 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiEmo-Bench: Multi-label Visual Emotion Analysis for Multi-modal Large Language Models
May 14, 2026This paper introduces a multi-label visual emotion analysis benchmark dataset for comprehensively evaluating the ability of multimodal large language models (MLLMs) to predict the emotions evoked by images. Recent user studies report an unintuitive finding: humans may prefer the predictions of MLLMs over the labels in existing datasets. We argue that this phenomenon stems from the suboptimal annotation scheme used in existing datasets, where each annotator is shown a single candidate emotion for each image and judges whether it is evoked or not. This approach is clearly limited because a single image can evoke multiple emotions with varying intensities. As a result, evaluations based on these datasets may underestimate the capabilities of MLLMs, yet an appropriate benchmark for evaluating such models remains lacking. To address this issue, we introduce a new multi-label benchmark dataset for visual emotion analysis toward MLLMs evaluation. We hire $20$ annotators per image and ask them to select all emotions they feel from an image. Then, we aggregate the votes across all annotators, providing a more reliable and representative dataset labeled with a distribution of emotions. The resulting dataset contains $10,344$ images with $236,998$ valid votes across eight emotions. Based on this benchmark dataset, we evaluate several recent models, including Qwen3-VL, OpenAI's GPT, Gemini, and Claude. We assess model performance on both dominant emotion prediction and emotion distribution prediction. Our results demonstrate the progress achieved by recent MLLMs while also indicating that substantial room for improvement remains. Furthermore, our experiments with LLM-as-a-judge show that the method does not consistently improve MLLMs' performance, indicating its limitations for the subjective task of visual emotion analysis.
Reference-Free Image Quality Assessment for Virtual Try-On via Human Feedback
Mar 13, 2026Given a person image and a garment image, image-based Virtual Try-ON (VTON) synthesizes a try-on image of the person wearing the target garment. As VTON systems become increasingly important in practical applications such as fashion e-commerce, reliable evaluation of their outputs has emerged as a critical challenge. In real-world scenarios, ground-truth images of the same person wearing the target garment are typically unavailable, making reference-based evaluation impractical. Moreover, widely used distribution-level metrics such as Fréchet Inception Distance and Kernel Inception Distance measure dataset-level similarity and fail to reflect the perceptual quality of individual generated images. To address these limitations, we propose Image Quality Assessment for Virtual Try-On (VTON-IQA), a reference-free framework for human-aligned, image-level quality assessment without requiring ground-truth images. To model human perceptual judgments, we construct VTON-QBench, a large-scale human-annotated benchmark comprising 62,688 try-on images generated by 14 representative VTON models and 431,800 quality annotations collected from 13,838 qualified annotators. To the best of our knowledge, this is the largest dataset to date for human subjective evaluation in virtual try-on. Evaluating virtual try-on quality requires verifying both garment fidelity and the preservation of person-specific details. To explicitly model such interactions, we introduce an Interleaved Cross-Attention module that extends standard transformer blocks by inserting a cross-attention layer between self-attention and MLP in the latter blocks. Extensive experiments show that VTON-IQA achieves reliable human-aligned image-level quality prediction. Moreover, we conduct a comprehensive benchmark evaluation of 14 representative VTON models using VTON-IQA.
Static Word Embeddings for Sentence Semantic Representation
Jun 05, 2025



We propose new static word embeddings optimised for sentence semantic representation. We first extract word embeddings from a pre-trained Sentence Transformer, and improve them with sentence-level principal component analysis, followed by either knowledge distillation or contrastive learning. During inference, we represent sentences by simply averaging word embeddings, which requires little computational cost. We evaluate models on both monolingual and cross-lingual tasks and show that our model substantially outperforms existing static models on sentence semantic tasks, and even rivals a basic Sentence Transformer model (SimCSE) on some data sets. Lastly, we perform a variety of analyses and show that our method successfully removes word embedding components that are irrelevant to sentence semantics, and adjusts the vector norms based on the influence of words on sentence semantics.
An Empirical Analysis of GPT-4V's Performance on Fashion Aesthetic Evaluation
Oct 31, 2024



Fashion aesthetic evaluation is the task of estimating how well the outfits worn by individuals in images suit them. In this work, we examine the zero-shot performance of GPT-4V on this task for the first time. We show that its predictions align fairly well with human judgments on our datasets, and also find that it struggles with ranking outfits in similar colors. The code is available at https://github.com/st-tech/gpt4v-fashion-aesthetic-evaluation.
Disentangling Likes and Dislikes in Personalized Generative Explainable Recommendation
Oct 17, 2024



Recent research on explainable recommendation generally frames the task as a standard text generation problem, and evaluates models simply based on the textual similarity between the predicted and ground-truth explanations. However, this approach fails to consider one crucial aspect of the systems: whether their outputs accurately reflect the users' (post-purchase) sentiments, i.e., whether and why they would like and/or dislike the recommended items. To shed light on this issue, we introduce new datasets and evaluation methods that focus on the users' sentiments. Specifically, we construct the datasets by explicitly extracting users' positive and negative opinions from their post-purchase reviews using an LLM, and propose to evaluate systems based on whether the generated explanations 1) align well with the users' sentiments, and 2) accurately identify both positive and negative opinions of users on the target items. We benchmark several recent models on our datasets and demonstrate that achieving strong performance on existing metrics does not ensure that the generated explanations align well with the users' sentiments. Lastly, we find that existing models can provide more sentiment-aware explanations when the users' (predicted) ratings for the target items are directly fed into the models as input. We will release our code and datasets upon acceptance.
A Fashion Item Recommendation Model in Hyperbolic Space
Sep 04, 2024In this work, we propose a fashion item recommendation model that incorporates hyperbolic geometry into user and item representations. Using hyperbolic space, our model aims to capture implicit hierarchies among items based on their visual data and users' purchase history. During training, we apply a multi-task learning framework that considers both hyperbolic and Euclidean distances in the loss function. Our experiments on three data sets show that our model performs better than previous models trained in Euclidean space only, confirming the effectiveness of our model. Our ablation studies show that multi-task learning plays a key role, and removing the Euclidean loss substantially deteriorates the model performance.
Unsupervised Lexical Simplification with Context Augmentation
Nov 01, 2023



We propose a new unsupervised lexical simplification method that uses only monolingual data and pre-trained language models. Given a target word and its context, our method generates substitutes based on the target context and also additional contexts sampled from monolingual data. We conduct experiments in English, Portuguese, and Spanish on the TSAR-2022 shared task, and show that our model substantially outperforms other unsupervised systems across all languages. We also establish a new state-of-the-art by ensembling our model with GPT-3.5. Lastly, we evaluate our model on the SWORDS lexical substitution data set, achieving a state-of-the-art result.
Unsupervised Paraphrasing of Multiword Expressions
Jun 02, 2023We propose an unsupervised approach to paraphrasing multiword expressions (MWEs) in context. Our model employs only monolingual corpus data and pre-trained language models (without fine-tuning), and does not make use of any external resources such as dictionaries. We evaluate our method on the SemEval 2022 idiomatic semantic text similarity task, and show that it outperforms all unsupervised systems and rivals supervised systems.
Unsupervised Lexical Substitution with Decontextualised Embeddings
Sep 17, 2022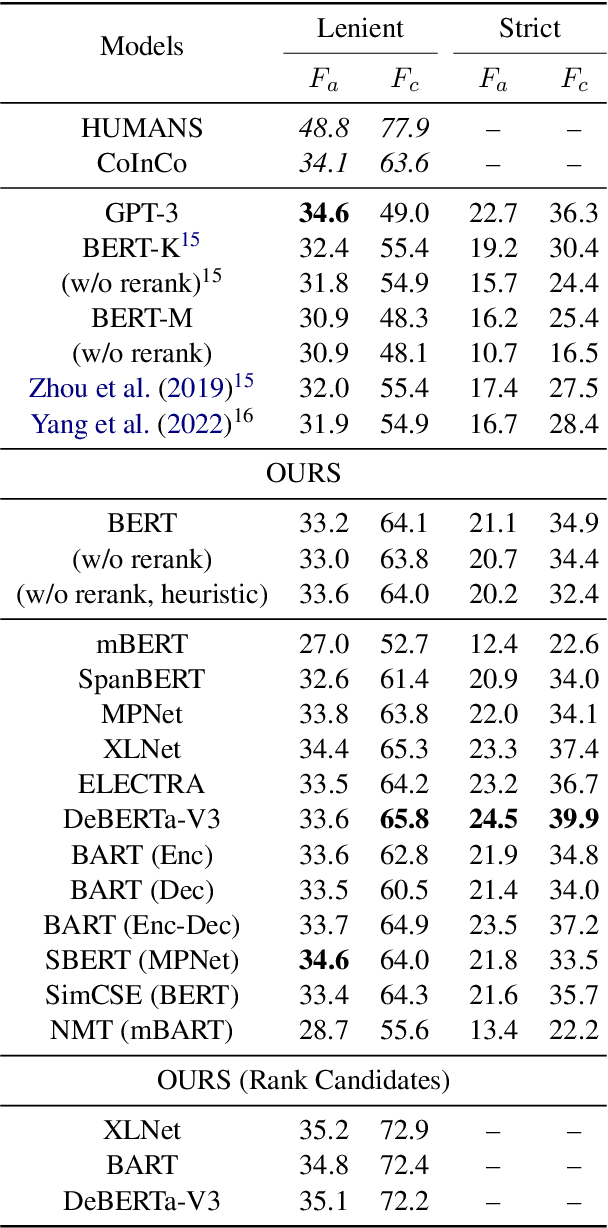
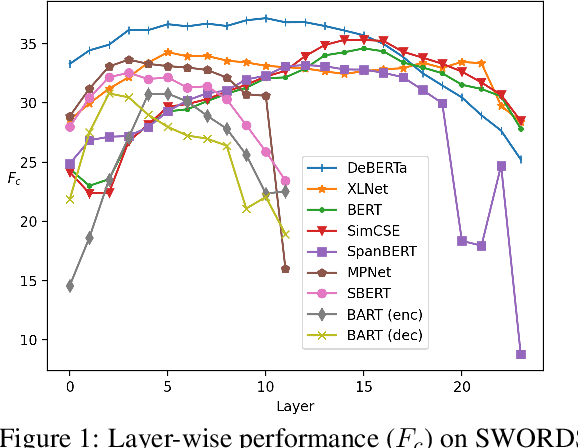
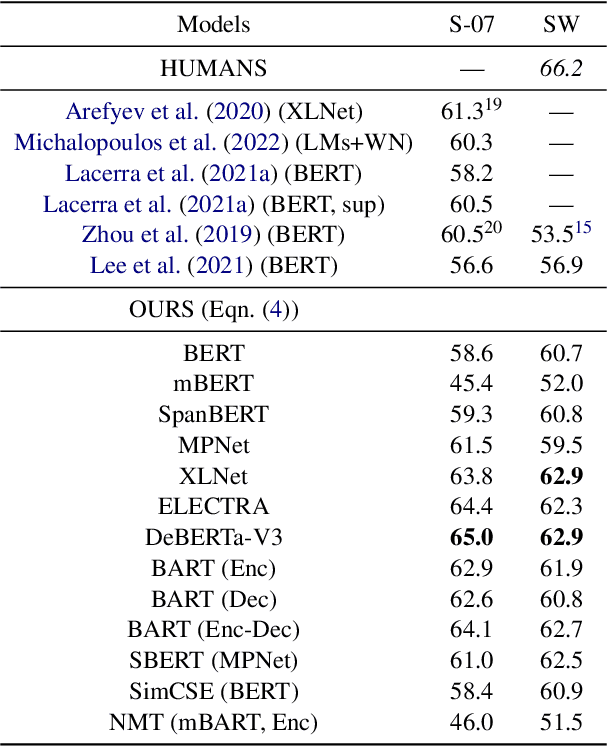
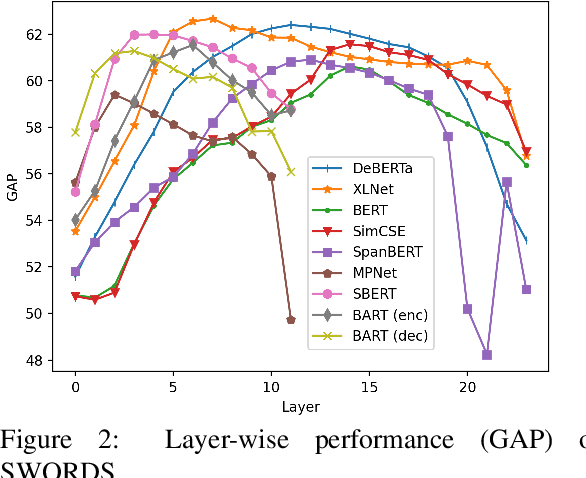
We propose a new unsupervised method for lexical substitution using pre-trained language models. Compared to previous approaches that use the generative capability of language models to predict substitutes, our method retrieves substitutes based on the similarity of contextualised and decontextualised word embeddings, i.e. the average contextual representation of a word in multiple contexts. We conduct experiments in English and Italian, and show that our method substantially outperforms strong baselines and establishes a new state-of-the-art without any explicit supervision or fine-tuning. We further show that our method performs particularly well at predicting low-frequency substitutes, and also generates a diverse list of substitute candidates, reducing morphophonetic or morphosyntactic biases induced by article-noun agreement.
Learning Contextualised Cross-lingual Word Embeddings for Extremely Low-Resource Languages Using Parallel Corpora
Oct 27, 2020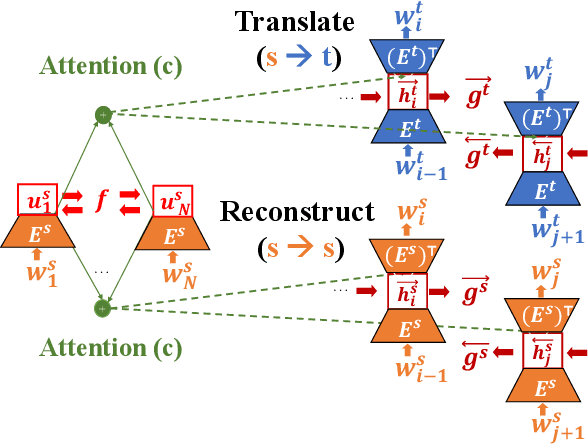
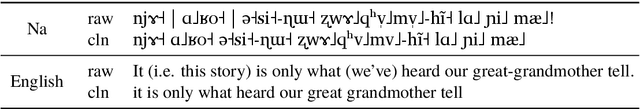
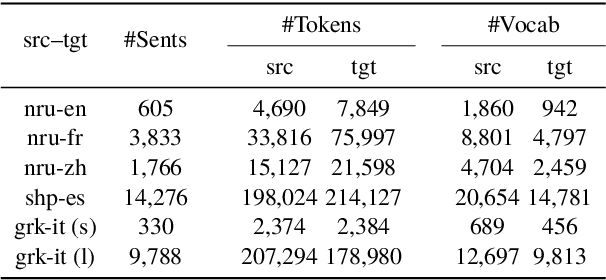
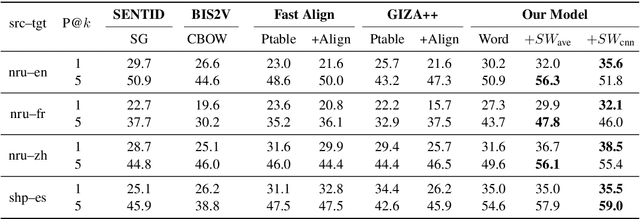
We propose a new approach for learning contextualised cross-lingual word embeddings based only on a small parallel corpus (e.g. a few hundred sentence pairs). Our method obtains word embeddings via an LSTM-based encoder-decoder model that performs bidirectional translation and reconstruction of the input sentence. Through sharing model parameters among different languages, our model jointly trains the word embeddings in a common multilingual space. We also propose a simple method to combine word and subword embeddings to make use of orthographic similarities across different languages. We base our experiments on real-world data from endangered languages, namely Yongning Na, Shipibo-Konibo and Griko. Our experiments on bilingual lexicon induction and word alignment tasks show that our model outperforms existing methods by a large margin for most language pairs. These results demonstrate that, contrary to common belief, an encoder-decoder translation model is beneficial for learning cross-lingual representations, even in extremely low-resource scenarios.