 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-To-Fine Tensor Trains for Compact Visual Representations
Jun 06, 2024



The ability to learn compact, high-quality, and easy-to-optimize representations for visual data is paramount to many applications such as novel view synthesis and 3D reconstruction. Recent work has shown substantial success in using tensor networks to design such compact and high-quality representations. However, the ability to optimize tensor-based representations, and in particular, the highly compact tensor train representation, is still lacking. This has prevented practitioners from deploying the full potential of tensor networks for visual data. To this end, we propose 'Prolongation Upsampling Tensor Train (PuTT)', a novel method for learning tensor train representations in a coarse-to-fine manner. Our method involves the prolonging or `upsampling' of a learned tensor train representation, creating a sequence of 'coarse-to-fine' tensor trains that are incrementally refined. We evaluate our representation along three axes: (1). compression, (2). denoising capability, and (3). image completion capability. To assess these axes, we consider the tasks of image fitting, 3D fitting, and novel view synthesis, where our method shows an improved performance compared to state-of-the-art tensor-based methods. For full results see our project webpage: https://sebulo.github.io/PuTT_website/
LoQT: Low Rank Adapters for Quantized Training
May 26, 2024



Training of large neural networks requires significant computational resources. Despite advances using low-rank adapters and quantization, pretraining of models such as LLMs on consumer hardware has not been possible without model sharding, offloading during training, or per-layer gradient updates. To address these limitations, we propose LoQT, a method for efficiently training quantized models. LoQT uses gradient-based tensor factorization to initialize low-rank trainable weight matrices that are periodically merged into quantized full-rank weight matrices. Our approach is suitable for both pretraining and fine-tuning of models, which we demonstrate experimentally for language modeling and downstream task adaptation. We find that LoQT enables efficient training of models up to 7B parameters on a consumer-grade 24GB GPU. We also demonstrate the feasibility of training a 13B parameter model using per-layer gradient updates on the same hardware.
MMEarth: Exploring Multi-Modal Pretext Tasks For Geospatial Representation Learning
May 04, 2024



The volume of unlabelled Earth observation (EO) data is huge, but many important applications lack labelled training data. However, EO data offers the unique opportunity to pair data from different modalities and sensors automatically based on geographic location and time, at virtually no human labor cost. We seize this opportunity to create a diverse multi-modal pretraining dataset at global scale. Using this new corpus of 1.2 million locations, we propose a Multi-Pretext Masked Autoencoder (MP-MAE) approach to learn general-purpose representations for optical satellite images. Our approach builds on the ConvNeXt V2 architecture, a fully convolutional masked autoencoder (MAE). Drawing upon a suite of multi-modal pretext tasks, we demonstrate that our MP-MAE approach outperforms both MAEs pretrained on ImageNet and MAEs pretrained on domain-specific satellite images. This is shown on several downstream tasks including image classification and semantic segmentation. We find that multi-modal pretraining notably improves the linear probing performance, e.g. 4pp on BigEarthNet and 16pp on So2Sat, compared to pretraining on optical satellite images only. We show that this also leads to better label and parameter efficiency which are crucial aspects in global scale applications.
Rethinking Few-shot 3D Point Cloud Semantic Segmentation
Mar 01, 2024



This paper revisits few-shot 3D point cloud semantic segmentation (FS-PCS), with a focus on two significant issues in the state-of-the-art: foreground leakage and sparse point distribution. The former arises from non-uniform point sampling, allowing models to distinguish the density disparities between foreground and background for easier segmentation. The latter results from sampling only 2,048 points, limiting semantic information and deviating from the real-world practice. To address these issues, we introduce a standardized FS-PCS setting, upon which a new benchmark is built. Moreover, we propose a novel FS-PCS model. While previous methods are based on feature optimization by mainly refining support features to enhance prototypes, our method is based on correlation optimization, referred to as Correlation Optimization Segmentation (COSeg). Specifically, we compute Class-specific Multi-prototypical Correlation (CMC) for each query point, representing its correlations to category prototypes. Then, we propose the Hyper Correlation Augmentation (HCA) module to enhance CMC. Furthermore, tackling the inherent property of few-shot training to incur base susceptibility for models, we propose to learn non-parametric prototypes for the base classes during training. The learned base prototypes are used to calibrate correlations for the background class through a Base Prototypes Calibration (BPC) module. Experiments on popular datasets demonstrate the superiority of COSeg over existing methods. The code is available at: https://github.com/ZhaochongAn/COSeg
Familiarity-Based Open-Set Recognition Under Adversarial Attacks
Nov 08, 2023Open-set recognition (OSR), the identification of novel categories, can be a critical component when deploying classification models in real-world applications. Recent work has shown that familiarity-based scoring rules such as the Maximum Softmax Probability (MSP) or the Maximum Logit Score (MLS) are strong baselines when the closed-set accuracy is high. However, one of the potential weaknesses of familiarity-based OSR are adversarial attacks. Here, we present gradient-based adversarial attacks on familiarity scores for both types of attacks, False Familiarity and False Novelty attacks, and evaluate their effectiveness in informed and uninformed settings on TinyImageNet.
Prompt, Condition, and Generate: Classification of Unsupported Claims with In-Context Learning
Sep 19, 2023



Unsupported and unfalsifiable claims we encounter in our daily lives can influence our view of the world. Characterizing, summarizing, and -- more generally -- making sense of such claims, however, can be challenging. In this work, we focus on fine-grained debate topics and formulate a new task of distilling, from such claims, a countable set of narratives. We present a crowdsourced dataset of 12 controversial topics, comprising more than 120k arguments, claims, and comments from heterogeneous sources, each annotated with a narrative label. We further investigate how large language models (LLMs) can be used to synthesise claims using In-Context Learning. We find that generated claims with supported evidence can be used to improve the performance of narrative classification models and, additionally, that the same model can infer the stance and aspect using a few training examples. Such a model can be useful in applications which rely on narratives , e.g. fact-checking.
Learning to Taste: A Multimodal Wine Dataset
Sep 07, 2023



We present WineSensed, a large multimodal wine dataset for studying the relations between visual perception, language, and flavor. The dataset encompasses 897k images of wine labels and 824k reviews of wines curated from the Vivino platform. It has over 350k unique vintages, annotated with year, region, rating, alcohol percentage, price, and grape composition. We obtained fine-grained flavor annotations on a subset by conducting a wine-tasting experiment with 256 participants who were asked to rank wines based on their similarity in flavor, resulting in more than 5k pairwise flavor distances. We propose a low-dimensional concept embedding algorithm that combines human experience with automatic machine similarity kernels. We demonstrate that this shared concept embedding space improves upon separate embedding spaces for coarse flavor classification (alcohol percentage, country, grape, price, rating) and aligns with the intricate human perception of flavor.
Fashionpedia-Taste: A Dataset towards Explaining Human Fashion Taste
May 03, 2023



Existing fashion datasets do not consider the multi-facts that cause a consumer to like or dislike a fashion image. Even two consumers like a same fashion image, they could like this image for total different reasons. In this paper, we study the reason why a consumer like a certain fashion image. Towards this goal, we introduce an interpretability dataset, Fashionpedia-taste, consist of rich annotation to explain why a subject like or dislike a fashion image from the following 3 perspectives: 1) localized attributes; 2) human attention; 3) caption. Furthermore, subjects are asked to provide their personal attributes and preference on fashion, such as personality and preferred fashion brands. Our dataset makes it possible for researchers to build computational models to fully understand and interpret human fashion taste from different humanistic perspectives and modalities.
Fashionpedia-Ads: Do Your Favorite Advertisements Reveal Your Fashion Taste?
May 03, 2023
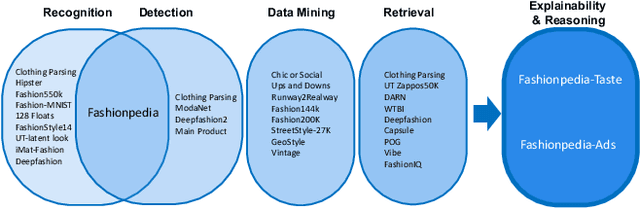


Consumers are exposed to advertisements across many different domains on the internet, such as fashion, beauty, car, food, and others. On the other hand, fashion represents second highest e-commerce shopping category. Does consumer digital record behavior on various fashion ad images reveal their fashion taste? Does ads from other domains infer their fashion taste as well? In this paper, we study the correlation between advertisements and fashion taste. Towards this goal, we introduce a new dataset, Fashionpedia-Ads, which asks subjects to provide their preferences on both ad (fashion, beauty, car, and dessert) and fashion product (social network and e-commerce style) images. Furthermore, we exhaustively collect and annotate the emotional, visual and textual information on the ad images from multi-perspectives (abstractive level, physical level, captions, and brands). We open-source Fashionpedia-Ads to enable future studies and encourage more approaches to interpretability research between advertisements and fashion taste.
Discriminative Class Tokens for Text-to-Image Diffusion Models
Mar 30, 2023Recent advances in text-to-image diffusion models have enabled the generation of diverse and high-quality images. However, generated images often fall short of depicting subtle details and are susceptible to errors due to ambiguity in the input text. One way of alleviating these issues is to train diffusion models on class-labeled datasets. This comes with a downside, doing so limits their expressive power: (i) supervised datasets are generally small compared to large-scale scraped text-image datasets on which text-to-image models are trained, and so the quality and diversity of generated images are severely affected, or (ii) the input is a hard-coded label, as opposed to free-form text, which limits the control over the generated images. In this work, we propose a non-invasive fine-tuning technique that capitalizes on the expressive potential of free-form text while achieving high accuracy through discriminative signals from a pretrained classifier, which guides the generation. This is done by iteratively modifying the embedding of a single input token of a text-to-image diffusion model, using the classifier, by steering generated images toward a given target class. Our method is fast compared to prior fine-tuning methods and does not require a collection of in-class images or retraining of a noise-tolerant classifier. We evaluate our method extensively, showing that the generated images are: (i) more accurate and of higher quality than standard diffusion models, (ii) can be used to augment training data in a low-resource setting, and (iii) reveal information about the data used to train the guiding classifier. The code is available at \url{https://github.com/idansc/discriminative_class_tokens}