 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOP-Q: Safety-First Reinforcement Learning for Robot Control via Cholesky-Ordered Projection
Jun 03, 2026Safe robot control requires maximizing return while satisfying safety constraints. In off-policy safe reinforcement learning, reward and safety Q-values are commonly learned by separate critic ensembles, with uncertainty handled independently for each objective. This objective-wise treatment neglects inter-objective correlation and can lead to overly conservative value estimates, thereby reducing sample efficiency. To address this issue, we propose Cholesky-Ordered Projection Q-learning (COP-Q), a safety-first method that incorporates inter-objective covariance into vector-valued Q-value estimation. COP-Q constructs a generalized confidence bound in the joint Q-value space and uses Cholesky factorization to encode objective priority in a sequential form. This preserves conservatism on safety while adaptively reducing excessive conservatism on the reward objective. The resulting estimate is used in both temporal-difference target computation and actor optimization. COP-Q incurs minimal computational overhead and is readily compatible with most existing deep Q-learning frameworks. Experiments on robot locomotion in Brax and safe navigation in Safety-Gymnasium, covering both hard- and soft-safety settings, demonstrate that COP-Q achieves strong safety performance together with competitive or improved sample efficiency relative to representative baselines.
Off-Policy Safe Reinforcement Learning with Constrained Optimistic Exploration
Mar 25, 2026When safety is formulated as a limit of cumulative cost, safe reinforcement learning (RL) aims to learn policies that maximize return subject to the cost constraint in data collection and deployment. Off-policy safe RL methods, although offering high sample efficiency, suffer from constraint violations due to cost-agnostic exploration and estimation bias in cumulative cost. To address this issue, we propose Constrained Optimistic eXploration Q-learning (COX-Q), an off-policy safe RL algorithm that integrates cost-bounded online exploration and conservative offline distributional value learning. First, we introduce a novel cost-constrained optimistic exploration strategy that resolves gradient conflicts between reward and cost in the action space and adaptively adjusts the trust region to control the training cost. Second, we adopt truncated quantile critics to stabilize the cost value learning. Quantile critics also quantify epistemic uncertainty to guide exploration. Experiments on safe velocity, safe navigation, and autonomous driving tasks demonstrate that COX-Q achieves high sample efficiency, competitive test safety performance, and controlled data collection cost. The results highlight COX-Q as a promising RL method for safety-critical applications.
On the Equivalence of Random Network Distillation, Deep Ensembles, and Bayesian Inference
Feb 26, 2026Uncertainty quantification is central to safe and efficient deployments of deep learning models, yet many computationally practical methods lack lacking rigorous theoretical motivation. Random network distillation (RND) is a lightweight technique that measures novelty via prediction errors against a fixed random target. While empirically effective, it has remained unclear what uncertainties RND measures and how its estimates relate to other approaches, e.g. Bayesian inference or deep ensembles. This paper establishes these missing theoretical connections by analyzing RND within the neural tangent kernel framework in the limit of infinite network width. Our analysis reveals two central findings in this limit: (1) The uncertainty signal from RND -- its squared self-predictive error -- is equivalent to the predictive variance of a deep ensemble. (2) By constructing a specific RND target function, we show that the RND error distribution can be made to mirror the centered posterior predictive distribution of Bayesian inference with wide neural networks. Based on this equivalence, we moreover devise a posterior sampling algorithm that generates i.i.d. samples from an exact Bayesian posterior predictive distribution using this modified \textit{Bayesian RND} model. Collectively, our findings provide a unified theoretical perspective that places RND within the principled frameworks of deep ensembles and Bayesian inference, and offer new avenues for efficient yet theoretically grounded uncertainty quantification methods.
Sparse Masked Attention Policies for Reliable Generalization
Feb 23, 2026In reinforcement learning, abstraction methods that remove unnecessary information from the observation are commonly used to learn policies which generalize better to unseen tasks. However, these methods often overlook a crucial weakness: the function which extracts the reduced-information representation has unknown generalization ability in unseen observations. In this paper, we address this problem by presenting an information removal method which more reliably generalizes to new states. We accomplish this by using a learned masking function which operates on, and is integrated with, the attention weights within an attention-based policy network. We demonstrate that our method significantly improves policy generalization to unseen tasks in the Procgen benchmark compared to standard PPO and masking approaches.
Parallelizing Tree Search with Twice Sequential Monte Carlo
Nov 18, 2025Model-based reinforcement learning (RL) methods that leverage search are responsible for many milestone breakthroughs in RL. Sequential Monte Carlo (SMC) recently emerged as an alternative to the Monte Carlo Tree Search (MCTS) algorithm which drove these breakthroughs. SMC is easier to parallelize and more suitable to GPU acceleration. However, it also suffers from large variance and path degeneracy which prevent it from scaling well with increased search depth, i.e., increased sequential compute. To address these problems, we introduce Twice Sequential Monte Carlo Tree Search (TSMCTS). Across discrete and continuous environments TSMCTS outperforms the SMC baseline as well as a popular modern version of MCTS. Through variance reduction and mitigation of path degeneracy, TSMCTS scales favorably with sequential compute while retaining the properties that make SMC natural to parallelize.
Universal Value-Function Uncertainties
May 27, 2025


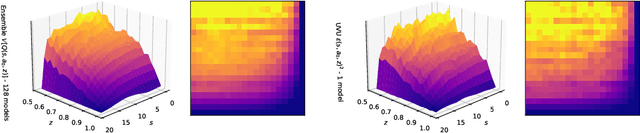
Estimating epistemic uncertainty in value functions is a crucial challenge for many aspects of reinforcement learning (RL), including efficient exploration, safe decision-making, and offline RL. While deep ensembles provide a robust method for quantifying value uncertainty, they come with significant computational overhead. Single-model methods, while computationally favorable, often rely on heuristics and typically require additional propagation mechanisms for myopic uncertainty estimates. In this work we introduce universal value-function uncertainties (UVU), which, similar in spirit to random network distillation (RND), quantify uncertainty as squared prediction errors between an online learner and a fixed, randomly initialized target network. Unlike RND, UVU errors reflect policy-conditional value uncertainty, incorporating the future uncertainties any given policy may encounter. This is due to the training procedure employed in UVU: the online network is trained using temporal difference learning with a synthetic reward derived from the fixed, randomly initialized target network. We provide an extensive theoretical analysis of our approach using neural tangent kernel (NTK) theory and show that in the limit of infinite network width, UVU errors are exactly equivalent to the variance of an ensemble of independent universal value functions. Empirically, we show that UVU achieves equal performance to large ensembles on challenging multi-task offline RL settings, while offering simplicity and substantial computational savings.
Bayesian Meta-Reinforcement Learning with Laplace Variational Recurrent Networks
May 24, 2025



Meta-reinforcement learning trains a single reinforcement learning agent on a distribution of tasks to quickly generalize to new tasks outside of the training set at test time. From a Bayesian perspective, one can interpret this as performing amortized variational inference on the posterior distribution over training tasks. Among the various meta-reinforcement learning approaches, a common method is to represent this distribution with a point-estimate using a recurrent neural network. We show how one can augment this point estimate to give full distributions through the Laplace approximation, either at the start of, during, or after learning, without modifying the base model architecture. With our approximation, we are able to estimate distribution statistics (e.g., the entropy) of non-Bayesian agents and observe that point-estimate based methods produce overconfident estimators while not satisfying consistency. Furthermore, when comparing our approach to full-distribution based learning of the task posterior, our method performs on par with variational baselines while having much fewer parameters.
How Ensembles of Distilled Policies Improve Generalisation in Reinforcement Learning
May 22, 2025



In the zero-shot policy transfer setting in reinforcement learning, the goal is to train an agent on a fixed set of training environments so that it can generalise to similar, but unseen, testing environments. Previous work has shown that policy distillation after training can sometimes produce a policy that outperforms the original in the testing environments. However, it is not yet entirely clear why that is, or what data should be used to distil the policy. In this paper, we prove, under certain assumptions, a generalisation bound for policy distillation after training. The theory provides two practical insights: for improved generalisation, you should 1) train an ensemble of distilled policies, and 2) distil it on as much data from the training environments as possible. We empirically verify that these insights hold in more general settings, when the assumptions required for the theory no longer hold. Finally, we demonstrate that an ensemble of policies distilled on a diverse dataset can generalise significantly better than the original agent.
VeRecycle: Reclaiming Guarantees from Probabilistic Certificates for Stochastic Dynamical Systems after Change
May 20, 2025



Autonomous systems operating in the real world encounter a range of uncertainties. Probabilistic neural Lyapunov certification is a powerful approach to proving safety of nonlinear stochastic dynamical systems. When faced with changes beyond the modeled uncertainties, e.g., unidentified obstacles, probabilistic certificates must be transferred to the new system dynamics. However, even when the changes are localized in a known part of the state space, state-of-the-art requires complete re-certification, which is particularly costly for neural certificates. We introduce VeRecycle, the first framework to formally reclaim guarantees for discrete-time stochastic dynamical systems. VeRecycle efficiently reuses probabilistic certificates when the system dynamics deviate only in a given subset of states. We present a general theoretical justification and algorithmic implementation. Our experimental evaluation shows scenarios where VeRecycle both saves significant computational effort and achieves competitive probabilistic guarantees in compositional neural control.
Trust-Region Twisted Policy Improvement
Apr 08, 2025
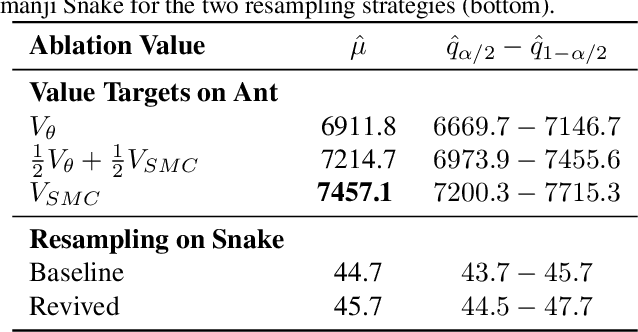


Monte-Carlo tree search (MCTS) has driven many recent breakthroughs in deep reinforcement learning (RL). However, scaling MCTS to parallel compute has proven challenging in practice which has motivated alternative planners like sequential Monte-Carlo (SMC). Many of these SMC methods adopt particle filters for smoothing through a reformulation of RL as a policy inference problem. Yet, persisting design choices of these particle filters often conflict with the aim of online planning in RL, which is to obtain a policy improvement at the start of planning. Drawing inspiration from MCTS, we tailor SMC planners specifically for RL by improving data generation within the planner through constrained action sampling and explicit terminal state handling, as well as improving policy and value target estimation. This leads to our Trust-Region Twisted SMC (TRT-SMC), which shows improved runtime and sample-efficiency over baseline MCTS and SMC methods in both discrete and continuous domains.