 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBundleFusion: Real-time Globally Consistent 3D Reconstruction using On-the-fly Surface Re-integration
Feb 07, 2017
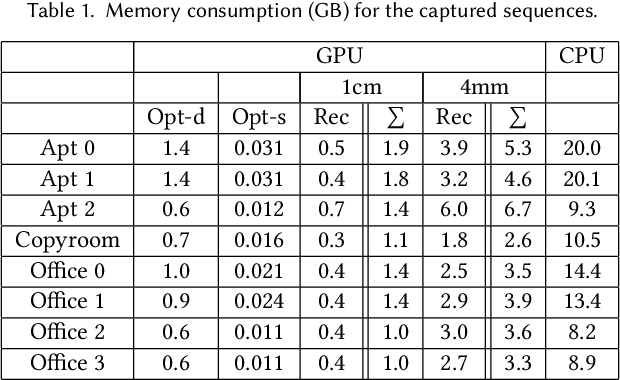
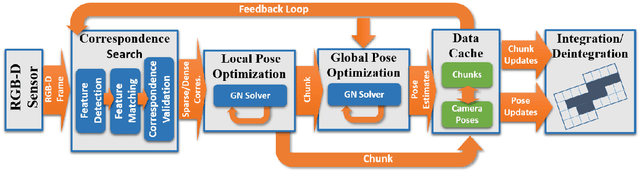
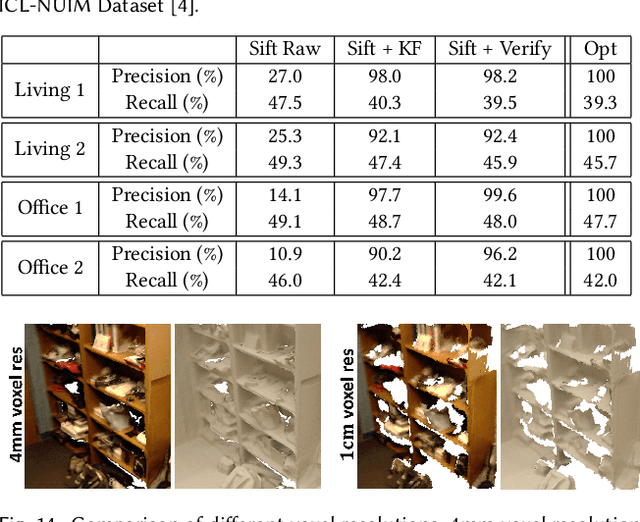
Real-time, high-quality, 3D scanning of large-scale scenes is key to mixed reality and robotic applications. However, scalability brings challenges of drift in pose estimation, introducing significant errors in the accumulated model. Approaches often require hours of offline processing to globally correct model errors. Recent online methods demonstrate compelling results, but suffer from: (1) needing minutes to perform online correction preventing true real-time use; (2) brittle frame-to-frame (or frame-to-model) pose estimation resulting in many tracking failures; or (3) supporting only unstructured point-based representations, which limit scan quality and applicability. We systematically address these issues with a novel, real-time, end-to-end reconstruction framework. At its core is a robust pose estimation strategy, optimizing per frame for a global set of camera poses by considering the complete history of RGB-D input with an efficient hierarchical approach. We remove the heavy reliance on temporal tracking, and continually localize to the globally optimized frames instead. We contribute a parallelizable optimization framework, which employs correspondences based on sparse features and dense geometric and photometric matching. Our approach estimates globally optimized (i.e., bundle adjusted) poses in real-time, supports robust tracking with recovery from gross tracking failures (i.e., relocalization), and re-estimates the 3D model in real-time to ensure global consistency; all within a single framework. Our approach outperforms state-of-the-art online systems with quality on par to offline methods, but with unprecedented speed and scan completeness. Our framework leads to a comprehensive online scanning solution for large indoor environments, enabling ease of use and high-quality results.
Learning to Navigate the Energy Landscape
Mar 18, 2016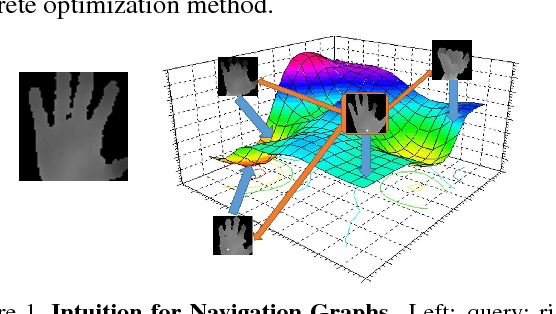
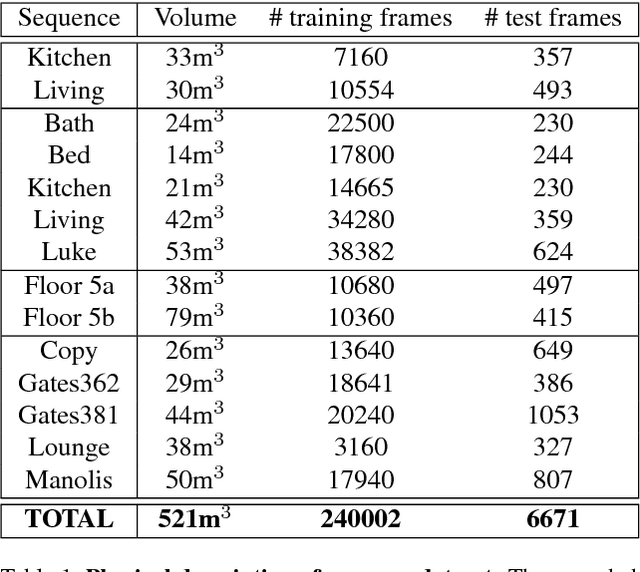
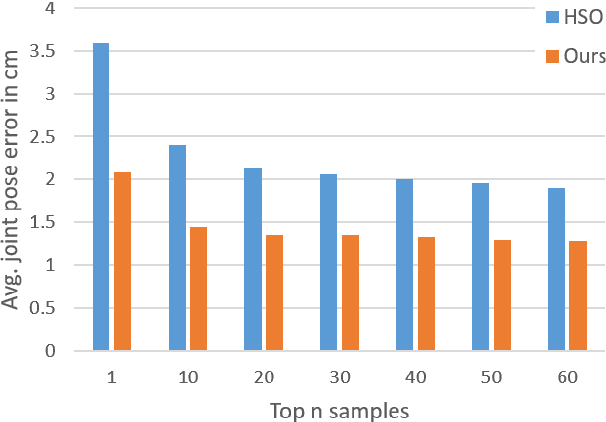
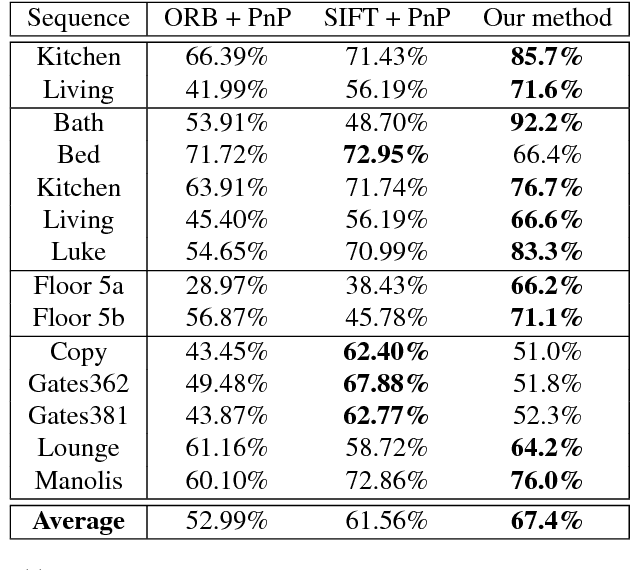
In this paper, we present a novel and efficient architecture for addressing computer vision problems that use `Analysis by Synthesis'. Analysis by synthesis involves the minimization of the reconstruction error which is typically a non-convex function of the latent target variables. State-of-the-art methods adopt a hybrid scheme where discriminatively trained predictors like Random Forests or Convolutional Neural Networks are used to initialize local search algorithms. While these methods have been shown to produce promising results, they often get stuck in local optima. Our method goes beyond the conventional hybrid architecture by not only proposing multiple accurate initial solutions but by also defining a navigational structure over the solution space that can be used for extremely efficient gradient-free local search. We demonstrate the efficacy of our approach on the challenging problem of RGB Camera Relocalization. To make the RGB camera relocalization problem particularly challenging, we introduce a new dataset of 3D environments which are significantly larger than those found in other publicly-available datasets. Our experiments reveal that the proposed method is able to achieve state-of-the-art camera relocalization results. We also demonstrate the generalizability of our approach on Hand Pose Estimation and Image Retrieval tasks.
Joint Object-Material Category Segmentation from Audio-Visual Cues
Jan 10, 2016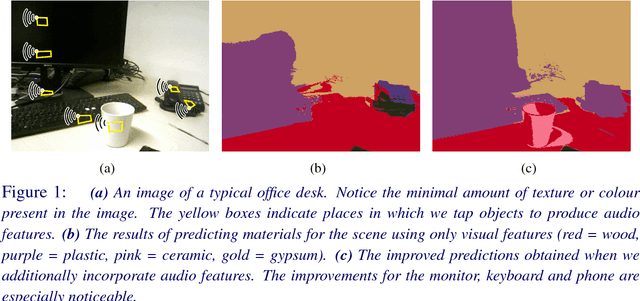

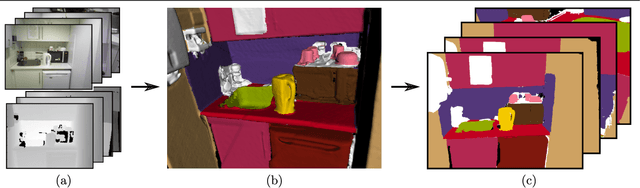
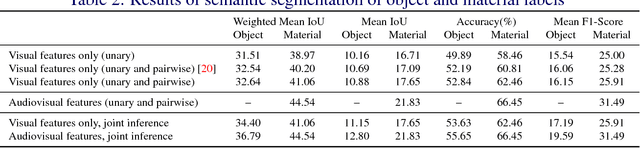
It is not always possible to recognise objects and infer material properties for a scene from visual cues alone, since objects can look visually similar whilst being made of very different materials. In this paper, we therefore present an approach that augments the available dense visual cues with sparse auditory cues in order to estimate dense object and material labels. Since estimates of object class and material properties are mutually informative, we optimise our multi-output labelling jointly using a random-field framework. We evaluate our system on a new dataset with paired visual and auditory data that we make publicly available. We demonstrate that this joint estimation of object and material labels significantly outperforms the estimation of either category in isolation.
SemanticPaint: A Framework for the Interactive Segmentation of 3D Scenes
Oct 13, 2015
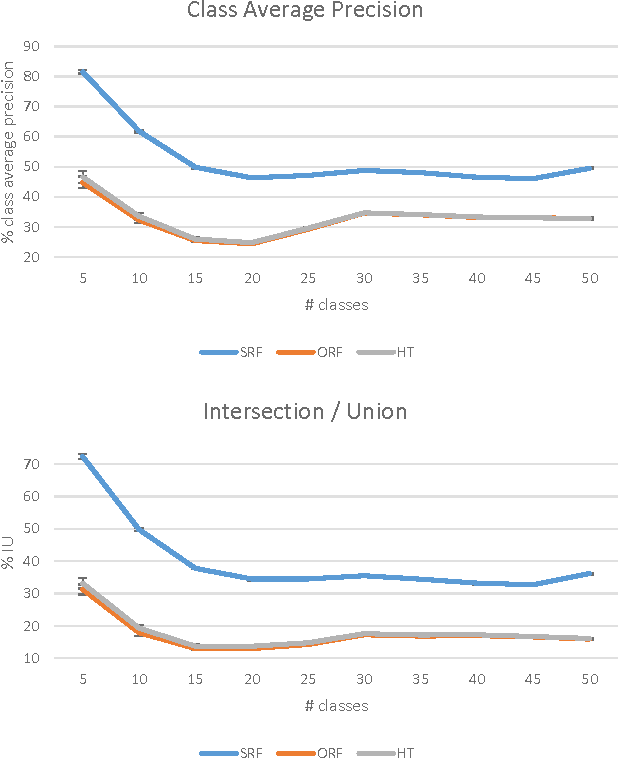

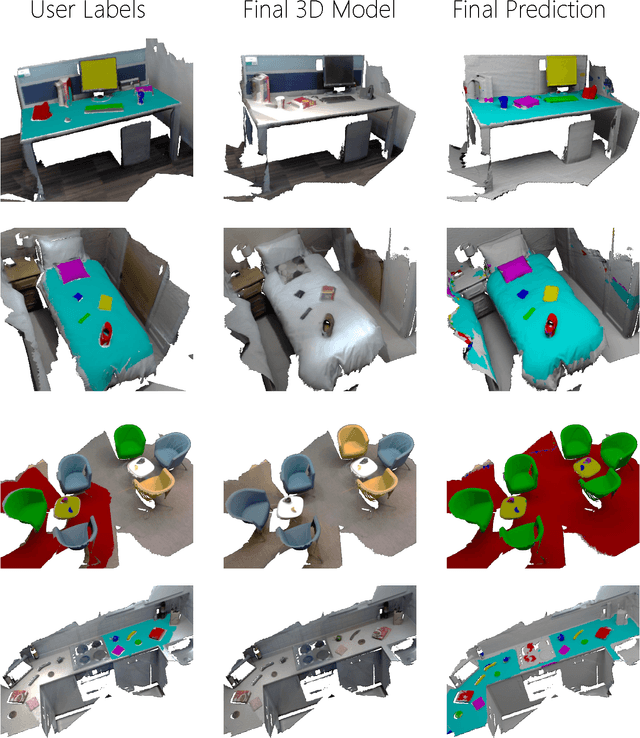
We present an open-source, real-time implementation of SemanticPaint, a system for geometric reconstruction, object-class segmentation and learning of 3D scenes. Using our system, a user can walk into a room wearing a depth camera and a virtual reality headset, and both densely reconstruct the 3D scene and interactively segment the environment into object classes such as 'chair', 'floor' and 'table'. The user interacts physically with the real-world scene, touching objects and using voice commands to assign them appropriate labels. These user-generated labels are leveraged by an online random forest-based machine learning algorithm, which is used to predict labels for previously unseen parts of the scene. The entire pipeline runs in real time, and the user stays 'in the loop' throughout the process, receiving immediate feedback about the progress of the labelling and interacting with the scene as necessary to refine the predicted segmentation.
A Light Transport Model for Mitigating Multipath Interference in TOF Sensors
Jan 30, 2015Continuous-wave Time-of-flight (TOF) range imaging has become a commercially viable technology with many applications in computer vision and graphics. However, the depth images obtained from TOF cameras contain scene dependent errors due to multipath interference (MPI). Specifically, MPI occurs when multiple optical reflections return to a single spatial location on the imaging sensor. Many prior approaches to rectifying MPI rely on sparsity in optical reflections, which is an extreme simplification. In this paper, we correct MPI by combining the standard measurements from a TOF camera with information from direct and global light transport. We report results on both simulated experiments and physical experiments (using the Kinect sensor). Our results, evaluated against ground truth, demonstrate a quantitative improvement in depth accuracy.