 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture Proportion Estimation and PU Learning: A Modern Approach
Paper and Code
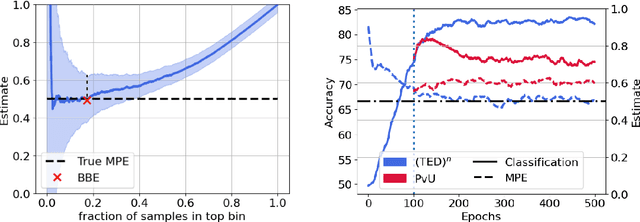
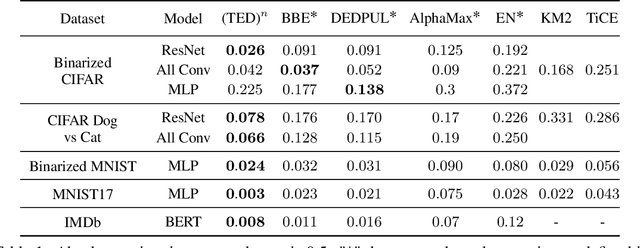
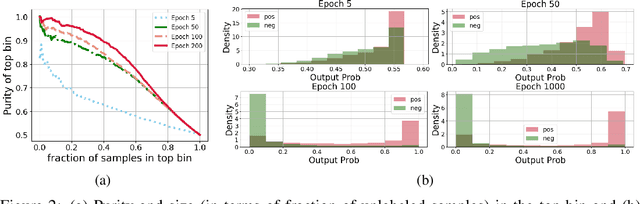
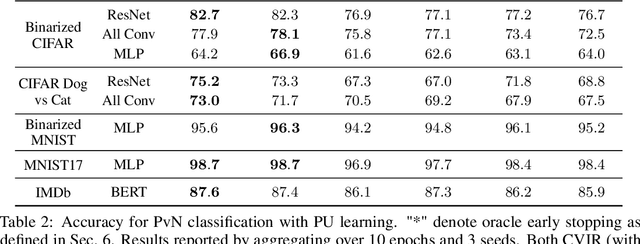
Given only positive examples and unlabeled examples (from both positive and negative classes), we might hope nevertheless to estimate an accurate positive-versus-negative classifier. Formally, this task is broken down into two subtasks: (i) Mixture Proportion Estimation (MPE) -- determining the fraction of positive examples in the unlabeled data; and (ii) PU-learning -- given such an estimate, learning the desired positive-versus-negative classifier. Unfortunately, classical methods for both problems break down in high-dimensional settings. Meanwhile, recently proposed heuristics lack theoretical coherence and depend precariously on hyperparameter tuning. In this paper, we propose two simple techniques: Best Bin Estimation (BBE) (for MPE); and Conditional Value Ignoring Risk (CVIR), a simple objective for PU-learning. Both methods dominate previous approaches empirically, and for BBE, we establish formal guarantees that hold whenever we can train a model to cleanly separate out a small subset of positive examples. Our final algorithm (TED)$^n$, alternates between the two procedures, significantly improving both our mixture proportion estimator and classifier