 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Neural Race Reduction: Dynamics of Abstraction in Gated Networks
Jul 21, 2022
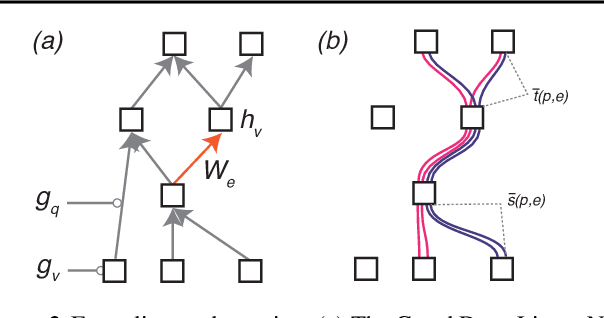
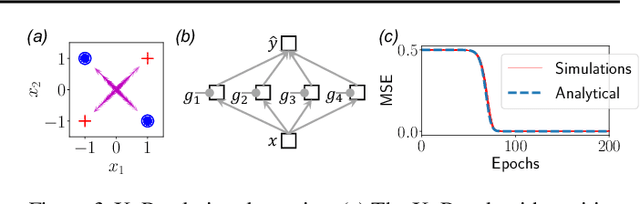
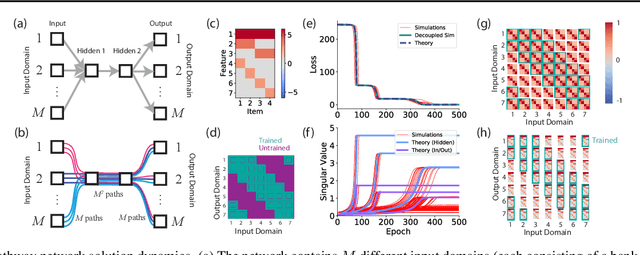
Our theoretical understanding of deep learning has not kept pace with its empirical success. While network architecture is known to be critical, we do not yet understand its effect on learned representations and network behavior, or how this architecture should reflect task structure.In this work, we begin to address this gap by introducing the Gated Deep Linear Network framework that schematizes how pathways of information flow impact learning dynamics within an architecture. Crucially, because of the gating, these networks can compute nonlinear functions of their input. We derive an exact reduction and, for certain cases, exact solutions to the dynamics of learning. Our analysis demonstrates that the learning dynamics in structured networks can be conceptualized as a neural race with an implicit bias towards shared representations, which then govern the model's ability to systematically generalize, multi-task, and transfer. We validate our key insights on naturalistic datasets and with relaxed assumptions. Taken together, our work gives rise to general hypotheses relating neural architecture to learning and provides a mathematical approach towards understanding the design of more complex architectures and the role of modularity and compositionality in solving real-world problems. The code and results are available at https://www.saxelab.org/gated-dln .
An Introduction to Lifelong Supervised Learning
Jul 12, 2022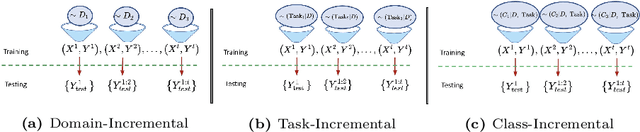
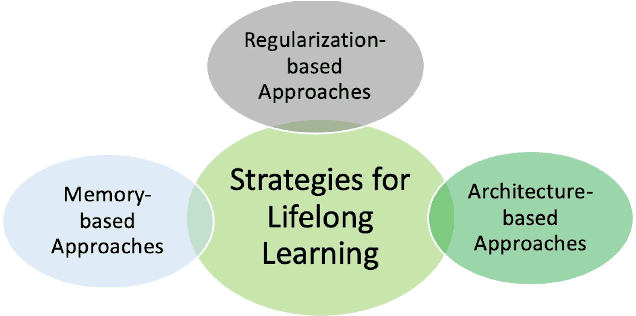
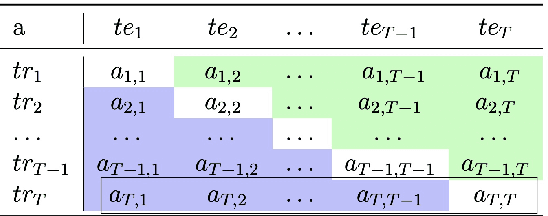
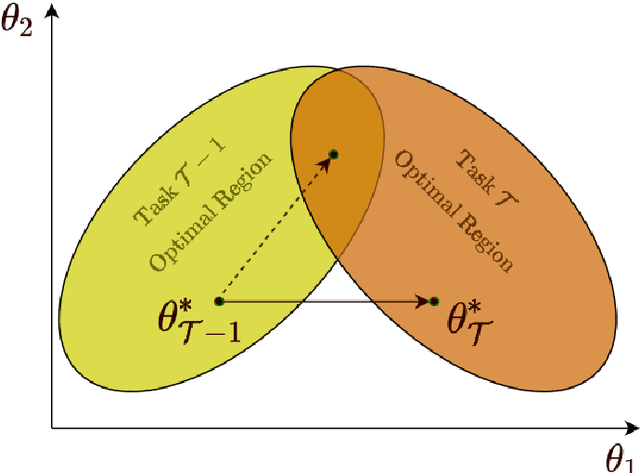
This primer is an attempt to provide a detailed summary of the different facets of lifelong learning. We start with Chapter 2 which provides a high-level overview of lifelong learning systems. In this chapter, we discuss prominent scenarios in lifelong learning (Section 2.4), provide 8 Introduction a high-level organization of different lifelong learning approaches (Section 2.5), enumerate the desiderata for an ideal lifelong learning system (Section 2.6), discuss how lifelong learning is related to other learning paradigms (Section 2.7), describe common metrics used to evaluate lifelong learning systems (Section 2.8). This chapter is more useful for readers who are new to lifelong learning and want to get introduced to the field without focusing on specific approaches or benchmarks. The remaining chapters focus on specific aspects (either learning algorithms or benchmarks) and are more useful for readers who are looking for specific approaches or benchmarks. Chapter 3 focuses on regularization-based approaches that do not assume access to any data from previous tasks. Chapter 4 discusses memory-based approaches that typically use a replay buffer or an episodic memory to save subset of data across different tasks. Chapter 5 focuses on different architecture families (and their instantiations) that have been proposed for training lifelong learning systems. Following these different classes of learning algorithms, we discuss the commonly used evaluation benchmarks and metrics for lifelong learning (Chapter 6) and wrap up with a discussion of future challenges and important research directions in Chapter 7.
Robust Policy Learning over Multiple Uncertainty Sets
Mar 04, 2022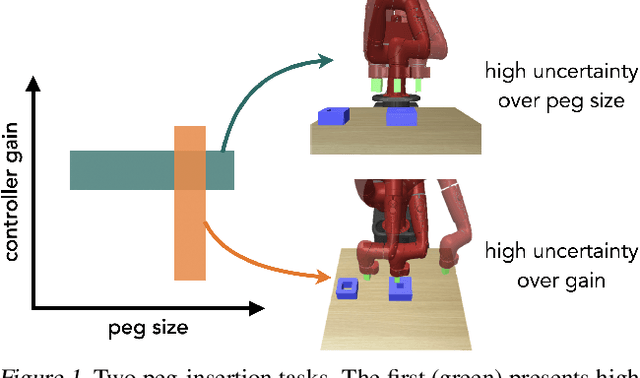
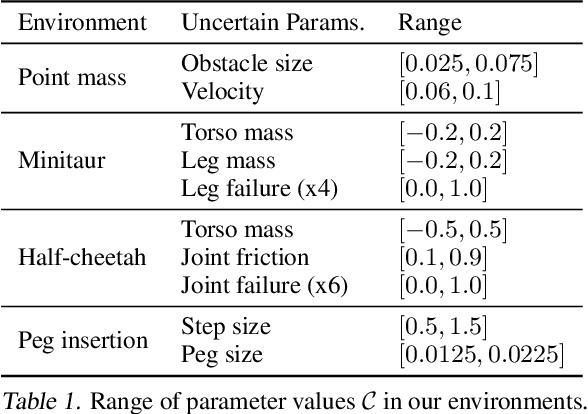
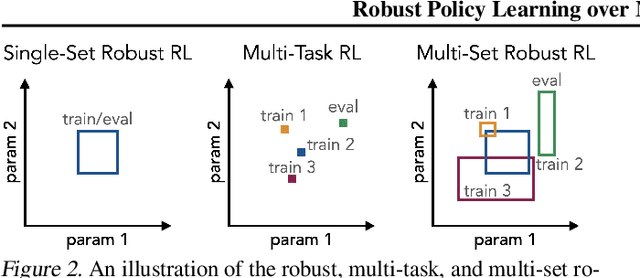

Reinforcement learning (RL) agents need to be robust to variations in safety-critical environments. While system identification methods provide a way to infer the variation from online experience, they can fail in settings where fast identification is not possible. Another dominant approach is robust RL which produces a policy that can handle worst-case scenarios, but these methods are generally designed to achieve robustness to a single uncertainty set that must be specified at train time. Towards a more general solution, we formulate the multi-set robustness problem to learn a policy robust to different perturbation sets. We then design an algorithm that enjoys the benefits of both system identification and robust RL: it reduces uncertainty where possible given a few interactions, but can still act robustly with respect to the remaining uncertainty. On a diverse set of control tasks, our approach demonstrates improved worst-case performance on new environments compared to prior methods based on system identification and on robust RL alone.
Block Contextual MDPs for Continual Learning
Oct 13, 2021
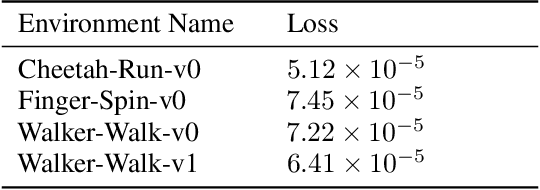
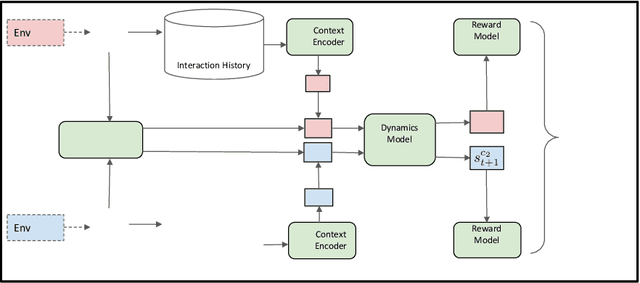
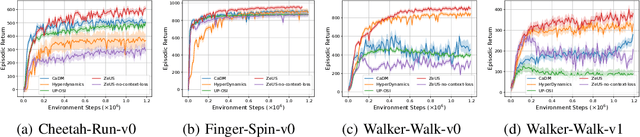
In reinforcement learning (RL), when defining a Markov Decision Process (MDP), the environment dynamics is implicitly assumed to be stationary. This assumption of stationarity, while simplifying, can be unrealistic in many scenarios. In the continual reinforcement learning scenario, the sequence of tasks is another source of nonstationarity. In this work, we propose to examine this continual reinforcement learning setting through the block contextual MDP (BC-MDP) framework, which enables us to relax the assumption of stationarity. This framework challenges RL algorithms to handle both nonstationarity and rich observation settings and, by additionally leveraging smoothness properties, enables us to study generalization bounds for this setting. Finally, we take inspiration from adaptive control to propose a novel algorithm that addresses the challenges introduced by this more realistic BC-MDP setting, allows for zero-shot adaptation at evaluation time, and achieves strong performance on several nonstationary environments.
Multi-Task Reinforcement Learning with Context-based Representations
Feb 11, 2021
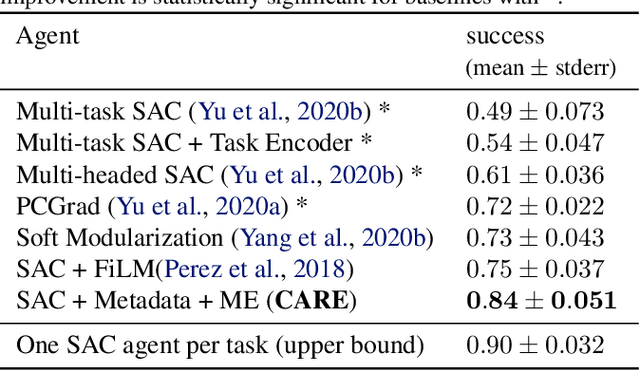
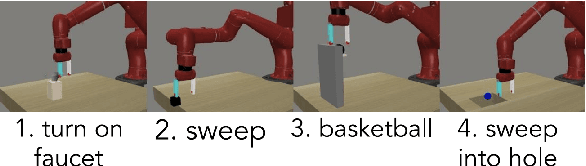
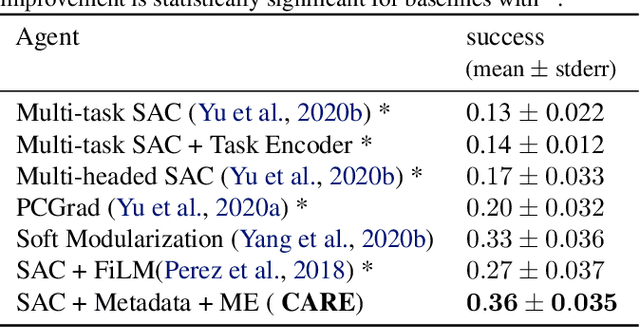
The benefit of multi-task learning over single-task learning relies on the ability to use relations across tasks to improve performance on any single task. While sharing representations is an important mechanism to share information across tasks, its success depends on how well the structure underlying the tasks is captured. In some real-world situations, we have access to metadata, or additional information about a task, that may not provide any new insight in the context of a single task setup alone but inform relations across multiple tasks. While this metadata can be useful for improving multi-task learning performance, effectively incorporating it can be an additional challenge. We posit that an efficient approach to knowledge transfer is through the use of multiple context-dependent, composable representations shared across a family of tasks. In this framework, metadata can help to learn interpretable representations and provide the context to inform which representations to compose and how to compose them. We use the proposed approach to obtain state-of-the-art results in Meta-World, a challenging multi-task benchmark consisting of 50 distinct robotic manipulation tasks.
IIRC: Incremental Implicitly-Refined Classification
Jan 11, 2021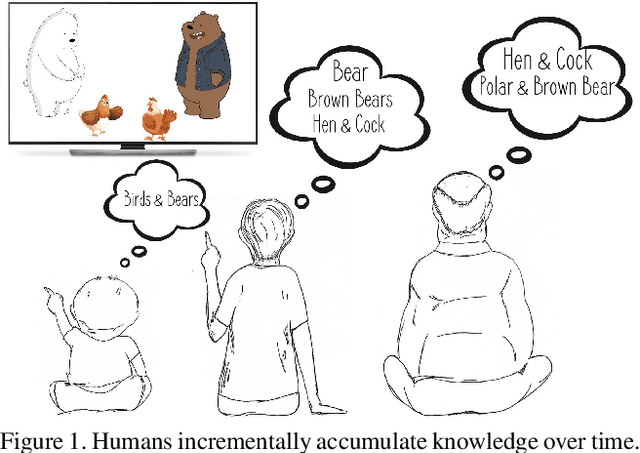

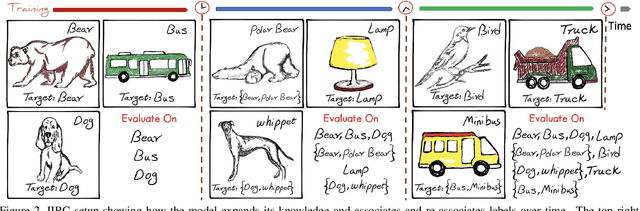

We introduce the "Incremental Implicitly-Refined Classi-fication (IIRC)" setup, an extension to the class incremental learning setup where the incoming batches of classes have two granularity levels. i.e., each sample could have a high-level (coarse) label like "bear" and a low-level (fine) label like "polar bear". Only one label is provided at a time, and the model has to figure out the other label if it has already learnfed it. This setup is more aligned with real-life scenarios, where a learner usually interacts with the same family of entities multiple times, discovers more granularity about them, while still trying not to forget previous knowledge. Moreover, this setup enables evaluating models for some important lifelong learning challenges that cannot be easily addressed under the existing setups. These challenges can be motivated by the example "if a model was trained on the class bear in one task and on polar bear in another task, will it forget the concept of bear, will it rightfully infer that a polar bear is still a bear? and will it wrongfully associate the label of polar bear to other breeds of bear?". We develop a standardized benchmark that enables evaluating models on the IIRC setup. We evaluate several state-of-the-art lifelong learning algorithms and highlight their strengths and limitations. For example, distillation-based methods perform relatively well but are prone to incorrectly predicting too many labels per image. We hope that the proposed setup, along with the benchmark, would provide a meaningful problem setting to the practitioners
A Closer Look at Codistillation for Distributed Training
Oct 06, 2020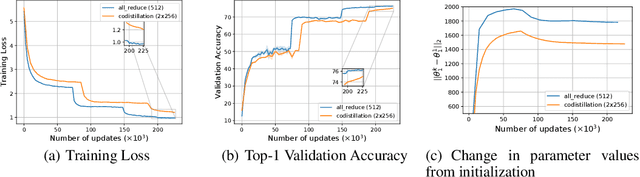
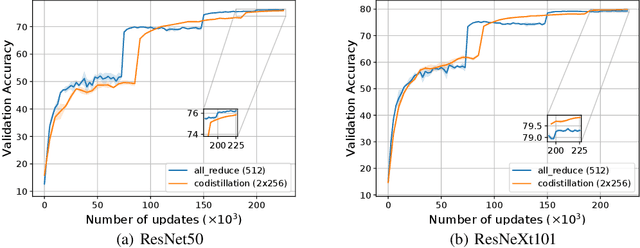
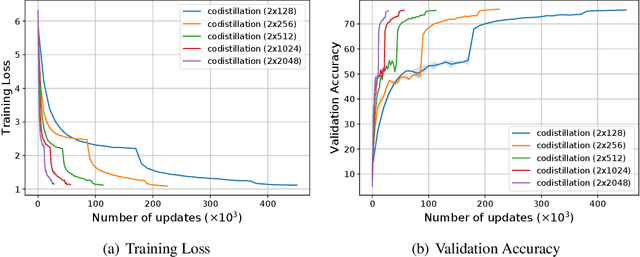
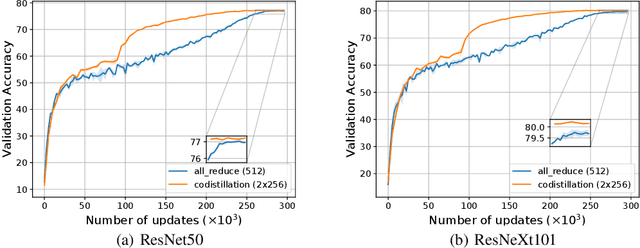
Codistillation has been proposed as a mechanism to share knowledge among concurrently trained models by encouraging them to represent the same function through an auxiliary loss. This contrasts with the more commonly used fully-synchronous data-parallel stochastic gradient descent methods, where different model replicas average their gradients (or parameters) at every iteration and thus maintain identical parameters. We investigate codistillation in a distributed training setup, complementing previous work which focused on extremely large batch sizes. Surprisingly, we find that even at moderate batch sizes, models trained with codistillation can perform as well as models trained with synchronous data-parallel methods, despite using a much weaker synchronization mechanism. These findings hold across a range of batch sizes and learning rate schedules, as well as different kinds of models and datasets. Obtaining this level of accuracy, however, requires properly accounting for the regularization effect of codistillation, which we highlight through several empirical observations. Overall, this work contributes to a better understanding of codistillation and how to best take advantage of it in a distributed computing environment.
Multi-Task Reinforcement Learning as a Hidden-Parameter Block MDP
Jul 28, 2020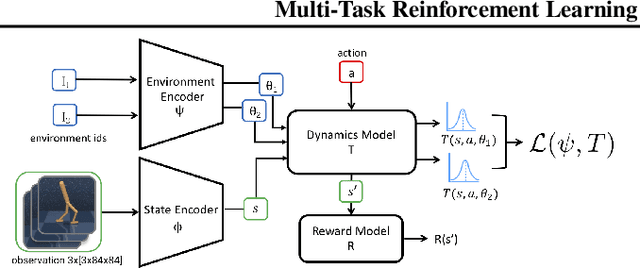
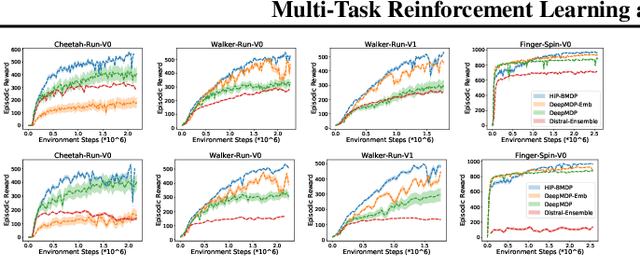
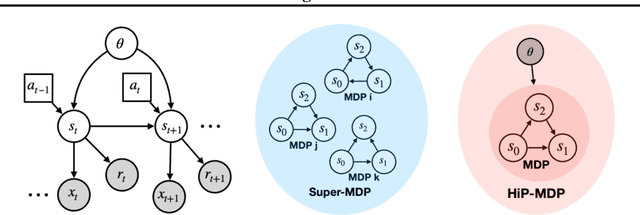

Multi-task reinforcement learning is a rich paradigm where information from previously seen environments can be leveraged for better performance and improved sample-efficiency in new environments. In this work, we leverage ideas of common structure underlying a family of Markov decision processes (MDPs) to improve performance in the few-shot regime. We use assumptions of structure from Hidden-Parameter MDPs and Block MDPs to propose a new framework, HiP-BMDP, and approach for learning a common representation and universal dynamics model. To this end, we provide transfer and generalization bounds based on task and state similarity, along with sample complexity bounds that depend on the aggregate number of samples across tasks, rather than the number of tasks, a significant improvement over prior work. To demonstrate the efficacy of the proposed method, we empirically compare and show improvements against other multi-task and meta-reinforcement learning baselines.
Ideas for Improving the Field of Machine Learning: Summarizing Discussion from the NeurIPS 2019 Retrospectives Workshop
Jul 21, 2020This report documents ideas for improving the field of machine learning, which arose from discussions at the ML Retrospectives workshop at NeurIPS 2019. The goal of the report is to disseminate these ideas more broadly, and in turn encourage continuing discussion about how the field could improve along these axes. We focus on topics that were most discussed at the workshop: incentives for encouraging alternate forms of scholarship, re-structuring the review process, participation from academia and industry, and how we might better train computer scientists as scientists. Videos from the workshop can be accessed at https://slideslive.com/neurips/west-114-115-retrospectives-a-venue-for-selfreflection-in-ml-research
Evaluating Logical Generalization in Graph Neural Networks
Mar 14, 2020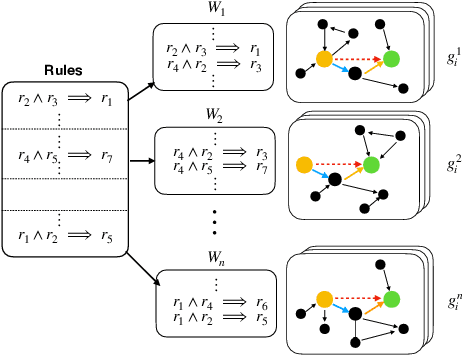
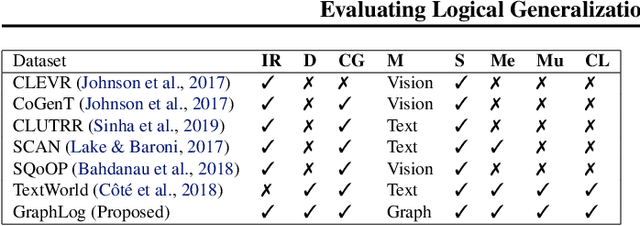
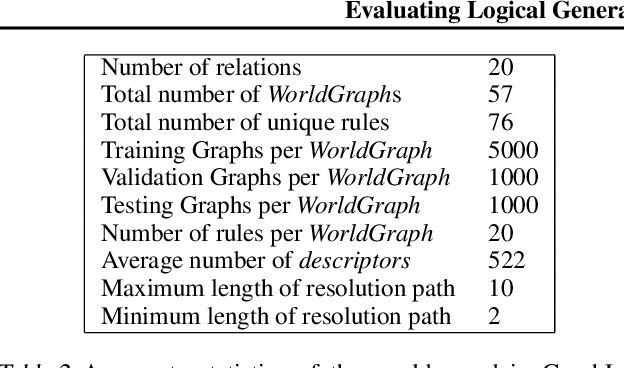
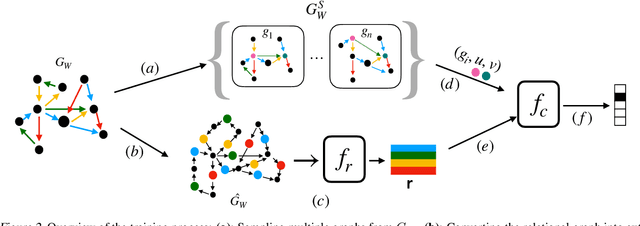
Recent research has highlighted the role of relational inductive biases in building learning agents that can generalize and reason in a compositional manner. However, while relational learning algorithms such as graph neural networks (GNNs) show promise, we do not understand how effectively these approaches can adapt to new tasks. In this work, we study the task of logical generalization using GNNs by designing a benchmark suite grounded in first-order logic. Our benchmark suite, GraphLog, requires that learning algorithms perform rule induction in different synthetic logics, represented as knowledge graphs. GraphLog consists of relation prediction tasks on 57 distinct logical domains. We use GraphLog to evaluate GNNs in three different setups: single-task supervised learning, multi-task pretraining, and continual learning. Unlike previous benchmarks, our approach allows us to precisely control the logical relationship between the different tasks. We find that the ability for models to generalize and adapt is strongly determined by the diversity of the logical rules they encounter during training, and our results highlight new challenges for the design of GNN models. We publicly release the dataset and code used to generate and interact with the dataset at https://www.cs.mcgill.ca/~ksinha4/graphlog.