 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny Aya: Bridging Scale and Multilingual Depth
Mar 12, 2026Tiny Aya redefines what a small multilingual language model can achieve. Trained on 70 languages and refined through region-aware posttraining, it delivers state-of-the-art in translation quality, strong multilingual understanding, and high-quality target-language generation, all with just 3.35B parameters. The release includes a pretrained foundation model, a globally balanced instruction-tuned variant, and three region-specialized models targeting languages from Africa, South Asia, Europe, Asia-Pacific, and West Asia. This report details the training strategy, data composition, and comprehensive evaluation framework behind Tiny Aya, and presents an alternative scaling path for multilingual AI: one centered on efficiency, balanced performance across languages, and practical deployment.
Unlocking Reasoning Capability on Machine Translation in Large Language Models
Feb 16, 2026Reasoning-oriented large language models (RLMs) achieve strong gains on tasks such as mathematics and coding by generating explicit intermediate reasoning. However, their impact on machine translation (MT) remains underexplored. We systematically evaluate several open- and closed-weights RLMs on the WMT24++ benchmark and find that enabling explicit reasoning consistently degrades translation quality across languages and models. Analysis reveals that MT reasoning traces are highly linear, lacking revision, self-correction and exploration of alternative translations, which limits their usefulness. Furthermore, injecting higher-quality reasoning traces from stronger models does not reliably improve weaker models' performance. To address this mismatch, we propose a structured reasoning framework tailored to translation, based on multi-step drafting, adequacy refinement, fluency improvement, and selective iterative revision. We curate a synthetic dataset of dynamic structured reasoning traces and post-train a large reasoning model on this data. Experiments show significant improvements over standard translation fine-tuning and injected generic reasoning baselines. Our findings demonstrate that reasoning must be task-structured to benefit MT.
Best-of-L: Cross-Lingual Reward Modeling for Mathematical Reasoning
Sep 19, 2025While the reasoning abilities of large language models (LLMs) continue to advance, it remains unclear how such ability varies across languages in multilingual LLMs and whether different languages produce reasoning paths that complement each other. To investigate this question, we train a reward model to rank generated responses for a given question across languages. Our results show that our cross-lingual reward model substantially improves mathematical reasoning performance compared to using reward modeling within a single language, benefiting even high-resource languages. While English often exhibits the highest performance in multilingual models, we find that cross-lingual sampling particularly benefits English under low sampling budgets. Our findings reveal new opportunities to improve multilingual reasoning by leveraging the complementary strengths of diverse languages.
Local Look-Ahead Guidance via Verifier-in-the-Loop for Automated Theorem Proving
Mar 12, 2025



The most promising recent methods for AI reasoning require applying variants of reinforcement learning (RL) either on rolled out trajectories from the model, even for the step-wise rewards, or large quantities of human annotated trajectory data. The reliance on the rolled-out trajectory renders the compute cost and time prohibitively high. In particular, the correctness of a reasoning trajectory can typically only be judged at its completion, leading to sparse rewards in RL or requiring expensive synthetic data generation in expert iteration-like methods. In this work, we focus on the Automatic Theorem Proving (ATP) task and propose a novel verifier-in-the-loop design, which unlike existing approaches that leverage feedback on the entire reasoning trajectory, employs an automated verifier to give intermediate feedback at each step of the reasoning process. Using Lean as the verifier, we empirically show that the step-by-step local verification produces a global improvement in the model's reasoning accuracy and efficiency.
On the Evaluation Practices in Multilingual NLP: Can Machine Translation Offer an Alternative to Human Translations?
Jun 20, 2024



While multilingual language models (MLMs) have been trained on 100+ languages, they are typically only evaluated across a handful of them due to a lack of available test data in most languages. This is particularly problematic when assessing MLM's potential for low-resource and unseen languages. In this paper, we present an analysis of existing evaluation frameworks in multilingual NLP, discuss their limitations, and propose several directions for more robust and reliable evaluation practices. Furthermore, we empirically study to what extent machine translation offers a {reliable alternative to human translation} for large-scale evaluation of MLMs across a wide set of languages. We use a SOTA translation model to translate test data from 4 tasks to 198 languages and use them to evaluate three MLMs. We show that while the selected subsets of high-resource test languages are generally sufficiently representative of a wider range of high-resource languages, we tend to overestimate MLMs' ability on low-resource languages. Finally, we show that simpler baselines can achieve relatively strong performance without having benefited from large-scale multilingual pretraining.
Analyzing the Evaluation of Cross-Lingual Knowledge Transfer in Multilingual Language Models
Feb 03, 2024



Recent advances in training multilingual language models on large datasets seem to have shown promising results in knowledge transfer across languages and achieve high performance on downstream tasks. However, we question to what extent the current evaluation benchmarks and setups accurately measure zero-shot cross-lingual knowledge transfer. In this work, we challenge the assumption that high zero-shot performance on target tasks reflects high cross-lingual ability by introducing more challenging setups involving instances with multiple languages. Through extensive experiments and analysis, we show that the observed high performance of multilingual models can be largely attributed to factors not requiring the transfer of actual linguistic knowledge, such as task- and surface-level knowledge. More specifically, we observe what has been transferred across languages is mostly data artifacts and biases, especially for low-resource languages. Our findings highlight the overlooked drawbacks of existing cross-lingual test data and evaluation setups, calling for a more nuanced understanding of the cross-lingual capabilities of multilingual models.
An Empirical Study on the Transferability of Transformer Modules in Parameter-Efficient Fine-Tuning
Feb 01, 2023



Parameter-efficient fine-tuning approaches have recently garnered a lot of attention. Having considerably lower number of trainable weights, these methods can bring about scalability and computational effectiveness. In this paper, we look for optimal sub-networks and investigate the capability of different transformer modules in transferring knowledge from a pre-trained model to a downstream task. Our empirical results suggest that every transformer module in BERT can act as a winning ticket: fine-tuning each specific module while keeping the rest of the network frozen can lead to comparable performance to the full fine-tuning. Among different modules, LayerNorms exhibit the best capacity for knowledge transfer with limited trainable weights, to the extent that, with only 0.003% of all parameters in the layer-wise analysis, they show acceptable performance on various target tasks. On the reasons behind their effectiveness, we argue that their notable performance could be attributed to their high-magnitude weights compared to that of the other modules in the pre-trained BERT.
Looking at the Overlooked: An Analysis on the Word-Overlap Bias in Natural Language Inference
Nov 07, 2022



It has been shown that NLI models are usually biased with respect to the word-overlap between premise and hypothesis; they take this feature as a primary cue for predicting the entailment label. In this paper, we focus on an overlooked aspect of the overlap bias in NLI models: the reverse word-overlap bias. Our experimental results demonstrate that current NLI models are highly biased towards the non-entailment label on instances with low overlap, and the existing debiasing methods, which are reportedly successful on existing challenge datasets, are generally ineffective in addressing this category of bias. We investigate the reasons for the emergence of the overlap bias and the role of minority examples in its mitigation. For the former, we find that the word-overlap bias does not stem from pre-training, and for the latter, we observe that in contrast to the accepted assumption, eliminating minority examples does not affect the generalizability of debiasing methods with respect to the overlap bias.
On the Importance of Data Size in Probing Fine-tuned Models
Mar 17, 2022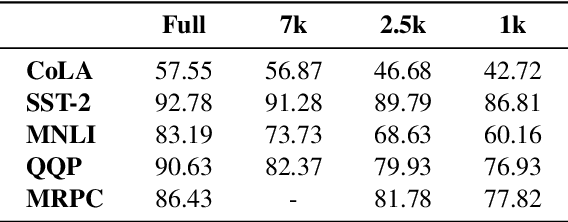
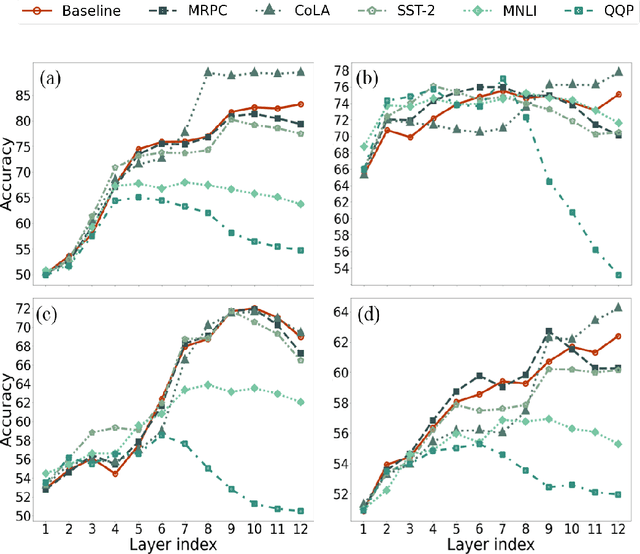
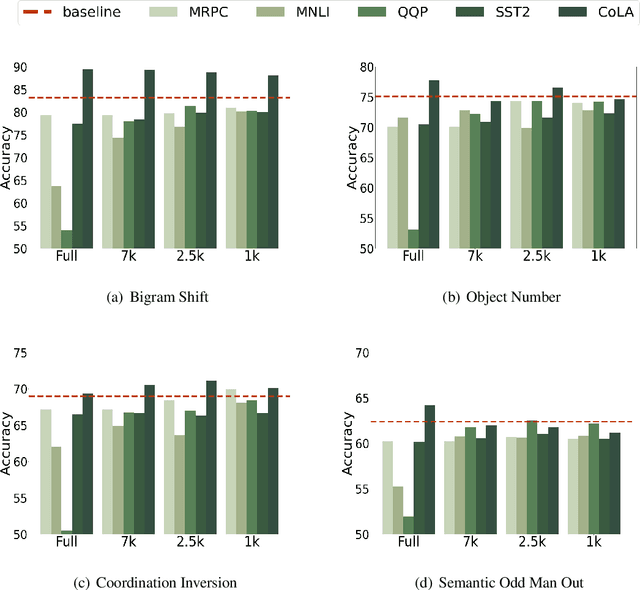
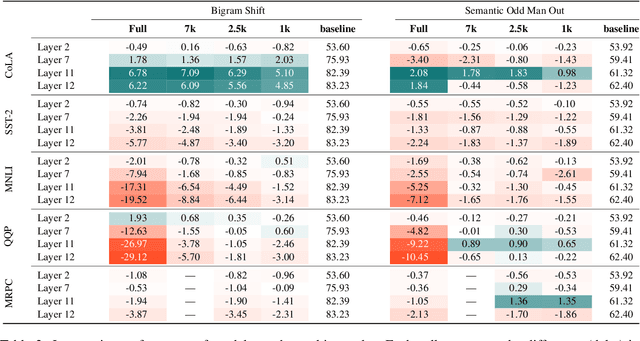
Several studies have investigated the reasons behind the effectiveness of fine-tuning, usually through the lens of probing. However, these studies often neglect the role of the size of the dataset on which the model is fine-tuned. In this paper, we highlight the importance of this factor and its undeniable role in probing performance. We show that the extent of encoded linguistic knowledge depends on the number of fine-tuning samples. The analysis also reveals that larger training data mainly affects higher layers, and that the extent of this change is a factor of the number of iterations updating the model during fine-tuning rather than the diversity of the training samples. Finally, we show through a set of experiments that fine-tuning data size affects the recoverability of the changes made to the model's linguistic knowledge.
An Isotropy Analysis in the Multilingual BERT Embedding Space
Oct 09, 2021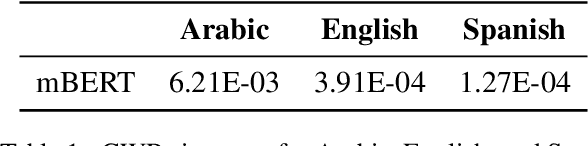
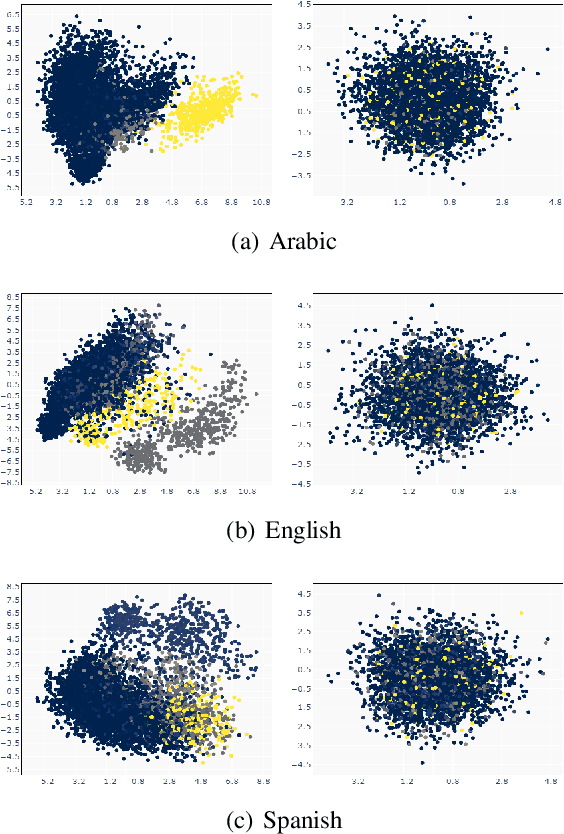


Several studies have explored various advantages of multilingual pre-trained models (e.g., multilingual BERT) in capturing shared linguistic knowledge. However, their limitations have not been paid enough attention. In this paper, we investigate the representation degeneration problem in multilingual contextual word representations (CWRs) of BERT and show that the embedding spaces of the selected languages suffer from anisotropy problem. Our experimental results demonstrate that, similarly to their monolingual counterparts, increasing the isotropy of multilingual embedding space can significantly improve its representation power and performance. Our analysis indicates that although the degenerated directions vary in different languages, they encode similar linguistic knowledge, suggesting a shared linguistic space among languages.