 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiC-CLIP: Continual Training of CLIP Models
Oct 24, 2023



Keeping large foundation models up to date on latest data is inherently expensive. To avoid the prohibitive costs of constantly retraining, it is imperative to continually train these models. This problem is exacerbated by the lack of any large scale continual learning benchmarks or baselines. We introduce the first set of web-scale Time-Continual (TiC) benchmarks for training vision-language models: TiC-DataCompt, TiC-YFCC, and TiC-RedCaps with over 12.7B timestamped image-text pairs spanning 9 years (2014--2022). We first use our benchmarks to curate various dynamic evaluations to measure temporal robustness of existing models. We show OpenAI's CLIP (trained on data up to 2020) loses $\approx 8\%$ zero-shot accuracy on our curated retrieval task from 2021--2022 compared with more recently trained models in OpenCLIP repository. We then study how to efficiently train models on time-continuous data. We demonstrate that a simple rehearsal-based approach that continues training from the last checkpoint and replays old data reduces compute by $2.5\times$ when compared to the standard practice of retraining from scratch.
Machine Learning for Leaf Disease Classification: Data, Techniques and Applications
Oct 19, 2023The growing demand for sustainable development brings a series of information technologies to help agriculture production. Especially, the emergence of machine learning applications, a branch of artificial intelligence, has shown multiple breakthroughs which can enhance and revolutionize plant pathology approaches. In recent years, machine learning has been adopted for leaf disease classification in both academic research and industrial applications. Therefore, it is enormously beneficial for researchers, engineers, managers, and entrepreneurs to have a comprehensive view about the recent development of machine learning technologies and applications for leaf disease detection. This study will provide a survey in different aspects of the topic including data, techniques, and applications. The paper will start with publicly available datasets. After that, we summarize common machine learning techniques, including traditional (shallow) learning, deep learning, and augmented learning. Finally, we discuss related applications. This paper would provide useful resources for future study and application of machine learning for smart agriculture in general and leaf disease classification in particular.
(Almost) Provable Error Bounds Under Distribution Shift via Disagreement Discrepancy
Jun 01, 2023



We derive an (almost) guaranteed upper bound on the error of deep neural networks under distribution shift using unlabeled test data. Prior methods either give bounds that are vacuous in practice or give estimates that are accurate on average but heavily underestimate error for a sizeable fraction of shifts. In particular, the latter only give guarantees based on complex continuous measures such as test calibration -- which cannot be identified without labels -- and are therefore unreliable. Instead, our bound requires a simple, intuitive condition which is well justified by prior empirical works and holds in practice effectively 100% of the time. The bound is inspired by $\mathcal{H}\Delta\mathcal{H}$-divergence but is easier to evaluate and substantially tighter, consistently providing non-vacuous guarantees. Estimating the bound requires optimizing one multiclass classifier to disagree with another, for which some prior works have used sub-optimal proxy losses; we devise a "disagreement loss" which is theoretically justified and performs better in practice. We expect this loss can serve as a drop-in replacement for future methods which require maximizing multiclass disagreement. Across a wide range of benchmarks, our method gives valid error bounds while achieving average accuracy comparable to competitive estimation baselines. Code is publicly available at https://github.com/erosenfeld/disagree_discrep .
Online Label Shift: Optimal Dynamic Regret meets Practical Algorithms
May 31, 2023This paper focuses on supervised and unsupervised online label shift, where the class marginals $Q(y)$ varies but the class-conditionals $Q(x|y)$ remain invariant. In the unsupervised setting, our goal is to adapt a learner, trained on some offline labeled data, to changing label distributions given unlabeled online data. In the supervised setting, we must both learn a classifier and adapt to the dynamically evolving class marginals given only labeled online data. We develop novel algorithms that reduce the adaptation problem to online regression and guarantee optimal dynamic regret without any prior knowledge of the extent of drift in the label distribution. Our solution is based on bootstrapping the estimates of \emph{online regression oracles} that track the drifting proportions. Experiments across numerous simulated and real-world online label shift scenarios demonstrate the superior performance of our proposed approaches, often achieving 1-3\% improvement in accuracy while being sample and computationally efficient. Code is publicly available at https://github.com/acmi-lab/OnlineLabelShift.
CHiLS: Zero-Shot Image Classification with Hierarchical Label Sets
Feb 07, 2023Open vocabulary models (e.g. CLIP) have shown strong performance on zero-shot classification through their ability generate embeddings for each class based on their (natural language) names. Prior work has focused on improving the accuracy of these models through prompt engineering or by incorporating a small amount of labeled downstream data (via finetuning). However, there has been little focus on improving the richness of the class names themselves, which can pose issues when class labels are coarsely-defined and uninformative. We propose Classification with Hierarchical Label Sets (or CHiLS), an alternative strategy for zero-shot classification specifically designed for datasets with implicit semantic hierarchies. CHiLS proceeds in three steps: (i) for each class, produce a set of subclasses, using either existing label hierarchies or by querying GPT-3; (ii) perform the standard zero-shot CLIP procedure as though these subclasses were the labels of interest; (iii) map the predicted subclass back to its parent to produce the final prediction. Across numerous datasets with underlying hierarchical structure, CHiLS leads to improved accuracy in situations both with and without ground-truth hierarchical information. CHiLS is simple to implement within existing CLIP pipelines and requires no additional training cost. Code is available at: https://github.com/acmi-lab/CHILS.
RLSbench: Domain Adaptation Under Relaxed Label Shift
Feb 06, 2023



Despite the emergence of principled methods for domain adaptation under label shift, the sensitivity of these methods for minor shifts in the class conditional distributions remains precariously under explored. Meanwhile, popular deep domain adaptation heuristics tend to falter when faced with shifts in label proportions. While several papers attempt to adapt these heuristics to accommodate shifts in label proportions, inconsistencies in evaluation criteria, datasets, and baselines, make it hard to assess the state of the art. In this paper, we introduce RLSbench, a large-scale relaxed label shift benchmark, consisting of >500 distribution shift pairs that draw on 14 datasets across vision, tabular, and language modalities and compose them with varying label proportions. First, we evaluate 13 popular domain adaptation methods, demonstrating more widespread failures under label proportion shifts than were previously known. Next, we develop an effective two-step meta-algorithm that is compatible with most deep domain adaptation heuristics: (i) pseudo-balance the data at each epoch; and (ii) adjust the final classifier with (an estimate of) target label distribution. The meta-algorithm improves existing domain adaptation heuristics often by 2--10\% accuracy points under extreme label proportion shifts and has little (i.e., <0.5\%) effect when label proportions do not shift. We hope that these findings and the availability of RLSbench will encourage researchers to rigorously evaluate proposed methods in relaxed label shift settings. Code is publicly available at https://github.com/acmi-lab/RLSbench.
Disentangling the Mechanisms Behind Implicit Regularization in SGD
Nov 29, 2022



A number of competing hypotheses have been proposed to explain why small-batch Stochastic Gradient Descent (SGD)leads to improved generalization over the full-batch regime, with recent work crediting the implicit regularization of various quantities throughout training. However, to date, empirical evidence assessing the explanatory power of these hypotheses is lacking. In this paper, we conduct an extensive empirical evaluation, focusing on the ability of various theorized mechanisms to close the small-to-large batch generalization gap. Additionally, we characterize how the quantities that SGD has been claimed to (implicitly) regularize change over the course of training. By using micro-batches, i.e. disjoint smaller subsets of each mini-batch, we empirically show that explicitly penalizing the gradient norm or the Fisher Information Matrix trace, averaged over micro-batches, in the large-batch regime recovers small-batch SGD generalization, whereas Jacobian-based regularizations fail to do so. This generalization performance is shown to often be correlated with how well the regularized model's gradient norms resemble those of small-batch SGD. We additionally show that this behavior breaks down as the micro-batch size approaches the batch size. Finally, we note that in this line of inquiry, positive experimental findings on CIFAR10 are often reversed on other datasets like CIFAR100, highlighting the need to test hypotheses on a wider collection of datasets.
Characterizing Datapoints via Second-Split Forgetting
Oct 26, 2022Researchers investigating example hardness have increasingly focused on the dynamics by which neural networks learn and forget examples throughout training. Popular metrics derived from these dynamics include (i) the epoch at which examples are first correctly classified; (ii) the number of times their predictions flip during training; and (iii) whether their prediction flips if they are held out. However, these metrics do not distinguish among examples that are hard for distinct reasons, such as membership in a rare subpopulation, being mislabeled, or belonging to a complex subpopulation. In this paper, we propose $second$-$split$ $forgetting$ $time$ (SSFT), a complementary metric that tracks the epoch (if any) after which an original training example is forgotten as the network is fine-tuned on a randomly held out partition of the data. Across multiple benchmark datasets and modalities, we demonstrate that $mislabeled$ examples are forgotten quickly, and seemingly $rare$ examples are forgotten comparatively slowly. By contrast, metrics only considering the first split learning dynamics struggle to differentiate the two. At large learning rates, SSFT tends to be robust across architectures, optimizers, and random seeds. From a practical standpoint, the SSFT can (i) help to identify mislabeled samples, the removal of which improves generalization; and (ii) provide insights about failure modes. Through theoretical analysis addressing overparameterized linear models, we provide insights into how the observed phenomena may arise. Code for reproducing our experiments can be found here: https://github.com/pratyushmaini/ssft
Downstream Datasets Make Surprisingly Good Pretraining Corpora
Sep 28, 2022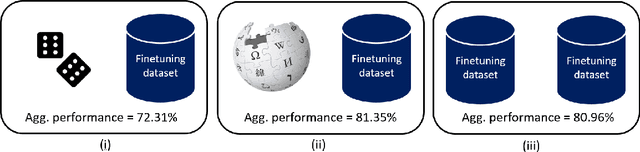
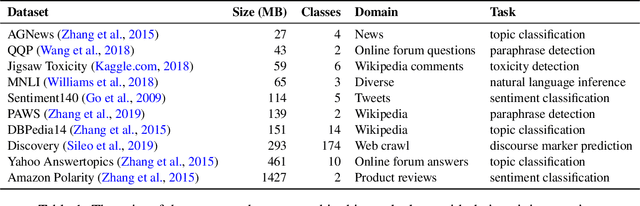
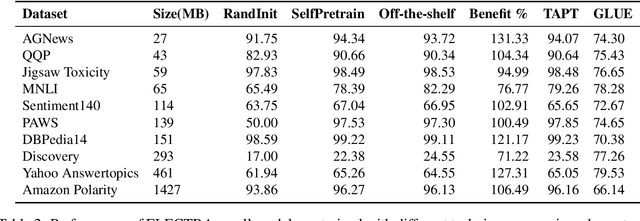
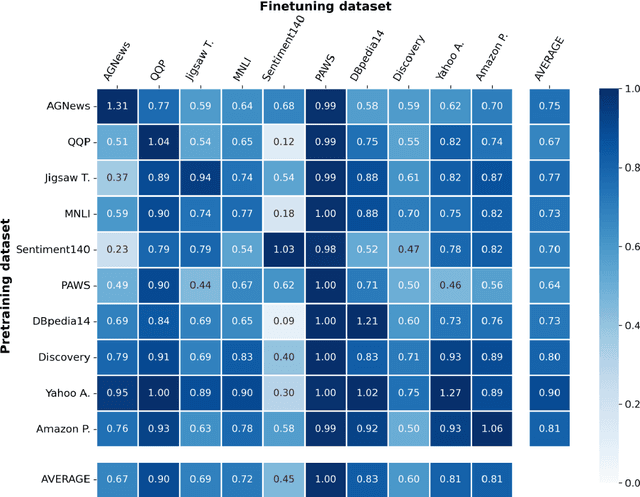
For most natural language processing tasks, the dominant practice is to finetune large pretrained transformer models (e.g., BERT) using smaller downstream datasets. Despite the success of this approach, it remains unclear to what extent these gains are attributable to the massive background corpora employed for pretraining versus to the pretraining objectives themselves. This paper introduces a large-scale study of self-pretraining, where the same (downstream) training data is used for both pretraining and finetuning. In experiments addressing both ELECTRA and RoBERTa models and 10 distinct downstream datasets, we observe that self-pretraining rivals standard pretraining on the BookWiki corpus (despite using around $10\times$--$500\times$ less data), outperforming the latter on $7$ and $5$ datasets, respectively. Surprisingly, these task-specific pretrained models often perform well on other tasks, including the GLUE benchmark. Our results suggest that in many scenarios, performance gains attributable to pretraining are driven primarily by the pretraining objective itself and are not always attributable to the incorporation of massive datasets. These findings are especially relevant in light of concerns about intellectual property and offensive content in web-scale pretraining data.
Unsupervised Learning under Latent Label Shift
Jul 26, 2022
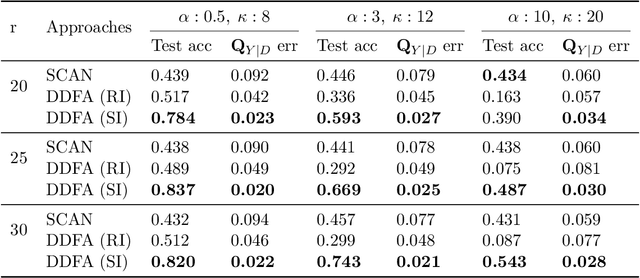

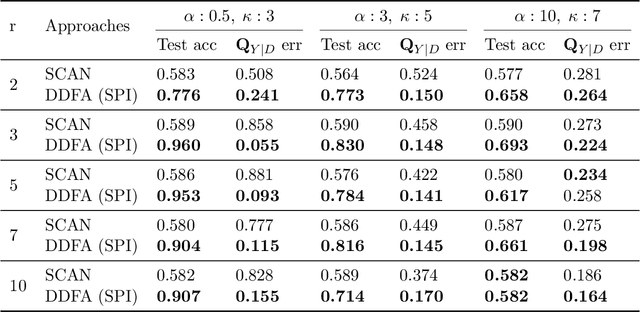
What sorts of structure might enable a learner to discover classes from unlabeled data? Traditional approaches rely on feature-space similarity and heroic assumptions on the data. In this paper, we introduce unsupervised learning under Latent Label Shift (LLS), where we have access to unlabeled data from multiple domains such that the label marginals $p_d(y)$ can shift across domains but the class conditionals $p(\mathbf{x}|y)$ do not. This work instantiates a new principle for identifying classes: elements that shift together group together. For finite input spaces, we establish an isomorphism between LLS and topic modeling: inputs correspond to words, domains to documents, and labels to topics. Addressing continuous data, we prove that when each label's support contains a separable region, analogous to an anchor word, oracle access to $p(d|\mathbf{x})$ suffices to identify $p_d(y)$ and $p_d(y|\mathbf{x})$ up to permutation. Thus motivated, we introduce a practical algorithm that leverages domain-discriminative models as follows: (i) push examples through domain discriminator $p(d|\mathbf{x})$; (ii) discretize the data by clustering examples in $p(d|\mathbf{x})$ space; (iii) perform non-negative matrix factorization on the discrete data; (iv) combine the recovered $p(y|d)$ with the discriminator outputs $p(d|\mathbf{x})$ to compute $p_d(y|x) \; \forall d$. With semi-synthetic experiments, we show that our algorithm can leverage domain information to improve state of the art unsupervised classification methods. We reveal a failure mode of standard unsupervised classification methods when feature-space similarity does not indicate true groupings, and show empirically that our method better handles this case. Our results establish a deep connection between distribution shift and topic modeling, opening promising lines for future work.