 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Sensitivity Analysis for Parametric Robust Markov Chains
May 01, 2023We provide a novel method for sensitivity analysis of parametric robust Markov chains. These models incorporate parameters and sets of probability distributions to alleviate the often unrealistic assumption that precise probabilities are available. We measure sensitivity in terms of partial derivatives with respect to the uncertain transition probabilities regarding measures such as the expected reward. As our main contribution, we present an efficient method to compute these partial derivatives. To scale our approach to models with thousands of parameters, we present an extension of this method that selects the subset of $k$ parameters with the highest partial derivative. Our methods are based on linear programming and differentiating these programs around a given value for the parameters. The experiments show the applicability of our approach on models with over a million states and thousands of parameters. Moreover, we embed the results within an iterative learning scheme that profits from having access to a dedicated sensitivity analysis.
COOL-MC: A Comprehensive Tool for Reinforcement Learning and Model Checking
Sep 15, 2022
This paper presents COOL-MC, a tool that integrates state-of-the-art reinforcement learning (RL) and model checking. Specifically, the tool builds upon the OpenAI gym and the probabilistic model checker Storm. COOL-MC provides the following features: (1) a simulator to train RL policies in the OpenAI gym for Markov decision processes (MDPs) that are defined as input for Storm, (2) a new model builder for Storm, which uses callback functions to verify (neural network) RL policies, (3) formal abstractions that relate models and policies specified in OpenAI gym or Storm, and (4) algorithms to obtain bounds on the performance of so-called permissive policies. We describe the components and architecture of COOL-MC and demonstrate its features on multiple benchmark environments.
Abstraction-Refinement for Hierarchical Probabilistic Models
Jun 06, 2022
Markov decision processes are a ubiquitous formalism for modelling systems with non-deterministic and probabilistic behavior. Verification of these models is subject to the famous state space explosion problem. We alleviate this problem by exploiting a hierarchical structure with repetitive parts. This structure not only occurs naturally in robotics, but also in probabilistic programs describing, e.g., network protocols. Such programs often repeatedly call a subroutine with similar behavior. In this paper, we focus on a local case, in which the subroutines have a limited effect on the overall system state. The key ideas to accelerate analysis of such programs are (1) to treat the behavior of the subroutine as uncertain and only remove this uncertainty by a detailed analysis if needed, and (2) to abstract similar subroutines into a parametric template, and then analyse this template. These two ideas are embedded into an abstraction-refinement loop that analyses hierarchical MDPs. A prototypical implementation shows the efficacy of the approach.
Safe Reinforcement Learning via Shielding for POMDPs
Apr 02, 2022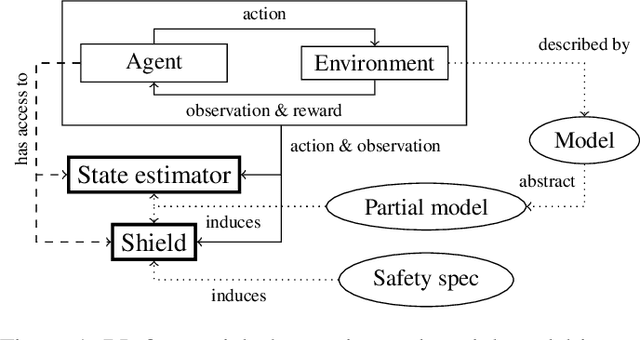
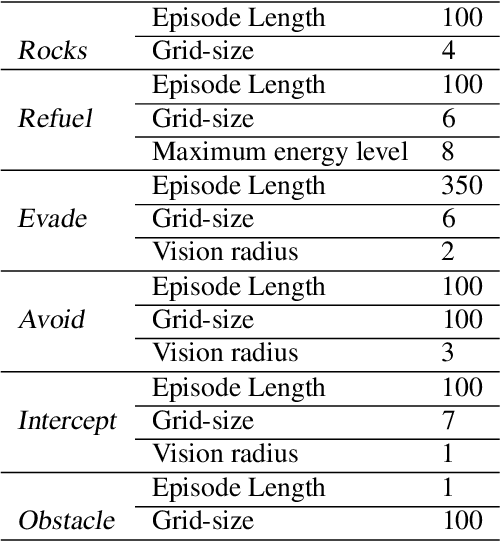
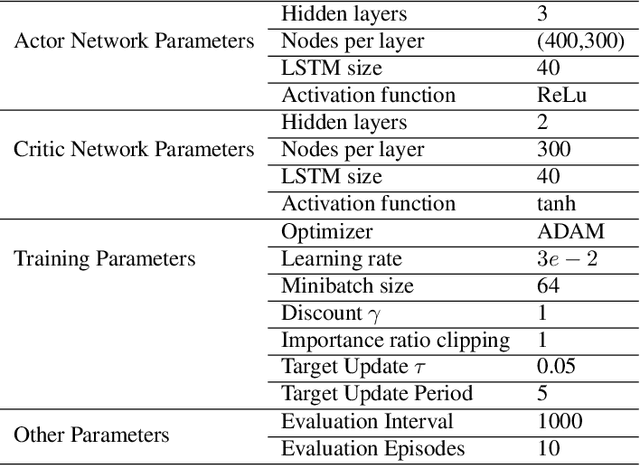
Reinforcement learning (RL) in safety-critical environments requires an agent to avoid decisions with catastrophic consequences. Various approaches addressing the safety of RL exist to mitigate this problem. In particular, so-called shields provide formal safety guarantees on the behavior of RL agents based on (partial) models of the agents' environment. Yet, the state-of-the-art generally assumes perfect sensing capabilities of the agents, which is unrealistic in real-life applications. The standard models to capture scenarios with limited sensing are partially observable Markov decision processes (POMDPs). Safe RL for these models remains an open problem so far. We propose and thoroughly evaluate a tight integration of formally-verified shields for POMDPs with state-of-the-art deep RL algorithms and create an efficacious method that safely learns policies under partial observability. We empirically demonstrate that an RL agent using a shield, beyond being safe, converges to higher values of expected reward. Moreover, shielded agents need an order of magnitude fewer training episodes than unshielded agents, especially in challenging sparse-reward settings.
Querying Labelled Data with Scenario Programs for Sim-to-Real Validation
Dec 01, 2021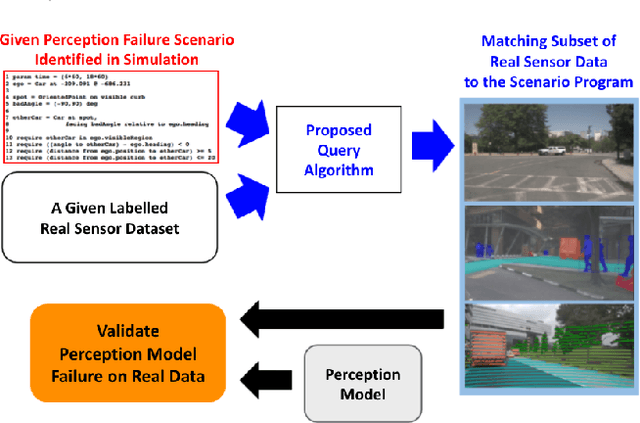

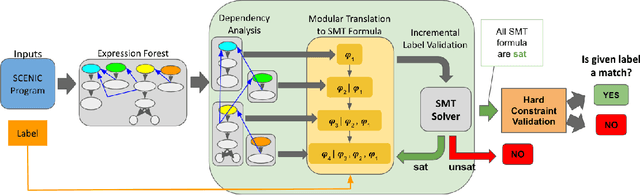
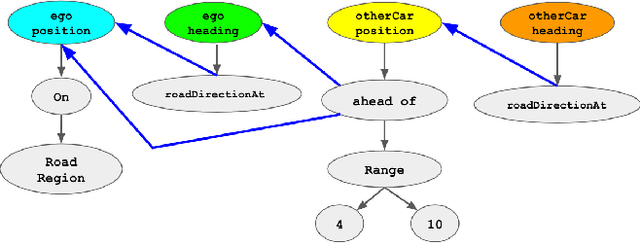
Simulation-based testing of autonomous vehicles (AVs) has become an essential complement to road testing to ensure safety. Consequently, substantial research has focused on searching for failure scenarios in simulation. However, a fundamental question remains: are AV failure scenarios identified in simulation meaningful in reality, i.e., are they reproducible on the real system? Due to the sim-to-real gap arising from discrepancies between simulated and real sensor data, a failure scenario identified in simulation can be either a spurious artifact of the synthetic sensor data or an actual failure that persists with real sensor data. An approach to validate simulated failure scenarios is to identify instances of the scenario in a corpus of real data, and check if the failure persists on the real data. To this end, we propose a formal definition of what it means for a labelled data item to match an abstract scenario, encoded as a scenario program using the SCENIC probabilistic programming language. Using this definition, we develop a querying algorithm which, given a scenario program and a labelled dataset, finds the subset of data matching the scenario. Experiments demonstrate that our algorithm is accurate and efficient on a variety of realistic traffic scenarios, and scales to a reasonable number of agents.
Convex Optimization for Parameter Synthesis in MDPs
Jun 30, 2021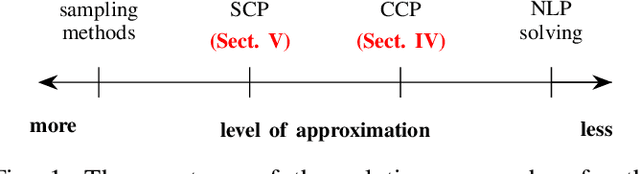
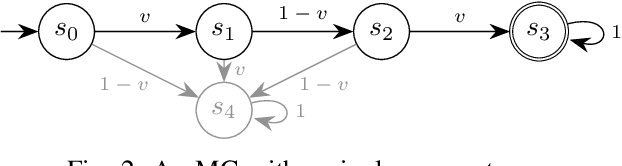
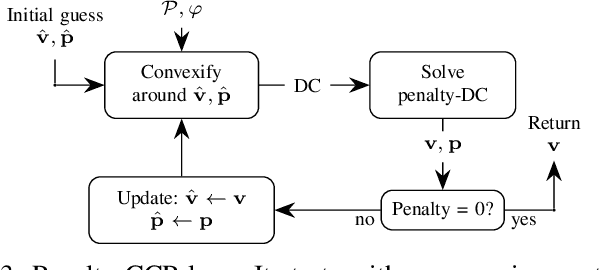
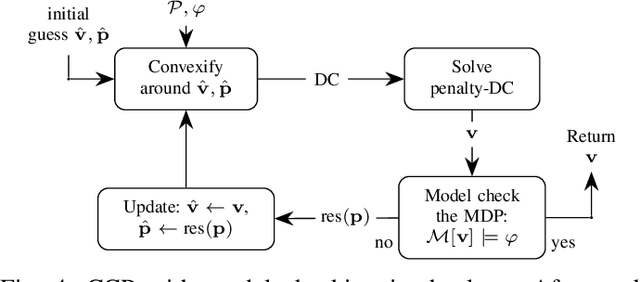
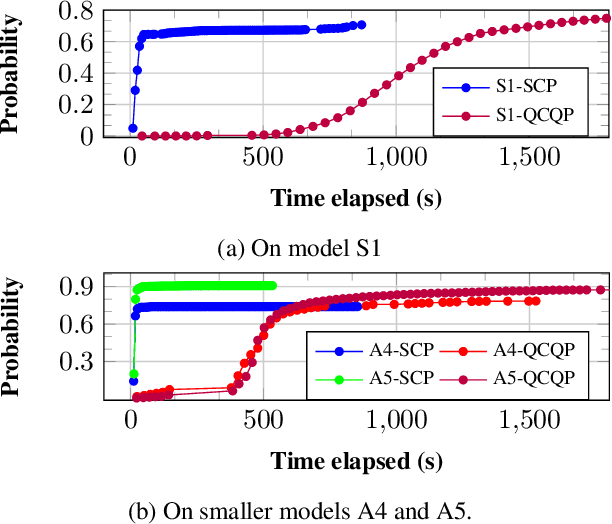
Probabilistic model checking aims to prove whether a Markov decision process (MDP) satisfies a temporal logic specification. The underlying methods rely on an often unrealistic assumption that the MDP is precisely known. Consequently, parametric MDPs (pMDPs) extend MDPs with transition probabilities that are functions over unspecified parameters. The parameter synthesis problem is to compute an instantiation of these unspecified parameters such that the resulting MDP satisfies the temporal logic specification. We formulate the parameter synthesis problem as a quadratically constrained quadratic program (QCQP), which is nonconvex and is NP-hard to solve in general. We develop two approaches that iteratively obtain locally optimal solutions. The first approach exploits the so-called convex-concave procedure (CCP), and the second approach utilizes a sequential convex programming (SCP) method. The techniques improve the runtime and scalability by multiple orders of magnitude compared to black-box CCP and SCP by merging ideas from convex optimization and probabilistic model checking. We demonstrate the approaches on a satellite collision avoidance problem with hundreds of thousands of states and tens of thousands of parameters and their scalability on a wide range of commonly used benchmarks.
Runtime Monitoring for Markov Decision Processes
May 26, 2021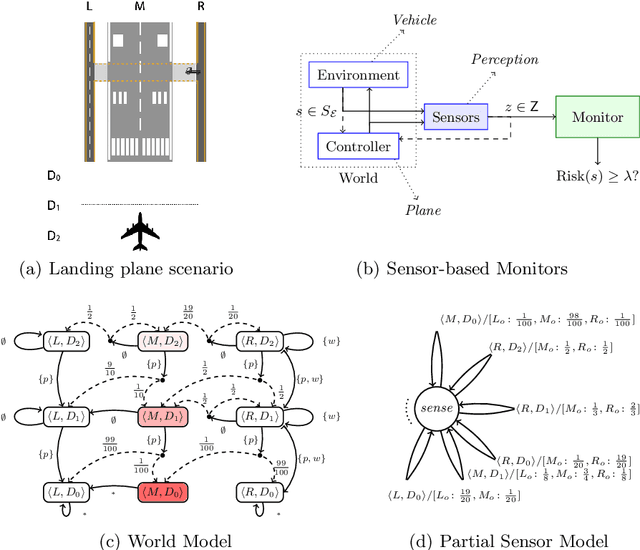
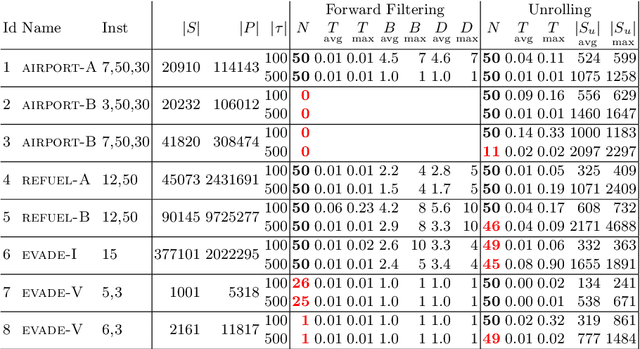
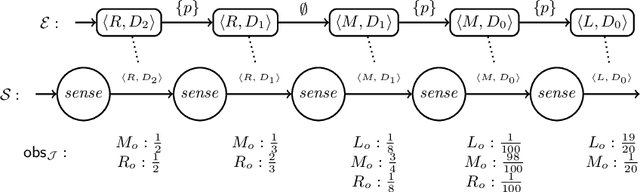
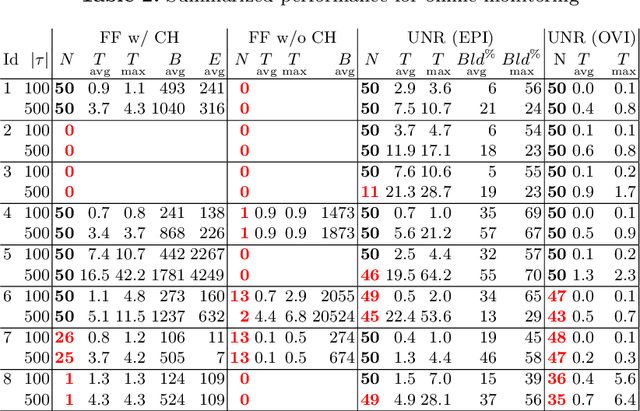
We investigate the problem of monitoring partially observable systems with nondeterministic and probabilistic dynamics. In such systems, every state may be associated with a risk, e.g., the probability of an imminent crash. During runtime, we obtain partial information about the system state in form of observations. The monitor uses this information to estimate the risk of the (unobservable) current system state. Our results are threefold. First, we show that extensions of state estimation approaches do not scale due the combination of nondeterminism and probabilities. While convex hull algorithms improve the practical runtime, they do not prevent an exponential memory blowup. Second, we present a tractable algorithm based on model checking conditional reachability probabilities. Third, we provide prototypical implementations and manifest the applicability of our algorithms to a range of benchmarks. The results highlight the possibilities and boundaries of our novel algorithms.
Entropy-Guided Control Improvisation
Mar 09, 2021
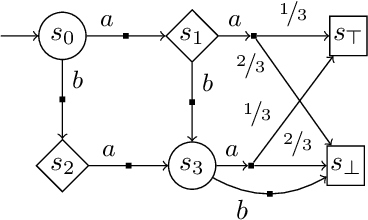
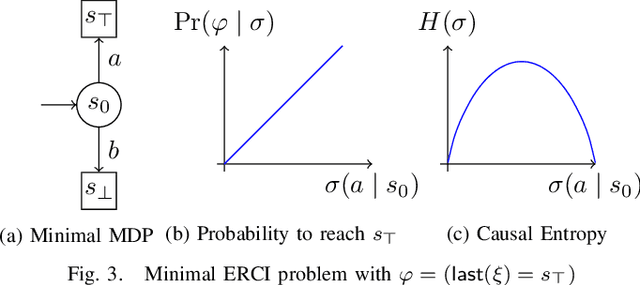
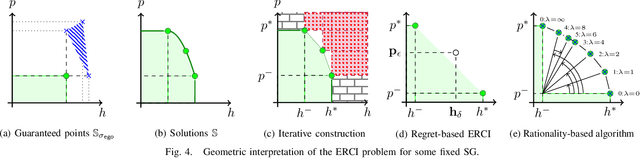
High level declarative constraints provide a powerful (and popular) way to define and construct control policies; however, most synthesis algorithms do not support specifying the degree of randomness (unpredictability) of the resulting controller. In many contexts, e.g., patrolling, testing, behavior prediction, and planning on idealized models, predictable or biased controllers are undesirable. To address these concerns, we introduce the \emph{Entropic Reactive Control Improvisation} (ERCI) framework and algorithm that supports synthesizing control policies for stochastic games that are declaratively specified by (i) a \emph{hard constraint} specifying what must occur (ii) a \emph{soft constraint} specifying what typically occurs, and (iii) a \emph{randomization constraint} specifying the unpredictability and variety of the controller, as quantified using causal entropy. This framework, which extends the state-of-the-art by supporting arbitrary combinations of adversarial and probabilistic uncertainty in the environment, enables a flexible modeling formalism which we argue, theoretically and empirically, remains tractable.
Inductive Synthesis for Probabilistic Programs Reaches New Horizons
Jan 29, 2021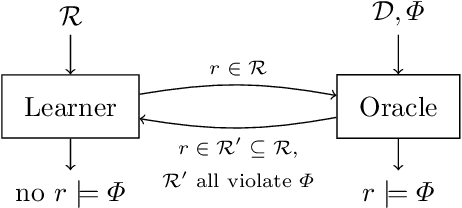

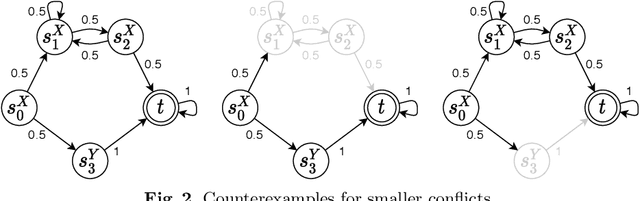
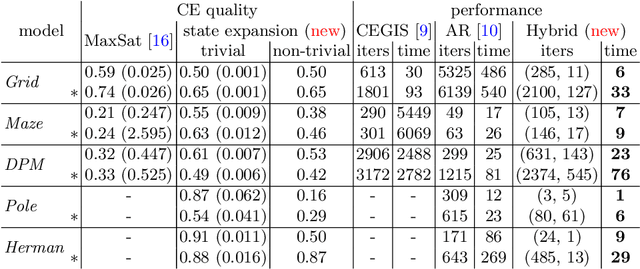
This paper presents a novel method for the automated synthesis of probabilistic programs. The starting point is a program sketch representing a finite family of finite-state Markov chains with related but distinct topologies, and a PCTL specification. The method builds on a novel inductive oracle that greedily generates counter-examples (CEs) for violating programs and uses them to prune the family. These CEs leverage the semantics of the family in the form of bounds on its best- and worst-case behaviour provided by a deductive oracle using an MDP abstraction. The method further monitors the performance of the synthesis and adaptively switches between the inductive and deductive reasoning. Our experiments demonstrate that the novel CE construction provides a significantly faster and more effective pruning strategy leading to acceleration of the synthesis process on a wide range of benchmarks. For challenging problems, such as the synthesis of decentralized partially-observable controllers, we reduce the run-time from a day to minutes.
Robust Finite-State Controllers for Uncertain POMDPs
Sep 24, 2020
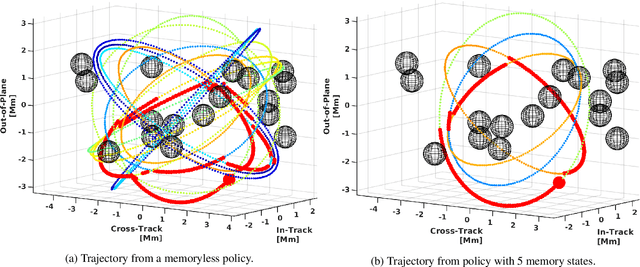
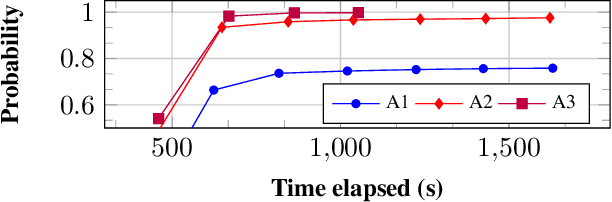
Uncertain partially observable Markov decision processes (uPOMDPs) allow the probabilistic transition and observation functions of standard POMDPs to belong to a so-called uncertainty set. Such uncertainty sets capture uncountable sets of probability distributions. We develop an algorithm to compute finite-memory policies for uPOMDPs that robustly satisfy given specifications against any admissible distribution. In general, computing such policies is both theoretically and practically intractable. We provide an efficient solution to this problem in four steps. (1) We state the underlying problem as a nonconvex optimization problem with infinitely many constraints. (2) A dedicated dualization scheme yields a dual problem that is still nonconvex but has finitely many constraints. (3) We linearize this dual problem and (4) solve the resulting finite linear program to obtain locally optimal solutions to the original problem. The resulting problem formulation is exponentially smaller than those resulting from existing methods. We demonstrate the applicability of our algorithm using large instances of an aircraft collision-avoidance scenario and a novel spacecraft motion planning case study.