 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoft-SVeRL: Self-Verified Reinforcement Learning with Soft Rewards
May 27, 2026Reinforcement Learning from Verifiable Rewards (RLVR) has improved language models in domains such as mathematics and code, where correctness can be checked automatically. However, many important tasks are only partially verifiable: prompts contain multiple requirements, responses may satisfy some but not all of them, or no single reference answer might exist. We introduce Soft-RLVR, a framework for reinforcement learning from decomposed, learned verification signals. Soft-RLVR converts each prompt into a checklist of atomic requirements, scores candidate responses item by item with an LLM verifier, and trains on the resulting soft reward. Checklist-based rewards turn sparse pass/fail supervision into a denser partial-credit signal, but they also introduce a tradeoff: averaging item-level judgments can reduce verifier noise, while partial credit can reward incomplete responses. We formalize this tradeoff and identify conditions under which checklist-based verification gives a more reliable RL training signal than holistic verification. We further introduce Soft-SVeRL, a self-verifying variant of Soft-RLVR in which the policy also acts as the verifier. We show that self-verification is prone to reward inflation from overly permissive self-judgments, and that explicit stabilization is needed to prevent this collapse. In a controlled instruction-following setting with rule-based ground-truth evaluation, checklist-based Soft-RLVR improves IFEval by up to 11.1 points using only learned verifier rewards. Our experiments further show that verifier quality and checklist quality both affect downstream RL outcomes, and that explicit stabilization is essential for effective self-verification.
Tiny Aya: Bridging Scale and Multilingual Depth
Mar 12, 2026Tiny Aya redefines what a small multilingual language model can achieve. Trained on 70 languages and refined through region-aware posttraining, it delivers state-of-the-art in translation quality, strong multilingual understanding, and high-quality target-language generation, all with just 3.35B parameters. The release includes a pretrained foundation model, a globally balanced instruction-tuned variant, and three region-specialized models targeting languages from Africa, South Asia, Europe, Asia-Pacific, and West Asia. This report details the training strategy, data composition, and comprehensive evaluation framework behind Tiny Aya, and presents an alternative scaling path for multilingual AI: one centered on efficiency, balanced performance across languages, and practical deployment.
Aya Vision: Advancing the Frontier of Multilingual Multimodality
May 13, 2025Building multimodal language models is fundamentally challenging: it requires aligning vision and language modalities, curating high-quality instruction data, and avoiding the degradation of existing text-only capabilities once vision is introduced. These difficulties are further magnified in the multilingual setting, where the need for multimodal data in different languages exacerbates existing data scarcity, machine translation often distorts meaning, and catastrophic forgetting is more pronounced. To address the aforementioned challenges, we introduce novel techniques spanning both data and modeling. First, we develop a synthetic annotation framework that curates high-quality, diverse multilingual multimodal instruction data, enabling Aya Vision models to produce natural, human-preferred responses to multimodal inputs across many languages. Complementing this, we propose a cross-modal model merging technique that mitigates catastrophic forgetting, effectively preserving text-only capabilities while simultaneously enhancing multimodal generative performance. Aya-Vision-8B achieves best-in-class performance compared to strong multimodal models such as Qwen-2.5-VL-7B, Pixtral-12B, and even much larger Llama-3.2-90B-Vision. We further scale this approach with Aya-Vision-32B, which outperforms models more than twice its size, such as Molmo-72B and LLaMA-3.2-90B-Vision. Our work advances multilingual progress on the multi-modal frontier, and provides insights into techniques that effectively bend the need for compute while delivering extremely high performance.
Command A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
How Does Quantization Affect Multilingual LLMs?
Jul 03, 2024Quantization techniques are widely used to improve inference speed and deployment of large language models. While a wide body of work examines the impact of quantized LLMs on English tasks, none have examined the effect of quantization across languages. We conduct a thorough analysis of quantized multilingual LLMs, focusing on their performance across languages and at varying scales. We use automatic benchmarks, LLM-as-a-Judge methods, and human evaluation, finding that (1) harmful effects of quantization are apparent in human evaluation, and automatic metrics severely underestimate the detriment: a 1.7% average drop in Japanese across automatic tasks corresponds to a 16.0% drop reported by human evaluators on realistic prompts; (2) languages are disparately affected by quantization, with non-Latin script languages impacted worst; and (3) challenging tasks such as mathematical reasoning degrade fastest. As the ability to serve low-compute models is critical for wide global adoption of NLP technologies, our results urge consideration of multilingual performance as a key evaluation criterion for efficient models.
Outliers and Calibration Sets have Diminishing Effect on Quantization of Modern LLMs
Jun 03, 2024



Post-Training Quantization (PTQ) enhances the efficiency of Large Language Models (LLMs) by enabling faster operation and compatibility with more accessible hardware through reduced memory usage, at the cost of small performance drops. We explore the role of calibration sets in PTQ, specifically their effect on hidden activations in various notable open-source LLMs. Calibration sets are crucial for evaluating activation magnitudes and identifying outliers, which can distort the quantization range and negatively impact performance. Our analysis reveals a marked contrast in quantization effectiveness across models. The older OPT model, upon which much of the quantization literature is based, shows significant performance deterioration and high susceptibility to outliers with varying calibration sets. In contrast, newer models like Llama-2 7B, Llama-3 8B, Command-R 35B, and Mistral 7B demonstrate strong robustness, with Mistral 7B showing near-immunity to outliers and stable activations. These findings suggest a shift in PTQ strategies might be needed. As advancements in pre-training methods reduce the relevance of outliers, there is an emerging need to reassess the fundamentals of current quantization literature. The emphasis should pivot towards optimizing inference speed, rather than primarily focusing on outlier preservation, to align with the evolving characteristics of state-of-the-art LLMs.
Aya 23: Open Weight Releases to Further Multilingual Progress
May 23, 2024



This technical report introduces Aya 23, a family of multilingual language models. Aya 23 builds on the recent release of the Aya model (\"Ust\"un et al., 2024), focusing on pairing a highly performant pre-trained model with the recently released Aya collection (Singh et al., 2024). The result is a powerful multilingual large language model serving 23 languages, expanding state-of-art language modeling capabilities to approximately half of the world's population. The Aya model covered 101 languages whereas Aya 23 is an experiment in depth vs breadth, exploring the impact of allocating more capacity to fewer languages that are included during pre-training. Aya 23 outperforms both previous massively multilingual models like Aya 101 for the languages it covers, as well as widely used models like Gemma, Mistral and Mixtral on an extensive range of discriminative and generative tasks. We release the open weights for both the 8B and 35B models as part of our continued commitment for expanding access to multilingual progress.
Intriguing Properties of Quantization at Scale
May 30, 2023



Emergent properties have been widely adopted as a term to describe behavior not present in smaller models but observed in larger models. Recent work suggests that the trade-off incurred by quantization is also an emergent property, with sharp drops in performance in models over 6B parameters. In this work, we ask "are quantization cliffs in performance solely a factor of scale?" Against a backdrop of increased research focus on why certain emergent properties surface at scale, this work provides a useful counter-example. We posit that it is possible to optimize for a quantization friendly training recipe that suppresses large activation magnitude outliers. Here, we find that outlier dimensions are not an inherent product of scale, but rather sensitive to the optimization conditions present during pre-training. This both opens up directions for more efficient quantization, and poses the question of whether other emergent properties are inherent or can be altered and conditioned by optimization and architecture design choices. We successfully quantize models ranging in size from 410M to 52B with minimal degradation in performance.
Learning Point Processes using Recurrent Graph Network
Aug 11, 2022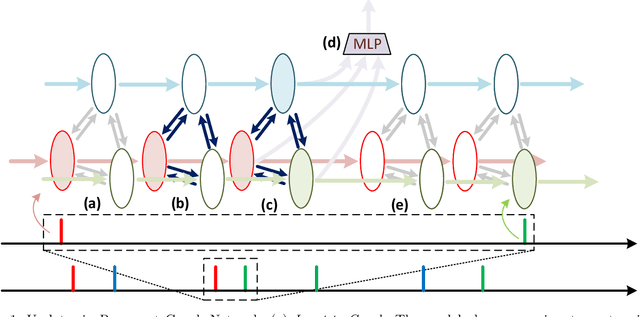
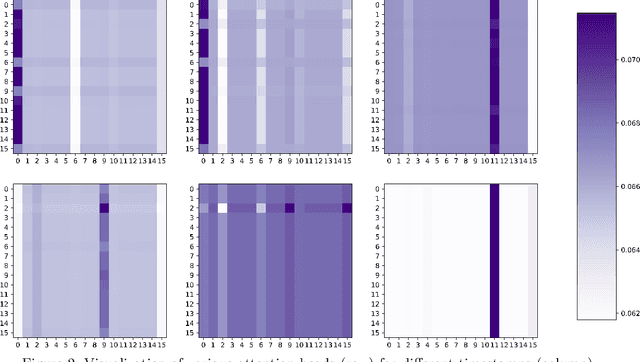
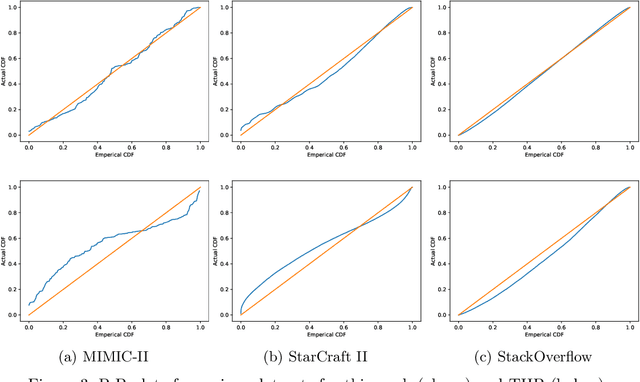

We present a novel Recurrent Graph Network (RGN) approach for predicting discrete marked event sequences by learning the underlying complex stochastic process. Using the framework of Point Processes, we interpret a marked discrete event sequence as the superposition of different sequences each of a unique type. The nodes of the Graph Network use LSTM to incorporate past information whereas a Graph Attention Network (GAT Network) introduces strong inductive biases to capture the interaction between these different types of events. By changing the self-attention mechanism from attending over past events to attending over event types, we obtain a reduction in time and space complexity from $\mathcal{O}(N^2)$ (total number of events) to $\mathcal{O}(|\mathcal{Y}|^2)$ (number of event types). Experiments show that the proposed approach improves performance in log-likelihood, prediction and goodness-of-fit tasks with lower time and space complexity compared to state-of-the art Transformer based architectures.
PhICNet: Physics-Incorporated Convolutional Recurrent Neural Networks for Modeling Dynamical Systems
Apr 14, 2020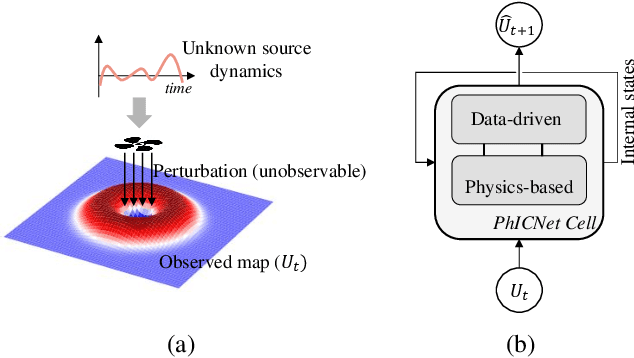
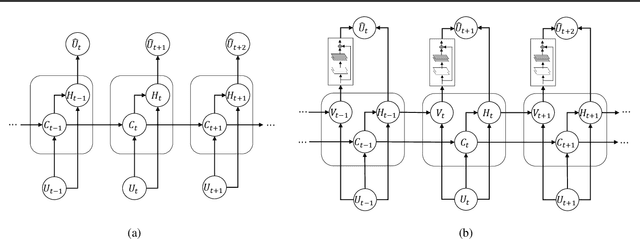
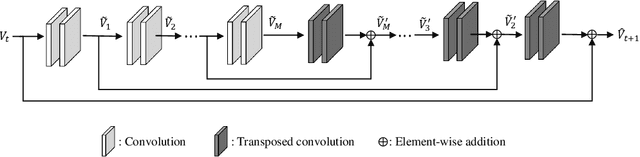
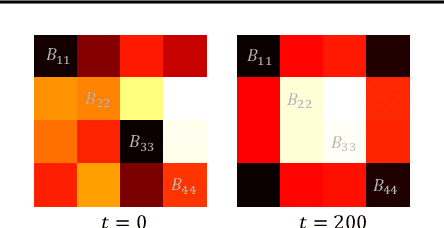
Dynamical systems involving partial differential equations (PDEs) and ordinary differential equations (ODEs) arise in many fields of science and engineering. In this paper, we present a physics-incorporated deep learning framework to model and predict the spatiotemporal evolution of dynamical systems governed by partially-known inhomogenous PDEs with unobservable source dynamics. We formulate our model PhICNet as a convolutional recurrent neural network which is end-to-end trainable for spatiotemporal evolution prediction of dynamical systems. Experimental results show the long-term prediction capability of our model.