 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Few Bad Neurons: Isolating and Surgically Correcting Sycophancy
Jan 26, 2026Behavioral alignment in large language models (LLMs) is often achieved through broad fine-tuning, which can result in undesired side effects like distributional shift and low interpretability. We propose a method for alignment that identifies and updates only the neurons most responsible for a given behavior, a targeted approach that allows for fine-tuning with significantly less data. Using sparse autoencoders (SAEs) and linear probes, we isolate the 3% of MLP neurons most predictive of a target behavior, decode them into residual space, and fine-tune only those neurons using gradient masking. We demonstrate this approach on the task of reducing sycophantic behavior, where our method matches or exceeds state-of-the-art performance on four benchmarks (Syco-Bench, NLP, POLI, PHIL) using Gemma-2-2B and 9B models. Our results show that sparse, neuron-level updates offer a scalable and precise alternative to full-model fine-tuning, remaining effective even in situations when little data is available
Reasoning Relay: Evaluating Stability and Interchangeability of Large Language Models in Mathematical Reasoning
Dec 16, 2025Chain-of-Thought (CoT) prompting has significantly advanced the reasoning capabilities of large language models (LLMs). While prior work focuses on improving model performance through internal reasoning strategies, little is known about the interchangeability of reasoning across different models. In this work, we explore whether a partially completed reasoning chain from one model can be reliably continued by another model, either within the same model family or across families. We achieve this by assessing the sufficiency of intermediate reasoning traces as transferable scaffolds for logical coherence and final answer accuracy. We interpret this interchangeability as a means of examining inference-time trustworthiness, probing whether reasoning remains both coherent and reliable under model substitution. Using token-level log-probability thresholds to truncate reasoning at early, mid, and late stages from our baseline models, Gemma-3-4B-IT and LLaMA-3.1-70B-Instruct, we conduct continuation experiments with Gemma-3-1B-IT and LLaMA-3.1-8B-Instruct to test intra-family and cross-family behaviors. Our evaluation pipeline leverages truncation thresholds with a Process Reward Model (PRM), providing a reproducible framework for assessing reasoning stability via model interchange. Evaluations with a PRM reveal that hybrid reasoning chains often preserve, and in some cases even improve, final accuracy and logical structure. Our findings point towards interchangeability as an emerging behavioral property of reasoning models, offering insights into new paradigms for reliable modular reasoning in collaborative AI systems.
Direct Confidence Alignment: Aligning Verbalized Confidence with Internal Confidence In Large Language Models
Dec 12, 2025



Producing trustworthy and reliable Large Language Models (LLMs) has become increasingly important as their usage becomes more widespread. Calibration seeks to achieve this by improving the alignment between the model's confidence and the actual likelihood of its responses being correct or desirable. However, it has been observed that the internal confidence of a model, derived from token probabilities, is not well aligned with its verbalized confidence, leading to misleading results with different calibration methods. In this paper, we propose Direct Confidence Alignment (DCA), a method using Direct Preference Optimization to align an LLM's verbalized confidence with its internal confidence rather than ground-truth accuracy, enhancing model transparency and reliability by ensuring closer alignment between the two confidence measures. We evaluate DCA across multiple open-weight LLMs on a wide range of datasets. To further assess this alignment, we also introduce three new calibration error-based metrics. Our results show that DCA improves alignment metrics on certain model architectures, reducing inconsistencies in a model's confidence expression. However, we also show that it can be ineffective on others, highlighting the need for more model-aware approaches in the pursuit of more interpretable and trustworthy LLMs.
WOLF: Werewolf-based Observations for LLM Deception and Falsehoods
Dec 09, 2025Deception is a fundamental challenge for multi-agent reasoning: effective systems must strategically conceal information while detecting misleading behavior in others. Yet most evaluations reduce deception to static classification, ignoring the interactive, adversarial, and longitudinal nature of real deceptive dynamics. Large language models (LLMs) can deceive convincingly but remain weak at detecting deception in peers. We present WOLF, a multi-agent social deduction benchmark based on Werewolf that enables separable measurement of deception production and detection. WOLF embeds role-grounded agents (Villager, Werewolf, Seer, Doctor) in a programmable LangGraph state machine with strict night-day cycles, debate turns, and majority voting. Every statement is a distinct analysis unit, with self-assessed honesty from speakers and peer-rated deceptiveness from others. Deception is categorized via a standardized taxonomy (omission, distortion, fabrication, misdirection), while suspicion scores are longitudinally smoothed to capture both immediate judgments and evolving trust dynamics. Structured logs preserve prompts, outputs, and state transitions for full reproducibility. Across 7,320 statements and 100 runs, Werewolves produce deceptive statements in 31% of turns, while peer detection achieves 71-73% precision with ~52% overall accuracy. Precision is higher for identifying Werewolves, though false positives occur against Villagers. Suspicion toward Werewolves rises from ~52% to over 60% across rounds, while suspicion toward Villagers and the Doctor stabilizes near 44-46%. This divergence shows that extended interaction improves recall against liars without compounding errors against truthful roles. WOLF moves deception evaluation beyond static datasets, offering a dynamic, controlled testbed for measuring deceptive and detective capacity in adversarial multi-agent interaction.
SwiftSolve: A Self-Iterative, Complexity-Aware Multi-Agent Framework for Competitive Programming
Oct 26, 2025



Correctness alone is insufficient: LLM-generated programs frequently satisfy unit tests while violating contest time or memory budgets. We present SwiftSolve, a complexity-aware multi-agent system for competitive programming that couples algorithmic planning with empirical profiling and complexity-guided repair. We frame competitive programming as a software environment where specialized agents act as programmers, each assuming roles such as planning, coding, profiling, and complexity analysis. A Planner proposes an algorithmic sketch; a deterministic Static Pruner filters high-risk plans; a Coder emits ISO C++17; a Profiler compiles and executes candidates on a fixed input-size schedule to record wall time and peak memory; and a Complexity Analyst fits log-log growth (s, R2) with an LLM fallback to assign a complexity class and dispatch targeted patches to either the Planner or Coder. Agents communicate via typed, versioned JSON; a controller enforces iteration caps and diminishing returns stopping. Evaluated on 26 problems (16 BigO, 10 Codeforces Div. 2) in a POSIX sandbox (2 s / 256-512 MB), SwiftSolve attains pass@1 = 61.54% (16/26) on the first attempt and Solved@<=3 = 80.77% with marginal latency change (mean 11.96 s to 12.66 s per attempt). Aggregate run-level success is 73.08% at 12.40 s mean. Failures are predominantly resource-bound, indicating inefficiency rather than logic errors. Against Claude Opus 4, SwiftSolve improves run-level success (73.1% vs 52.6%) at approximately 2x runtime overhead (12.4 s vs 6.8 s). Beyond correctness (pass@k), we report efficiency metrics (eff@k for runtime and memory, incidence of TLE or MLE, and complexity fit accuracy on BigO), demonstrating that profiling and complexity-guided replanning reduce inefficiency while preserving accuracy.
ERGO: Entropy-guided Resetting for Generation Optimization in Multi-turn Language Models
Oct 15, 2025Large Language Models (LLMs) suffer significant performance degradation in multi-turn conversations when information is presented incrementally. Given that multi-turn conversations characterize everyday interactions with LLMs, this degradation poses a severe challenge to real world usability. We hypothesize that abrupt increases in model uncertainty signal misalignment in multi-turn LLM interactions, and we exploit this insight to dynamically realign conversational context. We introduce ERGO (Entropy-guided Resetting for Generation Optimization), which continuously quantifies internal uncertainty via Shannon entropy over next token distributions and triggers adaptive prompt consolidation when a sharp spike in entropy is detected. By treating uncertainty as a first class signal rather than a nuisance to eliminate, ERGO embraces variability in language and modeling, representing and responding to uncertainty. In multi-turn tasks with incrementally revealed instructions, ERGO yields a 56.6% average performance gain over standard baselines, increases aptitude (peak performance capability) by 24.7%, and decreases unreliability (variability in performance) by 35.3%, demonstrating that uncertainty aware interventions can improve both accuracy and reliability in conversational AI.
Filtering for Creativity: Adaptive Prompting for Multilingual Riddle Generation in LLMs
Aug 26, 2025



Multilingual riddle generation challenges large language models (LLMs) to balance cultural fluency with creative abstraction. Standard prompting strategies -- zero-shot, few-shot, chain-of-thought -- tend to reuse memorized riddles or perform shallow paraphrasing. We introduce Adaptive Originality Filtering (AOF), a prompting framework that filters redundant generations using cosine-based similarity rejection, while enforcing lexical novelty and cross-lingual fidelity. Evaluated across three LLMs and four language pairs, AOF-enhanced GPT-4o achieves \texttt{0.177} Self-BLEU and \texttt{0.915} Distinct-2 in Japanese, signaling improved lexical diversity and reduced redundancy compared to other prompting methods and language pairs. Our findings show that semantic rejection can guide culturally grounded, creative generation without task-specific fine-tuning.
Distill CLIP (DCLIP): Enhancing Image-Text Retrieval via Cross-Modal Transformer Distillation
Jun 01, 2025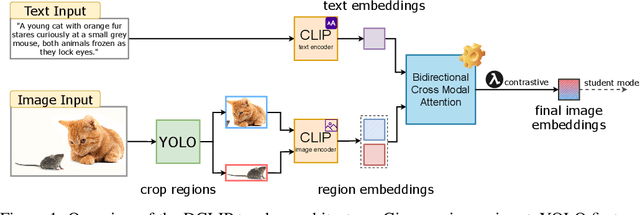

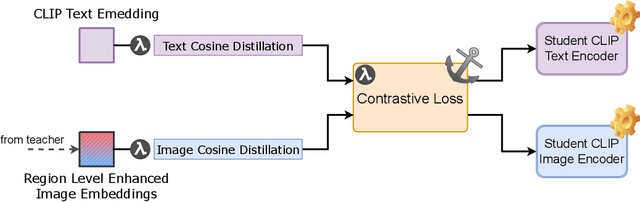
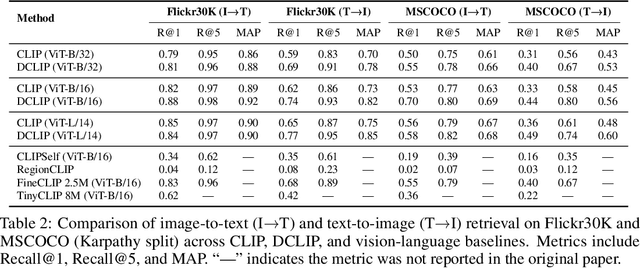
We present Distill CLIP (DCLIP), a fine-tuned variant of the CLIP model that enhances multimodal image-text retrieval while preserving the original model's strong zero-shot classification capabilities. CLIP models are typically constrained by fixed image resolutions and limited context, which can hinder their effectiveness in retrieval tasks that require fine-grained cross-modal understanding. DCLIP addresses these challenges through a meta teacher-student distillation framework, where a cross-modal transformer teacher is fine-tuned to produce enriched embeddings via bidirectional cross-attention between YOLO-extracted image regions and corresponding textual spans. These semantically and spatially aligned global representations guide the training of a lightweight student model using a hybrid loss that combines contrastive learning and cosine similarity objectives. Despite being trained on only ~67,500 samples curated from MSCOCO, Flickr30k, and Conceptual Captions-just a fraction of CLIP's original dataset-DCLIP significantly improves image-text retrieval metrics (Recall@K, MAP), while retaining approximately 94% of CLIP's zero-shot classification performance. These results demonstrate that DCLIP effectively mitigates the trade-off between task specialization and generalization, offering a resource-efficient, domain-adaptive, and detail-sensitive solution for advanced vision-language tasks. Code available at https://anonymous.4open.science/r/DCLIP-B772/README.md.
From Directions to Cones: Exploring Multidimensional Representations of Propositional Facts in LLMs
May 27, 2025



Large Language Models (LLMs) exhibit strong conversational abilities but often generate falsehoods. Prior work suggests that the truthfulness of simple propositions can be represented as a single linear direction in a model's internal activations, but this may not fully capture its underlying geometry. In this work, we extend the concept cone framework, recently introduced for modeling refusal, to the domain of truth. We identify multi-dimensional cones that causally mediate truth-related behavior across multiple LLM families. Our results are supported by three lines of evidence: (i) causal interventions reliably flip model responses to factual statements, (ii) learned cones generalize across model architectures, and (iii) cone-based interventions preserve unrelated model behavior. These findings reveal the richer, multidirectional structure governing simple true/false propositions in LLMs and highlight concept cones as a promising tool for probing abstract behaviors.
FAIRE: Assessing Racial and Gender Bias in AI-Driven Resume Evaluations
Apr 02, 2025In an era where AI-driven hiring is transforming recruitment practices, concerns about fairness and bias have become increasingly important. To explore these issues, we introduce a benchmark, FAIRE (Fairness Assessment In Resume Evaluation), to test for racial and gender bias in large language models (LLMs) used to evaluate resumes across different industries. We use two methods-direct scoring and ranking-to measure how model performance changes when resumes are slightly altered to reflect different racial or gender identities. Our findings reveal that while every model exhibits some degree of bias, the magnitude and direction vary considerably. This benchmark provides a clear way to examine these differences and offers valuable insights into the fairness of AI-based hiring tools. It highlights the urgent need for strategies to reduce bias in AI-driven recruitment. Our benchmark code and dataset are open-sourced at our repository: https://github.com/athenawen/FAIRE-Fairness-Assessment-In-Resume-Evaluation.git.