 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmplifying human performance in combinatorial competitive programming
Nov 29, 2024



Recent years have seen a significant surge in complex AI systems for competitive programming, capable of performing at admirable levels against human competitors. While steady progress has been made, the highest percentiles still remain out of reach for these methods on standard competition platforms such as Codeforces. Here we instead focus on combinatorial competitive programming, where the target is to find as-good-as-possible solutions to otherwise computationally intractable problems, over specific given inputs. We hypothesise that this scenario offers a unique testbed for human-AI synergy, as human programmers can write a backbone of a heuristic solution, after which AI can be used to optimise the scoring function used by the heuristic. We deploy our approach on previous iterations of Hash Code, a global team programming competition inspired by NP-hard software engineering problems at Google, and we leverage FunSearch to evolve our scoring functions. Our evolved solutions significantly improve the attained scores from their baseline, successfully breaking into the top percentile on all previous Hash Code online qualification rounds, and outperforming the top human teams on several. Our method is also performant on an optimisation problem that featured in a recent held-out AtCoder contest.
Transformers meet Neural Algorithmic Reasoners
Jun 13, 2024



Transformers have revolutionized machine learning with their simple yet effective architecture. Pre-training Transformers on massive text datasets from the Internet has led to unmatched generalization for natural language understanding (NLU) tasks. However, such language models remain fragile when tasked with algorithmic forms of reasoning, where computations must be precise and robust. To address this limitation, we propose a novel approach that combines the Transformer's language understanding with the robustness of graph neural network (GNN)-based neural algorithmic reasoners (NARs). Such NARs proved effective as generic solvers for algorithmic tasks, when specified in graph form. To make their embeddings accessible to a Transformer, we propose a hybrid architecture with a two-phase training procedure, allowing the tokens in the language model to cross-attend to the node embeddings from the NAR. We evaluate our resulting TransNAR model on CLRS-Text, the text-based version of the CLRS-30 benchmark, and demonstrate significant gains over Transformer-only models for algorithmic reasoning, both in and out of distribution.
The CLRS-Text Algorithmic Reasoning Language Benchmark
Jun 06, 2024



Eliciting reasoning capabilities from language models (LMs) is a critical direction on the path towards building intelligent systems. Most recent studies dedicated to reasoning focus on out-of-distribution performance on procedurally-generated synthetic benchmarks, bespoke-built to evaluate specific skills only. This trend makes results hard to transfer across publications, slowing down progress. Three years ago, a similar issue was identified and rectified in the field of neural algorithmic reasoning, with the advent of the CLRS benchmark. CLRS is a dataset generator comprising graph execution traces of classical algorithms from the Introduction to Algorithms textbook. Inspired by this, we propose CLRS-Text -- a textual version of these algorithmic traces. Out of the box, CLRS-Text is capable of procedurally generating trace data for thirty diverse, challenging algorithmic tasks across any desirable input distribution, while offering a standard pipeline in which any additional algorithmic tasks may be created in the benchmark. We fine-tune and evaluate various LMs as generalist executors on this benchmark, validating prior work and revealing a novel, interesting challenge for the LM reasoning community. Our code is available at https://github.com/google-deepmind/clrs/tree/master/clrs/_src/clrs_text.
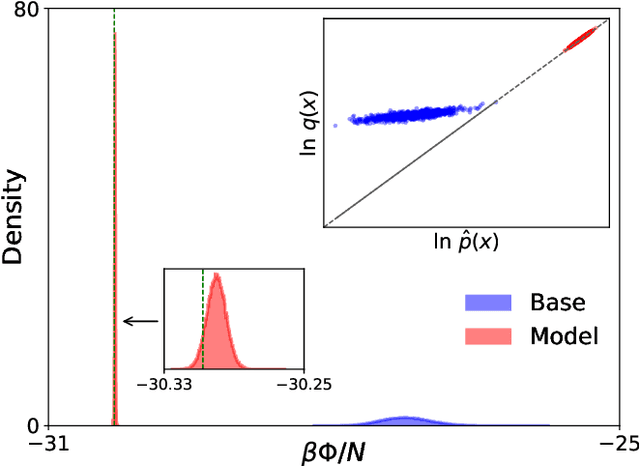
Gibbs free energies via isobaric-isothermal flows
May 22, 2023We present a machine-learning model based on normalizing flows that is trained to sample from the isobaric-isothermal (NPT) ensemble. In our approach, we approximate the joint distribution of a fully-flexible triclinic simulation box and particle coordinates to achieve a desired internal pressure. We test our model on monatomic water in the cubic and hexagonal ice phases and find excellent agreement of Gibbs free energies and other observables compared with established baselines.
Neural Algorithmic Reasoning with Causal Regularisation
Feb 20, 2023



Recent work on neural algorithmic reasoning has investigated the reasoning capabilities of neural networks, effectively demonstrating they can learn to execute classical algorithms on unseen data coming from the train distribution. However, the performance of existing neural reasoners significantly degrades on out-of-distribution (OOD) test data, where inputs have larger sizes. In this work, we make an important observation: there are many \emph{different} inputs for which an algorithm will perform certain intermediate computations \emph{identically}. This insight allows us to develop data augmentation procedures that, given an algorithm's intermediate trajectory, produce inputs for which the target algorithm would have \emph{exactly} the same next trajectory step. Then, we employ a causal framework to design a corresponding self-supervised objective, and we prove that it improves the OOD generalisation capabilities of the reasoner. We evaluate our method on the CLRS algorithmic reasoning benchmark, where we show up to 3$\times$ improvements on the OOD test data.
A Generalist Neural Algorithmic Learner
Sep 22, 2022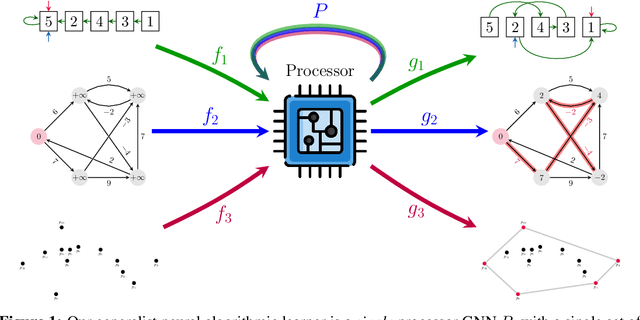
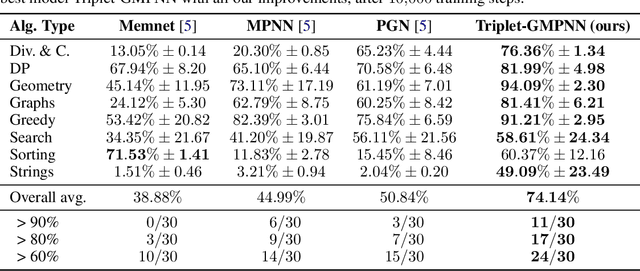
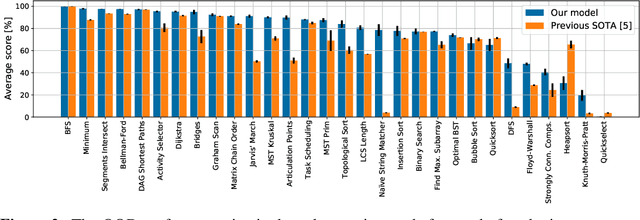
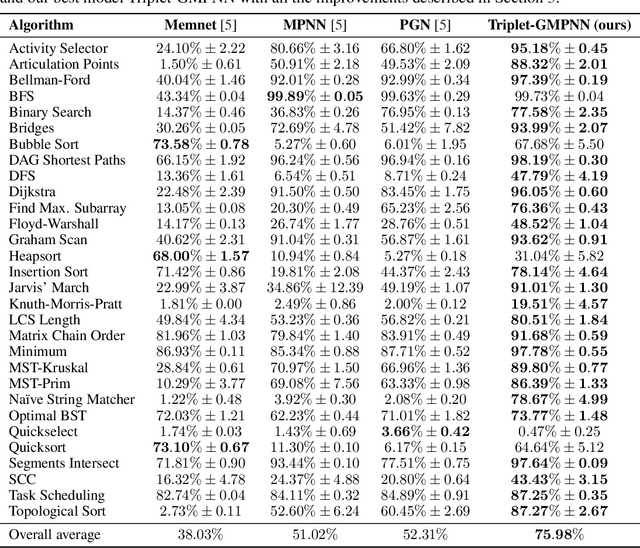
The cornerstone of neural algorithmic reasoning is the ability to solve algorithmic tasks, especially in a way that generalises out of distribution. While recent years have seen a surge in methodological improvements in this area, they mostly focused on building specialist models. Specialist models are capable of learning to neurally execute either only one algorithm or a collection of algorithms with identical control-flow backbone. Here, instead, we focus on constructing a generalist neural algorithmic learner -- a single graph neural network processor capable of learning to execute a wide range of algorithms, such as sorting, searching, dynamic programming, path-finding and geometry. We leverage the CLRS benchmark to empirically show that, much like recent successes in the domain of perception, generalist algorithmic learners can be built by "incorporating" knowledge. That is, it is possible to effectively learn algorithms in a multi-task manner, so long as we can learn to execute them well in a single-task regime. Motivated by this, we present a series of improvements to the input representation, training regime and processor architecture over CLRS, improving average single-task performance by over 20% from prior art. We then conduct a thorough ablation of multi-task learners leveraging these improvements. Our results demonstrate a generalist learner that effectively incorporates knowledge captured by specialist models.
Normalizing flows for atomic solids
Nov 16, 2021
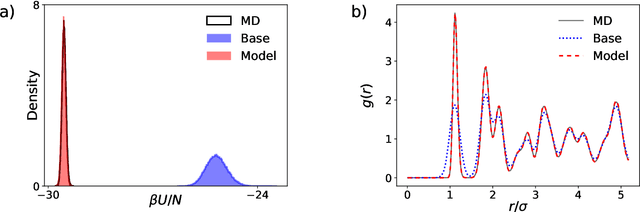
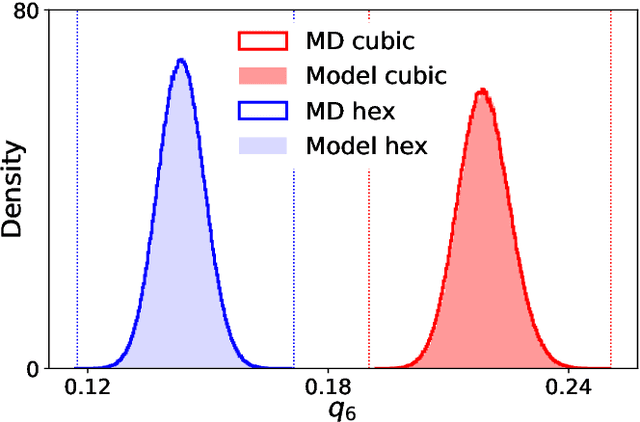
We present a machine-learning approach, based on normalizing flows, for modelling atomic solids. Our model transforms an analytically tractable base distribution into the target solid without requiring ground-truth samples for training. We report Helmholtz free energy estimates for cubic and hexagonal ice modelled as monatomic water as well as for a truncated and shifted Lennard-Jones system, and find them to be in excellent agreement with literature values and with estimates from established baseline methods. We further investigate structural properties and show that the model samples are nearly indistinguishable from the ones obtained with molecular dynamics. Our results thus demonstrate that normalizing flows can provide high-quality samples and free energy estimates of solids, without the need for multi-staging or for imposing restrictions on the crystal geometry.
Reward learning from human preferences and demonstrations in Atari
Nov 15, 2018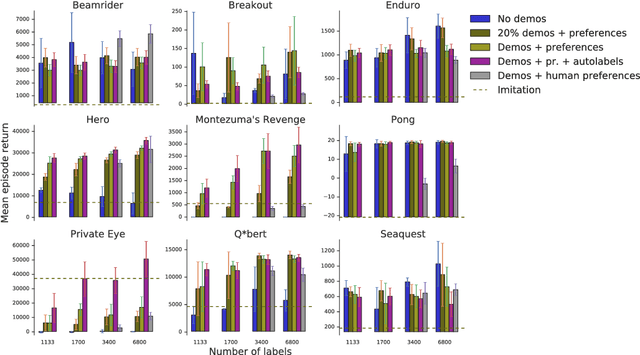
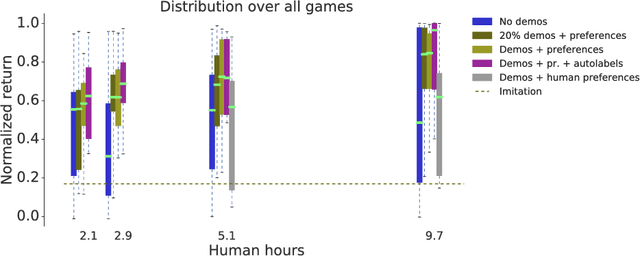
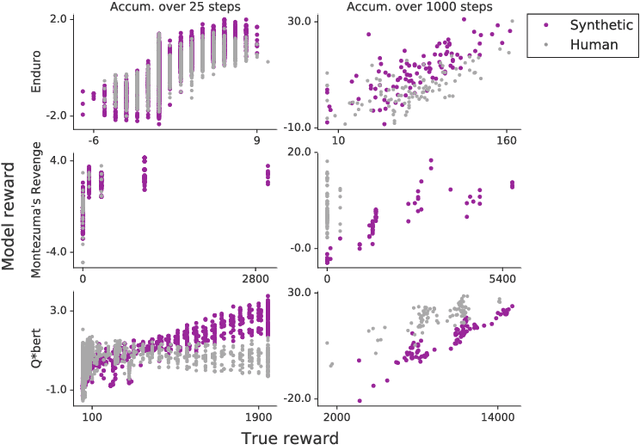
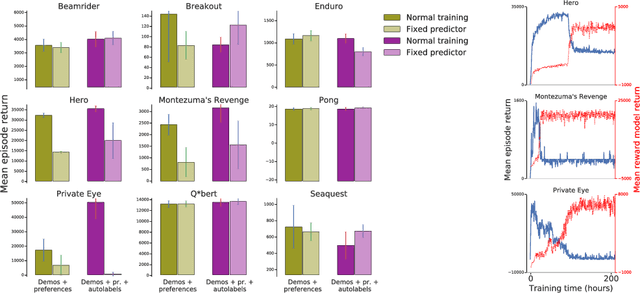
To solve complex real-world problems with reinforcement learning, we cannot rely on manually specified reward functions. Instead, we can have humans communicate an objective to the agent directly. In this work, we combine two approaches to learning from human feedback: expert demonstrations and trajectory preferences. We train a deep neural network to model the reward function and use its predicted reward to train an DQN-based deep reinforcement learning agent on 9 Atari games. Our approach beats the imitation learning baseline in 7 games and achieves strictly superhuman performance on 2 games without using game rewards. Additionally, we investigate the goodness of fit of the reward model, present some reward hacking problems, and study the effects of noise in the human labels.