 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardness of Independent Learning and Sparse Equilibrium Computation in Markov Games
Mar 22, 2023We consider the problem of decentralized multi-agent reinforcement learning in Markov games. A fundamental question is whether there exist algorithms that, when adopted by all agents and run independently in a decentralized fashion, lead to no-regret for each player, analogous to celebrated convergence results in normal-form games. While recent work has shown that such algorithms exist for restricted settings (notably, when regret is defined with respect to deviations to Markovian policies), the question of whether independent no-regret learning can be achieved in the standard Markov game framework was open. We provide a decisive negative resolution this problem, both from a computational and statistical perspective. We show that: - Under the widely-believed assumption that PPAD-hard problems cannot be solved in polynomial time, there is no polynomial-time algorithm that attains no-regret in general-sum Markov games when executed independently by all players, even when the game is known to the algorithm designer and the number of players is a small constant. - When the game is unknown, no algorithm, regardless of computational efficiency, can achieve no-regret without observing a number of episodes that is exponential in the number of players. Perhaps surprisingly, our lower bounds hold even for seemingly easier setting in which all agents are controlled by a a centralized algorithm. They are proven via lower bounds for a simpler problem we refer to as SparseCCE, in which the goal is to compute a coarse correlated equilibrium that is sparse in the sense that it can be represented as a mixture of a small number of product policies. The crux of our approach is a novel application of aggregation techniques from online learning, whereby we show that any algorithm for the SparseCCE problem can be used to compute approximate Nash equilibria for non-zero sum normal-form games.
Learning High-Dimensional Single-Neuron ReLU Networks with Finite Samples
Mar 03, 2023This paper considers the problem of learning a single ReLU neuron with squared loss (a.k.a., ReLU regression) in the overparameterized regime, where the input dimension can exceed the number of samples. We analyze a Perceptron-type algorithm called GLM-tron (Kakade et al., 2011), and provide its dimension-free risk upper bounds for high-dimensional ReLU regression in both well-specified and misspecified settings. Our risk bounds recover several existing results as special cases. Moreover, in the well-specified setting, we also provide an instance-wise matching risk lower bound for GLM-tron. Our upper and lower risk bounds provide a sharp characterization of the high-dimensional ReLU regression problems that can be learned via GLM-tron. On the other hand, we provide some negative results for stochastic gradient descent (SGD) for ReLU regression with symmetric Bernoulli data: if the model is well-specified, the excess risk of SGD is provably no better than that of GLM-tron ignoring constant factors, for each problem instance; and in the noiseless case, GLM-tron can achieve a small risk while SGD unavoidably suffers from a constant risk in expectation. These results together suggest that GLM-tron might be preferable than SGD for high-dimensional ReLU regression.
Learning Hidden Markov Models Using Conditional Samples
Feb 28, 2023This paper is concerned with the computational complexity of learning the Hidden Markov Model (HMM). Although HMMs are some of the most widely used tools in sequential and time series modeling, they are cryptographically hard to learn in the standard setting where one has access to i.i.d. samples of observation sequences. In this paper, we depart from this setup and consider an interactive access model, in which the algorithm can query for samples from the conditional distributions of the HMMs. We show that interactive access to the HMM enables computationally efficient learning algorithms, thereby bypassing cryptographic hardness. Specifically, we obtain efficient algorithms for learning HMMs in two settings: (a) An easier setting where we have query access to the exact conditional probabilities. Here our algorithm runs in polynomial time and makes polynomially many queries to approximate any HMM in total variation distance. (b) A harder setting where we can only obtain samples from the conditional distributions. Here the performance of the algorithm depends on a new parameter, called the fidelity of the HMM. We show that this captures cryptographically hard instances and previously known positive results. We also show that these results extend to a broader class of distributions with latent low rank structure. Our algorithms can be viewed as generalizations and robustifications of Angluin's $L^*$ algorithm for learning deterministic finite automata from membership queries.
Unpacking Reward Shaping: Understanding the Benefits of Reward Engineering on Sample Complexity
Oct 18, 2022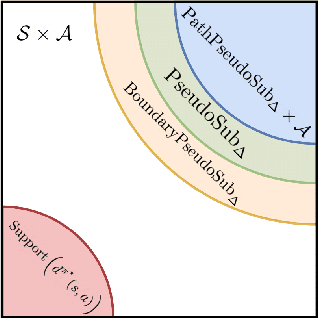

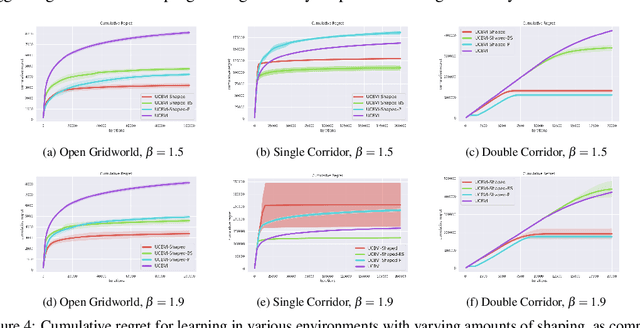
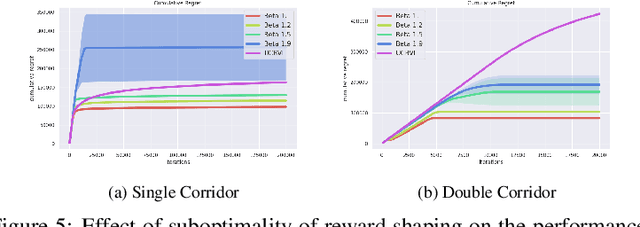
Reinforcement learning provides an automated framework for learning behaviors from high-level reward specifications, but in practice the choice of reward function can be crucial for good results -- while in principle the reward only needs to specify what the task is, in reality practitioners often need to design more detailed rewards that provide the agent with some hints about how the task should be completed. The idea of this type of ``reward-shaping'' has been often discussed in the literature, and is often a critical part of practical applications, but there is relatively little formal characterization of how the choice of reward shaping can yield benefits in sample complexity. In this work, we build on the framework of novelty-based exploration to provide a simple scheme for incorporating shaped rewards into RL along with an analysis tool to show that particular choices of reward shaping provably improve sample efficiency. We characterize the class of problems where these gains are expected to be significant and show how this can be connected to practical algorithms in the literature. We confirm that these results hold in practice in an experimental evaluation, providing an insight into the mechanisms through which reward shaping can significantly improve the complexity of reinforcement learning while retaining asymptotic performance.
The Role of Coverage in Online Reinforcement Learning
Oct 09, 2022
Coverage conditions -- which assert that the data logging distribution adequately covers the state space -- play a fundamental role in determining the sample complexity of offline reinforcement learning. While such conditions might seem irrelevant to online reinforcement learning at first glance, we establish a new connection by showing -- somewhat surprisingly -- that the mere existence of a data distribution with good coverage can enable sample-efficient online RL. Concretely, we show that coverability -- that is, existence of a data distribution that satisfies a ubiquitous coverage condition called concentrability -- can be viewed as a structural property of the underlying MDP, and can be exploited by standard algorithms for sample-efficient exploration, even when the agent does not know said distribution. We complement this result by proving that several weaker notions of coverage, despite being sufficient for offline RL, are insufficient for online RL. We also show that existing complexity measures for online RL, including Bellman rank and Bellman-Eluder dimension, fail to optimally capture coverability, and propose a new complexity measure, the sequential extrapolation coefficient, to provide a unification.
The Power and Limitation of Pretraining-Finetuning for Linear Regression under Covariate Shift
Aug 03, 2022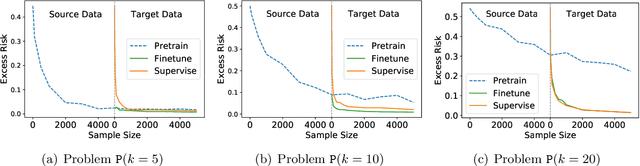
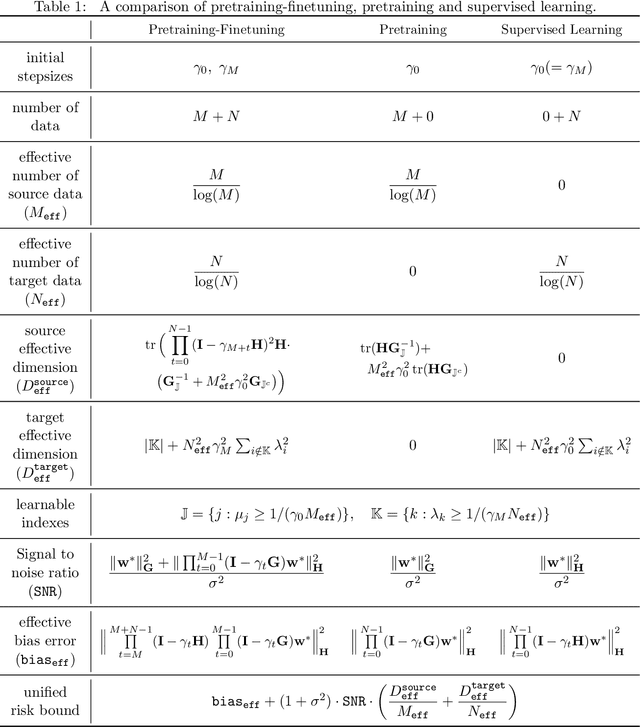
We study linear regression under covariate shift, where the marginal distribution over the input covariates differs in the source and the target domains, while the conditional distribution of the output given the input covariates is similar across the two domains. We investigate a transfer learning approach with pretraining on the source data and finetuning based on the target data (both conducted by online SGD) for this problem. We establish sharp instance-dependent excess risk upper and lower bounds for this approach. Our bounds suggest that for a large class of linear regression instances, transfer learning with $O(N^2)$ source data (and scarce or no target data) is as effective as supervised learning with $N$ target data. In addition, we show that finetuning, even with only a small amount of target data, could drastically reduce the amount of source data required by pretraining. Our theory sheds light on the effectiveness and limitation of pretraining as well as the benefits of finetuning for tackling covariate shift problems.
Risk Bounds of Multi-Pass SGD for Least Squares in the Interpolation Regime
Mar 07, 2022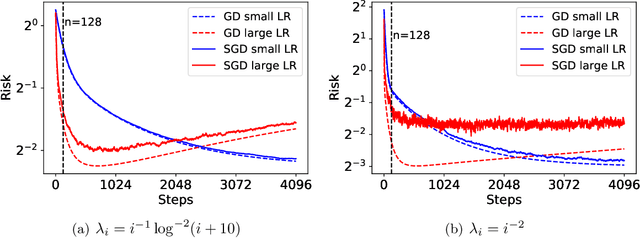
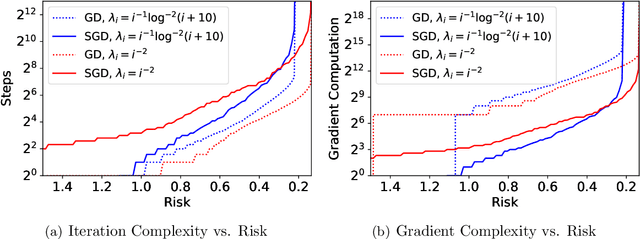
Stochastic gradient descent (SGD) has achieved great success due to its superior performance in both optimization and generalization. Most of existing generalization analyses are made for single-pass SGD, which is a less practical variant compared to the commonly-used multi-pass SGD. Besides, theoretical analyses for multi-pass SGD often concern a worst-case instance in a class of problems, which may be pessimistic to explain the superior generalization ability for some particular problem instance. The goal of this paper is to sharply characterize the generalization of multi-pass SGD, by developing an instance-dependent excess risk bound for least squares in the interpolation regime, which is expressed as a function of the iteration number, stepsize, and data covariance. We show that the excess risk of SGD can be exactly decomposed into the excess risk of GD and a positive fluctuation error, suggesting that SGD always performs worse, instance-wisely, than GD, in generalization. On the other hand, we show that although SGD needs more iterations than GD to achieve the same level of excess risk, it saves the number of stochastic gradient evaluations, and therefore is preferable in terms of computational time.
The Statistical Complexity of Interactive Decision Making
Dec 27, 2021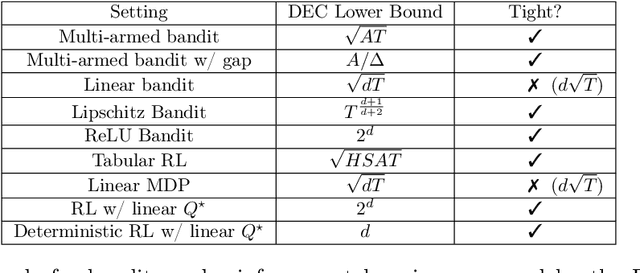

A fundamental challenge in interactive learning and decision making, ranging from bandit problems to reinforcement learning, is to provide sample-efficient, adaptive learning algorithms that achieve near-optimal regret. This question is analogous to the classical problem of optimal (supervised) statistical learning, where there are well-known complexity measures (e.g., VC dimension and Rademacher complexity) that govern the statistical complexity of learning. However, characterizing the statistical complexity of interactive learning is substantially more challenging due to the adaptive nature of the problem. The main result of this work provides a complexity measure, the Decision-Estimation Coefficient, that is proven to be both necessary and sufficient for sample-efficient interactive learning. In particular, we provide: 1. a lower bound on the optimal regret for any interactive decision making problem, establishing the Decision-Estimation Coefficient as a fundamental limit. 2. a unified algorithm design principle, Estimation-to-Decisions (E2D), which transforms any algorithm for supervised estimation into an online algorithm for decision making. E2D attains a regret bound matching our lower bound, thereby achieving optimal sample-efficient learning as characterized by the Decision-Estimation Coefficient. Taken together, these results constitute a theory of learnability for interactive decision making. When applied to reinforcement learning settings, the Decision-Estimation Coefficient recovers essentially all existing hardness results and lower bounds. More broadly, the approach can be viewed as a decision-theoretic analogue of the classical Le Cam theory of statistical estimation; it also unifies a number of existing approaches -- both Bayesian and frequentist.
Last Iterate Risk Bounds of SGD with Decaying Stepsize for Overparameterized Linear Regression
Oct 12, 2021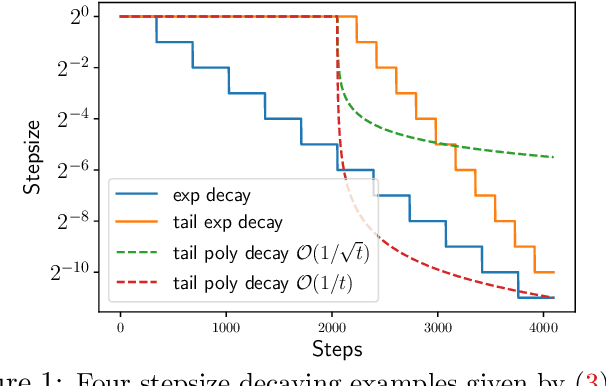
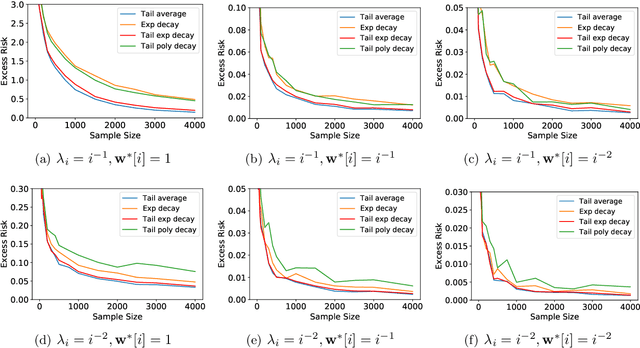
Stochastic gradient descent (SGD) has been demonstrated to generalize well in many deep learning applications. In practice, one often runs SGD with a geometrically decaying stepsize, i.e., a constant initial stepsize followed by multiple geometric stepsize decay, and uses the last iterate as the output. This kind of SGD is known to be nearly minimax optimal for classical finite-dimensional linear regression problems (Ge et al., 2019), and provably outperforms SGD with polynomially decaying stepsize in terms of the statistical minimax rates. However, a sharp analysis for the last iterate of SGD with decaying step size in the overparameterized setting is still open. In this paper, we provide problem-dependent analysis on the last iterate risk bounds of SGD with decaying stepsize, for (overparameterized) linear regression problems. In particular, for SGD with geometrically decaying stepsize (or tail geometrically decaying stepsize), we prove nearly matching upper and lower bounds on the excess risk. Our results demonstrate the generalization ability of SGD for a wide class of overparameterized problems, and can recover the minimax optimal results up to logarithmic factors in the classical regime. Moreover, we provide an excess risk lower bound for SGD with polynomially decaying stepsize and illustrate the advantage of geometrically decaying stepsize in an instance-wise manner, which complements the minimax rate comparison made in previous work.
The Benefits of Implicit Regularization from SGD in Least Squares Problems
Aug 10, 2021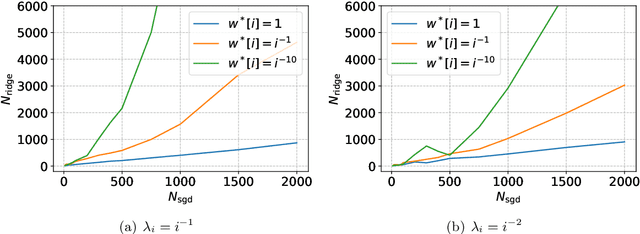
Stochastic gradient descent (SGD) exhibits strong algorithmic regularization effects in practice, which has been hypothesized to play an important role in the generalization of modern machine learning approaches. In this work, we seek to understand these issues in the simpler setting of linear regression (including both underparameterized and overparameterized regimes), where our goal is to make sharp instance-based comparisons of the implicit regularization afforded by (unregularized) average SGD with the explicit regularization of ridge regression. For a broad class of least squares problem instances (that are natural in high-dimensional settings), we show: (1) for every problem instance and for every ridge parameter, (unregularized) SGD, when provided with logarithmically more samples than that provided to the ridge algorithm, generalizes no worse than the ridge solution (provided SGD uses a tuned constant stepsize); (2) conversely, there exist instances (in this wide problem class) where optimally-tuned ridge regression requires quadratically more samples than SGD in order to have the same generalization performance. Taken together, our results show that, up to the logarithmic factors, the generalization performance of SGD is always no worse than that of ridge regression in a wide range of overparameterized problems, and, in fact, could be much better for some problem instances. More generally, our results show how algorithmic regularization has important consequences even in simpler (overparameterized) convex settings.