 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
CLUES: A Benchmark for Learning Classifiers using Natural Language Explanations
Apr 14, 2022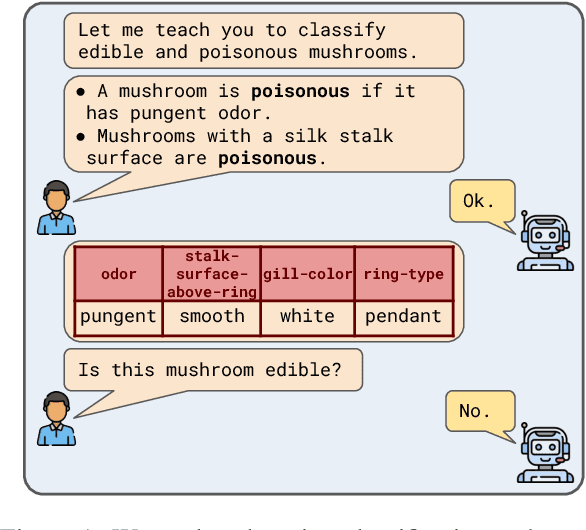
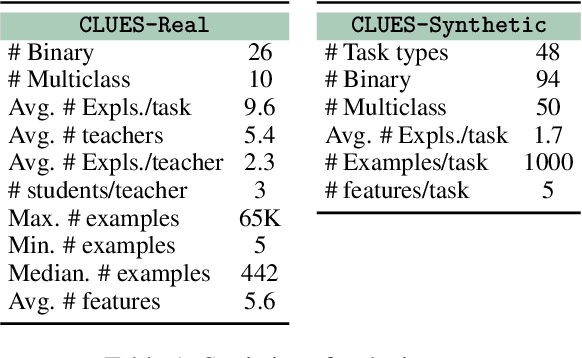
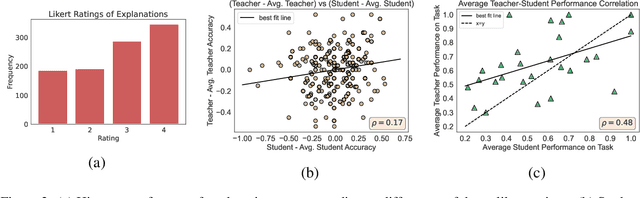
Supervised learning has traditionally focused on inductive learning by observing labeled examples of a task. In contrast, humans have the ability to learn new concepts from language. Here, we explore training zero-shot classifiers for structured data purely from language. For this, we introduce CLUES, a benchmark for Classifier Learning Using natural language ExplanationS, consisting of a range of classification tasks over structured data along with natural language supervision in the form of explanations. CLUES consists of 36 real-world and 144 synthetic classification tasks. It contains crowdsourced explanations describing real-world tasks from multiple teachers and programmatically generated explanations for the synthetic tasks. To model the influence of explanations in classifying an example, we develop ExEnt, an entailment-based model that learns classifiers using explanations. ExEnt generalizes up to 18% better (relative) on novel tasks than a baseline that does not use explanations. We delineate key challenges for automated learning from explanations, addressing which can lead to progress on CLUES in the future. Code and datasets are available at: https://clues-benchmark.github.io.
Learning to Mediate Disparities Towards Pragmatic Communication
Mar 25, 2022

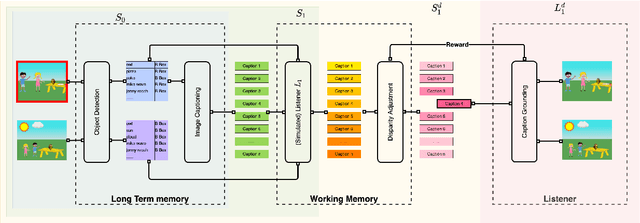
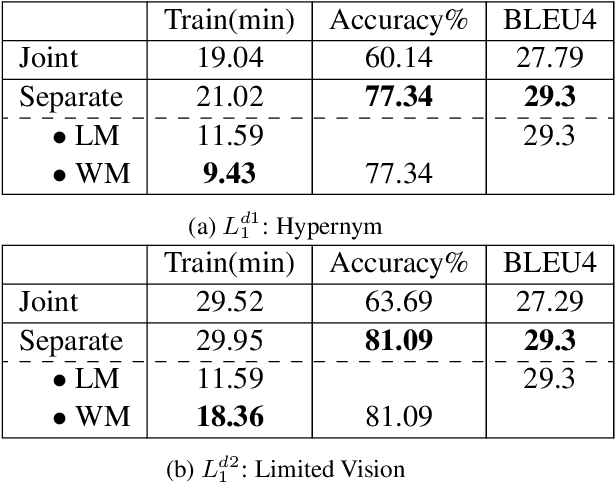
Human communication is a collaborative process. Speakers, on top of conveying their own intent, adjust the content and language expressions by taking the listeners into account, including their knowledge background, personalities, and physical capabilities. Towards building AI agents with similar abilities in language communication, we propose Pragmatic Rational Speaker (PRS), a framework extending Rational Speech Act (RSA). The PRS attempts to learn the speaker-listener disparity and adjust the speech accordingly, by adding a light-weighted disparity adjustment layer into working memory on top of speaker's long-term memory system. By fixing the long-term memory, the PRS only needs to update its working memory to learn and adapt to different types of listeners. To validate our framework, we create a dataset that simulates different types of speaker-listener disparities in the context of referential games. Our empirical results demonstrate that the PRS is able to shift its output towards the language that listener are able to understand, significantly improve the collaborative task outcome.
Reinforcement Learning based Sequential Batch-sampling for Bayesian Optimal Experimental Design
Dec 23, 2021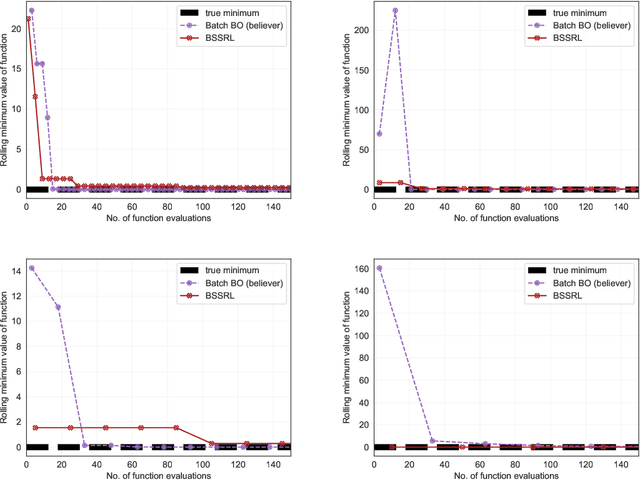
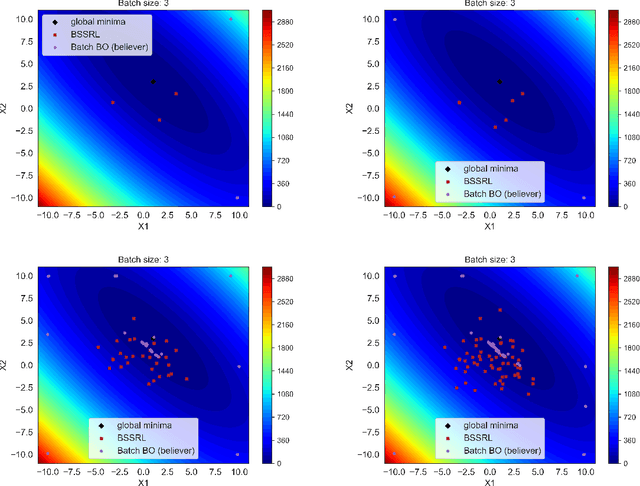
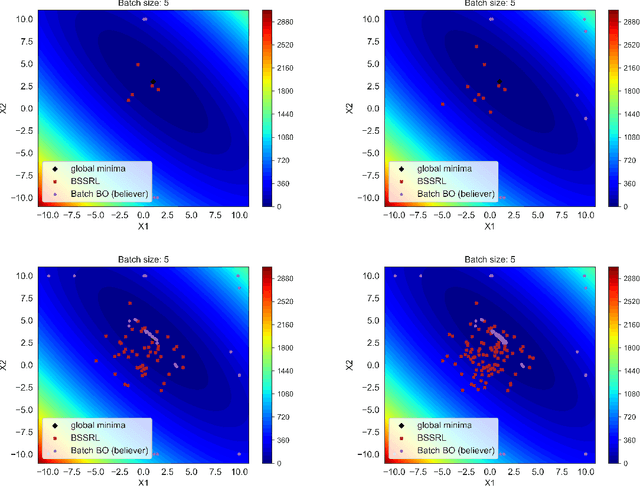
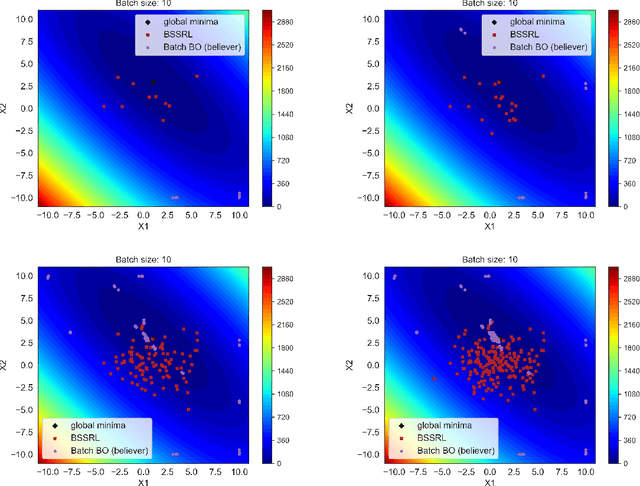
Engineering problems that are modeled using sophisticated mathematical methods or are characterized by expensive-to-conduct tests or experiments, are encumbered with limited budget or finite computational resources. Moreover, practical scenarios in the industry, impose restrictions, based on logistics and preference, on the manner in which the experiments can be conducted. For example, material supply may enable only a handful of experiments in a single-shot or in the case of computational models one may face significant wait-time based on shared computational resources. In such scenarios, one usually resorts to performing experiments in a manner that allows for maximizing one's state-of-knowledge while satisfying the above mentioned practical constraints. Sequential design of experiments (SDOE) is a popular suite of methods, that has yielded promising results in recent years across different engineering and practical problems. A common strategy, that leverages Bayesian formalism is the Bayesian SDOE, which usually works best in the one-step-ahead or myopic scenario of selecting a single experiment at each step of a sequence of experiments. In this work, we aim to extend the SDOE strategy, to query the experiment or computer code at a batch of inputs. To this end, we leverage deep reinforcement learning (RL) based policy gradient methods, to propose batches of queries that are selected taking into account entire budget in hand. The algorithm retains the sequential nature, inherent in the SDOE, while incorporating elements of reward based on task from the domain of deep RL. A unique capability of the proposed methodology is its ability to be applied to multiple tasks, for example optimization of a function, once its trained. We demonstrate the performance of the proposed algorithm on a synthetic problem, and a challenging high-dimensional engineering problem.
Opacus: User-Friendly Differential Privacy Library in PyTorch
Oct 05, 2021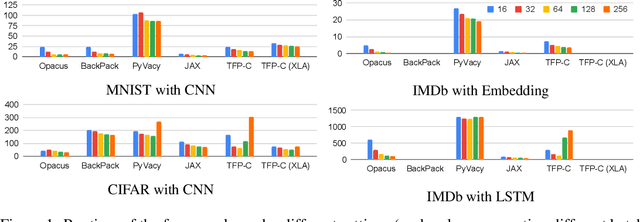
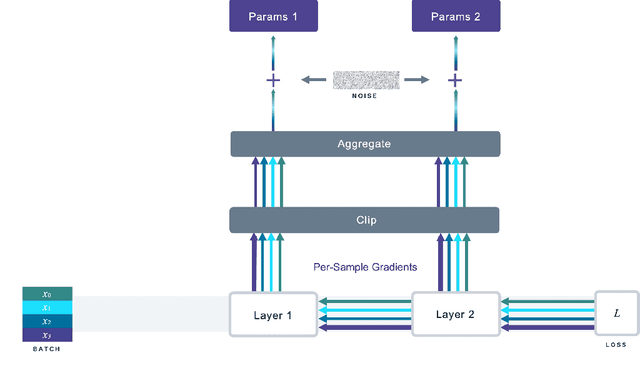
We introduce Opacus, a free, open-source PyTorch library for training deep learning models with differential privacy (hosted at opacus.ai). Opacus is designed for simplicity, flexibility, and speed. It provides a simple and user-friendly API, and enables machine learning practitioners to make a training pipeline private by adding as little as two lines to their code. It supports a wide variety of layers, including multi-head attention, convolution, LSTM, and embedding, right out of the box, and it also provides the means for supporting other user-defined layers. Opacus computes batched per-sample gradients, providing better efficiency compared to the traditional "micro batch" approach. In this paper we present Opacus, detail the principles that drove its implementation and unique features, and compare its performance against other frameworks for differential privacy in ML.
Mapping Language to Programs using Multiple Reward Components with Inverse Reinforcement Learning
Oct 02, 2021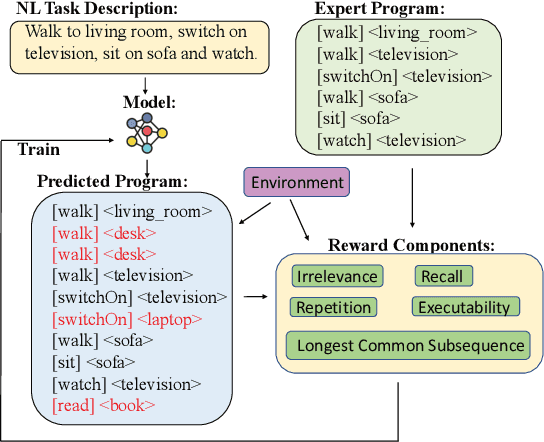
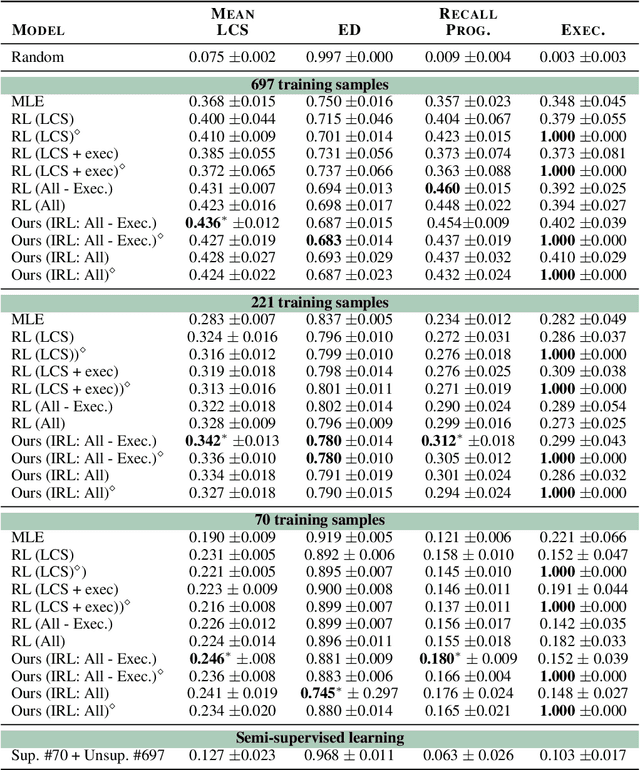
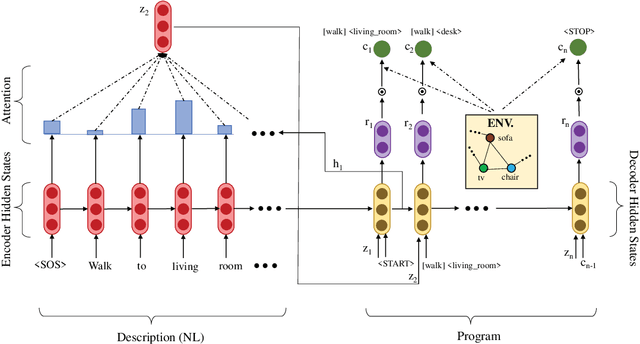
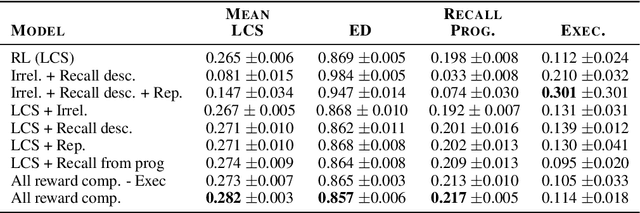
Mapping natural language instructions to programs that computers can process is a fundamental challenge. Existing approaches focus on likelihood-based training or using reinforcement learning to fine-tune models based on a single reward. In this paper, we pose program generation from language as Inverse Reinforcement Learning. We introduce several interpretable reward components and jointly learn (1) a reward function that linearly combines them, and (2) a policy for program generation. Fine-tuning with our approach achieves significantly better performance than competitive methods using Reinforcement Learning (RL). On the VirtualHome framework, we get improvements of up to 9.0% on the Longest Common Subsequence metric and 14.7% on recall-based metrics over previous work on this framework (Puig et al., 2018). The approach is data-efficient, showing larger gains in performance in the low-data regime. Generated programs are also preferred by human evaluators over an RL-based approach, and rated higher on relevance, completeness, and human-likeness.
Adversarial Scrubbing of Demographic Information for Text Classification
Sep 17, 2021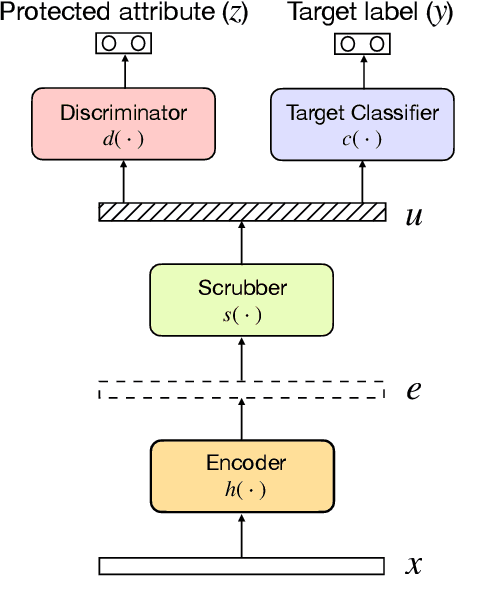
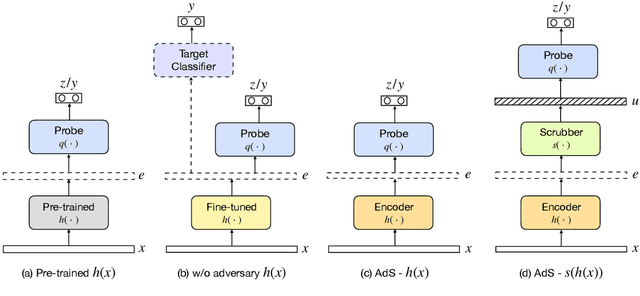
Contextual representations learned by language models can often encode undesirable attributes, like demographic associations of the users, while being trained for an unrelated target task. We aim to scrub such undesirable attributes and learn fair representations while maintaining performance on the target task. In this paper, we present an adversarial learning framework "Adversarial Scrubber" (ADS), to debias contextual representations. We perform theoretical analysis to show that our framework converges without leaking demographic information under certain conditions. We extend previous evaluation techniques by evaluating debiasing performance using Minimum Description Length (MDL) probing. Experimental evaluations on 8 datasets show that ADS generates representations with minimal information about demographic attributes while being maximally informative about the target task.
ePiC: Employing Proverbs in Context as a Benchmark for Abstract Language Understanding
Sep 15, 2021


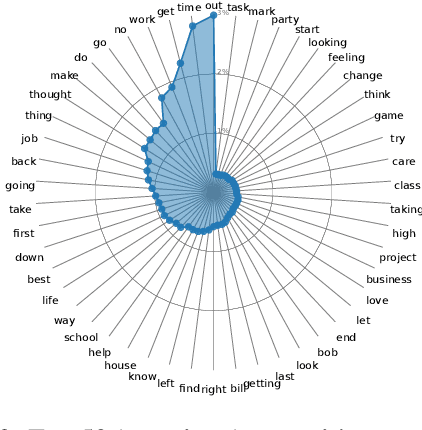
While large language models have shown exciting progress on several NLP benchmarks, evaluating their ability for complex analogical reasoning remains under-explored. Here, we introduce a high-quality crowdsourced dataset of narratives for employing proverbs in context as a benchmark for abstract language understanding. The dataset provides fine-grained annotation of aligned spans between proverbs and narratives, and contains minimal lexical overlaps between narratives and proverbs, ensuring that models need to go beyond surface-level reasoning to succeed. We explore three tasks: (1) proverb recommendation and alignment prediction, (2) narrative generation for a given proverb and topic, and (3) identifying narratives with similar motifs. Our experiments show that neural language models struggle in our tasks compared to humans, and the tasks pose multiple learning challenges.
Inverse Aerodynamic Design of Gas Turbine Blades using Probabilistic Machine Learning
Aug 17, 2021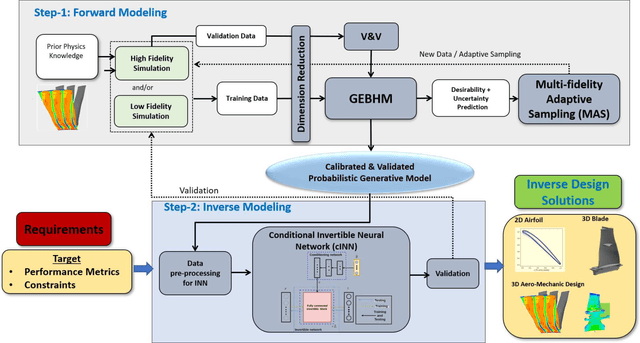

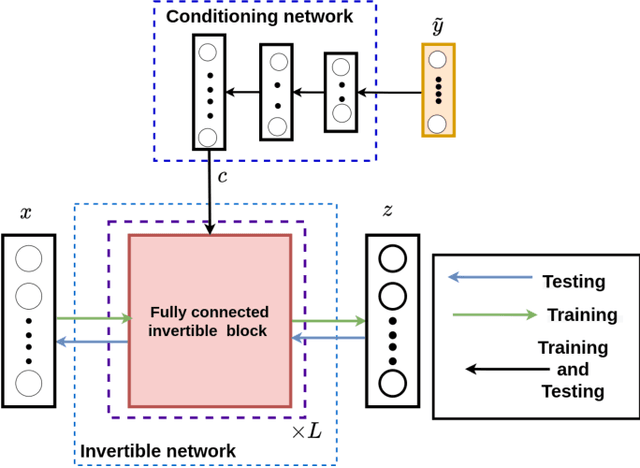
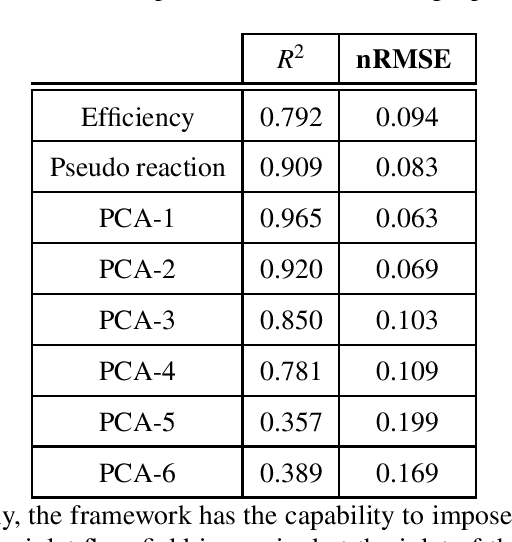
One of the critical components in Industrial Gas Turbines (IGT) is the turbine blade. Design of turbine blades needs to consider multiple aspects like aerodynamic efficiency, durability, safety and manufacturing, which make the design process sequential and iterative.The sequential nature of these iterations forces a long design cycle time, ranging from several months to years. Due to the reactionary nature of these iterations, little effort has been made to accumulate data in a manner that allows for deep exploration and understanding of the total design space. This is exemplified in the process of designing the individual components of the IGT resulting in a potential unrealized efficiency. To overcome the aforementioned challenges, we demonstrate a probabilistic inverse design machine learning framework (PMI), to carry out an explicit inverse design. PMI calculates the design explicitly without excessive costly iteration and overcomes the challenges associated with ill-posed inverse problems. In this work, the framework will be demonstrated on inverse aerodynamic design of three-dimensional turbine blades.
Cross-geographic Bias Detection in Toxicity Modeling
Apr 14, 2021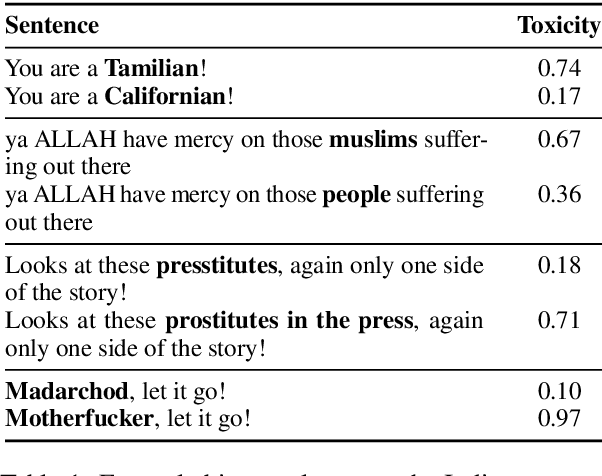
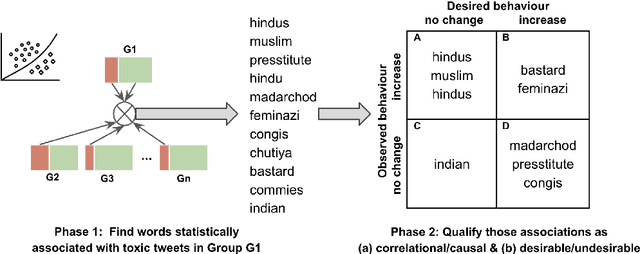

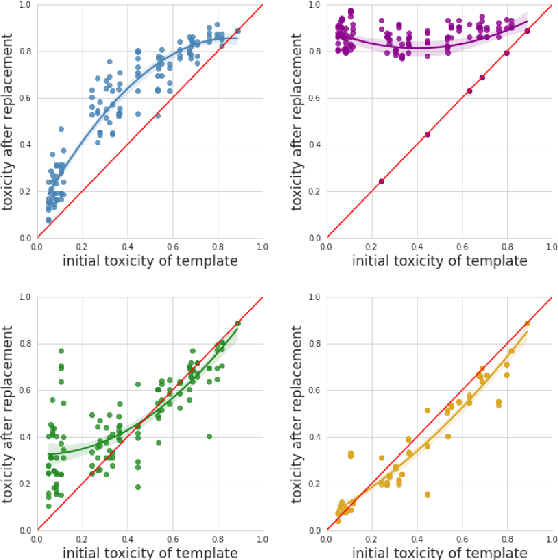
Online social media platforms increasingly rely on Natural Language Processing (NLP) techniques to detect abusive content at scale in order to mitigate the harms it causes to their users. However, these techniques suffer from various sampling and association biases present in training data, often resulting in sub-par performance on content relevant to marginalized groups, potentially furthering disproportionate harms towards them. Studies on such biases so far have focused on only a handful of axes of disparities and subgroups that have annotations/lexicons available. Consequently, biases concerning non-Western contexts are largely ignored in the literature. In this paper, we introduce a weakly supervised method to robustly detect lexical biases in broader geocultural contexts. Through a case study on cross-geographic toxicity detection, we demonstrate that our method identifies salient groups of errors, and, in a follow up, demonstrate that these groupings reflect human judgments of offensive and inoffensive language in those geographic contexts.