 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJointly Learning Predicates and Actions Enables Zero-Shot Skill Composition
May 20, 2026Learning from Demonstration (LfD) enables robots to learn complex behaviors from expert examples, yet existing approaches often fail to generalize to new compositions of known skills without retraining. Modern generative policies model distributions over action trajectories alone, thus are unable to reason about the symbolic outcomes required for robust composition. We propose that skills should jointly model action trajectories and the symbolic outcomes they induce. To address this gap, we introduce Predicate Action Skills (PACTS), a class of closed-loop visuomotor policies that model skills as a joint generative process over action and predicate belief trajectories, producing coherent action-outcome rollouts within a single model. Jointly generating actions and predicates enables PACTS to learn internal representations that improve both action generation and predicate classification. Furthermore, we demonstrate zero-shot composition of learned skills via planning by leveraging online predicate predictions from PACTS as a symbolic interface for sequencing and monitoring execution. Project website: https://planpacts.github.io/
You've Got a Golden Ticket: Improving Generative Robot Policies With A Single Noise Vector
Mar 16, 2026What happens when a pretrained generative robot policy is provided a constant initial noise as input, rather than repeatedly sampling it from a Gaussian? We demonstrate that the performance of a pretrained, frozen diffusion or flow matching policy can be improved with respect to a downstream reward by swapping the sampling of initial noise from the prior distribution (typically isotropic Gaussian) with a well-chosen, constant initial noise input -- a golden ticket. We propose a search method to find golden tickets using Monte-Carlo policy evaluation that keeps the pretrained policy frozen, does not train any new networks, and is applicable to all diffusion/flow matching policies (and therefore many VLAs). Our approach to policy improvement makes no assumptions beyond being able to inject initial noise into the policy and calculate (sparse) task rewards of episode rollouts, making it deployable with no additional infrastructure or models. Our method improves the performance of policies in 38 out of 43 tasks across simulated and real-world robot manipulation benchmarks, with relative improvements in success rate by up to 58% for some simulated tasks, and 60% within 50 search episodes for real-world tasks. We also show unique benefits of golden tickets for multi-task settings: the diversity of behaviors from different tickets naturally defines a Pareto frontier for balancing different objectives (e.g., speed, success rates); in VLAs, we find that a golden ticket optimized for one task can also boost performance in other related tasks. We release a codebase with pretrained policies and golden tickets for simulation benchmarks using VLAs, diffusion policies, and flow matching policies.
Technical Report: A Hierarchical Deliberative-Reactive System Architecture for Task and Motion Planning in Partially Known Environments
Feb 03, 2022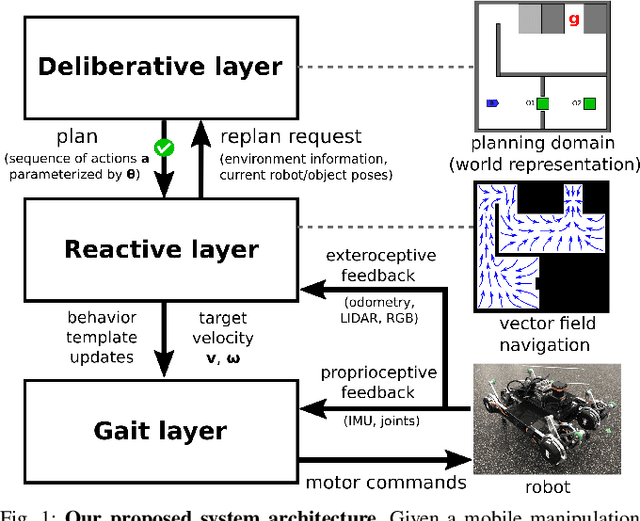
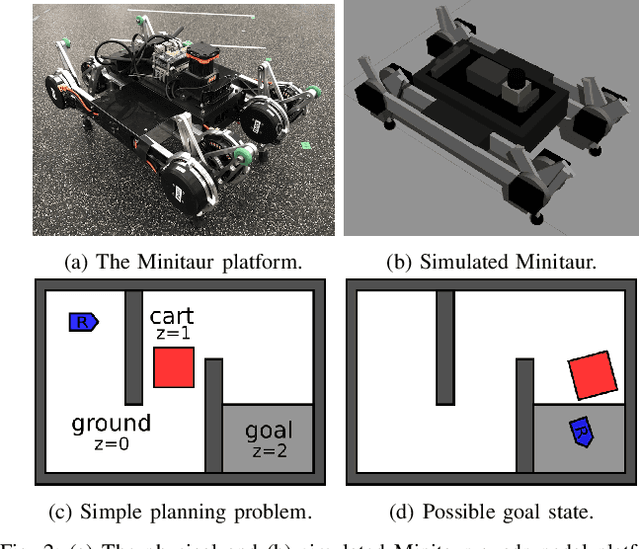
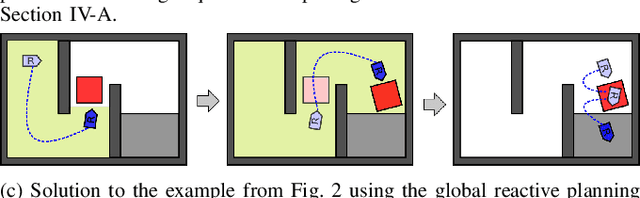
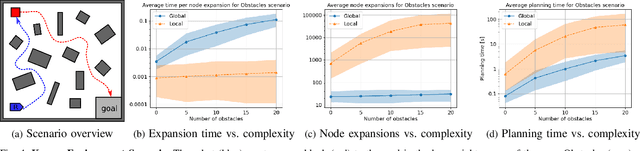
We describe a task and motion planning architecture for highly dynamic systems that combines a domain-independent sampling-based deliberative planning algorithm with a global reactive planner. We leverage the recent development of a reactive, vector field planner that provides guarantees of reachability to large regions of the environment even in the face of unknown or unforeseen obstacles. The reachability guarantees can be formalized using contracts that allow a deliberative planner to reason purely in terms of those contracts and synthesize a plan by choosing a sequence of reactive behaviors and their target configurations, without evaluating specific motion plans between targets. This reduces both the search depth at which plans will be found, and the number of samples required to ensure a plan exists, while crucially preserving correctness guarantees. The result is reduced computational cost of synthesizing plans, and increased robustness of generated plans to actuator noise, model misspecification, or unknown obstacles. Simulation studies show that our hierarchical planning and execution architecture can solve complex navigation and rearrangement tasks, even when faced with narrow passageways or incomplete world information.
Active Learning of Abstract Plan Feasibility
Jul 01, 2021

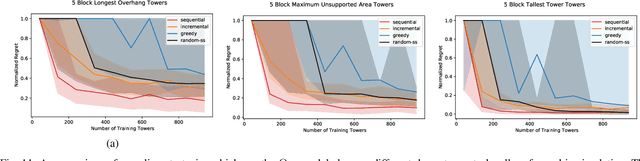
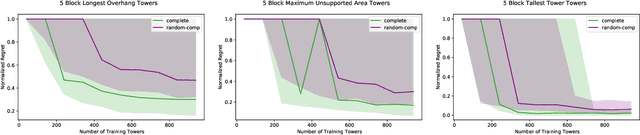
Long horizon sequential manipulation tasks are effectively addressed hierarchically: at a high level of abstraction the planner searches over abstract action sequences, and when a plan is found, lower level motion plans are generated. Such a strategy hinges on the ability to reliably predict that a feasible low level plan will be found which satisfies the abstract plan. However, computing Abstract Plan Feasibility (APF) is difficult because the outcome of a plan depends on real-world phenomena that are difficult to model, such as noise in estimation and execution. In this work, we present an active learning approach to efficiently acquire an APF predictor through task-independent, curious exploration on a robot. The robot identifies plans whose outcomes would be informative about APF, executes those plans, and learns from their successes or failures. Critically, we leverage an infeasible subsequence property to prune candidate plans in the active learning strategy, allowing our system to learn from less data. We evaluate our strategy in simulation and on a real Franka Emika Panda robot with integrated perception, experimentation, planning, and execution. In a stacking domain where objects have non-uniform mass distributions, we show that our system permits real robot learning of an APF model in four hundred self-supervised interactions, and that our learned model can be used effectively in multiple downstream tasks.
Learning and Planning for Temporally Extended Tasks in Unknown Environments
Apr 28, 2021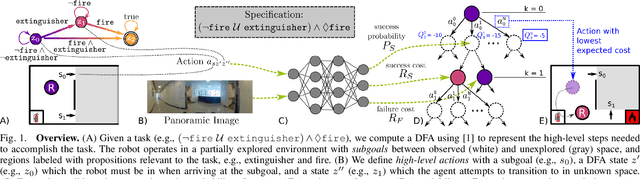
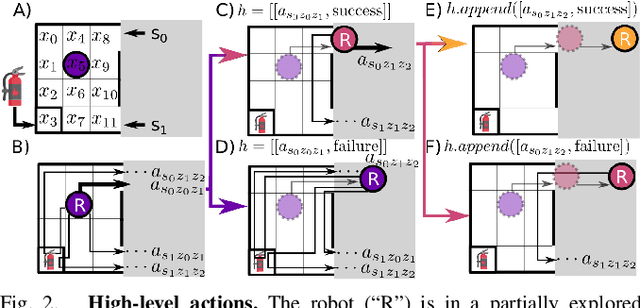
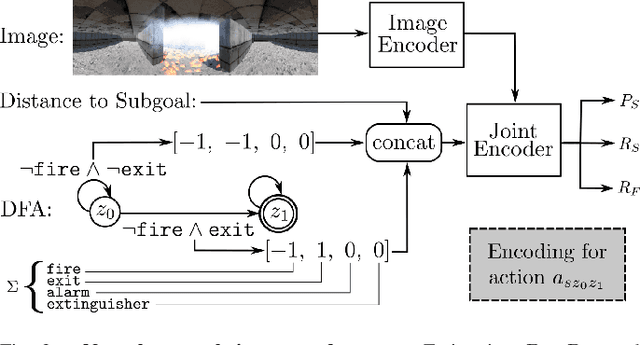

We propose a novel planning technique for satisfying tasks specified in temporal logic in partially revealed environments. We define high-level actions derived from the environment and the given task itself, and estimate how each action contributes to progress towards completing the task. As the map is revealed, we estimate the cost and probability of success of each action from images and an encoding of that action using a trained neural network. These estimates guide search for the minimum-expected-cost plan within our model. Our learned model is structured to generalize across environments and task specifications without requiring retraining. We demonstrate an improvement in total cost in both simulated and real-world experiments compared to a heuristic-driven baseline.