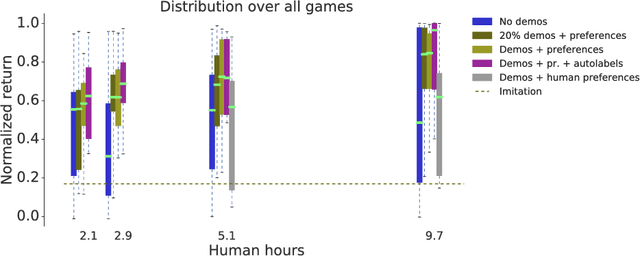
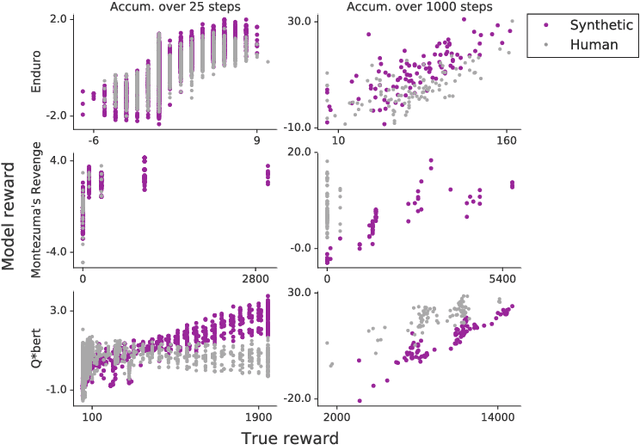
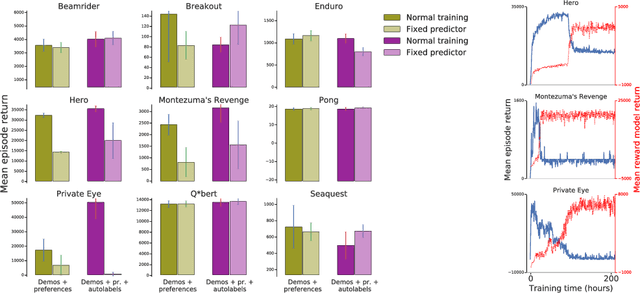
To solve complex real-world problems with reinforcement learning, we cannot rely on manually specified reward functions. Instead, we can have humans communicate an objective to the agent directly. In this work, we combine two approaches to learning from human feedback: expert demonstrations and trajectory preferences. We train a deep neural network to model the reward function and use its predicted reward to train an DQN-based deep reinforcement learning agent on 9 Atari games. Our approach beats the imitation learning baseline in 7 games and achieves strictly superhuman performance on 2 games without using game rewards. Additionally, we investigate the goodness of fit of the reward model, present some reward hacking problems, and study the effects of noise in the human labels.
Modeling Friends and Foes
Jun 30, 2018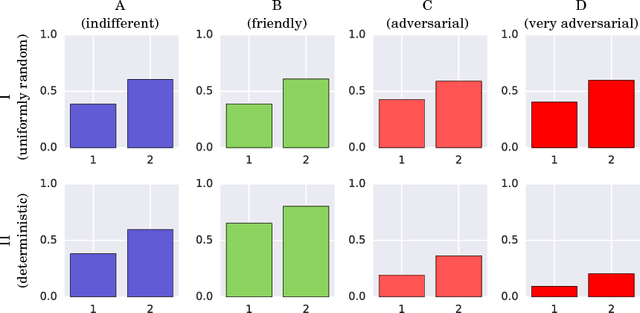
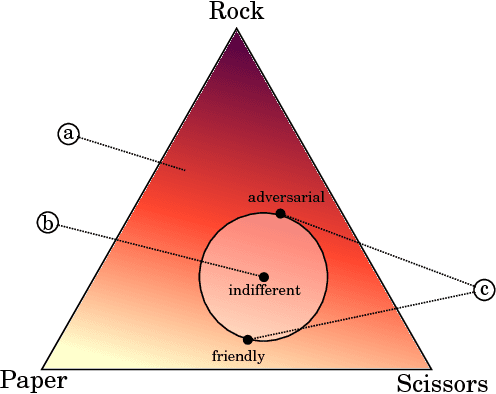
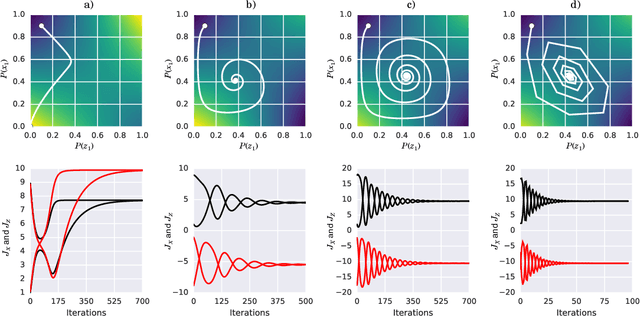
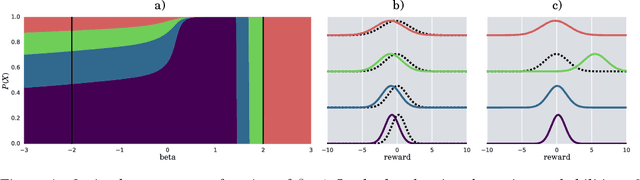
How can one detect friendly and adversarial behavior from raw data? Detecting whether an environment is a friend, a foe, or anything in between, remains a poorly understood yet desirable ability for safe and robust agents. This paper proposes a definition of these environmental "attitudes" based on an characterization of the environment's ability to react to the agent's private strategy. We define an objective function for a one-shot game that allows deriving the environment's probability distribution under friendly and adversarial assumptions alongside the agent's optimal strategy. Furthermore, we present an algorithm to compute these equilibrium strategies, and show experimentally that both friendly and adversarial environments possess non-trivial optimal strategies.