 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Markov Chain Theory Approach to Characterizing the Minimax Optimality of Stochastic Gradient Descent (for Least Squares)
Jul 21, 2018This work provides a simplified proof of the statistical minimax optimality of (iterate averaged) stochastic gradient descent (SGD), for the special case of least squares. This result is obtained by analyzing SGD as a stochastic process and by sharply characterizing the stationary covariance matrix of this process. The finite rate optimality characterization captures the constant factors and addresses model mis-specification.
Recovering Structured Probability Matrices
Feb 06, 2018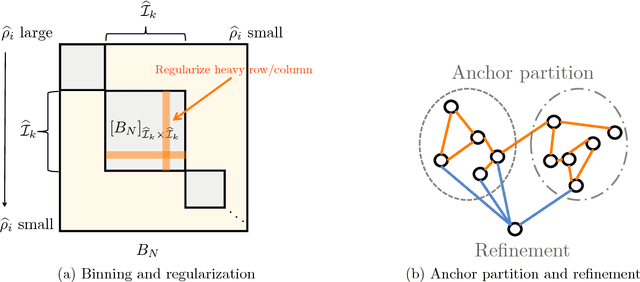
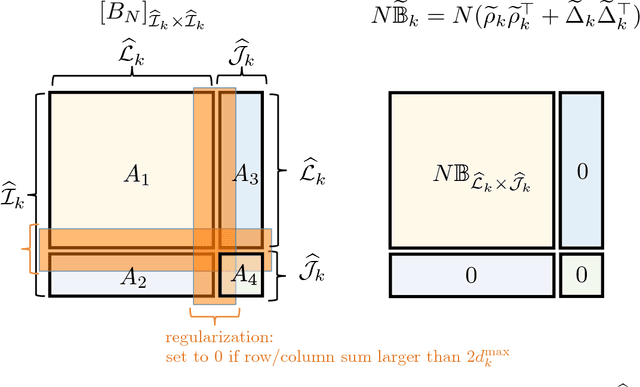
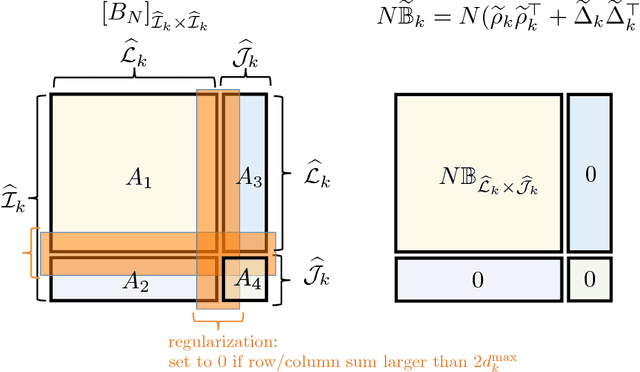
We consider the problem of accurately recovering a matrix B of size M by M , which represents a probability distribution over M2 outcomes, given access to an observed matrix of "counts" generated by taking independent samples from the distribution B. How can structural properties of the underlying matrix B be leveraged to yield computationally efficient and information theoretically optimal reconstruction algorithms? When can accurate reconstruction be accomplished in the sparse data regime? This basic problem lies at the core of a number of questions that are currently being considered by different communities, including building recommendation systems and collaborative filtering in the sparse data regime, community detection in sparse random graphs, learning structured models such as topic models or hidden Markov models, and the efforts from the natural language processing community to compute "word embeddings". Our results apply to the setting where B has a low rank structure. For this setting, we propose an efficient algorithm that accurately recovers the underlying M by M matrix using Theta(M) samples. This result easily translates to Theta(M) sample algorithms for learning topic models and learning hidden Markov Models. These linear sample complexities are optimal, up to constant factors, in an extremely strong sense: even testing basic properties of the underlying matrix (such as whether it has rank 1 or 2) requires Omega(M) samples. We provide an even stronger lower bound where distinguishing whether a sequence of observations were drawn from the uniform distribution over M observations versus being generated by an HMM with two hidden states requires Omega(M) observations. This precludes sublinear-sample hypothesis tests for basic properties, such as identity or uniformity, as well as sublinear sample estimators for quantities such as the entropy rate of HMMs.
Invariances and Data Augmentation for Supervised Music Transcription
Nov 13, 2017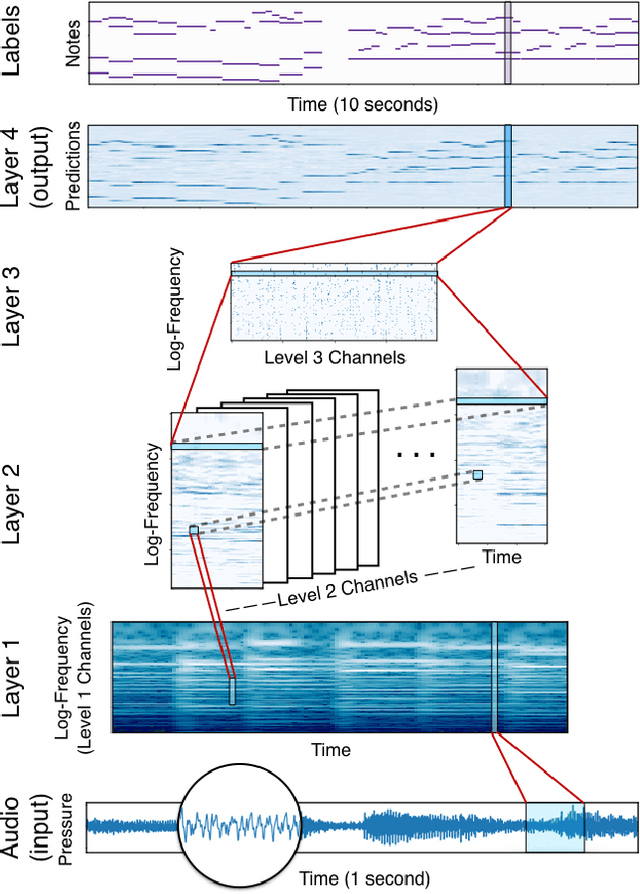
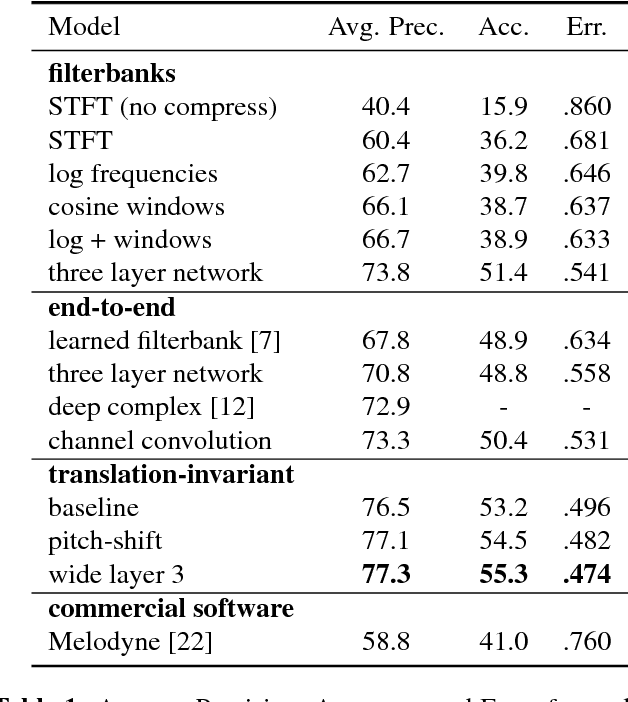
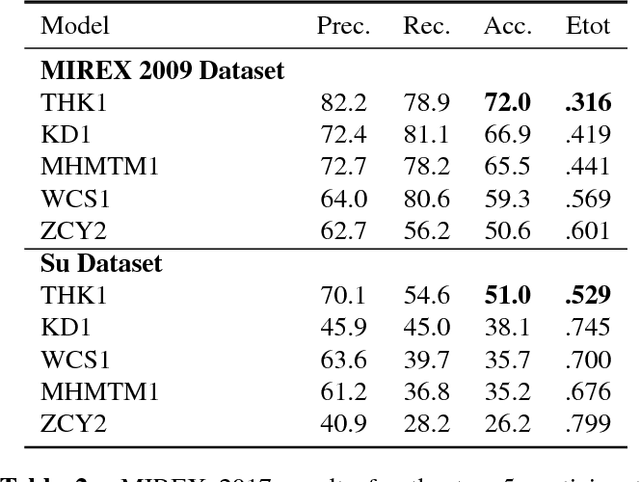
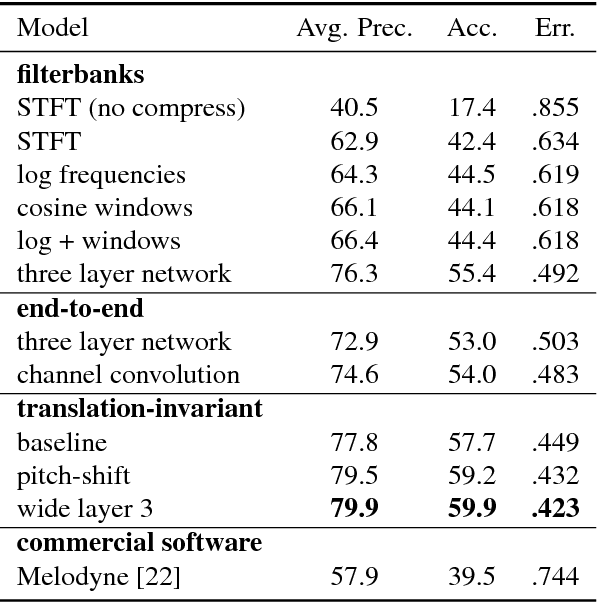
This paper explores a variety of models for frame-based music transcription, with an emphasis on the methods needed to reach state-of-the-art on human recordings. The translation-invariant network discussed in this paper, which combines a traditional filterbank with a convolutional neural network, was the top-performing model in the 2017 MIREX Multiple Fundamental Frequency Estimation evaluation. This class of models shares parameters in the log-frequency domain, which exploits the frequency invariance of music to reduce the number of model parameters and avoid overfitting to the training data. All models in this paper were trained with supervision by labeled data from the MusicNet dataset, augmented by random label-preserving pitch-shift transformations.
How to Escape Saddle Points Efficiently
Mar 02, 2017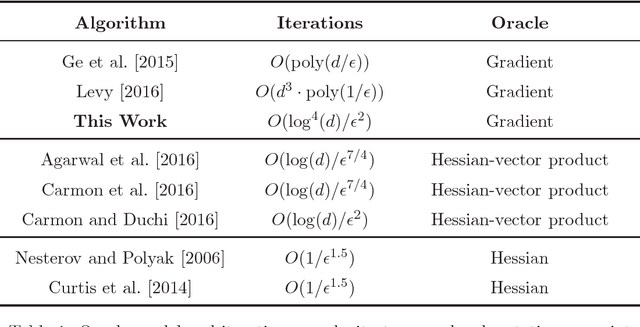
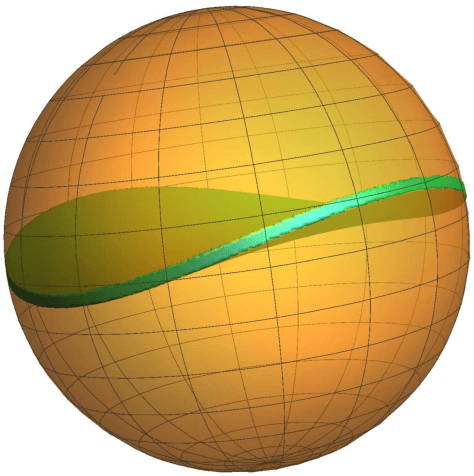
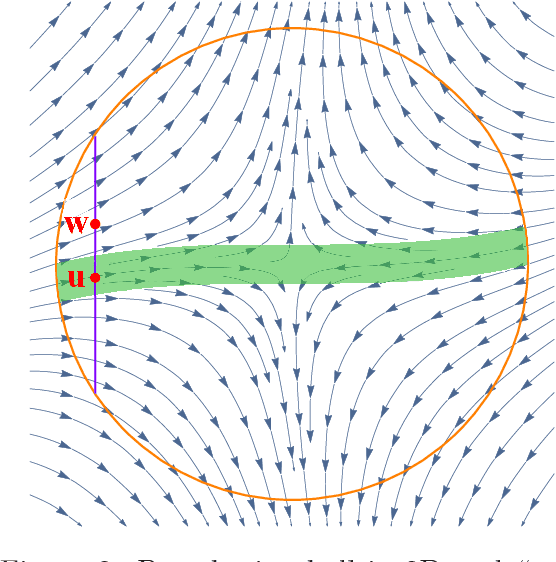
This paper shows that a perturbed form of gradient descent converges to a second-order stationary point in a number iterations which depends only poly-logarithmically on dimension (i.e., it is almost "dimension-free"). The convergence rate of this procedure matches the well-known convergence rate of gradient descent to first-order stationary points, up to log factors. When all saddle points are non-degenerate, all second-order stationary points are local minima, and our result thus shows that perturbed gradient descent can escape saddle points almost for free. Our results can be directly applied to many machine learning applications, including deep learning. As a particular concrete example of such an application, we show that our results can be used directly to establish sharp global convergence rates for matrix factorization. Our results rely on a novel characterization of the geometry around saddle points, which may be of independent interest to the non-convex optimization community.
Canonical Correlation Analysis for Analyzing Sequences of Medical Billing Codes
Jan 06, 2017
We propose using canonical correlation analysis (CCA) to generate features from sequences of medical billing codes. Applying this novel use of CCA to a database of medical billing codes for patients with diverticulitis, we first demonstrate that the CCA embeddings capture meaningful relationships among the codes. We then generate features from these embeddings and establish their usefulness in predicting future elective surgery for diverticulitis, an important marker in efforts for reducing costs in healthcare.
Robust Shift-and-Invert Preconditioning: Faster and More Sample Efficient Algorithms for Eigenvector Computation
May 30, 2016

We provide faster algorithms and improved sample complexities for approximating the top eigenvector of a matrix. Offline Setting: Given an $n \times d$ matrix $A$, we show how to compute an $\epsilon$ approximate top eigenvector in time $\tilde O ( [nnz(A) + \frac{d \cdot sr(A)}{gap^2}]\cdot \log 1/\epsilon )$ and $\tilde O([\frac{nnz(A)^{3/4} (d \cdot sr(A))^{1/4}}{\sqrt{gap}}]\cdot \log1/\epsilon )$. Here $sr(A)$ is the stable rank and $gap$ is the multiplicative eigenvalue gap. By separating the $gap$ dependence from $nnz(A)$ we improve on the classic power and Lanczos methods. We also improve prior work using fast subspace embeddings and stochastic optimization, giving significantly improved dependencies on $sr(A)$ and $\epsilon$. Our second running time improves this further when $nnz(A) \le \frac{d\cdot sr(A)}{gap^2}$. Online Setting: Given a distribution $D$ with covariance matrix $\Sigma$ and a vector $x_0$ which is an $O(gap)$ approximate top eigenvector for $\Sigma$, we show how to refine to an $\epsilon$ approximation using $\tilde O(\frac{v(D)}{gap^2} + \frac{v(D)}{gap \cdot \epsilon})$ samples from $D$. Here $v(D)$ is a natural variance measure. Combining our algorithm with previous work to initialize $x_0$, we obtain a number of improved sample complexity and runtime results. For general distributions, we achieve asymptotically optimal accuracy as a function of sample size as the number of samples grows large. Our results center around a robust analysis of the classic method of shift-and-invert preconditioning to reduce eigenvector computation to approximately solving a sequence of linear systems. We then apply fast SVRG based approximate system solvers to achieve our claims. We believe our results suggest the general effectiveness of shift-and-invert based approaches and imply that further computational gains may be reaped in practice.
Efficient Algorithms for Large-scale Generalized Eigenvector Computation and Canonical Correlation Analysis
May 27, 2016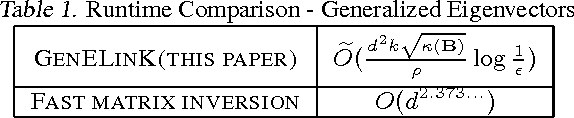

This paper considers the problem of canonical-correlation analysis (CCA) (Hotelling, 1936) and, more broadly, the generalized eigenvector problem for a pair of symmetric matrices. These are two fundamental problems in data analysis and scientific computing with numerous applications in machine learning and statistics (Shi and Malik, 2000; Hardoon et al., 2004; Witten et al., 2009). We provide simple iterative algorithms, with improved runtimes, for solving these problems that are globally linearly convergent with moderate dependencies on the condition numbers and eigenvalue gaps of the matrices involved. We obtain our results by reducing CCA to the top-$k$ generalized eigenvector problem. We solve this problem through a general framework that simply requires black box access to an approximate linear system solver. Instantiating this framework with accelerated gradient descent we obtain a running time of $O(\frac{z k \sqrt{\kappa}}{\rho} \log(1/\epsilon) \log \left(k\kappa/\rho\right))$ where $z$ is the total number of nonzero entries, $\kappa$ is the condition number and $\rho$ is the relative eigenvalue gap of the appropriate matrices. Our algorithm is linear in the input size and the number of components $k$ up to a $\log(k)$ factor. This is essential for handling large-scale matrices that appear in practice. To the best of our knowledge this is the first such algorithm with global linear convergence. We hope that our results prompt further research and ultimately improve the practical running time for performing these important data analysis procedures on large data sets.
Provable Efficient Online Matrix Completion via Non-convex Stochastic Gradient Descent
May 26, 2016
Matrix completion, where we wish to recover a low rank matrix by observing a few entries from it, is a widely studied problem in both theory and practice with wide applications. Most of the provable algorithms so far on this problem have been restricted to the offline setting where they provide an estimate of the unknown matrix using all observations simultaneously. However, in many applications, the online version, where we observe one entry at a time and dynamically update our estimate, is more appealing. While existing algorithms are efficient for the offline setting, they could be highly inefficient for the online setting. In this paper, we propose the first provable, efficient online algorithm for matrix completion. Our algorithm starts from an initial estimate of the matrix and then performs non-convex stochastic gradient descent (SGD). After every observation, it performs a fast update involving only one row of two tall matrices, giving near linear total runtime. Our algorithm can be naturally used in the offline setting as well, where it gives competitive sample complexity and runtime to state of the art algorithms. Our proofs introduce a general framework to show that SGD updates tend to stay away from saddle surfaces and could be of broader interests for other non-convex problems to prove tight rates.
Faster Eigenvector Computation via Shift-and-Invert Preconditioning
May 26, 2016

We give faster algorithms and improved sample complexities for estimating the top eigenvector of a matrix $\Sigma$ -- i.e. computing a unit vector $x$ such that $x^T \Sigma x \ge (1-\epsilon)\lambda_1(\Sigma)$: Offline Eigenvector Estimation: Given an explicit $A \in \mathbb{R}^{n \times d}$ with $\Sigma = A^TA$, we show how to compute an $\epsilon$ approximate top eigenvector in time $\tilde O([nnz(A) + \frac{d*sr(A)}{gap^2} ]* \log 1/\epsilon )$ and $\tilde O([\frac{nnz(A)^{3/4} (d*sr(A))^{1/4}}{\sqrt{gap}} ] * \log 1/\epsilon )$. Here $nnz(A)$ is the number of nonzeros in $A$, $sr(A)$ is the stable rank, $gap$ is the relative eigengap. By separating the $gap$ dependence from the $nnz(A)$ term, our first runtime improves upon the classical power and Lanczos methods. It also improves prior work using fast subspace embeddings [AC09, CW13] and stochastic optimization [Sha15c], giving significantly better dependencies on $sr(A)$ and $\epsilon$. Our second running time improves these further when $nnz(A) \le \frac{d*sr(A)}{gap^2}$. Online Eigenvector Estimation: Given a distribution $D$ with covariance matrix $\Sigma$ and a vector $x_0$ which is an $O(gap)$ approximate top eigenvector for $\Sigma$, we show how to refine to an $\epsilon$ approximation using $ O(\frac{var(D)}{gap*\epsilon})$ samples from $D$. Here $var(D)$ is a natural notion of variance. Combining our algorithm with previous work to initialize $x_0$, we obtain improved sample complexity and runtime results under a variety of assumptions on $D$. We achieve our results using a general framework that we believe is of independent interest. We give a robust analysis of the classic method of shift-and-invert preconditioning to reduce eigenvector computation to approximately solving a sequence of linear systems. We then apply fast stochastic variance reduced gradient (SVRG) based system solvers to achieve our claims.
Streaming PCA: Matching Matrix Bernstein and Near-Optimal Finite Sample Guarantees for Oja's Algorithm
Mar 28, 2016
This work provides improved guarantees for streaming principle component analysis (PCA). Given $A_1, \ldots, A_n\in \mathbb{R}^{d\times d}$ sampled independently from distributions satisfying $\mathbb{E}[A_i] = \Sigma$ for $\Sigma \succeq \mathbf{0}$, this work provides an $O(d)$-space linear-time single-pass streaming algorithm for estimating the top eigenvector of $\Sigma$. The algorithm nearly matches (and in certain cases improves upon) the accuracy obtained by the standard batch method that computes top eigenvector of the empirical covariance $\frac{1}{n} \sum_{i \in [n]} A_i$ as analyzed by the matrix Bernstein inequality. Moreover, to achieve constant accuracy, our algorithm improves upon the best previous known sample complexities of streaming algorithms by either a multiplicative factor of $O(d)$ or $1/\mathrm{gap}$ where $\mathrm{gap}$ is the relative distance between the top two eigenvalues of $\Sigma$. These results are achieved through a novel analysis of the classic Oja's algorithm, one of the oldest and most popular algorithms for streaming PCA. In particular, this work shows that simply picking a random initial point $w_0$ and applying the update rule $w_{i + 1} = w_i + \eta_i A_i w_i$ suffices to accurately estimate the top eigenvector, with a suitable choice of $\eta_i$. We believe our result sheds light on how to efficiently perform streaming PCA both in theory and in practice and we hope that our analysis may serve as the basis for analyzing many variants and extensions of streaming PCA.